シュティフ ロマン(データプラットフォーム), Apache Igniteコミッター @rshtykh
Apache Igniteは、Apache Sparkと同様にインメモリ技術を活用した高耐障害性分散データ処理プラットフォームです。
しかし、Apache Sparkは非トランザクション(バッチ)的な分析を処理の対象をしている一方、Apache Igniteはリアルタイム処理に優れ、非トランザクションとACIDトランザクション的な処理を両方サポートします。
この2つのプラットフォームを組み合わせて使うことには大きなメリットがあり、2つの統合のための機能がApache Igniteには早期開発段階から導入されました。
本稿では、Apache Ignite + Apache Sparkの統合はどういう風に実現されたか、既にSparkを使ってデータ処理を行うシステムへIgnite導入のメリットについて説明します。
はじめに
Apache Ignite(以下、Ignite)は、メモリを中心に据えた分散データベース・キャッシュ・コンピュートといった複数の機能を備えたプラットフォームです。インメモリ技術を活かし高パフォーマンスストレージだけではなく、多機能且つリアルタイム性の高い分散処理を提供しており、ヤフーをはじめ[1]American Airlines[2], ING[3], 24 Hour Fitness[4]等に採用されています。(機能や特徴については、[5]を参照してください)
Apache Ignite以外にもインメモリ技術を活用したプラットフォームはいくつかあります。そのなかでもApache Spark[6] (以下、Spark)は、RDD(Resilient Distributed Dataset)コンセプトを開発し、Hadoopの処理能力のボトルネックを解消した有名なインメモリデータ処理エンジンです。SparkはIgniteのようにデータを分散させほとんどのコンピュート処理はメモリ上で行い、高度な機械学習やインタラクティブなアドホッククエリーのような
複数のステップにわたる高速な処理を実現可能としています。加えて、関係データモデルや手続き型APIを提供し、ユーザーの利便性を考慮してそれらを柔軟に組み合わせることができるので、非トランザクション的な分析によく使われるプラットフォームです。
一方、Igniteはリアルタイム処理に優れ、大量データに対して非トランザクションとACIDトランザクション的な処理を両方サポートします。
二つのプラットフォーム統合の大きな有用性があるため、Igniteには早期開発段階(バージョン1.2.0)からshared RDDが実装され、2.4.0からDataFrameサポートも導入されました。
この統合により、既にSparkを使ってデータ処理を行うシステムにとって以下のようなメリットがあります。
- Sparkワーカー間の迅速かつ容易なステートシェアリングができ、複雑なデータ処理実現の際にボトルネックになりそうなファイルシステムへのデータオフロードを避けれます。
- データ移動の最小化やインデックス利用でSpark SQLのパフォーマンス向上を達成できます。
- そして、SQLを利用し同じデータストアに対してIgniteの得意なリアルタイム処理機能やSparkのOLAP・機械学習機能のオーバヘッドの少ない多様なデータ処理ができます。
以下は、IgniteとSparkのインテグレーションやその利用について説明します。
共用RDD
RDDはSparkに於けるコアなデータ抽象です。RDDにより並列処理を可能とするデータの分割や分散を隠蔽し、ユーザーに高度なAPIを提供することができます。IgniteはRDDインターフェースを実装しているため、Sparkのバックエンドとして使うことが可能です。例えば以下のように、RDD APIをそのまま利用できます。
// Ignite Shared RDD
val sharedRDD: IgniteRDD[String, MyType] = igniteContext.fromCache[String, MyType]("myCache")
// some transformations
sharedRDD.map(x => ...).filter(...).map(...)また、不変のデータ構造であるSparkのネイティブRDDと違って、IgniteRDDは複数のSparkタスクに共有され(図1参照)、ファイルシステムにRDD内容を書き出すことなくステートシェアリングが容易にできます。あるアプリケーションの処理によるデータに対する変更はあった場合、その変更は即時に他のアプリケーションに共有できます。それにより複雑な処理のパイプラインで必要な出力はなくなりさらに高速なデータ処理の実装は可能です。
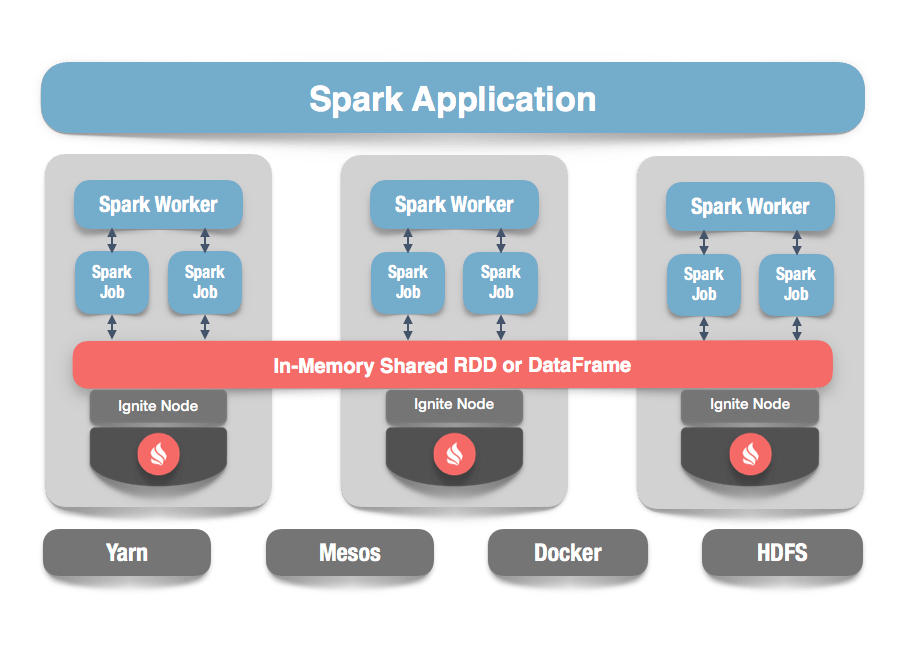
図1. Ignite + Sparkインテグレーション
そして、処理において生じうる不必要なデータ移動を防ぐためにRDD <- Igniteパティーションマッピングが行われSparkのDAGSchedulerにデータロケーション情報が伝わりデータロカリティ(どのノードにデータが存在するか)を考慮した並列処理が行われます。
DataFrameサポート
Sparkに限らず、データ分析にはSQLがデファクト標準言語となっています。Sparkでは、関係クエリーはSQL或いはDataSet APIで発行可能です。そして、クエリー対象は、Spark SQLの主なデータ抽象である、スキーマ(概念的にRDBのテーブルに相当)を持った構造化データをあらわすDataset(DataFrame)です。
Igniteは、DataFrameを拡張し、Igniteがストレージに用いられることを可能としています。IgniteSparkSessionを利用し、テーブル、ビュー、関数などのメターデータを管理するcatalogに登録しそれへのアクセスを透過的かつ迅速に行われるようにしています。
それにより、長期的ストレージを持たないSparkに高速なIgniteからのデータロードやオフロード機能を与えて(RDDと同じく)Sparkワーカーに跨ったステートシェアリングが可能となります。
以下は、IgniteクラスターにあるUser型データに対するクエリーのサンプルです。詳しくは[7]参照
// Define the schema
case class User(id UUID, name: String, city: String, age: Int)
// import data (for instance) via Ignite data streamer or load with SQL
...
// read data
val userDF = spark.read.format(IgniteDataFrameSettings.FORMAT_IGNITE) //Data source type.
.option(IgniteDataFrameSettings.OPTION_TABLE, "USER") //Table to read.
.option(IgniteDataFrameSettings.OPTION_CONFIG_FILE, "path_to_ignite_config") //Ignite config.
.load()
// register as a temporary view in catalog
userDF.createOrReplaceTempView("usertable")
// query
spark.sql("SELECT name, city, age FROM usertable WHERE city='Osaka' AND age>20").showSpark SQLはCatalystクエリーオプティマイザに生成された論理プランを、複数の最適化を通り物理プランにします。最適化の段階でpredicate pushdownやJOIN仕方の変更のようなルールベースやコストベースの最適化をプランに適用します。
Igniteクラスターのデータに対してクエリーが行われるとき、全テーブルはIgniteにある場合、Ignite側で実装されたextraOptimizationsであるIgniteOptimizationにより最適化が行われます。これにより全処理はIgniteクエリーエンジンにて行われ、データ移動を最低限にしてより効率の高いクエリー実行が実現できます。
具体的に、論理オペレーターのツリーである論理クエリープランの構築に使われるLogicalPlanをスキャンしそのオペレーターをなるべくIgniteのQueryAccumulatorに追加します。追加できたらIgniteにて処理が可能であることで論理プランから取り除かれます。QueryAccumulatorで集まった情報に基づいてSQLクエリーを作成します。
この最適化が不要な場合、ignite.disableSparkSQLOptimizationオプションをtrueにして無効にすることもできます。
Igniteデータベースのインデックスの活用
Sparkはストレージを持たない分散処理フレームワークです。一般的にディスクを用いたストレージからデータをロードし、処理終了次第そのデータを破棄・保存します。そのため、Spark SQLはクエリーの最適化行いますが、どうしてもインデックスを要しているクエリーには、ORCやParquetのようなインデックスをサポートする形式のデータへのアクセスが必要となります。
一方、Igniteはそのものでインデックスをサポートしているので、Sparkとの統合によりインデックスの活用もできクエリーの大きな高速化が可能となります(1,000xの高速化の報告も見られます)。
ユースケース
IgniteとSparkを組み合わせた活用例として、[8]では紹介されたユースケースは上記を活用し株価予測を実現しています。
Sparkの高度なストリーミング機能を利用しデータ分析を行って処理結果をIgniteデータベースで持つことにしています。そして結果はTableau[9]で参照します。詳しくは、[8]を参照してください。
また、他のユースケースやIgnite + Sparkインテグレーションについては、[10-12]を参照してください。
最後に
本稿では大規模データ処理システムではIgniteとSparkの組み合わせでどのようなメリットを得ることができるか解説しました。
Ignite導入により既にSparkを使ってデータ処理を行うシステムでSparkワーカー間のステートシェアリングやSQLのパフォーマンス向上などは実現できますが、Ignite利用者にもSparkを使うメリットはあります。その一つは、Sparkが提供する高度なストリーム処理です。Igniteは高速なデータストリーミングの機能を実装していますが、ベーシックなものであってSparkのマッピングやフィルタリングを使ってより高度なストリーム処理が実現できます。
最後になりますが、IgniteとSparkの設定方法は[13]を参照できます。
参考URL
- 'Recent purchases' with Apache Ignite, https://techblog.yahoo.co.jp/oss/yahoo_shopping_purchases_ignite/
- American Airlines, https://www.americanairlines.jp
- ING, https://www.ing.com
- 24 Hour Fitness, https://www.24hourfitness.com
- Apache Ignite, https://ignite.apache.org
- Apache Spark, https://spark.apache.org
- DataFrameサンプル, https://github.com/apache/ignite/blob/master/examples/src/main/spark/org/apache/ignite/examples/spark/IgniteDataFrameExample.scala
- When One Minute Can Cost You a Million: Predicting Share Prices in Real-Time with Apache Spark and Apache Ignite, https://www.imcsummit.org/2018/eu/session/when-one-minute-can-cost-you-million-predicting-share-prices-real-time-apache-spark-and
- Tableau, https://www.tableau.com
- Apache Spark and Apache Ignite: Where Fast Data Meets the IoT, https://www.imcsummit.org/2017/us/sessions/apache-spark-and-apache-ignite-where-fast-data-meets-iot
- Breakout: Shared In-Memory RDDs - Missing Link in Spark, https://www.imcsummit.org/2016/videos-and-slides/shared-in-memory-rdds-missing-link-in-spark/
- Apache Ignite -- Using a Memory Grid for Distributed Computation Frameworks (Spark and Containerized Apps), https://www.imcsummit.org/2018/us/session/apache-ignite-using-memory-grid-distributed-computation-frameworks-spark-and-containerized
- Apache Igniteインストールやデプロイ, https://apacheignite-fs.readme.io/docs/installation-deployment
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました



