こんにちは。サイエンス統括本部でYahoo!ショッピング やPayPayモール のおすすめ機能(レコメンドシステム)を担当している杉浦です。
Yahoo!ショッピングではさまざまな種類のレコメンドを提供しています。今回はレコメンドに検索エンジン(= Apache Solr )を導入することで運用改善した話をします。
この記事では最初にYahoo!ショッピングにおけるレコメンドの仕組みや既存のシステムの問題点について説明した後、どのように検索エンジンを導入し改善につなげたのかを順に説明していきます。
Yahoo!ショッピングにおけるレコメンド
Yahoo!ショッピングには「あなたへのおすすめ商品」のようなモジュールがさまざまな箇所に出てきます。これがレコメンド (recommend) です。日本語にすると推薦という意味です。Yahoo!ショッピングやPayPayモールなどのECサイトをはじめ、動画サイトやSNSなどさまざまな分野に応用されています。
Yahoo!ショッピングにおけるレコメンドにはさまざまな種類があります。例えばある商品を見ている人に対しては「この商品を見ている人におすすめ」、カート追加や購入後の画面であれば「この商品を買った人におすすめ」など場合によってモジュールの出し分けを行っています。他にも例えばPCとスマートフォンでは購買行動が違うため別のレコメンドモジュールを提供しています。また最近ではYahoo!ショッピングだけでなくPayPayモールやLOHACO にもレコメンドの提供を行っています。
このように一口にレコメンドといってもその種類はさまざまで、現在60種類以上のモデルで100以上の掲載面にレコメンドを展開しています。
レコメンドが表示される仕組み
では次にこのレコメンドがユーザーに配信されるまでの流れを見ていきます。
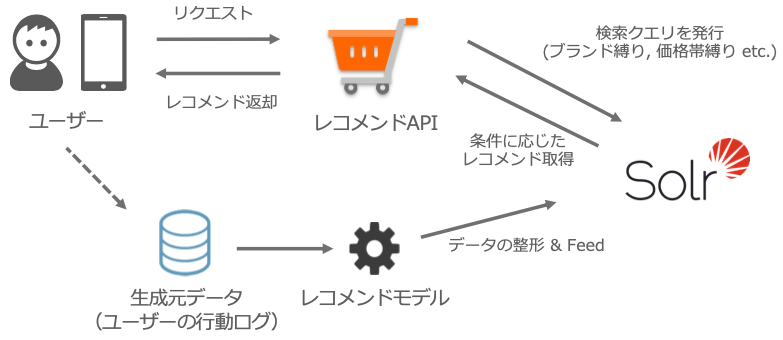
ユーザーが端末である商品Aを見たとします。この商品Aをseed商品と呼びます。するとシステムの裏側では瞬時にこの情報がレコメンドAPIに伝えられます。具体的には「どの面で」「どの商品が」見られたか、などです。するとレコメンドAPIからは、事前にレコメンドを格納しておいたデータベース(後述)からseed商品Aに対するレコメンドとして「商品B、商品C」といったレコメンドデータが返却されます。こうして商品Aを見ているユーザーの端末には商品B、商品Cがおすすめ商品として掲載されます。
この返却までにかかる時間のことをレイテンシと呼びます。レイテンシが長くなるほどユーザー体験の悪化につながるため、できるだけ短くする必要があります。
また、商品Aをseed商品と呼びましたが、返却される商品B、Cを今後レコメンド商品と呼びます。
これらの流れを図にしたのが以下です。

