こんにちは。ヤフーの音声認識エンジン「YJVOICE」の研究開発を担当している前角です。この記事ではヤフーにおける音声処理技術の研究開発の最新の取り組みの中から、自己教師あり学習を用いた音声言語モデルの改善手法について取り上げます。今回は音声向けの表現学習モデル「HuBERT」を用いたところ、学習データが不足する状況下でも、すべての評価指標において前回提案した手法を上回る性能を達成できました。
なお、今回の内容は前回紹介した「ラベルなしの音声データを用いて言語理解が可能に?音声言語モデルの性能改善手法のご紹介」の続きですので、そちらも合わせてご覧いただければと思います。
また、本研究は米国カーネギーメロン大学の渡部晋治准教授との共同研究として実施したものです。詳細は昨年開催された信号処理分野のトップ国際会議「ICASSP 2022」で発表していますので、ご興味がある方はぜひ論文の方もご覧ください。
はじめに
近年、自己教師あり学習が機械学習の分野で大変注目を集めています。自己教師あり学習は、人手で付与した教師ラベルを用いずにデータ自体に含まれる情報を使って予測問題を解く手法で、音声処理の分野においても数多くの応用例が報告されています。その中の1つとして、テキストデータを使用せず、音声データのみを用いて音声対話システムを実現しようとする研究がいくつか提案されています。これらの取り組みの背景には、音声のゼロリソース問題と呼ばれるものがあります。
音声のゼロリソース問題
現在音声認識や音声翻訳などに使用されるモデルの学習は、膨大な量の音声とそれに対応した書き起こしテキストのペアデータを用いて行われています。しかし世界には信頼できるテキストデータが十分に存在しない言語が多く存在しています。例えばEthnologueによると、世界の7,139言語のうち2,990言語は書き言葉が存在していないとされているため、書き起こすこと自体が不可能です。このため、こういったマイナーな言語については、書き起こしテキストを必要とした手法を適用するのが難しいという問題があります。
一方、乳幼児はテキスト等の教師データを用いることなく、聴覚や視覚といったセンサー情報を元に自発的に母国語を学ぶことができます。よってシステム上でも同様のプロセスで音声言語理解を実現するというのが理想の1つといえます。
音声言語理解タスク(Zero Resource Speech Challenge 2021)
こうしたゼロリソース問題に取り組むために、Zero Resource Speech Challenge(以下ZeroSpeechタスク)というコンペティションが開催されています。このタスクは、聴覚などのセンサー情報のみを用いて音声対話システムを実現することを最終目標とするコンペティションです。しかし、フルスクラッチで教師なしの音声対話システムを実現するのは現状では非常に難しいため、タスクをブレイクダウンして各回で異なるサブタスクに取り組みながら段階的に実現していこうとしています。そして前回われわれが取り組んだ2021年のタスクは、音声データのみを用いて構築した言語モデル(音声言語モデル)の言語理解性能を、以下の4つの観点で評価するというものでした。
- 音素的観点:
- “aba”や”apa”といった音声から音素を識別可能かどうか
- 語彙(ごい)的観点:
- “brick”と”blick”といった単語の違いを聞き分けられるかどうか
- 文法的観点:
- “dogs eat meat”と”dogs eats meat”のようなペアが与えられたときに文法的に正しい方を選択可能かどうか
- 意味的観点:
- 2単語間の意味的な類似度を求め、人間が別途与えた類似度とどの程度相関があるか
今回私たちは、同じZeroSpeechタスクの設定にのっとり、昨今音声の表現学習モデルとして有力視されているHuBERTをベースラインに適用して性能改善を行いました(今回はコンペティションには不参加)。また、HuBERTのハイパーパラメータ探索を効率化するためにBIC(Bayesian Information Criterion)を用いたモデル選択も提案しています。なお、ベースラインの手法については前回の記事で説明しておりますので、そちらをご覧ください。
HuBERT
HuBERT(Hidden Unit BERT)はBERTのようなmasked predictionタスクとiterative trainingを組み合わせた音声向けの表現学習モデルです。モデルの構造は、図 1に示すようにCNNとTransformerの各エンコーダから構成されており、次の手順で学習を行います。
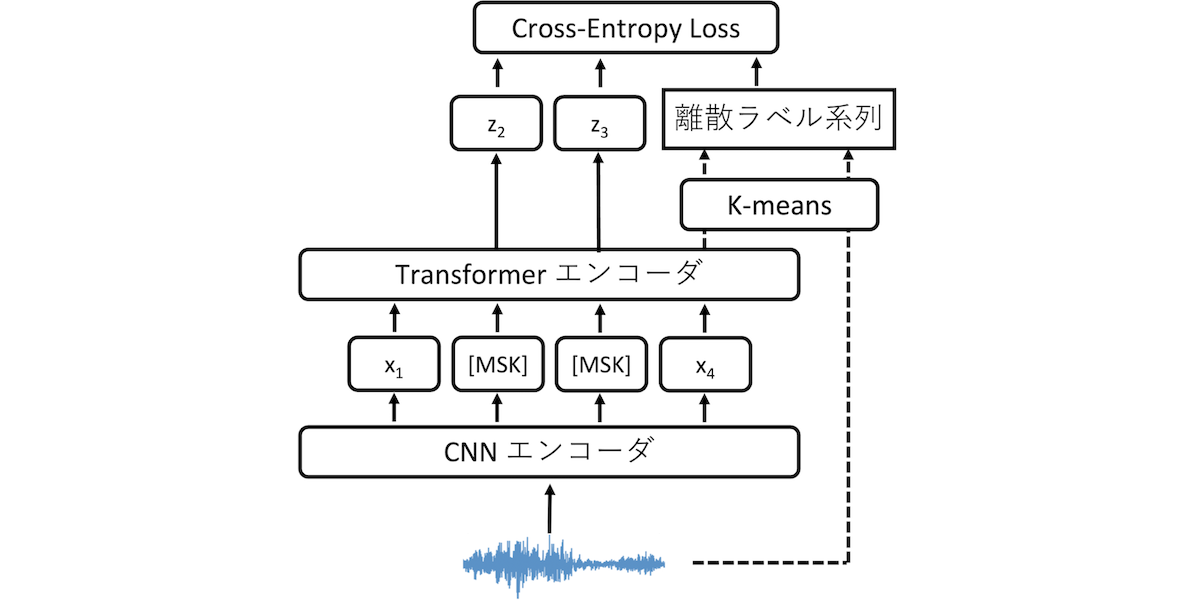 図 1. HuBERT
図 1. HuBERT
まず入力音声からMFCCと呼ばれる音響特徴量をフレームごとに抽出します。MFCCは音声処理でよく用いられる音響特徴量で、音声のパワースペクトルの情報から微細な振動の情報を落としてスペクトル包絡成分の情報を取り出した特徴量となります。次にMFCCの系列をk-meansを用いてクラスタリングすることで、離散ラベル(疑似ラベル)の系列を生成します。次に音声をCNNエンコーダへ入力して1つ目の埋め込み表現xを抽出します。xの系列はランダムにマスクされてTransformerエンコーダに入力され、2つ目の埋め込み表現zを出力します。最後にzの系列と疑似ラベル系列を用いて、BERTと同様にマスクされたトークンを予測するように(masked predictionタスク)学習を行います(初期学習)。HuBERTでは、さらにiterative trainingを行います。これは学習済みネットワークのTransformerエンコーダの出力を用いてk-meansを適用することで疑似ラベルを生成し直し、これを教師ラベルとして初期学習と同様の学習を複数回行うものです。こうして疑似ラベルを更新していくことで、音声認識等のタスクでより性能が向上することが報告されています。
提案法
次に提案法について説明します。システム構成におけるベースラインとの差分は以下の2点です。
- 音声の表現学習モデルとしてHuBERTを用いて音声の特徴量を抽出する
- 音声言語モデル学習の前にBICによるモデル選択を行う
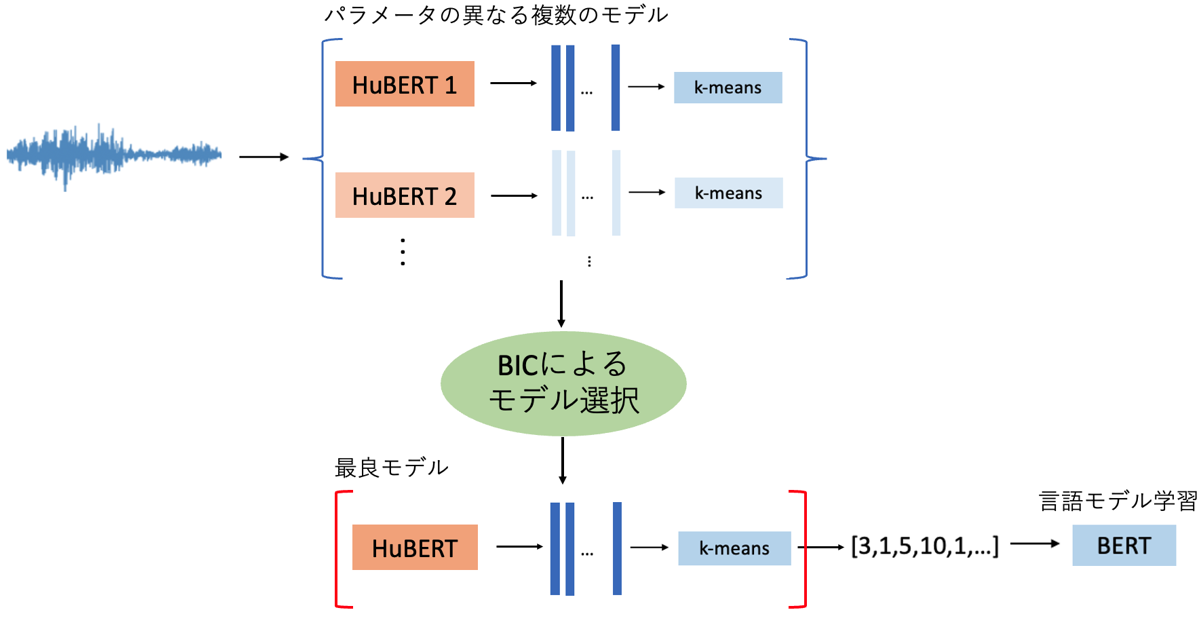 図 2. 提案法の全体図
図 2. 提案法の全体図
以下で詳しく説明します。
クラスタ数と反復回数を増やしたHuBERTの適用
ベースラインでは音声の特徴抽出を行う表現学習モデルとしてCPC(Contrastive Predictive Coding)が使用されていました。CPCは音声の文脈情報を取り込むように学習されますが、過去方向の情報しか使用されていませんでした。一方でHuBERTは、masked predictionを行うことによって入力特徴の前後の文脈を考慮しているため、よりリッチな言語的特徴を捉えることが可能となっています。また、音声認識の性能もCPCと比較して大変優れています。そのため、CPCをHuBERTに置き換えることを考えました。
