こんにちは、ヤフー独自の音声認識エンジン「YJVOICE」の研究開発を担当している大町です。こちらのブログでも紹介しているように、ヤフーではEnd-to-End(E2E)音声認識の研究開発に取り組んでいます。
今回は、自然言語処理のトップカンファレンスNAACL2021(2021 Annual Conference of the North American Chapter of the Association for Computational Linguistics)で発表した、新しいE2E音声認識の手法を紹介します。より詳しい内容を知りたい方は原論文もご参照ください。
既存のE2E音声認識は、ユーザーの発言意図を特定しにくい
音声認識は、ユーザーの話した声からテキスト(主に表記列といいます)を推定する技術です。近年では音声ユーザーインターフェース(VUI)を実現する上で重要な役割を果たしています。
従来の音声認識は、音響モデル・発音辞書・言語モデルといったいくつかのモデルが用いられていましたが、近年では、それらのモデルを単一のニューラルネットワークに置き換えたE2E音声認識の研究が盛んにおこなわれています。E2E音声認識は、モデルの軽量化技術などを用いることでオンデバイスへの応用が可能となるだけでなく、従来の音声認識に迫る性能を実現できるというメリットがあります。
しかし、現在提案されている多くのE2E音声認識のほとんどは発話内容を書き起こした表記列のみを出力します。
この特性は、しばしば問題をひき起こします。例えば、ある発話の認識結果の出力が「日本橋」のとき、ユーザーの意図した発話が「にっぽんばし」と「にほんばし」のどちらかだったかを特定できません。ナビアプリの行き先が「にほんばし(東京)」と「にっぽんばし(大阪)」のどちらになるかでは、大違いです。
そこで、読みや品詞も同時推定する音声認識を検討
もし、E2E音声認識で読みの情報も同時に得られるならば、発話者の発話意図を特定するのも容易です。さらに品詞も同時に推定できれば、発話した意図をより特定しやすくなります。
そこで、E2E音声認識で表記だけでなく、読みや品詞といった素性を同時に推定する手法を開発しました。この方法は、VUIにE2E音声認識を組み込む際にもメリットがあります。以下の図は、E2E音声認識を使ってVUIを実現しようとした場合のシステム構成を示したものです。
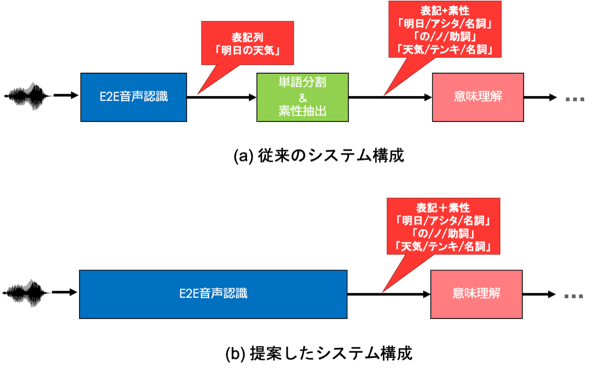
上段の(a)は、現在主流のE2E音声認識を用いた場合のVUIのシステム構成を示しています。まず、E2E音声認識により発話内容の表記列(「明日の天気」)を推定します。そして、表記列に単語分割や素性抽出などの自然言語処理を適用することで素性(「明日、アシタ、名詞」「の、ノ、助詞」など)を抽出し、意味理解モジュールでユーザーが発話した意図を推定します。この構成では、音声認識と自然言語処理にはそれぞれ異なるモデルが用いられているので、音声認識結果に誤りが含まれてしまったときに、後続の自然言語処理を正しくおこなえません。
また、表記と素性のアライメントをとる必要があり、高精度にアライメントをする技術が求められます。さらに、それぞれのモデルを保持するためのメモリやストレージが必要となり、スマートフォンなどのデバイスで動かすことが難しいといった課題もあります。
下段の(b)は、今回提案したE2E音声認識を用いた場合のVUIのシステム構成です。このシステム構成では、音声認識と素性抽出の両方を考慮するようにモデルが学習されているため、音声認識結果に応じた素性を抽出できると期待されます。
また、表記と素性のアライメントもE2E音声認識の枠組みの中で実現されるので、別途アライメントを取る必要がありません。さらに、音声認識と素性抽出それぞれのモデルを持つ必要がないため、計算資源が少ないデバイスでも動作が可能というメリットもあります。
今回開発した手法で良くなったところは?
テキストから素性を推定する方法は数多く提案されていますが、今回の提案法はテキストだけでなく音声の情報も使えるという利点があります。そのため、テキストだけで素性を推定するのが難しい発話に対しても頑健に動作することが期待できます。音声を使うことによって読みや品詞がうまく推定できた発話例を、いくつか示します。
各発話は上段から「正解の系列」「素性推定にテキストのみを用いた方法(従来法)」「素性推定に音声とテキストを用いた方法(提案法)」の出力を示します。また、出力は、形態素に分割されており、形態素は「表記/読み/品詞」のように記述されています。UNKは読みや品詞がうまく推定できなかったことを表す記号(Unknown)です。

(a)は、言いよどみを含む「ぴっちとすぺくとらすぺくとる」という発話に対する出力です。この発話の、「スペクトラ」と「スペクトル」という形態素の間には短い無音が含まれています。テキストのみを用いた従来法では、この2つの形態素をうまく分割できずに、読み・品詞がうまく推定できません。一方、提案法は、テキストだけでなく音声の情報も用いることができるため、2つの形態素をうまく分割でき、読み・品詞を正しく推定できています。
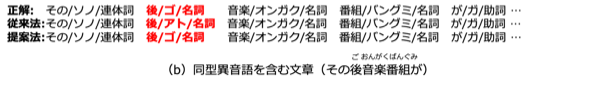
(b)は、同型異音語(同じ表記でも読みが異なる語)を含む「そのごおんがくばんぐみが」という発話に対する出力です。同型異音語の読みは従来法では一意に定めることが難しいという問題がありますが、音声の情報を使うことで正しい読みを付与できている様子を確認できるかと思います。
関連研究で広く用いられているモデルだと性能が劣化
関連研究として、「音声から表記列と固有表現分類(組織・人名などのカテゴリー)」「音声から表記列と話者情報(話者タグ)」を推定するモデルが既に提案されています。それらの研究では、connectionist temporal classification(CTC)がよく用いられています。CTCは、出力されるシンボル(例えば、文字)が互いに独立であるという仮定のもと、音声が与えられた際の事後確率が最も高くなるようなシンボル系列を推定するモデルです。
そこで、関連研究と同様にCTCを使って表記列と素性を並べた系列を同時推定するモデルを構築し、音声認識の性能評価をしました。評価には日本語の講演音声などを含むCorpus of Spontaneous Japanese(CSJ)とよばれるデータセットを使い、文字誤り率・読み誤り率を算出しました。本研究の目的は音声認識と素性抽出を同時に実現することですが、音声認識そのものの推定性能が劣化してしまうことは望ましくありません。評価では、表記列のみを推定する従来のE2Eモデルと今回構築したモデルとで性能差があまりないことを確認しました。以下の図は、結果を示したグラフです。文字誤り率は低い方が良い評価尺度ですので、下にいくほど音声認識に適したモデルであるといえます。
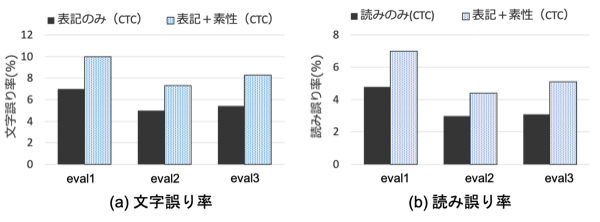
ご覧の通り、表記列と素性を同時に推定する提案法は、従来の表記列のみを推定するモデルと比べて性能が劣化してしまっていることがわかります。CTCは出力されるシンボルどうしの関係性を考慮しないモデルですが、表記列と素性は互いに関係していることがあります(例えば、同音異義語など)。そのため、CTCは本研究の利用用途としてはふさわしいモデルであるとはいえません。そこで、出力したい系列全体を考慮したモデルを用いて、音声認識の性能も改善できないか検討しました。
今回の手法、最新のTransformerモデル応用だと十分な性能が得られた
出力系列全体を考慮したモデルとして、Transformerが提案されています。Transformerは機械翻訳分野でも広く使われているモデルですが、近年では音声認識に応用した研究が多く報告されています。特に、音声認識に応用する場合には、TransformerとCTCを組み合わせることでより良い性能が得られることが知られています。そこで、TransformerとCTCを組み合わせたモデル(Transformer-CTCモデル)で、表記列と素性を同時に推定したときの音声認識性能を調査しました。先ほどの図にこの結果を加えて示します。
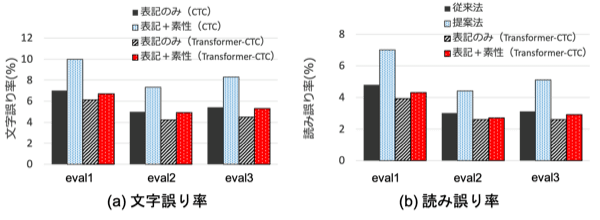
やはり、従来の表記列のみを推定するモデルに比べて若干の性能劣化はありますが、その程度はCTCを用いた場合よりも少なくなっています。まだ改善の余地はありますが、Transformer-CTCモデルを用いれば音声認識の精度としては十分な性能が得られていると思われます。
次に、今回の提案法が十分な性能で素性を抽出できるのかを検証しました。素性抽出の評価尺度としては、Precision, Recall, F値を用いました。比較として、Transformer-CTCモデルを用いたE2E音声認識と自然言語処理に基づく素性推定手法を組み合わせた従来法の性能も計算しました。以下の図は、その結果を示しています。上にいくほどより正確に素性を抽出できていることを示しています。
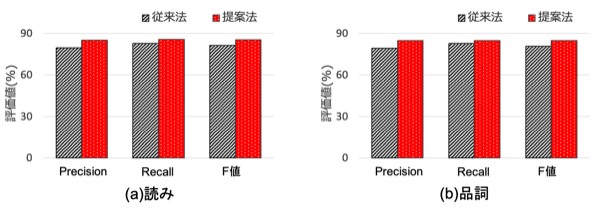
提案法は、自然言語処理に基づく従来法よりも若干ではありますが、良い性能が得られています。
以上の結果より、提案法は音声認識本来の性能を担保しつつ、素性を十分な精度で抽出可能であることが確認できました。
まとめ
表記列だけでなく読み・品詞の情報も同時に推定するE2E音声認識システムを開発しました。この方法は、表記列に加えて固有表現分類などの他の素性やアクセント情報などとも組み合わせることが可能です。今後は、それらの応用についても検討していこうと考えています。さらに、計算量削減やオンライン化、性能改善などの課題にも取り組んで、ヤフーのアプリをもっと使いやすくしていきたいと思います。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました
- 大町 基
- 音声処理エンジニア
- ヤフー独自の音声認識エンジンYJVOICEに関する研究開発をおこなっています。



