こんにちは。CTO直下のR&D組織であるテックラボにて、コマース領域向けの研究開発に取り組んでいる脇山です。
本記事ではベクトル検索を製品への紐付け(いわゆる名寄せ)業務に利用した事例を紹介します。
商品を製品マスタに紐付けする
みなさんはYahoo!ショッピングで商品を探したことがあるでしょうか?
Yahoo!ショッピングにはいろんなストアが商品を出品しているため、同じ商品を異なるストアが販売しています。そのため、「コカ・コーラ 500ml 48本」といったクエリで検索すると、検索結果に異なるストアが出品した「コカ・コーラ 500ml 48本」の商品が複数並ぶことがあります。商品を購入する際は、同じ商品でも商品価格や送料などがストアによってどのように違うか比較したりすることが多いと思います。Yahoo!ショッピングには異なるストアが出品しているが、同一製品として1つにまとめたページが存在し、ユーザはこのページで同じ製品の価格の比較や製品情報を知ることができます。
同一製品の情報をまとめたページのイメージ
説明のためにこの記事では各ストアが出品したアイテムを“商品”、同一商品をまとめるためのマスタを“製品”と呼ぶことにします。
ユーザのお買い物をサポートするために製品でまとめたページを作成するためには、製品マスタに商品を紐付けるいわゆる名寄せ作業が必要です。商品を製品マスタに紐付ける方法としてはJANと呼ばれる製品識別コードを利用する方法もありますが、未入力や誤入力もあるため一部手動で名寄せ作業が行われています。この手動での名寄せ作業はテキスト検索を用いて実施されていましたが、検索クエリを作成する際は工夫が必要なため作業精度や作業時間が課題となっていました。
今回、手動での名寄せ作業を効率化するためにベクトル検索を試したので、この記事ではその内容を紹介します。
ベクトル検索を試した理由
従来の名寄せ作業は、製品マスタに対してテキスト検索を行い紐付け先となる製品を探すことで実施されていました。この検索を行う場合は商品名から検索クエリを作成するのですが、検索精度を上げるために大きく2つの課題がありました。
- 同義語の存在
- ノイズとなる文字列の存在
1つ目の同義語の存在についてですが、アルファベット表記とカタカナ表記に関係する問題です。例えば商品名に“NIKE”と書かれているが、“ナイキ”とは書かれていないといった、アルファベット表記では書かれているが、カタカナ表記では書かれていない場合です。検索クエリ、製品マスタの双方にアルファベット表記かカタカナ表記のどちらかしか記載されていない場合、同一製品が検索結果に含まれないことがあります。
2つ目のノイズとなる文字列の存在は、われわれが日常的に目にするものでもあります。商品名には送料無料、ポイント○倍といった文字列、ストアが独自に商品を管理するための英数字列が含まれることがあります。このような文字列は人間にとっては商品の理解の助けになりますが、名寄せの検索においてはノイズとして振る舞い、同一製品の検索順位を下げることがあります。これらに対して、従来は作業者が検索クエリを試行錯誤しながら検索を何度か実行することで同一製品を探していました。
今回ベクトル検索を試したのは、商品名・製品名を密ベクトルにEmbeddingすることでこれらノイズとなる文字列や同義語の影響を受けずにアイテム間の距離計算を行うことができれば、検索クエリを工夫する作業が不要になると考えられるためでした。
BERTによる商品名・製品名のEmbedding
商品名・製品名のEmbeddingにはBERTを利用しました。Embeddingに利用するBERTのモデルは、Wikipediaのデータでpretrain済みのBERTに対してYahoo!ショッピングのデータでfine-tuneしたものを利用しています。fine-tuneの際はYahoo!ショッピングの全カテゴリのデータを利用しました。
BERTのfine-tuneはクラス分類問題を解くことで行いました。Yahoo!ショッピングの製品データは、製品に対してストアが出品した商品が紐づく1:Nの関係になっています。1製品を1クラスとしてクラス分類問題として扱い、LossにはCurricularFace、OptimizerにはAdamW + SAMで学習しました。fine-tuneは以下の図のアーキテクチャで行いました。Embeddingする際はBERTの出力に対してGlobal Average Poolingを適用した768次元のベクトルを利用しています。
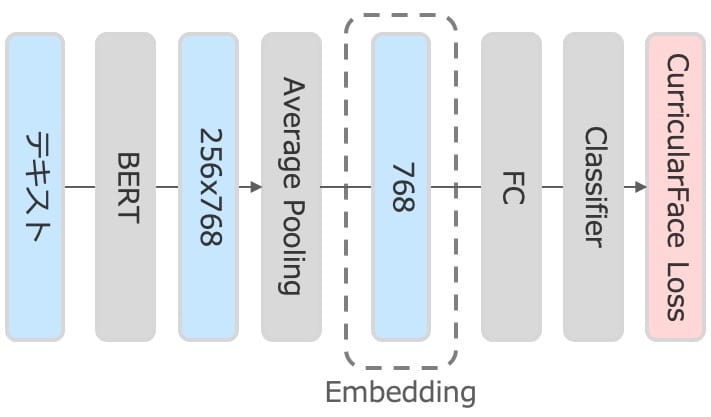
Embeddingに用いるBERTのfine-tuneの方法としてはSentence-BERTもありますが、Lossをいくつか変えて試してもクラス分類問題を解く方法よりも良い精度を出すことはできませんでした。また、BERTをクラス分類問題でfine-tuneする際のLossとしてArcFaceを用いる方法もありますが、ArcFaceよりもCurricularFaceの方が若干ですが良い結果が得られたのでCurricularFaceを利用しています。
Embedding後のベクトルを用いてベクトル検索には、NGTを利用しました。NGTを用いることで、高次元ベクトルデータの近似近傍検索を高速に行うことができます。NGT内での距離計算はベクトル間のcos距離で行いました。
ベクトル検索結果のサンプル
ベクトル検索を行うにあたって、事前にYahoo!ショッピングの製品データをEmbeddingしてIndexを作成しておきます。
では、早速ベクトル検索の結果を見てみましょう。1つ目は同義語が影響する検索の例です。
検索クエリ:PILOT Dr.Grip 4+1
検索結果
| 順位 | 製品名 |
|---|---|
| 1 | パイロット ドクターグリップ 4+1 多機能ボールペン 0.7mm BKHDF1SFN |
| 2 | パイロット ドクターグリップ 4+1 多機能ボールペン BKHDF1SE 0.5mm |
| 3 | パイロット ドクターグリップ 4+1 多機能ボールペン 細字 0.7mm BKHDF1SF |
| 4 | パイロット ドクターグリップ 4+1 多機能ボールペン 極細(ミントグリーン) 0.5mm BKHDF1SEF-MG |
| 5 | パイロット ドクターグリップ 4+1 多機能ボールペン (スカイブルー) 0.7mm BKHDF1SFN-SB |
検索クエリをアルファベット表記で検索しても、カタカナ表記の製品が検索でヒットしています。Embeddingされたことで、アルファベット表記とカタカナ表記の距離が近くなっていると考えられます。
もう1つ同義語が影響する検索の例を見てみましょう。
検索クエリ:CHANEL allure homme sport cologne
検索結果
| 順位 | 製品名 |
|---|---|
| 1 | CHANEL アリュール オム スポーツ オードゥ トワレット (ヴァポリザター) 50ml 男性用香水、フレグランス |
| 2 | シャネル アリュールオム スポーツ 100ml EDT 香水 フレグランス 男性用香水、フレグランス |
| 3 | シャネル ココ ヌワール ボディ クリーム 150g ボディクリーム |
| 4 | アリュール オム スポーツ オードゥ トワレ 男性用香水、フレグランス |
| 5 | CHANEL アリュール オム スポーツ スポーツスプレイ オードゥ トワレット 20ml × 3 男性用香水、フレグランス |
こちらもアルファベット表記のクエリに対して、カタカナ表記の製品が検索でヒットしています。ただし、検索順位の4位は別ブランドがヒットしており、必ずしもうまくいっているわけではないようです。
