こんにちは、ヤフーの音声認識エンジン「YJVOICE」の研究開発を担当している藤田です。
今回のブログでは、ヤフーにおける音声認識技術の研究開発の最新の取り組みを紹介します。具体的には、前回のブログでご紹介した新しい音声認識処理を、長時間の録音にも対応可能にした研究をご紹介いたします。長時間録音に対応するためには音声区間検出という処理が必要になるのですが、1つのモデルで音声区間検出と音声認識を処理可能な手法を提案し、従来法に比べて高い精度を短い処理時間で実現しました。なお、この研究は難関国際会議INTERSPEECH 2021に投稿し、採択されました。論文はこちらで公開されていますので、詳細が気になる方はぜひご覧ください。
Non-L2R(Left-to-Right)な音声認識処理の復習
まず、前回のブログでご紹介した、non-L2Rな音声認識処理を簡単に復習したいとおもいます。従来の音声認識処理で用いられるモデルの多くは自己回帰(autoregressive, AR)モデルと呼ばれるもので、音声認識結果は左から右に(Left-to-Right, L2R)に生成されることを仮定しています。例えば、「明日の天気」という音声は、「明 → 日 → の → 天 → 気」という順番で認識処理されます。
一方で、non-L2Rな音声認識処理では、例えば「の → 明、気 → 天、日」というように複数の文字がL2Rではない順番で認識処理されます。これは、非自己回帰(non-autoregressive, NAR)モデルを利用することで実現できます。前回のブログでは、KERMITと呼ばれる挿入操作に基づくNARモデルを利用して、non-L2Rな音声認識処理を実現しました。このモデルは、認識処理の際にある程度認識結果の出力順序を制御できることが利点です。理論的にはどんな順番でも良いのですが、Balanced-Binary-Tree(BBT)という順序を利用しました。従来のL2Rを仮定したモデルだとN文字の認識処理にN回の反復が必要なのですが、このBBTだとほぼlog(N)の反復で済むという利点があります。
L2Rとnon-L2R(BBT)の処理の違いを具体的に図で書くと以下のようになります。
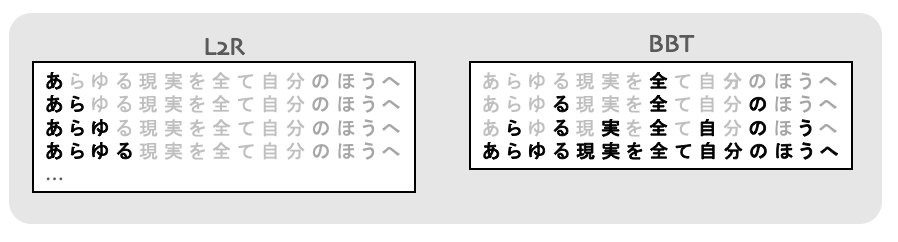
前回のブログでは、KERMITにconnectionist temporal classification(CTC)というモデルを組み合わせることで、従来のL2Rを仮定したモデルより高い精度を達成したことをご紹介しました。
Non-L2Rな音声認識の課題 〜長時間録音への対応〜
これまでの説明のように、non-L2Rな音声認識処理はL2Rなものより精度も高く、反復回数も少ないので良いことばかりのように見えますが、実応用を考えると致命的な問題があります。マイクから入力される音声を逐次処理する場合や、長時間の音声ファイルの認識処理が難しいのです。これは、モデルの構造によってはL2Rな音声認識処理でも内包する問題なのですが、全ての音声データが入力されてから認識処理を行う前提のモデルとなっていることが原因です。
マイクから入力される音声は途切れることがないので、全ての音声データの入力を待つことはできません。 また、すでに録音された音声ファイルの認識処理の場合でも、音声ファイルの長さの二乗に比例する計算量とメモリを必要とするため、 数時間の音声ファイルの処理などは現実的ではありません。
この問題を解決するためには、音声区間検出(Voice Activity Detection, VAD)という処理が必要です。これは、その名の通り音声信号の中から人の声が含まれている区間を検出する処理です。マイクからの入力音声の場合は、例えば、しばらく人の声が含まれない時間が続いたらそれまでの音声データを切り出して認識処理を行えます。長時間の音声ファイルの場合、一般的には、音声が含まれている区間は短いので、それを切り出すことで現実的な長さの複数の音声区間の認識処理で対応できます。
VADは多くの手法が存在するのですが、今回はVADと音声認識処理を1つのモデルで実現したいと考えました。スマートフォンなど計算資源の限られたデバイスでの動作を考えた時に、モデルの数は少ないほうが良いからです。
1つのモデルで長時間録音へ対応するには?
以下2つの工夫により、1つのモデルでVADと音声認識処理を実現しました。
- CTCのブランクシンボルを利用してVADを行う
- ブロック化された自己注意(self-attention)を用いる
それぞれ説明していきます。
CTCのブランクシンボルを利用したVAD
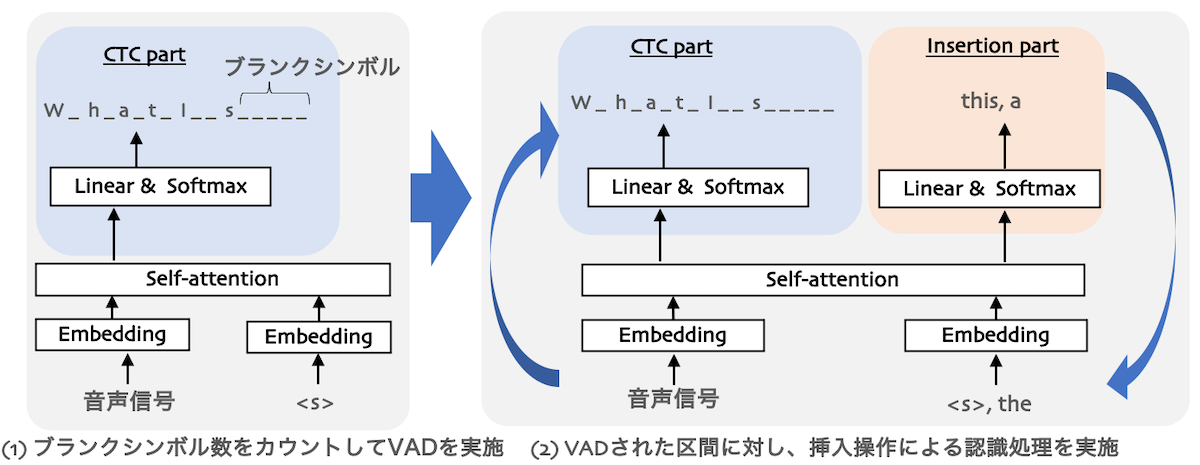
今回利用するモデルは、CTCと結合学習を行っています。詳しい説明は割愛しますが、CTCは音声認識モデルの1つであり、その特徴として、「ブランクシンボル」と呼ばれる特殊なシンボルを出力します。このブランクシンボル、色々な解釈ができるのですが、観察してみると、音声が存在しないところで出力される傾向があります。そこで、ブランクシンボルが一定数続いたら、そこを音声区間の終端とみなすVAD処理を行うことにしました。
このVADによって音声区間が定まった後、挿入操作に基づく音声認識処理を行います。これらの処理を図で書くと、以下の様になります。左側のように、入力される音声に対してCTCによる認識処理を行い、ブランクシンボル数をカウントします。ブランクシンボル数が一定数以上継続したら、音声区間を確定し、右側のように挿入操作(Insertion)による反復的な音声認識処理を行います。
ブロック化された自己注意
今回利用するモデルは自己注意(self-attention)と呼ばれる構造が含まれています。自己注意は、音声データが全て入力されないと計算ができない構造のため、部分的な音声データに対しても計算できるように構造を変更する必要があります。今回は自己注意を、あらかじめ決められたブロック幅の中で計算するようにしました(Transformer-XLで用いられている構造と似たものです)。
詳しくはこちらの入出力関係の依存の概念図を使って説明していきます。
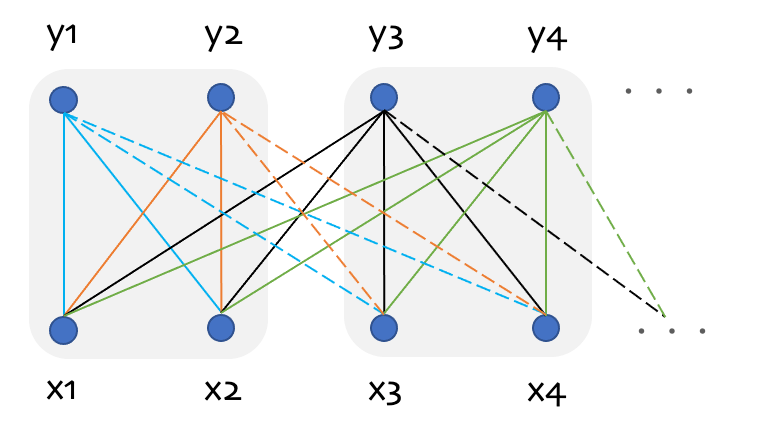
通常の自己注意の場合、例えばy3を得るためには実線・点線で接続されている入力に依存するため、x4よりも未来の入力が全て必要になります。これを、ブロック化により、一定数の未来の入力だけを利用して処理を行えるようにします。図の例だと、ブロック幅は2に設定しています。この場合、y3を得るためには実線で書かれているx4までの入力があればOKです。
これにより、逐次入力される音声に対してもブロック幅に相当する一定の時間を待つことで計算が可能ですし、長時間の音声ファイルに対しても逐次処理を行うことで現実的な計算量/メモリで処理が可能です。
実験で効果を検証
提案した手法の有効性を検証するため、Corpus of Spontaneous Japanese(CSJ)という日本語の音声データを用いて評価を行いました。従来手法としてはCTCと結合学習した自己回帰型のTransformer(ART)とCTCのみのモデルを採用しました。これらは、ブロック化された自己注意を利用すると、上記で説明したのと同様にブランク数をカウントすることで、1つのモデルでVADと音声認識処理を行えます。また、参考までに、人手でラベルづけされた音声区間で切り出した場合の精度(オラクル)と、音声認識モデルとは別のニューラルネットワークで構成されたVADモデルを用いた場合の結果も掲載しています。
評価指標は、文字誤り率(Character Error Rate, CER)とRTF(Real Time Factor)です。CERは低いほど正確に音声を文字に変換できていることを示す指標です。RTFは認識処理の速度を表す指標で、認識処理にかかった時間を実際の音声長さで割った値です。例えば、10秒の音声を5秒で処理できた場合、RTFは0.5です。
まずはオラクルです。
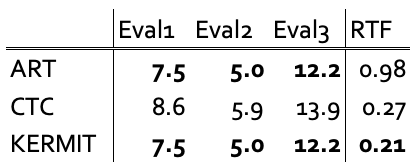
ARTとKERMITは同じCERですが、KERMITの方がRTFが低く、認識処理にかかる時間が短いことがわかります。
次に、別のVADモデルを用いた結果です。
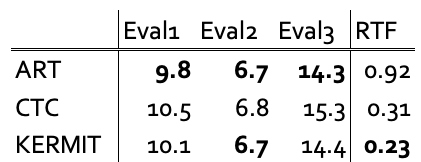
ARTの方が若干CERは良いですが、KERMITの方がRTFが低く、精度と処理時間のトレードオフの関係が見て取れます。
そして、今回提案した、VADと認識処理を1つのモデルで行った結果です。

KERMITがCERではベストでした。RTFはCTCの方が若干低いですが、KERMITは精度と処理時間のバランスが良いと考えられます。一方で、オラクルや別のVADモデルを用いた場合のCER/RTFには及んでいません。おそらく、音声区間検出に失敗して、音声が含まれない区間でも音声認識処理を行ってしまい、不要な認識結果が出力されることにより精度が低下し、処理時間が長くなっていると推測されます。
まとめ
今回は、前回のブログでご紹介した新しい音声認識処理を、逐次入力される音声や長時間の録音にも対応可能にしました。VADという処理が必要になるのですが、計算資源の限られたデバイスでの動作を考慮し、1つのモデルで音声認識処理とVADを行う手法を提案しました。日本語のデータを用いた実験では、1つのモデルで音声認識処理とVADを行う手法での比較では良い結果が得られたものの、別のVADモデルを用いた場合との精度/処理速度の差が大きいため、さらなる改良が必要と考えています。
これらの課題を解決して従来よりも処理時間が短く精度の高い音声認識エンジンの実現を目指します。
(この記事に関連する採用情報「音声認識エンジニア・研究員」もぜひご覧ください)
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました
- 藤田 悠哉
- エンジニア



