こんにちは、ヤフー独自の音声認識エンジン「YJVOICE」の研究開発を担当している大町です。
今回は前回のブログで紹介した音声認識手法の実行時間を削減するための枠組みをご紹介します。この手法は、信号処理分野のトップカンファレンスICASSP2022(2022 IEEE International Conference on Acoustics, Speech and Signal Processing)で発表しました。
ユーザーの意図を汲める音声認識とは(前回のブログのおさらい)
今回のお話に入る前に、前回のブログで紹介した音声認識の手法を復習したいと思います。
音声認識の研究分野では、ユーザーが話した声から発話内容の文字列を一つのニューラルネットワークで推定するEnd-to-End(E2E)音声認識が注目を浴びています。しかし、現在提案されている多くのE2E音声認識では、発話内容の表記しか出力していないため、出力結果からユーザーの発話意図を汲み取ることが難しいという課題があります。
例えば、音声認識の出力が「日本橋」という文字列であったとき、ユーザーの意図した発話が「にほんばし(東京の地名)」と「にっぽんばし(大阪の地名)」のどちらなのかを特定できません。Yahoo!カーナビやYahoo!乗換案内で音声入力をした際に、意図しない場所を案内されてしまうのは困ります。そこで前回のブログでは、E2E音声認識で、表記だけでなく読みや品詞などの素性を同時に推定する手法を提案しました。
モデルとしては、connectionist temporal classification(CTC)とTransformerを組み合わせたモデルを採用しています。CTCは、出力されるシンボル(例えば、文字)が互いに独立(無関係)であるという仮定のもと、音声が与えられた際の事後確率が最も高くなるようなシンボル系列を推定するモデルです。しかし、表記と素性は関係がないとは必ずしもいえないため、それらを同時に推定する場合にCTCを用いるのはふさわしくありません。
一方、Transformerは出力されるシンボルの関係性を考慮できるモデルであるので、表記と素性を同時に推定するのに適したモデルであるといえます。CTCとTransformerを組み合わせたモデルは、E2E音声認識で高い性能が得られることが知られています。前回のブログでは、このTransformerとCTCを組み合わせたモデルを用いることで、音声認識本来の性能を許容範囲で担保しつつ、素性を十分な精度で抽出可能であることを示しました。
今回のブログでは、性能を許容範囲で担保しつつ実行時間を削減する方法を紹介
前回のブログではご紹介できませんでしたが、E2E音声認識で表記と読みを同時推定するときには、実行時間と性能のトレードオフの関係を考慮する必要があります。以下の図を使って、具体的にご説明します。
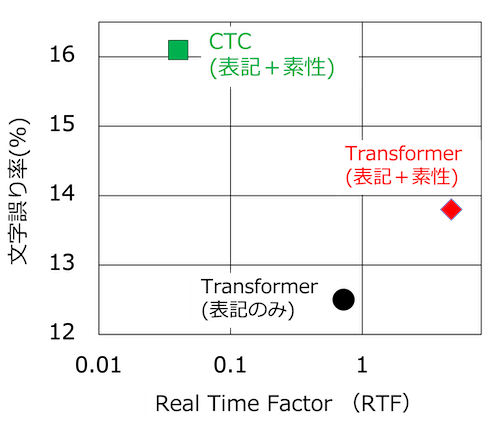
こちらの図は、TransformerとCTCを用いて表記と素性を同時に推定したときの実行速度と音声認識性能の関係を示しています。比較として、Transformerで表記だけを推定した場合の結果も示しています。横軸は、音声認識の実行時間に関する尺度(Real time Factor, RTF)で、縦軸は音声認識の性能を測る尺度(文字誤り率)です。RTFは、音声認識にかかった実行時間を入力した音声の長さで割ったもので、小さければ実行時間が短いことを示しています。
Transformerで表記と素性を推定したモデル(Transformer(表記+素性))の実行時間は、表記のみを推定したモデル(Transformer(表記のみ))の5倍以上増加するものの、性能劣化は1ポイント程度にとどまります。 一方、CTCで表記と素性を同時推定したモデル(CTC(表記+素性))の実行時間は表記のみを推定したモデルの1/10以下ですが、性能は4ポイント程度劣化してしまいます。
そこで、今回は、性能を担保しつつ短い実行時間で表記と素性を同時に推定するE2E音声認識を実現する手法を検討しました。
非自己回帰モデルで実行時間を削減しつつ性能劣化を抑える
現在提案されているE2E音声認識を実現するモデルは、自己回帰(Autoregressive, AR)モデルと非自己回帰(Non-autoregressive, NAR)モデルに分類できます。前節で紹介したTransformerはARモデル、CTCはNARモデルに分類されます。
ARモデルは、過去の出力に基づき現在の出力が決定されるという仮定に基づくため、N個のシンボルを出力するにはN回の反復計算が必要です。一方、NARモデルは、出力の順序を考慮しないため、一度の計算で複数の出力を得ることができ、ARモデルと比べると少ない反復計算で音声認識が可能になります。そこで本研究では、NARモデル(具体的には、樋口氏らにより提案されたMask-CTCと呼ばれるモデル)を基に、表記と素性を同時に推定する方法を検討しました。
ここで、以下の図を使って、Mask-CTCと呼ばれる方法を簡単に説明します。詳細は、原論文(外部サイト)をご参照ください。
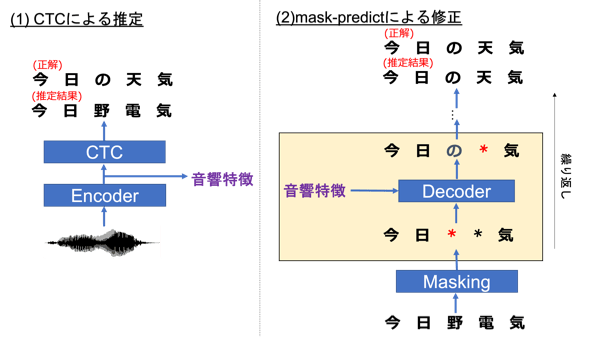
Mask-CTCでは、まず、Encoderを用いて入力された音声から音響的な特徴(音響特徴)を抽出し、CTCにより発話内容を推定します。上述の通り、CTCは出力されるシンボルが互いに独立であるという仮定を置いたモデルであるため、一部誤った認識結果を出力してしまうことがしばしばあります。
例えば、上図では、「今日の天気」という正解に対して、「今日野電気」という結果が出力されています。この問題を解決するため、Mask-CTCではmask-predictを用いてCTCの出力に含まれる誤りを修正します。mask-predictは、まずCTCの出力のうち信頼度の低いシンボル(「野」、「電」)を特殊なシンボル(mask)に置換します。そして、Decoderにより、maskされていないシンボル(信頼度の高いシンボル)や音響的な特徴を用いて、maskに置換されたシンボルを再推定します。図ではmaskに置換された「野」のシンボルが、「の」というシンボルに置換されています。この処理を、全てのmaskが置換されるまで繰り返すことにより、最終的な出力系列「今日の天気」が得られます。
複数のラベルを同時に推定するための非自己回帰モデルを提案
本研究では、以下の図のように、Mask-CTCを複数種類のラベルを含む系列に対して適用します。複数種類のラベルを含む系列に対してMask-CTCを適用した例は、私が知る限りではありません。
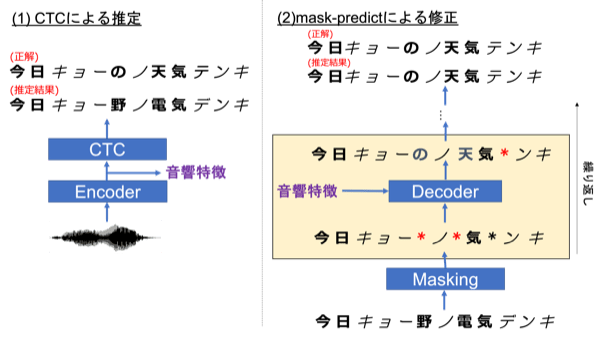
本研究で用いるモデルは最初に、CTCにより表記と読みを含む系列を推定します。先程の例と同様に、この系列には誤りが含まれます(「野(表記)」、「電(表記)」、「デ(読み)」)ので、Mask-CTCと同様に、それらの誤りをmask-predictにより修正します。ここではラベルの種類を区別しない方法(global mask-predict)とラベルの種類を区別した方法(typewise mask-predict)の2種類の方法を検討しました。
ラベルの種類を区別しない方法 global mask-predict
global mask-predictでは、従来のMask-CTCと同様、CTCの出力のうち信頼度の低いシンボルをmaskに置換したのちに、Decoderを用いた修正をおこないます。しかし、この方法には考慮すべき点が2つあります。
まず、ラベルの種類によって誤りの傾向が異なるという点を考慮する必要があります。例えば、表記のシンボル数(漢字を含む)は読みのシンボル数(カナのみ)に比べて圧倒的に数が多いため、表記の推定は読みの推定よりも難しいことが想像されます。そのため、maskに置換する際の信頼度の閾値は、表記と読みで別々の値を用いることが望ましいと考えられます。
次に、Decoderによる修正の際にラベルの種類を無視しているという点です。表記と読みを同時に推定するのではなく、正しい表記を得られてから読みを推定した方がより推定は簡単になると思われます。
ラベルの種類を区別した方法 typewise mask-predict
typewise mask-predictは、global mask-predictにおける上記の点を考慮したアルゴリズムです。
まず、ラベルの種類ごとの誤り傾向の違いを考慮するために、maskに置換する際の信頼度の閾値をラベルの種類ごとに定義しています。この変更により、maskされる表記のシンボルの数を読みのシンボルよりも多めに設定するといったことが可能となります。
さらに、Decoderによる修正の際にラベルの種類を考慮するために、各反復で更新するラベルの種類を選択するようにしました。例えば、奇数回目の反復では表記のシンボルだけを更新し、偶数回目の反復では読みのシンボルだけを更新するといったことが可能となります。
音声認識と音声意味理解での効果を確認
提案した手法の有効性を検証するため、Corpus of Spontaneous Japanese(CSJ)という日本語の音声データと、A Spoken Language Understanding Resource Package(SLURP)という英語の音声データを用いて、音声認識と音声意味理解の評価を行いました。CSJでは表記に加えて読み・品詞を出力するモデルを学習し、音声認識と固有名詞抽出・言い淀み検出の性能を評価しました。また、SLURPでは表記と固有表現分類を出力するモデルを学習し、音声認識と固有表現抽出の性能を評価しました。
モデルは、global mask-predictを用いた方法(g-MaskCTC)、typewise mask-predictを用いた方法(t-MaskCTC)を用いました。また比較として、ARモデルのTransformer、NARモデルのCTCを用いました。Transformerは精度は高いが計算時間が長いという性質がある一方で、CTCは計算時間が短いものの精度が低いという性質があります。
音声認識精度の評価尺度として、CSJは文字誤り率、SLURPは単語誤り率を用いました。また、計算時間の評価尺度には、RTFを用いました。固有名詞抽出、言い淀み検出、および固有表現抽出の評価には、音声意味理解の評価尺度であるWord-F1、Char-F1、SLU-F1を用います。これらの評価尺度については、原論文(外部サイト)で詳しく説明されています。
まずは、音声認識の性能評価の結果を示します。
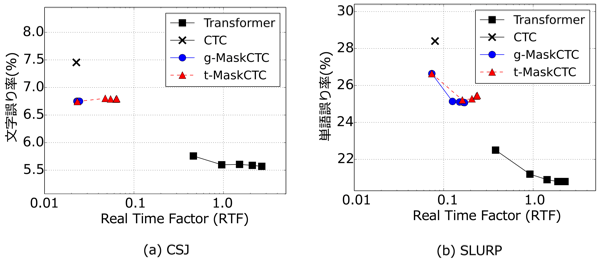
こちらの図は、音声認識精度と実行時間の関係を示しています。今回の目的は、精度を担保しつつ実行時間を削減することなので、左下にいけばいくほど良いモデルであるといえます。なお、g-MaskCTCおよびt-MaskCTCは反復回数を、Transformerは精度と実行時間のトレードオフを調整するパラメータ(ビームサーチ幅)を変化させた結果を示しています。今回提案したg-MaskCTCおよびt-MaskCTCは、CTCよりも性能が高く、Transformerよりも短い時間で音声認識ができていることが確認できます。
次に、自然言語処理の性能評価の結果を示します。
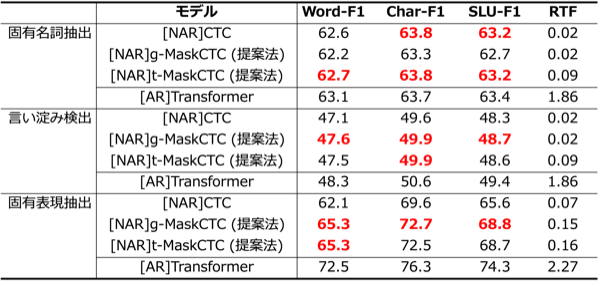
固有表現抽出のタスクでは、g-MaskCTCとt-MaskCTCはCTCと同等の性能でしたが、言い淀み検出・固有表現抽出のタスクではCTCの性能を上回りました。提案法は、Transformerに性能面で及ばないものの、実行時間を最大93倍程度まで削減できました。提案法の性能改善は今後おこなっていきます。
まとめ
本ブログでは、前回のブログで紹介した音声認識手法の実行時間を削減するための方法を紹介しました。この方法は、実行時間を削減するために、NARモデルのひとつであるMask-CTCを基に考案されたもので、音声認識と自然言語処理を従来の方法よりも実行時間を大幅に削減できることを確認しました。一方で、性能についてはまだ改善の余地があるため、そのための方法を今後検討していきたいと思います。
(ヤフーでは、今回の取り組みの他にも音声認識に関する研究開発をおこなっています。よろしければ、「ヤフーの音声認識に対する取り組み」 もぜひご覧ください。)
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました
- 大町 基
- 音声処理エンジニア
- ヤフー独自の音声認識エンジンYJVOICEに関する研究開発をおこなっています。