既存システムではデータベースとしてCassandraを採用
先程の例ではレコメンドデータを事前にデータベースに格納しておくという話をしました。ではなぜデータベースが必要なのでしょうか。
実は「どの商品にどの商品をレコメンドするか」を決めるには時間がかかります。Yahoo!ショッピングの場合、seed商品ごとにレコメンド候補になる商品を集めた後、GBDT (Gradient Boosting Decision Tree) と呼ばれる決定木をベースにした手法で機械学習により商品の表示順序を決定しています。このときにseed商品ごとにレコメンド商品のスコアを計算し、スコアが降順になるように並び替えます。Yahoo!ショッピングの場合は商品数、ユーザー数ともに膨大であるためこれらの作業には数時間はかかります。
一方でレイテンシはできるだけ短くしたいため、リスクエストがきてからこれらを計算していたのではとても間に合いません。そこであらゆる商品に対してどの商品群をどの順番でレコメンドするかをバッチ処理で事前に計算しておき、 何かしらのデータベースに格納しておく必要があるのです。
Cassandraとは
データベースとしてはApache Cassandra (以下Cassandra)を採用していました。Cassandraはオープンソースのデータベース管理システムで、キーバリューストア (KVS) と呼ばれるデータ構造を採用しています。
Cassandraの内部ではkeyとそれに対応するvalueが格納されており、ハッシュを用いた仕組みによりkeyを指定すると対応するvalueを高速で呼び出すことができます。この高速であることがCassandraが採用された一番の理由です。
例えば商品Aをkeyとして商品B、Cをvalueとしてデータを格納しておくとします。そうすればkeyである商品Aを指定した時に瞬時にレコメンド商品群を取得できます。
既存システムの問題点
前述のようにCassandraをベースとした既存システムは高速であるメリットがある反面、運用していく中であるデメリットが目立ってきました。それはモデルの管理が大変になるという点です。例えばYahoo!ショッピングとPayPayモールでは同じseed商品でもレコメンド商品が異なるため別のテーブルでデータを格納する必要があります。他にもPCなのかスマートフォンなのか、アプリのトップ画面なのかカート画面なのか、などそれぞれのパターンにおいて全て別のテーブルで保存する必要があります。
それだけではありません。同じ掲出面に出ている一見同じようなレコメンドでも、細かい条件の違いにより数多くのテーブルが派生するのです。例えば
- 「ここには同一ブランドに絞ったレコメンドを新しく出そう」
- 「ここには価格帯を絞ったレコメンドを新しく出そう」
などの新しいレコメンドモジュールの追加を検討するとします。その度にブランド絞りレコメンド、価格帯レコメンドなどのデータを新しく生成し、別のテーブル(= 別モデル)としてCassandraに格納する必要がありました。そのため当初は管理できる範囲内だったモデル数もどんどん肥大化していきました。
その結果、本来レコメンドの精度向上などに割きたい業務時間を大量のレコメンドモデルの管理、運用に費やさなければならなくなってしまいました。
これらの肥大化したシステムの様子を表しているのが下図です。

検索エンジンの検討
そこで検討されたのが、検索エンジンの導入です。検索エンジンの具体的な説明に入る前に、なぜ検索エンジンが有用なのかを説明したいと思います。既存システムの場合は先ほど触れたように、ブランド縛りと価格帯縛りでは別々のモデルとしてデータを格納する必要がありました。しかし、これらは本当に別々に計算、格納される必要があるのでしょうか?
実はそうではありません。ブランド縛りであればseed商品と同じブランドの商品だけを絞り込み検索すればブランド縛りレコメンドを得られます。また、価格帯縛りであれば指定した価格帯の商品だけを絞り込み検索すればいいのです。
このように絞り込み検索を使えば、同一のデータからさまざまなパターンのレコメンドを取得するとこができ、運用負荷の軽減を期待できます。
ABYSSとSolr
検索エンジンとして、ABYSS と呼ばれる社内システムを採用しました。ABYSSは検索に特化した社内プラットフォームで、内部で使われているのはオープンソースの全文検索システムであるApache Solr(以下Solr)です。Solrは多くのサービスでの運用実績があり、社外でも広く用いられています。
システム構成図は以下です。先ほど触れた概念図でCassandraだった箇所が検索エンジンを用いたシステムに置き換わっています。レコメンドAPIはデータ取得の際にseed商品や絞り込み条件などを含んだ検索クエリを発行し、Solr内部に格納されたデータを取得します。
一方でバッチ処理により整形された新しいデータが定期的にSolrにfeedされ、内部のデータが更新されます。
データ取得の仕組み
では次に、検索エンジンをどのようにレコメンドに用いるのかをもう少し詳しく見ていきます。Cassandraのデータ構造とSolrのデータ構造を比較してみます。
Cassandraの場合
先述のように、CassandraではKVSのデータ構造を持っており、seed商品をkeyとしてレコメンド商品とスコアが格納されています。例えば以下の図のように、seed商品としてAをkeyにすればrecB,Cが、DをkeyにすればrecE,Bが返ってくるとします。

しかし、このままでは柔軟性がありません。例えば「1000円から2000円の商品のみ」に絞った表示はできません。
Solrの場合
Solrを用いる場合、まずは先程のテーブルを転置します。つまり、seedごとにレコメンド商品がスコア降順に並んでいたものを、レコメンド商品ごとにseed商品がスコア降順に並ぶようにするのです。図にすると以下のようになります。
recBに対してseedA,Dが、recCに対してはseedA、recEに対してはseedDがそれぞれ紐づいており、先ほどと比較して転置されていることがわかると思います。

レコメンド商品にはdocument IDという識別子がついています。今回はdocument(= 文章)ではないのでピンとこないかもしれませんが、検索という行為を大量の文章から特定の単語を含むものを見つけてくることだと捉えると少しイメージしやすいかもしれません。
今回で言えばレコメンド商品ごとにseedとスコアが連なったものがテキストであり、その中から特定のseedを含むものを検索するイメージです。
一方、document IDごとにメタ情報を加えて検索に使うことができます。例えば上図においてはrecB,C,Eに対してにそれぞれ1000, 1200, 1000000という価格情報を加えてあります。
この状態で 「seed商品がDで、1000円から2000円の商品のレコメンドのみ」に絞ることを考えてみます。seedDを含むdocument IDとして、上図のようにrecBとrecEが該当したとします。このとき、recEは価格が高すぎるので検索時に除外され、seedDのレコメンドとしてはrecBのみが選ばれます。
このように、検索エンジンをうまく使うことで柔軟にデータの取得が行えます。
高速化の仕組み
ここではもう少し技術的な話をします。今まで検索をどのようにレコメンドに導入するかについて説明してきましたが、レイテンシも重要な問題です。検索エンジンを使った場合はCassandraよりは遅くなることが予想されますが、許容できる範囲のレイテンシに抑える必要があります。
検索エンジンを導入を検討した当初、レイテンシを悪化させる原因として一部の人気商品に大量のseed商品が紐づいてしまう問題がありました。seed商品ごとに見た場合、それぞれに紐づくレコメンド商品数はせいぜい数十件です。しかしこれを転置した場合、一部の人気商品は多くのseed商品においてレコメンド商品群に入っているため、場合によっては数万〜数十万件になることもありました。
この状態を表しているのが以下の図です。
このような状態で、あるdocument IDにおいて特定のseed商品を検索する場合、先頭から順番に走査するとレイテンシが悪化してしまいます。今回はABYSSで提供されているプラグインを用いて内部で転置インデックスを作ることで、seed商品の検索を高速に行えました。これにより無事許容されるレイテンシに抑えることができました。

リリースまで
今回説明したアイディアをもとに、レコメンドに検索エンジンを導入するプロジェクトが立ち上がりました。多くの人の協力のもと、現在はモジュールごとに順次リリースを行っています。
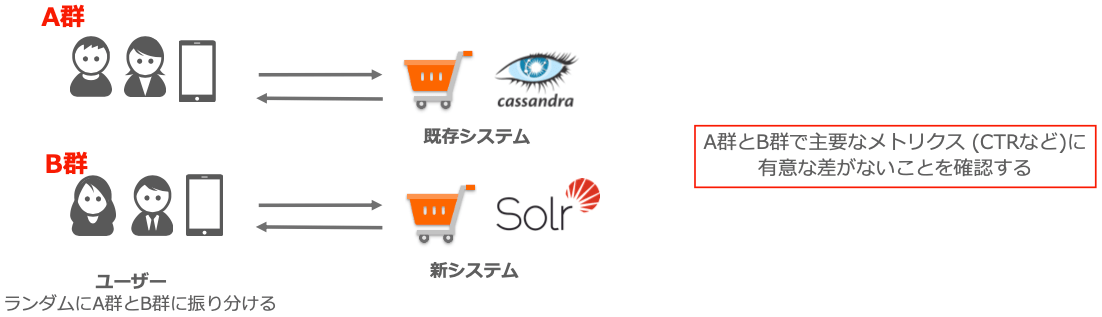
リリースの際には既存のシステムと新しいシステムでA/Bテストを行い、CTR (Click Through Rate)などの主要なメトリクスに差が出ないかを確認しています。
以下はA/Bテストの概念図です。
図ではユーザーをランダムにA群、B群に振り分けた後、それぞれを既存システム、新システムに割り当てています。
おわりに
今回はレコメンドに検索エンジンを導入することで運用コストを削減する話をしました。機械学習を用いたシステムを運用している場合、どうしても精度をいかに向上させるかに意識が向きがちですが、 長期的な視点で見ると運用コストの改善も重要な課題です。リリースの完遂に向けて尽力するとともに、これからもユーザーに快適なレコメンドを届けるために頑張ります。
Apache®, Apache Cassandra™, Apache Solr™, 及びCassandraのロゴ, Solrのロゴは、米国および/またはその他の国におけるApache Software Foundationの商標または登録商標です。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました

- 杉浦 哲郎
- データサイエンティスト
- 主にYahoo!ショッピングのレコメンド改善のお仕事をしています。物理の博士号持ってます。
-



