
こんにちは、音声処理黒帯(黒帯はヤフー内のスキル任命制度)の藤田です。今日のブログでは、音声認識技術の研究開発におけるヤフーの最新の取り組みを紹介します。
特に、近年注目されているTransformerという手法に基づく、End-to-End音声認識の計算量を削減した研究を紹介します。この研究は、難関国際会議IEEE ICASSP2020に投稿し、採択されました。また、arXivでプレプリントを公開しています。そして、ESPnetというEnd-to-Endモデルのツールキット上でソースコードも公開しています。興味のある方はぜひ、こちらもご参照ください。
音声認識で用いられるEnd-to-Endモデルとは?
音声認識技術は音声をテキストに変換する技術です。近年注目を集めている音声ユーザーインターフェース(Voice User Interface, VUI)の最初の入り口として用いられており、その性能がユーザー体験に大きく影響します。ヤフーでは、独自の音声認識エンジン「YJVOICE」の開発を2011年から開始し、すでに色々なアプリに組み込まれています。さらなるユーザー体験向上のため、日々、性能改善に取り組んでいます。
音声認識技術の研究領域では近年、End-to-End(E2E)モデルが注目を集めています。従来の音声認識技術では、音響モデルや言語モデル、発音辞書といった複数の部品を個々に最適化して組み合わせることで音声認識システムを構築していました。
一方、E2Eモデルでは1つのニューラルネットワークで構成されており、モデルが非常にシンプルです。したがって、例えばモデルを軽量化してスマホ上で動かすことが従来法より容易に行えるといった利点があります。
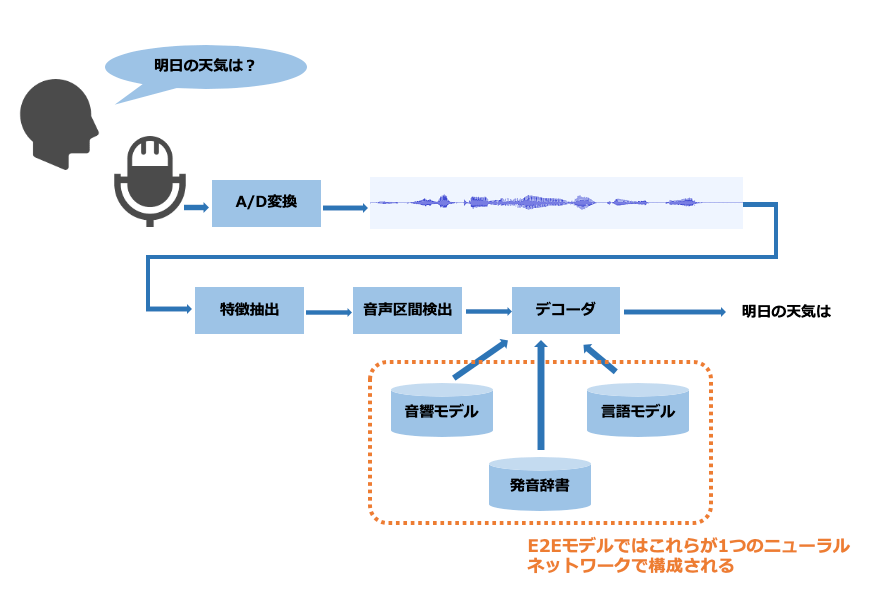
特に近年、機械翻訳の分野で提案されたTransformerというモデルが音声認識にも応用され、その性能が従来法に迫りつつあります。今後、E2Eモデルが音声認識技術のスタンダードになる可能性が高いと考えており、ヤフーでも研究開発を進めています。
Transformerは効率的な並列計算が可能だが、音声認識では計算量が大きくなる
Transformer以前のE2Eモデルでは、リカレントニューラルネットワーク(Reccurent Neural Network, RNN)が用いられていました。しかし、RNNは再帰構造を持つため、GPUなどを用いた並列計算の効率が悪いことや、勾配消失の問題がありました。この欠点を解決するためにRNNをself-attention(自己注意)という構造に置き換えたのがTransformerです。Self-attentionは再帰構造を持たないため、効率的な並列計算が可能です。しかし、条件によっては計算量そのものが大きくなってしまいます。Self-attentionの入力の長さをTとすると、Tの二乗に比例する計算が発生します。
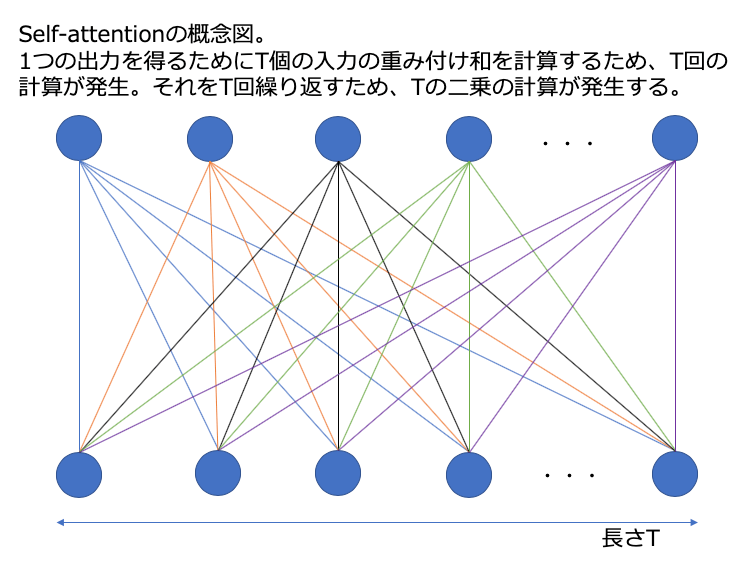
翻訳の場合はTは文字数や単語数に相当するので、それほど長くはありません。しかし、音声の場合、例えば1秒の音声でもTは100ほどです。2秒の音声では200の二乗で40,000回の計算だったものが、4秒の音声になると160,000回の計算となり、6秒だと360,000回というように急激に増加します。仮に1秒間に40,000回の計算しかできないCPUを用いると(そんな低性能なものは今の時代はありませんが…)2秒の音声は1秒待てば認識結果が得られますが、6秒の音声では9秒待たねばなりません。このように、長い音声を入力すると音声認識結果が得られるまでの待ち時間が長くなってしまい、VUIのユーザー体験を損ねてしまいます。
畳み込みを用いて計算量を削減しよう!
上記の課題を解決するために有効なのが、畳み込み構造です。畳み込みでは、1つの出力を得るために、ある長さ(カーネル長)の重み係数(カーネル)によって入力の重み付け和を計算します。このため、カーネル長と入力長の積が計算量です。一般的にはカーネル長は入力長より小さいので、入力長に比例した計算量です。Self-attentionでは二乗に比例しますから、大幅な計算量の削減です。
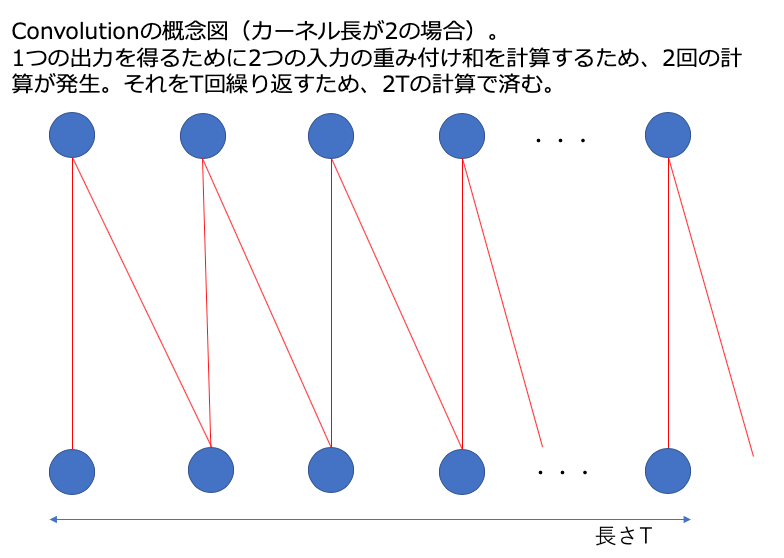
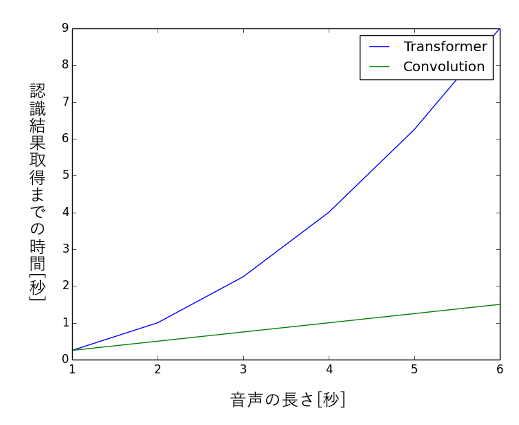
カーネル長は性能に影響するのであまり短くはできませんが、例えば100に設定した場合、2秒の音声では20,000回、6秒の音声では60,000回の計算で済みますので、self-attentionに比べると、特に長い音声において、大幅に計算量が減ります。先述のCPUの例だと、6秒の音声でも1.5秒待てば音声認識結果が得られます。グラフで見ると以下のように一目瞭然です。
特に、従来の畳み込みよりもパラメータ数と演算量が少ないLighweight/Dynamic Convolutionという手法が機械翻訳で提案されており、この研究ではそれを音声認識に応用しました。応用にあたっては、以下3つのテクニックを導入しました。詳細は論文をご参照ください。
- 周波数軸上での畳み込み
- Connectionist Temporal Classificationとのマルチタスク学習
- 部分的にself-attentionを用いた構造
畳み込みの効率的な実装テクニック
少し本題からずれるのですが、本手法を実装した時の工夫を1つご紹介します。
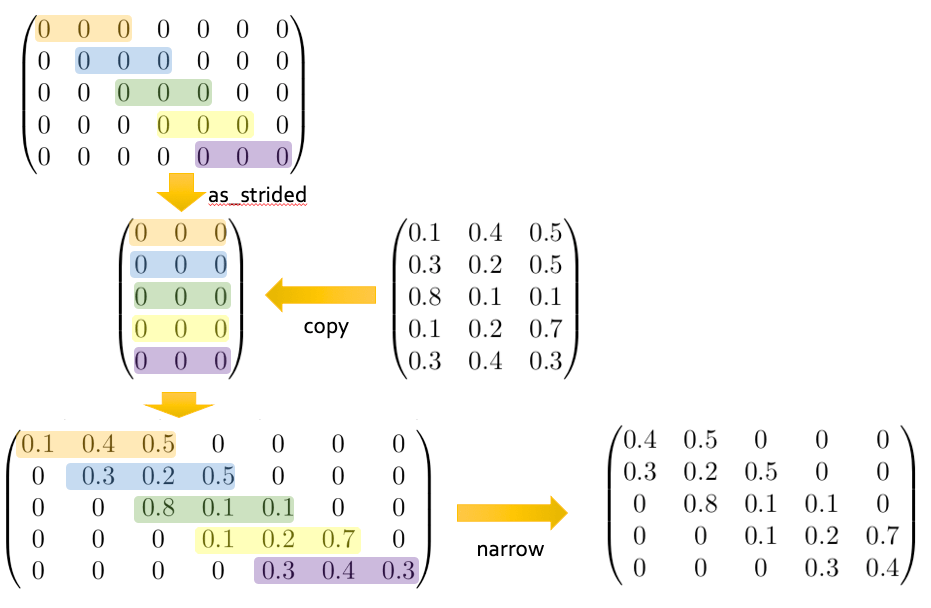
実装はESPnetを用いて行いました。バックエンドはPyTorchを利用しました。PyTorchには畳み込みモジュールが用意されているので、Lighweight Convolutionの実装はそれほど難しくありません。問題はDynamic Convolutionです。Dynamic Convolutionでは、畳み込みに用いる重み係数(カーネル)が入力に依存して変化します。通常の畳み込みではカーネルは学習パラメータであり、変化しません。上記のPyTorchのモジュールもその想定で作られており、利用できませんでした。そこで今回は、GPUで効率的に計算を行うためには行列演算の形で実装する必要があるため、帯行列を使って実装しました。これは以下の図のように、カーネル長が3で入力長が5の場合、5x3のカーネルが並んだ行列をゼロ詰をして5x5の帯行列に拡張し、入力と乗算するテクニックです。

実際のコードはこちらです。実装は少し複雑で、以下の図のように、まずは大きな行列を用意して、as_stridedというメソッドを用いて一定の間隔で行列要素をスキップした新たな行列を仮想的に作成します。次に、この仮想的な行列にカーネルの行列をコピーして、大きさを元に戻し、narrowメソッドで不要な列を削除する、という手順になっています。
実験で効果を検証
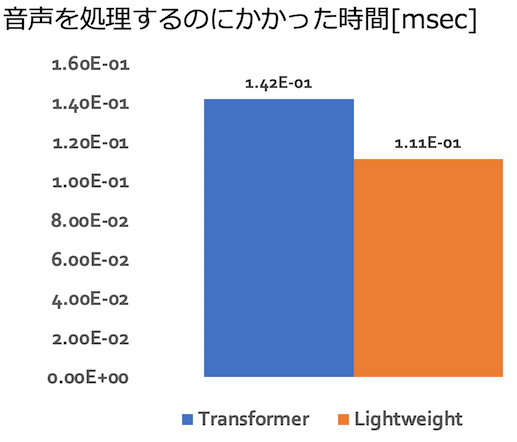
まず、計算量について確認しました。以下の図は、音声を処理するのにかかった時間[msec]の平均値を表したグラフです。左がTransformer, 右がLightweight Convolutionです。計算時間が減っていることがわかります。
次に、音声認識の精度を確認しました。計算量が減ることで精度が低下しないかを確認するためです。1つめはCorpus of Spontaneous Japanese(CSJ)という日本語のパブリックコーパスの実験結果です。以下の図は、文字誤り率(Character Error Rate, CER)のグラフです。オレンジの線がTransformerの性能で、その右側の棒が畳み込みを用いた場合の結果です。条件にもよりますが、ほぼ同程度の性能が得られることがわかりました。
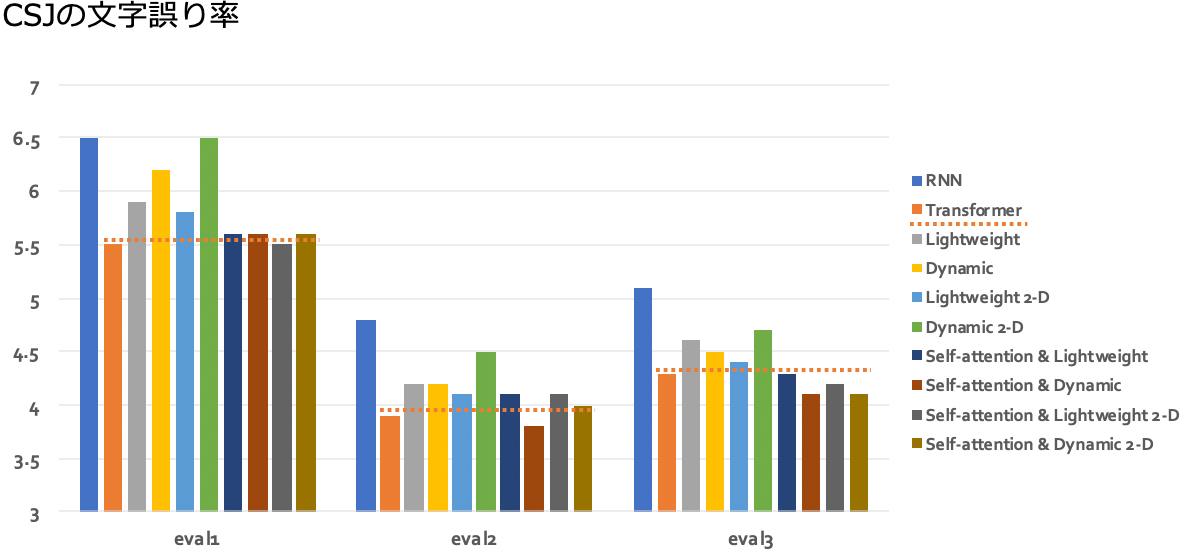
そして、CHiME4という英語の雑音環境下音声認識のパブリックコーパスでも実験を行いました。こちらは単語誤り率(Word Error Rate, WER)です。意外なことに、条件によってはTransformerよりも良い精度が得られました。
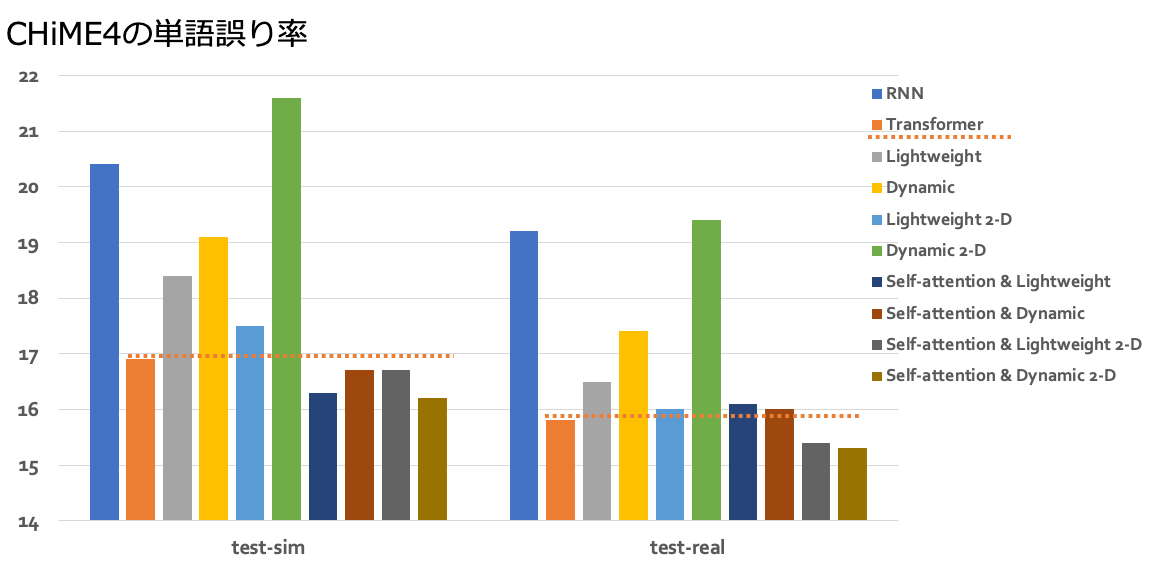
まとめ
今日は音声認識技術の研究開発の取り組みの中から、新たなスタンダードになりつつあるEnd-to-Endモデルを用いた音声認識の計算量を削減する研究をご紹介しました。ユーザー体験向上のため、待ち時間が短くて精度の高い音声認識エンジンを提供できるよう、さらなる性能改善に取り組んでまいります。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました
- 藤田 悠哉
- 音声処理黒帯



