こんにちは。ヤフーの音声認識エンジン「YJVOICE」の研究開発を担当している前角です。
本稿ではヤフーにおける音声処理技術の研究開発の最新の取り組みを紹介します。今回は先日参加したThe Zero Resource Speech Challenge 2021(以下ZeroSpeech Challenge)で、ヤフーのチームが行ったモデルの性能改善手法を紹介します。
ZeroSpeech Challengeは、音声データのみ(話者ラベルも使用可)を用いた自己教師あり学習によって、言語理解がどの程度まで可能かどうかを競うコンペティションです。自己教師あり学習はデータ自身から自動的に生成された教師を用いて学習を行う手法で、自然言語処理や画像処理といったさまざまな分野で近年目覚ましい進展を遂げており、音声処理の分野においても現在ホットな研究テーマの1つとなっています。
本コンペティションでは言語理解の指標としていくつかのスコアが設定されていますが、その中の文法誤り識別スコアに関しては、testセットにおける評価においてコンペティション参加チーム中トップのスコアを達成できました。どのように取り組んだのか、その手法についてお話しします。
なお、この研究は音声処理系の難関国際会議INTERSPEECH 2021に投稿し、採択されました。
ZeroSpeech Challenge
今日の音声認識システムは、ニューラルネットワークを用いたEnd-to-End(E2E)モデルが主流となっています。ヤフーで取り組んでいるE2Eモデルについては過去に紹介した記事がありますので、こちらもご覧ください。
E2Eモデルは音声データを入力とし、それらを書き起こしたテキストデータを教師データとして1つのニューラルネットワークで学習を行うことで実現しています。E2Eモデルはタスクによっては人間に迫る音声認識性能を達成しており、近年盛んに研究されています。しかし、基本的には音声データのペアとなるテキストデータが必要であるという制約を抱えています。一般に十分な認識性能を実現するためには大量の学習データが必要になりますので、大規模な音声データを収集するだけでなく、それらを書き起こすリソースも求められます。
一方で乳幼児が言語を理解し、話せるようになるまでの過程を想像してみてください。彼らはテキストの情報に頼らなくても周囲の環境から浴びせられる音声を元に自発的に言語を習得します。よって究極的には音声データのみから音声認識器をある程度実現できるはずであると考えられます。
ZeroSpeech Challengeは、幼少期の言語学習者が利用可能な聴覚などのセンサー情報のみを用いて音声対話システムを1から学習することを最終目標として、2015年にスタートしたコンペティションです。なお、現状ではこの最終目標に到達することが困難であるため、各回で異なるタスクを設定し段階的に目標に進んでいく構成となっています。2021年の今回は、音声データのみ(話者ラベルも使用可)を用いて音声言語モデル(spoken language model: sLM)を構築し、その性能を競うというものでした(音素に関する情報を陽に与えて学習する一般的な言語モデルと区別するため、ここでは音声言語モデルと呼んでいます)。評価は以下の4つの言語的観点で行います。
- 音素的観点: "aba"や"apa"といった音声から音素を識別可能かどうか
- 語彙(ごい)的観点: “brick”と”blick”といった単語の違いを聞き分けられるかどうか
- 文法的観点: “dogs eat meat”と”dogs eats meat”のようなペアが与えられたときに文法的に正しい方を選択可能かどうか
- 意味的観点: 2単語間の意味的な類似度を求め、人間が別途与えた類似度と相関を計算
今回私たちは、Deep ClusterとConformerという2つの手法を用いてモデルの性能改善に取り組みました。
ベースライン
本コンペティションで提供されているベースラインのシステムについて説明します。
まず、表現学習を行うことによって音声をある固定次元のベクトルに変換します。表現学習とは、入力データの要素について予測問題を解かせることによって低次元の埋め込み表現を得る手法です。ここでは、音声のような系列データの表現学習を行う上でよく用いられる手法の1つであるCPC (Contrastive Predictive Coding) を使用します。CPCは、現在時刻のコンテキストと未来方向の埋め込み表現との相互情報量を最大化するように学習を行います。その後、学習済みのCPCモデルを用いて入力音声をフレームごとに固定長の特徴ベクトルに写像します。
次にk-meansを用いてこの特徴量をクラスタリングします。これにより、各フレームの特徴量を音響的に近いクラスIDで置き換えることで入力音声は離散系列に変換されます。最後にこの離散系列を入力とし、音声言語モデルを学習します。sLMのネットワークには、近年自然言語処理の分野で注目されているBERTを使用してMasked Language Modeling(マスクされた系列から元の系列を生成)のタスクのみで学習を行います。

Deep Clusterとは?
Deep Clusterは画像処理の分野で2018年にFacebookによって提案された、自己教師あり学習によって画像分類を行う手法です。まずニューラルネットワークを用いて入力画像を特徴ベクトルに変換します。次にこの特徴量をクラスタリングすることによって得られたクラスIDを疑似ラベルとして、画像の識別学習を行います。これにより教師ラベルをあらかじめ用意することなく画像分類を学習させることが可能です。
(出典:Deep Clustering for Unsupervised Learningof Visual Features)
Conformerとは?
Conformerは、2020年にGoogleによって提案されたTransformerとCNN(convolutional neural network)を組み合わせたモデルです。Transformerに内在するself-attentionは全域的なコンテキスト情報を捉えられますが、これに加えて畳み込みモジュールを用いることで局所的なコンテキスト情報も合わせて捉えることが可能です。TransformerをConformerに置き換えることにより、さまざまな音声認識タスクで認識性能が向上することが多くの研究で報告されています。

ベースラインシステムの改良
本コンペティションの評価指標の多くは識別タスクであるため、ベースラインのシステムに対して何らかの音響的な識別タスクを追加することが有益であると考えられます。これには、ベースラインのk-meansの実行時に得られるクラスIDの情報を、表現学習用のネットワークの学習時に使用することで実現できそうです。よって、前述したDeep Clusterを用いて識別タスクを追加することにしました。具体的にはCPCの特徴量をクラスタリングした後、クラスIDを疑似ラベルとして用いてCPCと同様の構成のネットワークに対して教師あり学習を行います。これにより、このネットワークの中間層から得られた特徴量が音素識別的な表現を獲得することを期待しています。この特徴量を再度k-meansでクラスタリングし、得られた離散系列を用いてベースラインと同様に音声言語モデルを学習します。

次に、ベースラインではCPCの学習時に系列予測用のネットワークとしてTransformerを用いていますが、これをConformerに変更します。こうすることで母音や子音といった局所的な音響特徴の変化をより正確に捉えることが可能になると考えられます。
実験で効果を確認
Deep Clusterを適用した手法(提案法1)とConformerを適用した手法(提案法2)、さらに2つの提案法を組み合わせた場合(提案法1+2)をベースラインと比較しました。学習データはLibriSpeechという英語のパブリックコーパスであり、評価データはLibriSpeechを含むコンペティション向けに作成されたデータセット(dev/test)を使用しています。
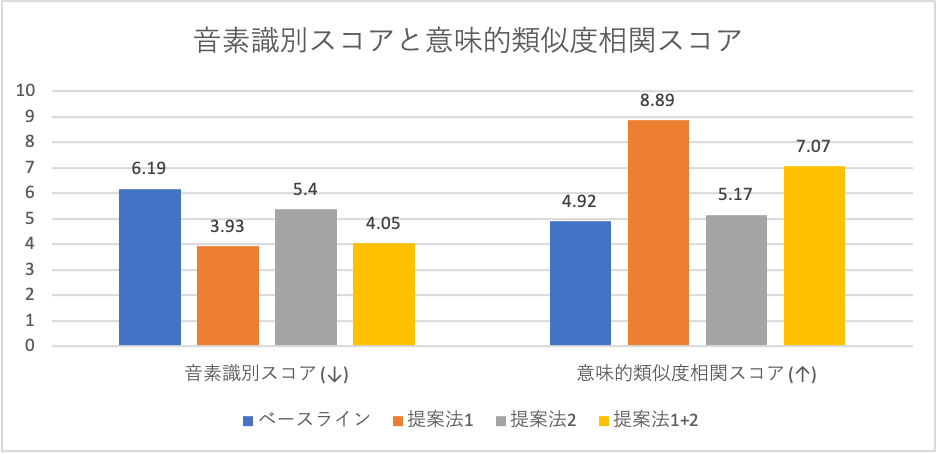
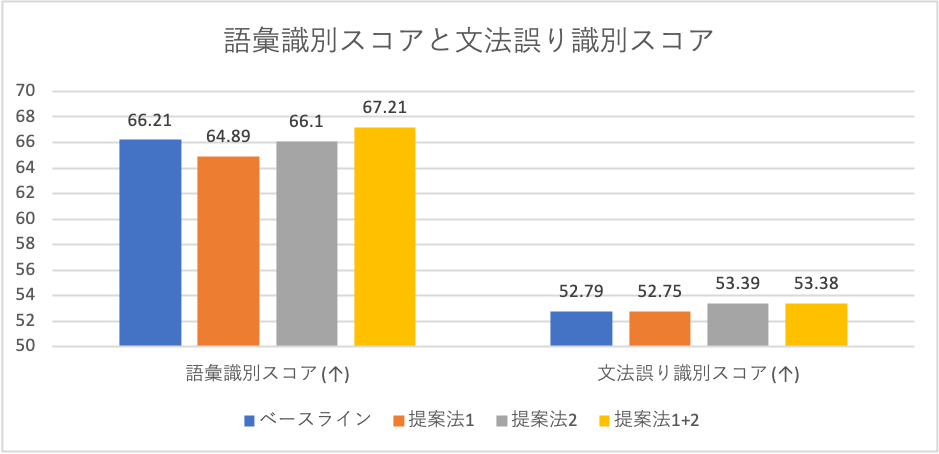
LibriSpeechから460時間分の学習データを使用した場合のdevセットにおける実験結果を以下の表に示します。結果として、さまざまな言語的観点から提案法の効果を確認できました。
- 音素識別、文法誤り識別、意味的類似度相関スコア: 提案法はいずれもベースラインの性能を上回った。
- 語彙識別スコア: 提案法単体では改善しなかったが、2つの手法を組み合わせることで相互補助的な作用が働き、ベースラインの性能を上回った。
以上の結果から、Deep ClusterやConformerが音素識別的な特徴だけでなく、より高階層の言語的特徴の学習に寄与することが確認できました。特に文法誤り識別スコアに関しては、testセットにおける評価においてコンペティション参加チーム中トップのスコアを達成できました。
おわりに
今回はZeroSpeech Challenge 2021の中で取り組んだことについてお話ししました。音声データのみを用いて音声言語モデルを構築する際にDeep ClusterやConformerといった手法を組み込むことにより、各種識別タスクで性能を向上させられました。今回このコンペティションに参加したことで得られた知見は、一般的な音声認識システムの改善にも応用が可能であると考えています。この経験を生かしてこれからもYJVOICEのさらなる性能改善に取り組んでまいります。
参考文献
- Z. Tüske, G. Saon, and B. Kingsbury, “On the limit of English conversational speech recognition,” arXiv preprint arXiv:2105.00982, 2021.
- T. A. Nguyen, M. de Seyssel, P. Rozé, M. Rivière, E. Kharitonov, A. Baevski, E. Dunbar, and E. Dupoux, “The zero resource speech benchmark 2021: Metrics and baselines for unsupervised spoken language modeling,” in NeurIPS Workshop on Self-Supervised Learning for Speech and Audio Processing, 2020.
- A. v. d. Oord, Y. Li, and O. Vinyals, “Representation learning with contrastive predictive coding,” arXiv preprint arXiv:1807.03748, 2018.
- M. Caron, P. Bojanowski, A. Joulin, and M. Douze, “Deep clustering for unsupervised learning of visual features,” in Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 132–149.
- A. Gulati, J. Qin, C.-C. Chiu, N. Parmar, Y. Zhang, J. Yu,W. Han, S. Wang, Z. Zhang, Y. Wu et al., “Conformer: Convolution-augmented transformer for speech recognition,” Proc. Interspeech 2020, pp. 5036–5040, 2020.
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました
- 前角 高史
- 音声処理エンジニア