また、疑似ラベルzのクラスタ数とiterative trainingの反復回数を増やすことを検討します。HuBERTを用いた音声認識の研究では、クラスタ数は500個までで、反復回数も2回までしか行われていませんでした。ここではタスクは異なりますが、もっと増やして性能上限を探ることにしました。
BICによる音声言語モデル選択
前述のHuBERTのハイパーパラメータ探索は、後段の音声言語モデルの学習も行う必要があるため大変計算コストが高いという問題があります。このためクラスタ数の選定に関しては、事前にHuBERTの特徴量とk-meansのパラメータに対してBICを用いることで、音声言語モデル学習を行わずにモデル選択を行う方法を提案しました。
BIC(Bayesian Information Criterion)とは、統計的モデル選択(与えられた複数のモデルから、ある基準に従って最良のモデルを選択すること)に用いられる評価基準の1つです。次のようにモデルパラメータθにおけるデータDの対数尤度(第1項)とペナルティ項(第2項)から構成されており、値が小さいほど良いモデルであることを表しています。Sはパラメータ数を表しているため、パラメータ数が大きすぎる(モデルが複雑である)とペナルティが働くという構造になっています。k-meansは、分散を固定化した混合ガウスモデルの特殊な場合と考えられるため、モデルの尤度は各クラスタのセントロイドを平均とした場合の混合ガウスモデルを用いて計算が可能です。またBICの計算はCPU上で行うことができるため、GPUが必要な音声言語モデル学習に比べて計算コストが軽く、効率的なクラスタ数のチューニングが可能です。
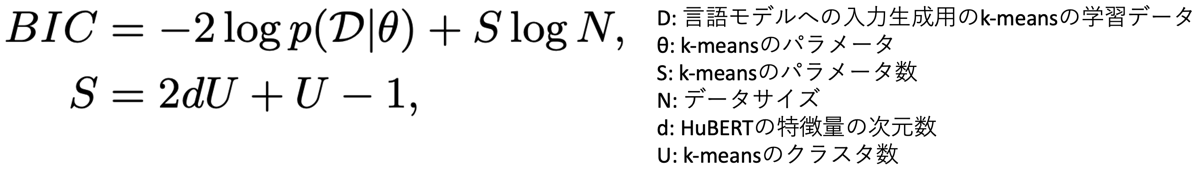
よって全体の学習手順は以下のようになります。
- HuBERTについて、クラスタ数が異なる事前学習モデルを複数用意しておく。
- 学習データの一部を入力とし、各HuBERTのモデルを用いて特徴量の抽出及びk-meansクラスタリングを行う。
- 上で得られたk-meansのセントロイドやパラメータ等を用いてBICを算出する。
- BICが最も小さいときのHuBERTモデル及びk-meansのパラメータを採用し、学習データを疑似ラベル系列に変換する。
- 上で得られた疑似ラベル系列を入力として音声言語モデルを学習する。
評価方法
各音響・言語理解タスクの評価方法について簡単に説明します。詳細はZeroSpeechチャレンジのベースライン論文をご覧ください。
- 音素識別スコア(ABXエラー率)
- 2つの音素カテゴリとそれらに属する音声a∈Aとb∈Bが与えられたとき、評価音声x∈AがカテゴリBに誤って分類される割合(エラー率)を算出する。
- 各音声の表現学習モデルによる特徴量を用いて音声aとx、bとx間の距離d(a,x)とd(b,x)をそれぞれ求め、d(a,x)≧d(b,x)であれば誤分類されたとみなす。
- このスコアに関してのみ音声言語モデルは不使用。
- 語彙識別スコア、文法誤り識別スコア
- (よく似ているが、スペルもしくは文法が少し異なる)音声のペアについて、各入力音声を離散系列化して音声言語モデルに入力し、音声言語モデルスコアをそれぞれ算出する。
- スペルもしくは文法的に正しい音声の言語モデルスコアの方が値が大きければ正解とし、正解率を算出する。
- 意味的類似度相関スコア
- 与えられた単語のペアに対し、音声言語モデルの中間特徴量を用いて類似度を算出する。
- 別途人手で付与した類似度との相関係数を求める。
実験結果
提案法をベースラインと比較しました。使用した学習データは以下のとおりです。
- 表現学習モデル
- ベースライン/前回の提案法: Libri-Light(英語の読み上げ音声;6,000時間)
- 提案法: LibriSpeech(英語の読み上げ音声;100時間)
- 音声言語モデル(全モデル共通)
- LibriSpeech(960時間)
なお、今回の表現学習モデルの学習に使用したデータ、及びデータサイズは前回の記事と異なることにご注意ください。評価データはLibriSpeechをベースにZeroSpeechタスク向けに作成されたデータセットを使用しています。
まずBICと評価指標の関係について見ていきます。図 3ではHuBERTのクラスタ数と反復回数を変化させたときの各モデルにおけるBICと語彙識別スコア、文法誤り識別スコアをプロットしています。ここで、各モデルの表記は”{クラスタ数}-{反復回数}iter”となっています。この結果より以下のことが確認できました。
- クラスタ数を500から増やすことでさらに性能が改善
- 語彙識別スコアに関しては反復回数を3回まで増やすことでさらに性能が改善した。
- (特に語彙識別スコアで)BICを用いたモデル選択の有効性を確認
- 例えば”3-iter”の場合、クラスタ数を500から1,100に増やすと語彙識別スコアが向上し、BICの値が小さくなっている。さらに2,100個まで増やすと性能は悪化し、BICの値も大きくなっている。
- BICを用いて、各反復における最適なクラスタ数の範囲をある程度見積もることが可能。
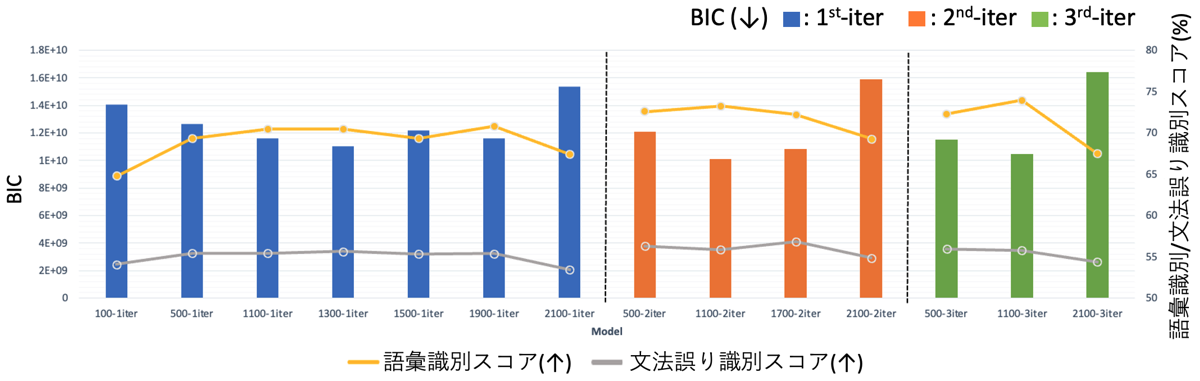 図 3. 各モデルにおけるBICと語彙識別スコア、文法誤り識別スコアの評価結果
図 3. 各モデルにおけるBICと語彙識別スコア、文法誤り識別スコアの評価結果
次に、反復回数が3回のモデルの中で最もBICが小さい”1100-3iter”を選んでベースライン、及び前回の提案法との性能比較を行いました。図 4、図 5より、提案法は表現学習モデルの学習データサイズがベースライン、前回の提案法の1/60でありながら、どの評価指標においても最も良い性能を達成できました。
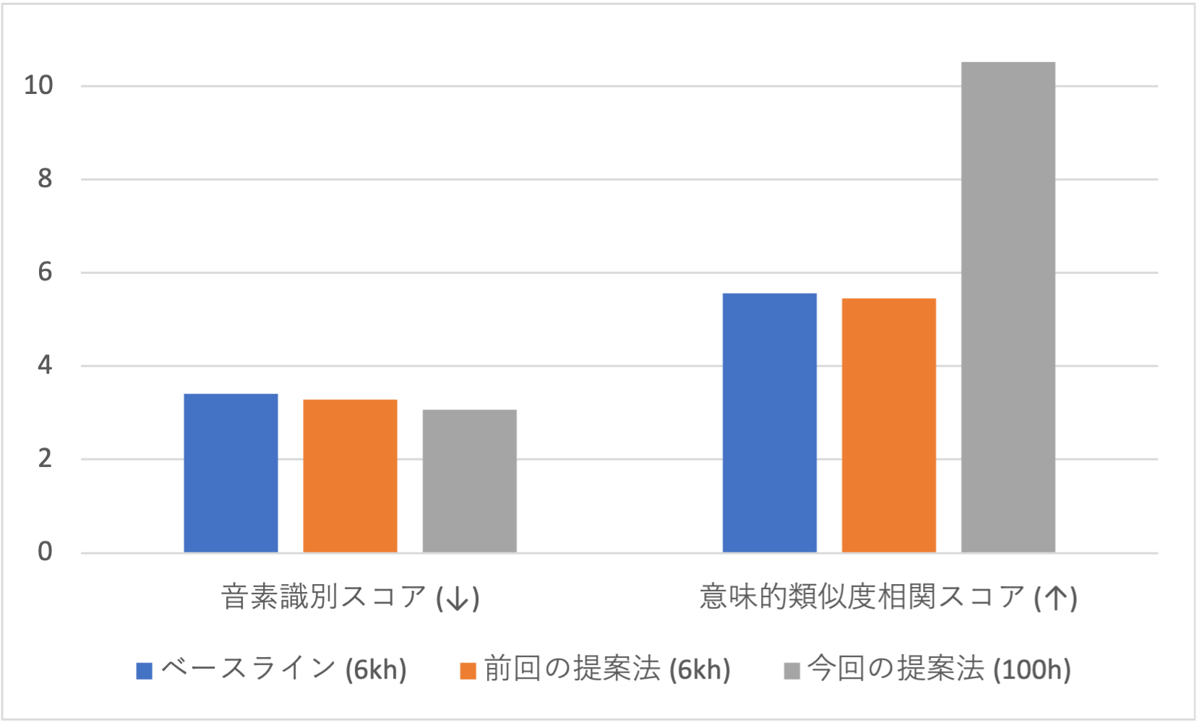 図 4. 音素識別スコアと意味的類似度相関スコア
図 4. 音素識別スコアと意味的類似度相関スコア
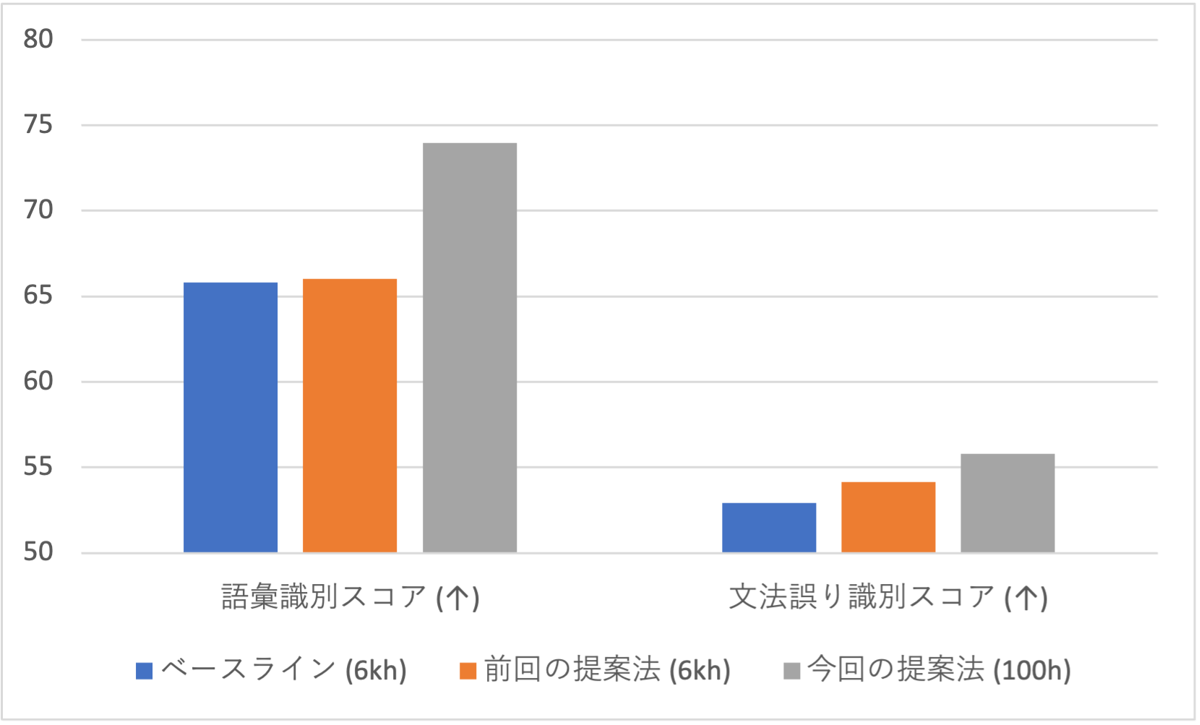 図 5. 語彙識別スコアと文法誤り識別スコア
図 5. 語彙識別スコアと文法誤り識別スコア
おわりに
今回はZeroSpeechタスクの設定において、ベースラインにHuBERTを適用して性能改善を行いました。またHuBERTの疑似ラベルのクラスタ数と学習時の反復回数を増やすことで性能上限をさらに引き上げられることを検証しました。さらに語彙識別スコアや文法誤り識別スコアにおいては、BICがモデル選択の指標となり得ることが確認できました。今後はこの知見を活かし、日本語の音声認識モデルの性能改善に取り組んでいきたいと考えています。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました
- 前角 高史
- 音声処理エンジニア



