本記事は前編に続いて出張報告の後編です。後編はデータプラットフォーム本部の浅沼が担当します。この記事ではMeetUpの様子と、MeetUpで発表があった新機能のRouter-based Federationについて詳しく紹介します。
MeetUpの様子
今回のMeetUpはシリコンバレーにあるLinkedInのオフィスで開催されました。シリコンバレーでは南北にわたってフリーウェイと呼ばれる無料の高速道路が伸びています。片道5車線もあるのですが、通勤ラッシュ時は渋滞になるほど大量の車が引っ切り無しに走っています。ホテルからLinkedInのオフィスまで結構離れていたのですが、この道路のおかげで数十分でたどり着くことができました。(前編を担当した鯵坂が全部運転してくれました)
LinkedInの広い敷地の中には4, 5階建のビルが何個かあり、移動のために誰でも乗って良い自転車がたくさん置いてありました。会社というよりは大学のキャンパスのような自由な雰囲気でした。

Hadoop Contributors Meetupの看板
MeetUpにはさまざまな企業のエンジニアが参加していました。午前から午後までセッションが盛りだくさんのMeetUpでしたが、休憩時間でもみんな活発に議論していました。会社が違ってもフレンドリーにディスカッションしているのが印象的で、シリコンバレーで働くエンジニア同士のネットワークの強さを感じました。

Hadoop Contributors Meetupの会場
Router-based Federationについて
今回のMeetUpで一番聞きたかったのがRouter-based Federation(以下RBF)というHDFSの新機能に関する発表です。ここから少し技術よりな話になりますが、RBFについて説明します。
既存のHDFSの課題
Hadoopの分散ファイルシステムであるHDFSは、1台のマスターサーバーであるNameNodeが全てのメタデータをメモリ上に保持しています。
そのためHDFSのスケーラビリティはNameNodeのメモリサイズに依存します。
NameNodeのメモリの使用量が数百GBを超えるとGCの影響が無視できなくなり、
たとえ高性能なマシンでNameNodeを稼働させても、1つのクラスタのサイズは数千台(データ量は数十PB)が限界です。
それ以上のデータを保存する場合は別のNameNodeが必要となり、複数のクラスタが必要となります。ただしクラスタの数が増えると、クラスタごとの設定・管理が必要となるため、クライアントにとって扱いづらくなります。複数のクラスタをまとめ、クライアントから見て1つの大きなクラスタとして扱えるようにしたいというニーズがあります。
RBFの登場
Router-based Federationとは、RouterとState Storeから構成されるフェデレーション層を導入することで、クライアント側からNameNodeが隠蔽され、複数のクラスタを1つの大きなクラスタのように扱うことができる機能です。
Routerとはクライアントのリクエストを適切なNameNodeへルーティングするプロキシサーバーです。State Storeは共通のマウントテーブル(どのディレクトリパスがどのクラスタに対応するか)を一元管理します。
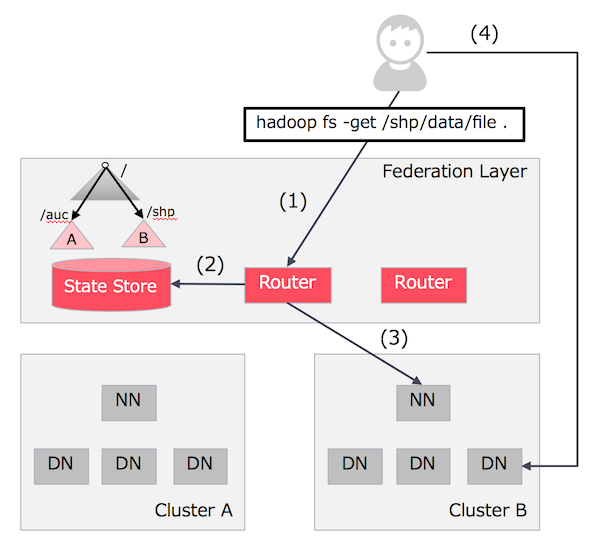
Router-based Federationの処理の流れ