最後にノイズとなる文字列が含まれる検索の例を見てみましょう。確認のために、検索クエリの先頭と末尾に製品特定には関係ない”送料無料”と”管理番号n-200-2”という文字列を追加しました。
検索クエリ:送料無料 ニベア スキンミルク しっとり 200g 2本 管理番号n-200-2
| 順位 | 製品名 |
|---|---|
| 1 | NIVEA ニベア スキンミルク しっとり 200g×2 ボディローション |
| 2 | NIVEA ニベア スキンミルク しっとり 200g ボディローション |
| 3 | NIVEA ニベア スキンミルク しっとり 200g×3 ボディローション |
| 4 | NIVEA ニベア スキンミルク しっとり 200g×10 ボディローション |
| 5 | NIVEA ニベア スキンミルク しっとり 200g×20 ボディローション |
Indexした製品は本数ごとに別製品としてデータが存在しているため、同じ検索結果が並んでいるように見えます。ただし、少なくともノイズとなる文字列の影響は受けていないように見えます。
上記の検索結果のサンプルは比較的うまくいった例ですが、「片手鍋」と検索して「両手鍋」の方が上位に来るなどうまくEmbeddingが行えていない場合もありました。特に検索クエリが短い場合にうまくいかない傾向が強いため、検索クエリとIndexをEmbeddingするモデルを個別に用意するTwo-Towerモデルの方が良い可能性もありましたが、今回はそこまで検証できませんでした。
ベクトル検索の評価
ベクトル検索の結果を評価するために、評価用データセットを作成してテキスト検索との比較を行いました。
検証用データセットとして135クエリと、Index対象となる34,365製品を用意しました。学習用データセットにはYahoo!ショッピングの全カテゴリのデータを利用していますが、検証用データセットでIndexしたのは一部のカテゴリのみになっています。135クエリの各クエリはIndexされた製品の中に1つだけ正解となる製品が存在しています。今回はこのデータセットを用いてベクトル検索とテキスト検索の比較を行ってみました。テキスト検索は、Apache Solrで環境構築を行いベクトル検索と同じ34,365製品をIndexしました。スコア計算は形態素解析+BM25で行いました。
以下は評価指標をRecall@Nのマクロ平均をテキスト検索とベクトル検索で比較した結果です。
| Recall@1 | Recall@3 | Recall@5 | Recall@10 | |
|---|---|---|---|---|
| テキスト検索 | 72.6% | 77.8% | 80.7% | 84.4% |
| ベクトル検索 | 86.7% | 88.9% | 89.6% | 89.6% |
今回用意した検証用データセットにおいては、ベクトル検索の方がテキスト検索よりも精度が高いことが確認できました。とはいえ、ベクトル検索は製品データで学習しているのに対してテキスト検索は機械学習を全く利用していないので、ベクトル検索の方に有利な検証になっています。
また、実際の名寄せ作業の効率化にベクトル検索が有効か検証した結果、従来の名寄せ作業と比べて作業時間を42%削減できることが分かりました。
おわりに
今回は商品名・製品名をEmbeddingするために用いたBERTの学習方法と、それを用いたベクトル検索の検証結果を紹介しました。実際にバックオフィスで製品データの名寄せ作業を行っている方にもベクトル検索を試してもらい、名寄せ先の製品の発見率や作業時間を短縮できるという検証結果も得られたため、現在は実際の業務でベクトル検索を利用できるように準備を進めています。Embeddingの方法についても改善の余地があるため、引き続き改善を進めていく予定です。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました
- 脇山 宗也
- CTOテックラボ 機械学習エンジニア



