こんにちは。サイエンス統括本部で画像処理エンジニアをしている伊藤です。Yahoo! BEAUTYの検索改善に取り組みました。本記事では、画像解析による予測を通してヘアスタイルのタグづけ精度を上げる、という改善事例を紹介いたします。
Yahoo! BEAUTY ヘアスタイル検索とは
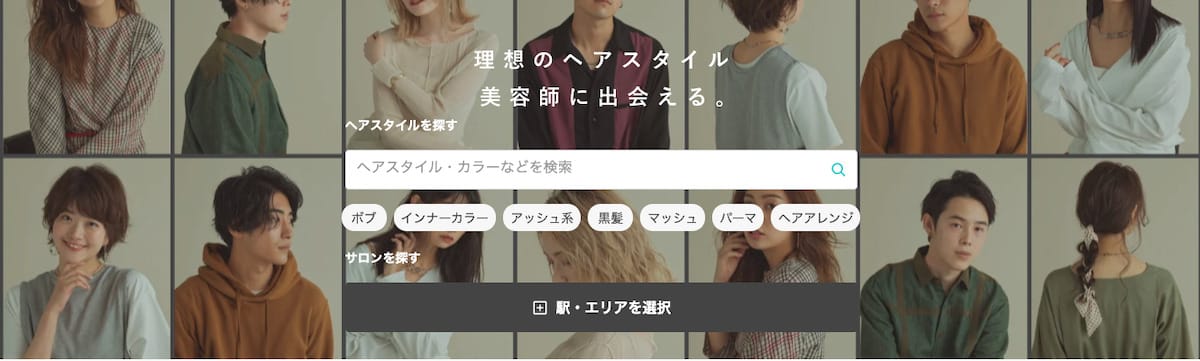
Yahoo! BEAUTYのヘアスタイル検索は、自分の理想のヘアスタイル、スタイリストを探すためのサービスです。検索対象となるヘアスタイル画像は、主にスタイリストの方が説明文やタグなどを付けて投稿しています。一般ユーザーは、タグや条件を指定して検索します。
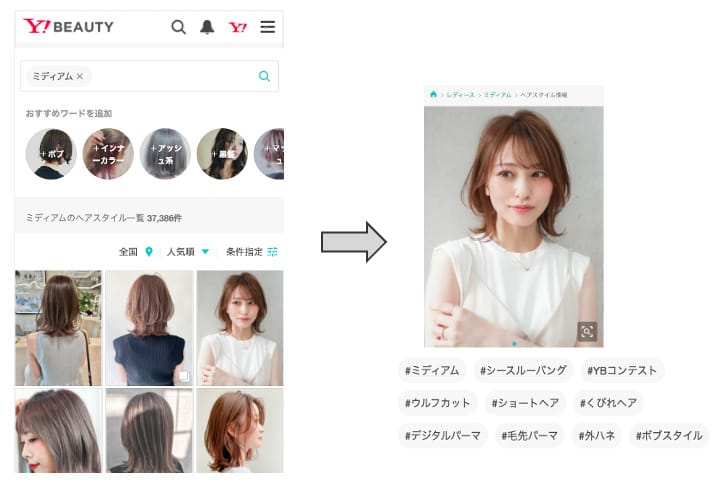
検索結果は、グリッド表示でタグなどの情報情報が見えず、画像のみが表示されるのが特徴です。
課題:検索意図とマッチしないタグが混入している
Yahoo! BEAUTYのヘアスタイル検索では、必ずしもクエリとなるタグとマッチしないヘアスタイル画像も表示されていました。例えば、「インナーカラー」と検索しているのに、インナーカラーではない画像が混ざって表示されてしまう、ということが起こっていました。
検索意図と異なる画像が表示されていまう原因を調べたところ、画像にヘアスタイルタグとして検索意図とマッチしないタグが付けられていることが分かりました。
今回の施策:タグキレイ化
去年、検索結果をよりよいものにしようとYahoo! BEAUTYの検索改善PJが立ち上がりました。人気順の並び替えロジックとして、今まで、投稿日時の新しさ、ユーザーの興味関心度合いによる並び替えをしていましたが、本PJで推定CTRやタグキレイ化の導入をし、検索改善に取り組みました。また、現在は機外学習ランキング導入にも取り組んでいます。
本記事は、この取り組みの1つのタグキレイ化についての紹介です。
画像解析のモデルでヘアスタイルタグのキレイ化を実施し、クエリにマッチするヘアスタイル画像を出やすいようにしました。画像解析モデルでタグのスコアを予測し、予測したスコアが閾値以下であれば検索順位を下げるようにします。

本取り組みは、ABテストを経て本導入されています。
タグキレイ化のモデル
タグキレイ化のモデルの詳細について説明します。
モデルアーキテクチャ
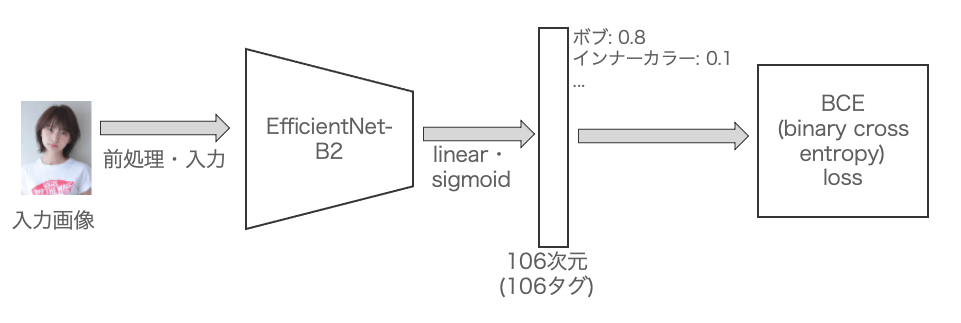
マルチラベル分類モデルとして、Binary cross entoropy lossで学習しました。backbornとしてEfficientNet-B2を採用しました。EfficientNet-B2はResnet50と比較しCPUでの推論時間が同等なのに対して、分類タスクで高い精度なので採用しました。106タグのスコアを予測しますが、このタグは検索数や付与画像数などを元にサービス担当者に選定してもらいました。
学習と評価
まずは、学習画像としてスタイリストの方が付与したタグを正解として利用しました。理想の学習データとしては、画像に検索意図とマッチしたタグが過不足なく付いたものですが、最初の取り組みとして既存で手に入るデータで実施しました。
Yahoo! BEAUTYに今まで投稿されたヘアスタイル画像とタグのデータを9:1にtrainデータとtestデータに分割し、trainデータを使ってモデルを学習しました。評価は以下の3つで行いました。
- 分類評価: testデータに対するタグ分類評価(ノイジーなデータなので参考値)
- 検索ランキング評価: 検索のクリックログを使ってのオフライン評価
- 定性評価: 検索結果にモデルを反映させてみての定性評価
通常の分類モデルの評価では分類精度のみを気にすればよいのですが、検索改善の取り組みですので、過去の検索クリックログを使った検索ランキング評価もしました。また、定性的に見てよくなっているかも重要で、奇抜なヘアスタイルや釣りっぽい画像で不当に精度を高くしていないかのチェックもします。
分類評価
| mAP (mean average precision) | |
|---|---|
| baseline(タグの頻度をそのままスコアにしたもの) | 0.3959 |
| キレイ化モデル | 0.6302 |
検索ランキング評価
| AUC (Area Under the Curve) | |
|---|---|
| baseline(当時の現行検索順位) | 0.5419 |
| キレイ化モデル | 0.5562 |
定性評価
全体の評価値としては悪くない結果となり、定性評価では意図にマッチした結果が出やすくなったのを確認しました。また、タグごとの評価値や検索数などを確認し、106タグ全てではなく効果が高そうな28タグを選びABテストを実施することになりました。
ABテスト
ABテストはタグキレイ化と推定CTRの取り組みも組み合わせて4パターンで実施しました。Controlが既存の検索結果、TestAがタグキレイ化のみ適用、TestBが推定CTRのみ適用、最後のTestCがタグキレイ化と推定CTRを組み合わせたものです。

タグキレイ化のみのTestAだとCTRの改善は見られませんでしたが、推定CTRと組み合わせることによってCTRの改善が見られました。定性的にも良くなるのを考慮し、最終的にTestCが採用され、タグキレイ化も本導入されることになりました。
データのアノテーション
タグキレイ化は本導入されましたが、精度改善していくにあたって以下の課題がありました。
- 手元にノイジーなデータしかなく画像分類の正しい評価ができない
- 学習データとしてもクリーンなデータを使って精度を上げたい
そこでデータのアノテーションをすることにしました。
まず最初のステップとして、自前のツールで1タグのみ1,000画像をサービス担当者にアノテーションしてもらい、検証しました。

アノテーションした1,000画像のうち200をテストデータとして、学習データにアノテーションデータを適用すれば精度が上がることを確認しました。
以下がアノテーションデータを徐々に学習データに追加した時の精度推移です。
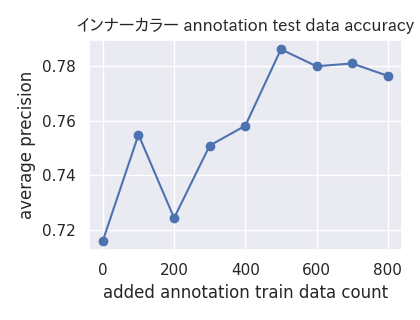
上記の検証で精度向上の見込みがついたので、Yahoo!クラウドソーシングを利用し、27タグ×約1,000画像の合計26,700のデータをアノテーションしました。
学習データへの反映と、学習時の重み調整(後述)もして、アノテーションした合計28タグの分類評価値のmAPを0.76から0.82に向上することができました。
精度向上の取り組み
精度向上の取り組みをいくつか試しましたので、うまくいった取り組み、うまくいかなかった取り組みを紹介します。
うまくいった取り組み:学習時のlossの重み調整
学習時のlossはBCE lossを利用していますが、以下のように重みを適用すると、精度向上ができました。
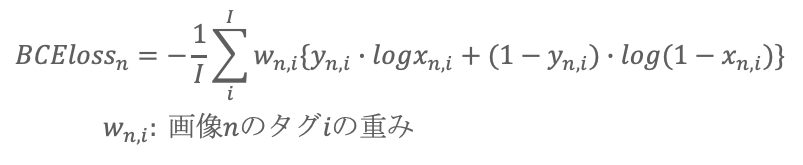
重みを以下に調整
- アノテーションした画像は10倍
- 10タグ付けられた画像は1/10倍
1画像に10タグがYahoo! BEAUTYの仕様上の上限です。以下が1画像あたりのタグ数分布です。
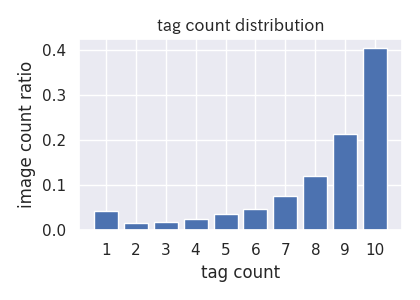
1画像あたりに少ししかタグを付けていない場合は、厳選してタグを付けていると考えられ検索意図ともマッチする場合が多いように見えました。他の重み倍率や、タグの分布を重みに反映する方法も試しましたが、試行した中では上記の重みが一番精度がよくなりました。
以下、アノテーションした13タグについての評価値です。(本検証時にはまだアノテーションデータ作成が全て完了していなかったため、13タグのみで評価しています。)
| model | 分類評価(mAP) | 検索ランキング評価(AUC) |
|---|---|---|
| 既存モデル | 0.5951 | 0.5518 |
| アノテーションデータ反映 | 0.6093 | 0.5431 |
| アノテーションデータ反映+重み調整(アノテーション10倍) | 0.6805 | 0.5679 |
| アノテーションデータ反映+重み調整(10タグ1/10) | 0.6389 | 0.5541 |
| アノテーションデータ反映+重み調整(アノテーション10倍, 10タグ1/10) | 0.7006 | 0.5673 |
単純にアノテーションデータを反映させるよりも大きな精度向上となりました。
うまくいかなかった取り組み:画像の前処理
モデルへ画像全体ではなく、ヘアセグメントや顔検出などの前処理をした画像を入力するように変更しましたが、どれも精度は上がりませんでした。
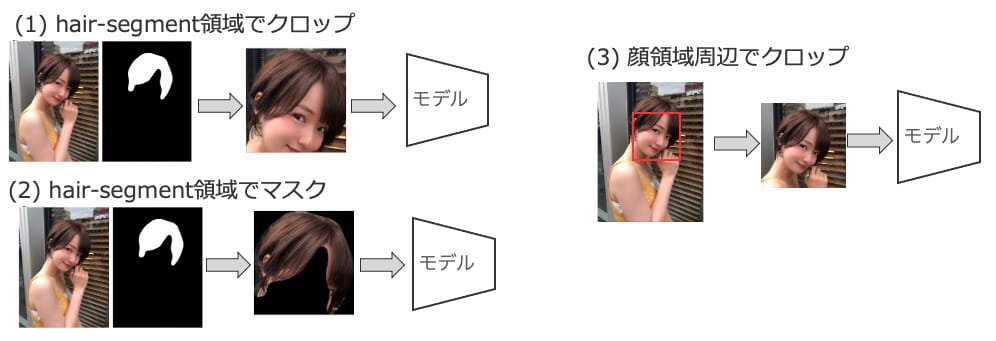
詳しい原因は調べられていませんが、ヘアスタイル画像はほぼ構図が一定で整っていることや、前処自体が失敗する場合があることや、「成人式」タグなどヘアスタイル以外の服装などが重要になる場合があるのが要因ではないかと推測しています。
うまくいかなかった取り組み:テキスト情報の利用
テキスト+画像のマルチモーダルモデルを検証しましたが、うまく精度があげられませんでした。タイトルと説明文を、Wikipediaの日本語データでpretrainしたfastTextのモデルでembeddingして以下の様に利用しました。
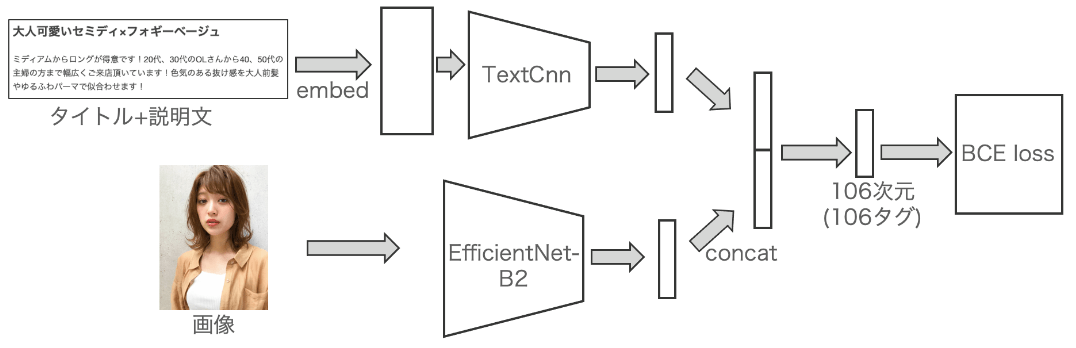
精度が上がらなかった理由として、タイトル+説明文がヘアスタイルの説明ではなくスタイリストの方の意気込みやメニューの紹介の場合があること、また、複数のヘアスタイル画像で同じテキスト情報の場合があることが要因ではないかと思っています。
今後の予定
学習方法の工夫として重みを適用するのみでしたが、学習の問題設定としてPositive-Unlabeled LearningやNoisy labelsの分野が適用できそうなので、それらの手法を試して精度改善できないかと考えています。
また、検索改善PJとしての次のPhaseで機械学習ランキングモデルの導入を検証していますが、入れると良さそうな画像素性の開発を予定しています。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました
- 伊藤 文啓
- 画像処理エンジニア
- サイエンス統括本部で画像処理エンジニアをしています。社内向けに画像解析のモデルやAPIを提供しています。