上の図を例に処理の流れを説明します。Routerはクライアントからリクエストを受け取ると(1)、State Storeのマウントテーブルを参照し(2)、リクエスト先のディレクトリパスに対応したクラスタのNameNodeにルーティングします(3)。クライアントのリクエストは適切なDataNodeにリダイレクトされ、データの参照・作成を行います(4)。図の例では/shp配下のパスにアクセスしているので、クラスタBにリダイレクトされています。
弊社のHadoopクラスタも年々データ量が増加しているためRBFに注目しており、これまでもさまざまな調査や安定化のためのOSS貢献を行ってきました。
RBFのセキュリティと導入に向けて
RBFの基本的な機能の実装は完了しているのですが、Kerberos認証によるセキュリティ機能の実装が未完了で、現在もHadoopコミュニティで開発中です。Kerberos認証とはユーザーを区別するためのセキュリティの機能で、マルチテナントなHadoop環境を実現するためには必須の技術です。弊社のHadoopクラスタでも昔からKerberos認証を有効にしており、RBFを導入するにあたってKerberos認証のサポートが必須です。Kerberos認証のサポートの実装方針やスケジュールについて、MeetUpで情報共有してもらうことが今回の出張の大きな目的でした。
MeetUpのRBFセキュリティの発表
MeetUpの話に戻ります。RBFの開発者の方も数名参加しており、休憩時間にディスカッションすることができました。弊社の事情を話すと、MicrosoftやUberのHadoopクラスタでもKerberos認証をサポートしたRBFを使用する計画があり、実装のスケジュール感を共有してもらえました。
このディスカッションの直後にUberによるRBFセキュリティの発表が行われたのですが、
「Yahoo! JAPANもこの機能に興味を持っているそうです」と弊社のことも紹介してくれました。今後もより一層開発やフィードバックなどの貢献ができるように頑張りたいと思います。
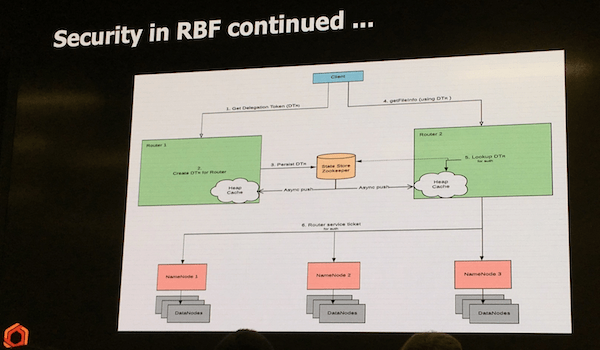
UberによるRBFセキュリティのアーキテクチャーの図
Uberの発表ではデリゲーショントークンをどのように扱うかについて述べられていました。デリゲーショントークンとはHadoop独自の実装で、Kerberosの認証情報をトークンに委譲し、その後の認証処理を低コストに行える仕組みです。上の図によるとデリゲーショントークンをState Storeに保存して、複数のRouterで共用するシンプルな実装になっているようです。
まとめ
普段は顔が見えない状態でやりとりしている現地の開発者の方々と直接コミュニケーションを取り、RBFのセキュリティに関する実装方針やスケジュール感を聞くことができて、非常に収穫の大きい出張だったと思います。弊社のHadoopクラスタにRBFを導入する見通しをつけることができそうです。また実はこれが私にとって初めての海外出張だったのですが、西海岸の生活を肌で感じることができ、いちエンジニアとしても大変貴重な経験になりました。
Hadoop/Spark Conference Japan 2019について
最後に1つお知らせをさせてください。日本でも来月の2019年3月14日に、日本Hadoopユーザー会の主催によるHadoop/Spark Conference Japan 2019が開催されます。Hadoop/Sparkやそれにまつわるエコシステムの事例紹介や技術紹介が行われます。前編を担当した鯵坂と私も登壇させていただき、Hadoopの将来像やここで紹介したRBFを含めたHDFSの最新機能について発表させていただきます。ぜひご参加ください!
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました



