Apache Ignite導入の体験レポート
Roman Shtykh (Data and Science Solutions Group, Apache Ignite committer) @rshtykh
Toru Yabuki(Shopping Services Group, Commerce Company)
Yahoo!ショッピングは、ユーザが買い物を楽しむために様々なサービスを提供する日本最大級のEコマースプラットフォームです。本稿では、Apache Igniteを用いて、階層を持つカテゴリーなどで絞り込みながらたった今売れた商品を取得できるサービスを刷新した事例を紹介します。スケールアウトするApache Igniteを採用することで既存のRDBMSでの性能上の制約を解消し、同時にシステムをシンプルにできました。
Yahoo! JAPAN is one of the largest e-commerce platforms in Japan, and we are constantly working on improving users' shopping experience from attempts to understand their needs and behaviors and applying that knowledge to provide better shopping experience. We have a large number of services and APIs for that, and as the number of requests to them is growing (due to release of new services, or increase of calls from numerous microservices) we have to be able to scale accordingly and guarantee sub-second data access.
One of the services with a high demand for being able to process tens of thousands requests per second and grow in near future is 'Recent purchases.' Querying the service for such purchases provides you the latest n items by particular categories in a specified depth. Originally, the data was stored in RDBMS and reached 500+ million records, and the old DB infrastructure couldn't cope with increasing number of requests and prevented the service adoption by other users. That now was the time to renovate the DB to meet higher demand from users.

Figure 1. Legacy system's hight-level architecture.
And for choosing the solution to go we had several things to consider:
- the service relied on
memcachedto improve the speed of API responses but had operating costs issues we wanted to cut but get the same/similar responsiveness of the service; - scaling to the growing number of queries;
- being able to scale when data size grows. Having more services querying 'recent purchases' API will likely increase the demand for new functionalities, that in turn will most likely result in having us store more data;
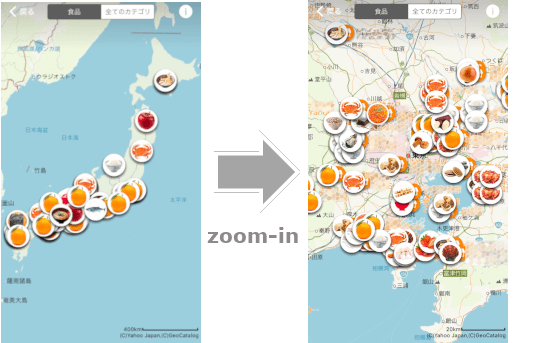
「出典:ヤフーショッピングの買い物マップ」
Figure 2. An example of the service use. Map for recently sold products around Japan by 'grocery' category.
In search for such a solution we had a POC and multiple tests with Apache Ignite (hereinafter Ignite) -- "a memory-centric distributed database, caching, and processing platform" [1] that is known for its cluster elasticity and SQL support. This database platform fully met the requirements, and also we had some previous working experience with Ignite[2,3] that helped much to quickly roll out the solution in production.
With Ignite we have removed memcached, which had a role of a look-aside cache with somewhat outdated results and would have further quite eroded benefits, had we invalidate entries in a fast manner, not mentioning about operation costs. At the same time, we haven't lost responsiveness of the service, and even made some gains in it.
The system architecture is quite simple. We have purchase events coming via Kafka brokers, which are injected into Ignite cluster after going through transformations. Recent purchases are searched in categories and with several conditions, hence SQL flexibility of queries is needed. Apache Ignite provides ANSI-99 SQL support [4] having all DML commands and providing a subset of DDL commands relevant for distributed systems. Data can be queried with SQL API of native libraries but we have chosen to go with thin clients, since they do not require a standard topology join and therefore easier to be handled through container services. With the release of Apache Ignite 2.7, Python, Node.js, PHP and C++ thin clients are available[5], and switching our legacy code to query Ignite was relatively easy. As early adopters of Node.js client, we have even managed to work with it and help to fix issues[6].

Figure 3. Hight-level architecture with Apache Ignite.
Don't expect your SQL queries being fast just because your data is in-memory. When it comes to queries, map-reduce is done through the cluster and data must be properly indexed and organized (especially if you need affinity). We tuned our queries with query hints for, depending on resulting data set, some queries worked best hitting particular secondary indices but some queries work better with other group indices or just scanning records in memory. Some care had to be done not to offload too much data to the heap that would slow down the processing significantly. As a result, all our queries have a low heap use, very low CPU and I/O consumption.
From operation perspective, we have found that Ignite is
- Very easy to scale out
- Having a rich set of APIs that can be used for building monitoring tools
- Having multiple connectors enabling easy data injection [7]
But - SQL query metrics are still immature but being gradually improved
- In comparison to other major database systems like Cassandra or MySQL, no rolling upgrade is supported, and we will need to go through blue-green deployment in future.
In general, we have a good experience with Apache Ignite, and, in addition to using its SQL functionalities, also have plans to consider it for distributed compute-intensive tasks.
References
[1] What is Ignite? https://apacheignite.readme.io/docs
[2] Apache Igniteとのインメモリーコンピューティング https://ameblo.jp/principia-ca/entry-12124166753.html
[3] Apache Igniteを分散キャッシュに利用したシステム負荷軽減 https://developers.cyberagent.co.jp/blog/archives/1799/
[4] SQL Conformance https://apacheignite-sql.readme.io/docs/sql-conformance
[5] Thin client features https://cwiki.apache.org/confluence/display/IGNITE/Thin+clients+features
[6] Node.js large payloads issue https://issues.apache.org/jira/browse/IGNITE-9382
[7] Streaming Integrations https://apacheignite-mix.readme.io/docs/getting-started#section-streaming-integrations
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました



