ヤフーがリリースしたEnd-to-End(E2E)音声認識のSDKについて紹介します。E2E音声認識は、外部との通信をおこなわずにエッジデバイスで音声認識をおこなうというものです。この機能は、私たちがラボアプリとして提供している「音声検索」アプリにも導入しています。App Storeでダウンロードできますので、ご興味がある方は試していただけると幸いです(ダウンロードはこちら)。
音声認識エンジンYJVOICE
まず最初に、ヤフーが2011年から開発している音声認識エンジン「YJVOICE」について紹介します。YJVOICEは、検索や対話などの利用用途でヤフーの多くのアプリケーションに導入されており、150万語以上の語彙を出力できます。
YJVOICEは、クライアントサーバーシステムに基づきます。まず、ユーザーが発話した音声をスマートフォンで収音し、この音声を一度サーバーにアップロードし、サーバーで音声認識を動かします。サーバーで得られた結果をスマートフォンに戻すことで、ユーザーは自分が発話した音声に対応するテキストを取得できる仕組みです。
しかし、現行のYJVOICEには、「安定性」「ユーザープライバシー」「レイテンシー」の観点で、以下の3つの課題があります。
- 安定性: 通信を必要とするシステムであるので、サーバーとの通信が途絶えてしまうと、音声認識ができない
- ユーザープライバシー: 自分の音声をサーバーに送りたくないユーザーにとっては、音声認識利用のハードルがある
- レイテンシー: 通信速度が遅い環境では、音声認識の結果を得るのに時間がかかる
これらの課題を解決するために、私たちは音声認識処理をエッジデバイスで実行する「オンデバイス音声認識機能」をリリースしました。
オンデバイス音声認識はサーバーとの通信をおこなわないので、安定性やレイテンシーの問題が発生せず、サーバーに音声を送りたくないユーザーも気軽に音声認識を試せるというメリットがあります。
次に、オンデバイス音声認識を実現するために採用したE2E音声認識について紹介しますが、まずは現行のYJVOICEで採用している「DNN-HMM hybrid音声認識」について説明します。
End-to-End(E2E)音声認識
DNN-HMM hybrid音声認識
この方式では、まずマイクで収音した信号から音声認識を行うための音響特徴量を取得します。しかし、収音した信号にはユーザーが発話していない区間が含まれており、そのまま音声認識を行うと処理時間が長くなります。
そこで、音声区間検出と呼ばれる技術を用いて、音響特徴量のうち音声が発話されている区間のみを切り出し、デコーダーと呼ばれるモジュールでもっともらしいテキストを推定します。
デコーダーでテキストを推定するためには、「音響モデル」「発音辞書」「言語モデル」の3つのモデルを用います。
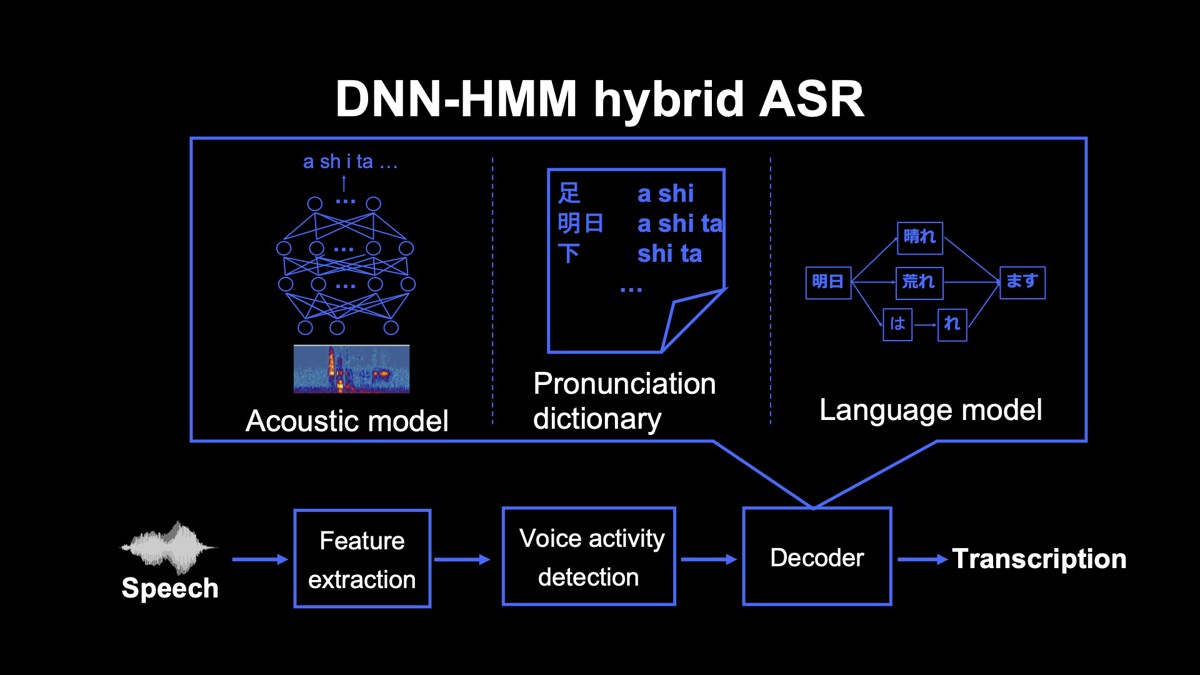
音響モデルは音響特徴量から「あ・し・た」などの音素の系列を推定し、発音辞書は音素の系列を単語の系列にマッピングします。
ここで注意が必要なのは、音素から単語への変換は必ずしも一意に定まらないという点です。音素系列をどこで区切るのかの問題もありますし、区切った単語の表記が複数存在することもありえます。そのため、ここでは複数の単語系列の候補が得られます。
言語モデルは、単語と単語のつながりやすさを測るモデルであり、複数の単語系列の中でもっともらしい系列を推定するのに用います。
DNN-HMM hybrid音声認識に必要な3つのモデルの中でも発音辞書と言語モデルは音声データを必要としないので、最新の検索クエリを用いてモデルを再学習することで、流行語に対応できます。
しかし、これらのモデルを動かすためには、多くのメモリや演算処理が必要なので、リソースが限られたエッジデバイスで動かすことが難しいという課題が残ります。
この課題を解決するために、私たちはE2E音声認識を用いて、オンデバイス音声認識を実現しました。E2E音声認識は、DNN-HMM hybrid音声認識に必要な3つのモデルを単一のニューラルネットワークに置き換えたものです。この技術は、近年の音声認識の研究分野で注目されている技術の1つで、多くの論文が国際会議で発表されています。
E2E音声認識の優れた点
E2E音声認識がDNN-HMM hybrid音声認識よりも優れている点を2つ紹介します。
1つ目はシンプルさです。DNN-HMM hybrid音声認識のシステムを開発するには、音声や言語、探索などの専門知識が必要です。そのため、モデルの学習や実装が難しい傾向があります。一方E2E音声認識は、ニューラルネットワークが主なモジュールなので、非常にシンプルな構造です。DNN-HMM hybrid音声認識に比べて比較的実装がしやすいことがメリットです。
2つ目はモデルサイズです。DNN-HMM hybrid音声認識のモデルをニューラルネットワークに置き換えることで、モデルサイズを大幅に削減できます。YJVOICEを例にすると、オンデバイス音声認識のモデルはサーバーで動かしているものと比べて100分の1程度まで削減できています。
E2E音声認識を行う主なモデル
E2E音声認識を行う主なモデルを紹介します。「Encoderに基づくモデル」「RNN Transducer」「Attentionに基づくEncoder-Decoder」の3つです。
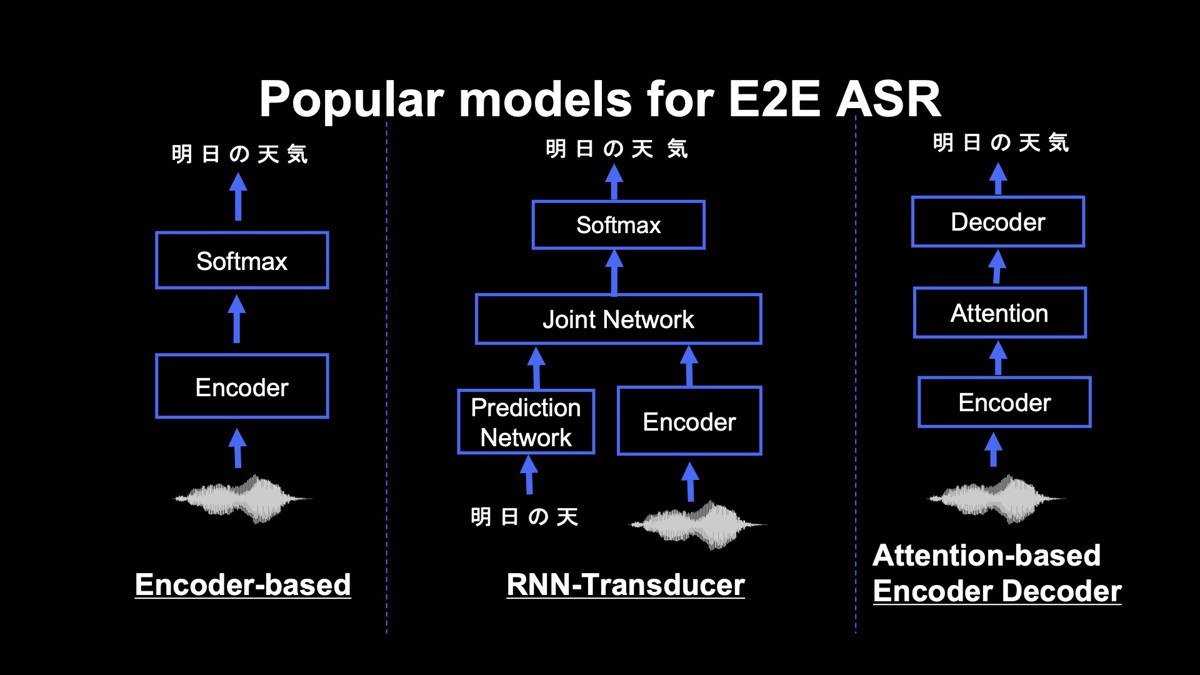
Encoderに基づくモデル
音声からEncoderと呼ばれるネットワークによって音響特徴量を推定し、テキストを推定します。主な手法として、Connectionist Temporal Classification(CTC)があります。CTCは、出力される可能性がある全ての系列の確率を計算し、もっともらしい系列を出力します。
このモデルは、発話している途中でも認識結果が得られるストリーミング処理が可能です。しかし、CTCは、出力同士の関係性を明示的に考慮しておらず、性能面での改善の余地があります。
RNN Transducer
エンコーダに基づく手法を拡張したものです。Encoderに基づく手法、特にCTCでは、出力される文字同士の関係性を明示的に考慮していないことが課題でした。RNN TransducerはPrediction networkとJoint networkと呼ばれるネットワークを利用することで、過去に出力した文字列を考慮しながら、現在の出力を推定します。そのため、Encoderに基づくモデルよりも高い精度が得られます。
このモデルのメリットは、ストリーミング処理が可能であり、さらにエンコーダに基づく方法よりも高い精度が得られる点にあります。一方、CTCよりもモデル構造が少し複雑になるので、モデルの学習や実装が難しくなります。
Attentionに基づくEncoder-Decoder
自然言語処理で広く用いられているAttentionといわれる構造を導入することで、入力された音響特徴量全体を考慮します。精度はEncoderに基づく手法やRNN Transducerよりも高くなりますが、ユーザーの発話が終了するまで認識結果が得られないので、音声対話など、リアルタイム性が求められる用途にはあまり望ましくありません。
3つのモデルの中では最も高い精度が得られますが、ストリーミング処理を実行するためには工夫が必要です。YJVOICEの利用用途としては、ストリーミング性が求められてくるので、このモデルを利用することは難しいと考えます。
以上のことを踏まえ、今年の4月にEncoderに基づくモデルを、今年の10月にRNN Transducerをそれぞれリリースしました。

E2E音声認識のSDKと関連する研究トピック
E2E音声認識のSDKを開発するにあたり、OS、実行速度、精度の3点でSLAを立てました。
OS
iOSとAndroidの両方に対応できるように実装しています。コアのライブラリをOSに依存しない形で実装し、それぞれのOSに依存するラッパーを別途用意することで、この問題に対応しました。
実行速度
リアルタイムファクター(RTF)が1.0を下回るように設定しました。RTFは認識処理の速度を表す指標で、実行処理にかかった時間を、実際の音声の長さで割った値です。例えば10秒の音声を1秒で処理できた場合、RTFは0.1です。この値が1.0未満であることを、iPhone 11 Proで確認しています。
精度
サーバー版の音声認識に近い精度を最低限の目標値としました。
下図は、各モデルの性能を示しています。縦軸は音声認識の誤り率を表したもので、下に行けば行くほど良い性能と言えます。
左からEncoderに基づくモデル、RNN Transducer、そしてサーバーで稼働しているDNN-HMMの音声認識の誤り率を示しています。最初にリリースしたEncoderに基づくモデルはDNN-HMM hybridに比べて性能差があり、およそ4.7ポイントのギャップがありました。
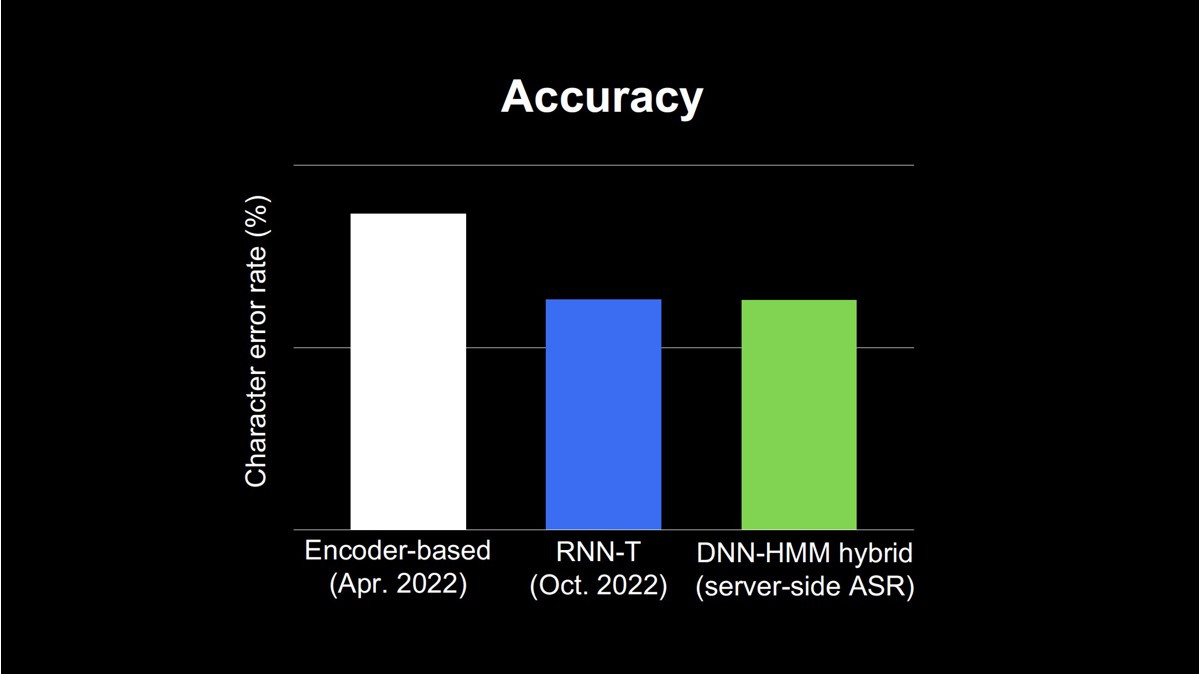
一方、RNN Transducerは、DNN-HMM hybrid形式にほぼ近い性能が得られています。このように性能面では、DNN-HMMに近いものが得られていることが確認できましたが、品質面で課題が残っています。
1つ目の課題は、E2E音声認識は学習データに含まれない語彙(未知語)の出力が難しいことです。多くのアプリケーションでヤフーの音声認識を利用するためには、流行語や住所、固有名詞などを出力できる必要があります。
2つ目の課題は、E2Eモデルの出力は表記列であり、読みの情報が得られないことです。E2Eモデルで表記と読みの情報を同時に出力できれば、東京の日本橋(にほんばし)と大阪の日本橋(にっぽんばし)のような同一表記の語彙の区別が可能となるので、ナビゲーションシステムなどへの応用が期待できます。
未知語に対する取り組み
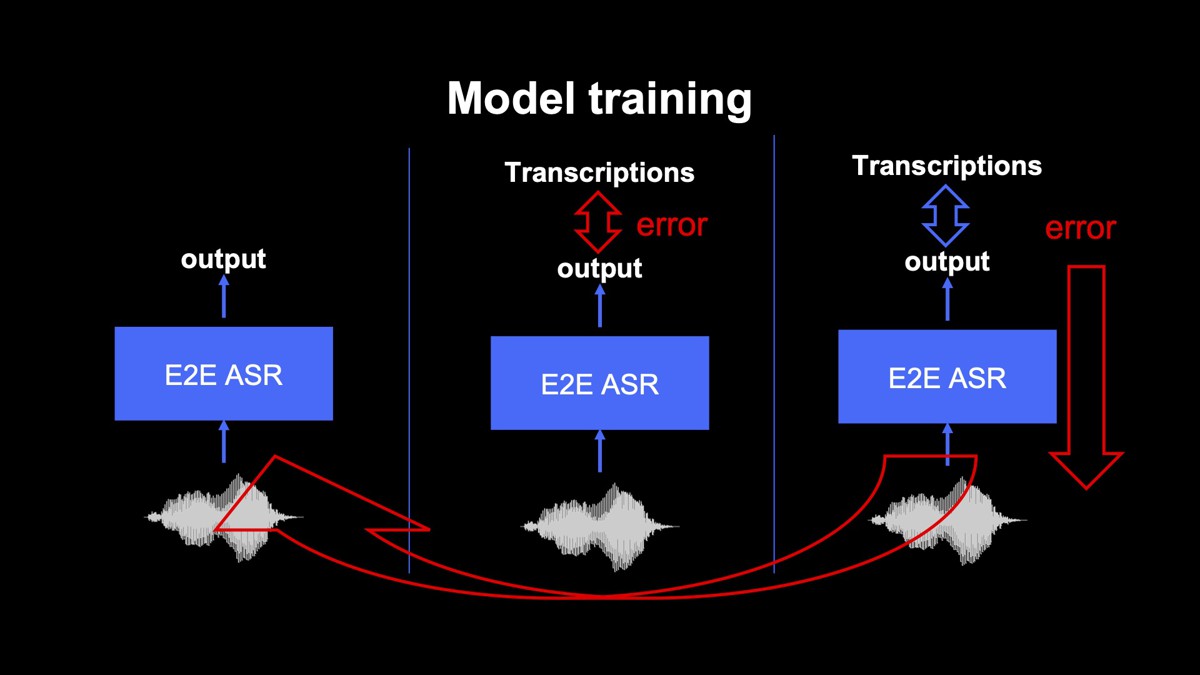
E2E音声認識のモデルの学習には、以下の3つの処理を繰り返しおこなう教師あり学習が広く用いられています。
- 学習データの中から音声を取り出し、その音声に対する認識結果をモデルで出力する
- 事前に用意した正解の書き起こしと、モデルの出力との差分を計算する
- 差分が小さくなるようにモデルのパラメータを更新する
上記の学習をおこなうことで、モデルは事前に用意した書き起こしテキストに近い結果を出力できるようになります。もし、学習データの中に最新の音声に対する書き起こしが存在しなければ、モデルが最新の流行語などを出力することは原理的に難しくなります。
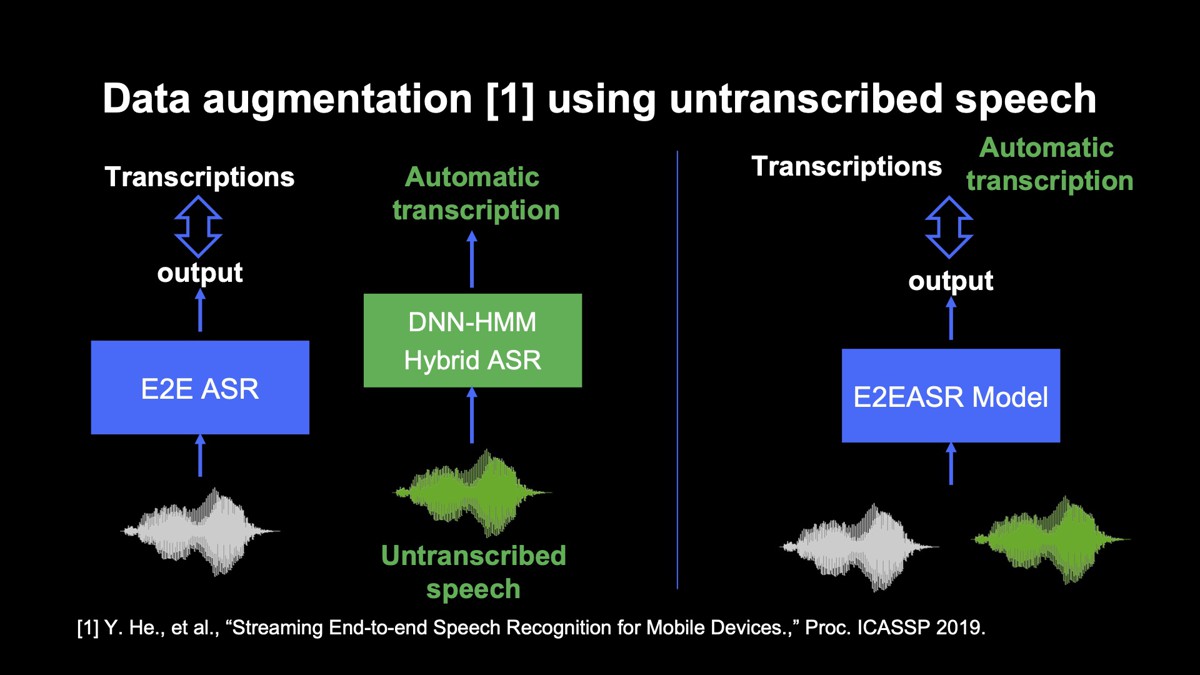
そこで、書き起こされていない音声を利用した方法を検討しています。
まず、書き起こされていない音声をDNN-HMM hybrid音声認識にかけ、音声認識結果と音声のペアのデータを取得します。
先述したように、DNN-HMM hybrid音声認識は、最新の検索クエリを含めて発音辞書、言語モデルを学習することで、直近の単語を出力できます。 この性質を利用すれば、認識結果のうち、E2E音声認識のモデルの学習データに含まれない語彙を発話した音声と、認識結果のペアを抽出できます。
そのようなペアを学習データに加えてモデルを学習することで、未知語に対するカバレッジを広げます。
書き起こしにDNN-HMM hybrid音声認識による認識結果を加えることで、未知語に対する音声認識の誤り率を19.9ポイント減らせることを確認しています。
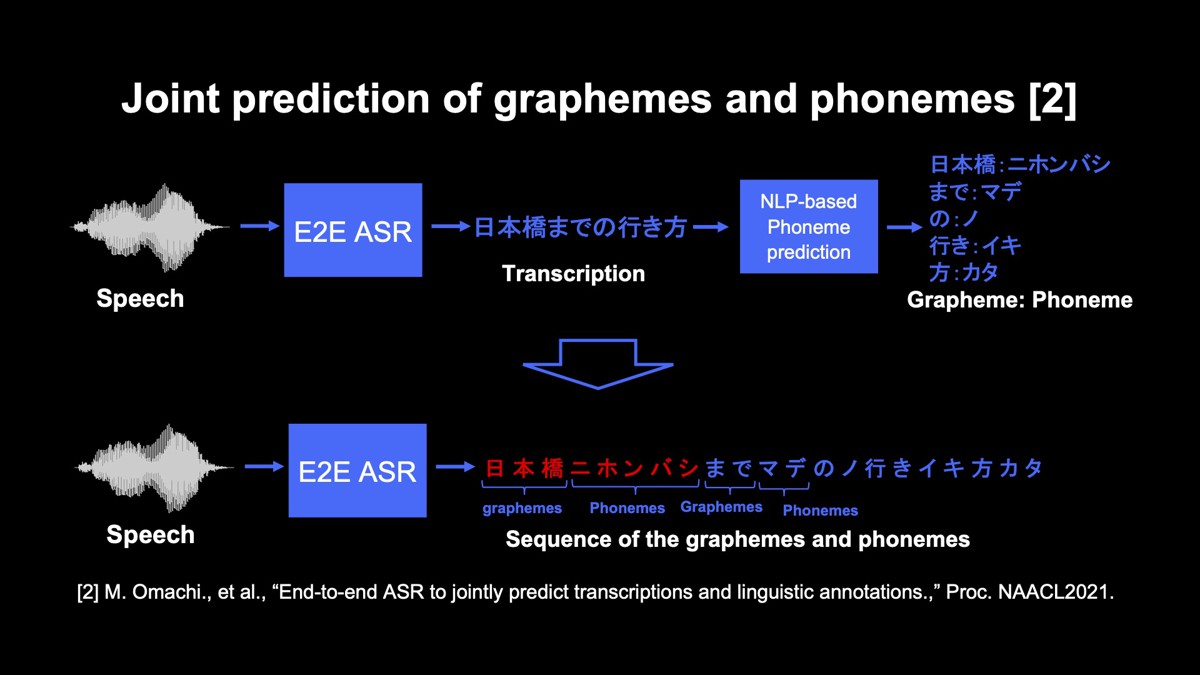
読みが推定できない問題に対する取り組み
先述したように、現在のE2E音声認識の出力は、書き起こしの表記列です。しかし、この性質は問題を起こすことがあります。例えば「日本橋までの行き方」という認識結果から、ユーザーが「日本橋(にほんばし)までの行き方」と「日本橋(にっぽんばし)までの行き方」のどちらを言ったのかを判定することは困難です。
この問題を解決するための方法として、音声認識と自然言語処理を組み合わせたパイプラインシステムが広く用いられています。この方式では、音声認識の出力に対して、自然言語処理による読み推定を適用します。

しかし、このシステムには2つの課題があります。1つ目は、音声認識に誤りが含まれていると、読み推定が失敗し、間違った読みが得られてしまうこと。2つ目は、自然言語処理のモデルを動かすためのリソースが必要なので、エッジデバイスで動かすにはあまり望ましくないということです。
そこで、E2E音声認識の出力を、単語ごとの表記と読みを並べた系列に置き換え、表記と読みを同時に推定できる方法を提案しました。この方法だと出力から表記と読みを容易に取得できます。
また、未知語の表記が間違っていても、正しい読みを取得できるので、発話内容を特定しやすくなるメリットもあります。さらに、自然言語処理を動かすための追加のメモリや、計算資源が不要です。これらの理由から、オンデバイスで動かす方法と親和性が高い方法と言えます。
この方法で認識した例を2つ紹介します。下の結果はAttentionに基づくEncoder-Decoderによるもので、モデルの学習はパブリックコーパスを利用しています。

上の例では、「ピッチとスペクトラ…、スペクトル包絡」と言い直した場合を含めた音声です。自然言語処理に基づく方法では、この言い直しの部分をうまく分割できません。一方、提案法では、音声の情報を使うことで、この言い直しの部分をうまく分割できます。
下の例は、同形異音語です。言語的な情報だけだと、「その後(ご)」なのか、「その後(あと)」なのかを特定することは難しいですが、提案法は音の情報を利用できるので、それらを一意に定めることができます。現在、この方法をRNN Transducerに応用しようと試みており、将来的にはプロダクションにおいても表記と読みを出力できるようにしたいと考えております。
その他の取り組み
その他現在取り組んでいることについて、いくつか紹介します。
まずは、自己教師あり学習、「Self-supervised learning(SSL)」です。E2E音声認識は、学習データを増やせば性能が上がっていく性質があります。しかし、そのためには音声と書き起こしのペアが必要となり、このペアを用意するためのコストがかかります。SSLは、書き起こしされていない音声を活用して音声認識のモデルを学習できるので、この方式を利用することで、より高精度なオンデバイス音声認識を、低いコストで実現できると考えています。
また、ユーザーの発話終了のタイミングから、認識結果が得られるまでのレイテンシーの改善も考慮しなくてはなりません。スマートフォンアプリへの組み込みを考えると、認識結果が得られるまでの時間を可能な限り短くする必要があります。この問題を解決するために、RNN Transducerの学習時に遅延を短くする制約を加える方法を検討しているところです。これらの取り組みに関して、ヤフーの音声チームは論文を発表しています。直近ではトップカンファレンスであるICASSP2022やINTERSPEECH2022にて3本の論文が採択されました。
最後にヤフーの研究活動について紹介すると、共同研究も含め、2020年からICASSPやINTERSPEECHなどに継続して論文が採択されています。これからも最新の音声認識技術の研究開発を行っていけるよう、チーム一丸となって努力していきます。
アーカイブ動画
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました
- 大町 基
- 音声処理エンジニア
- ヤフー独自の音声認識エンジンYJVOICEに関する研究開発をおこなっています。



