こんにちは、システム統括本部クラウドプラットフォーム本部の水嶋と申します。私は現在、社内向けにキューイング・Pub-Sub・ストリーミングなどのメッセージングプラットフォームを提供するチームに所属しています。
このチームでは、メッセージングプラットフォームとしてOSS Apache Pulsar(以降、Pulsar)を利用しています。この業務内でPulsarの機能改善に取り組み、OSSコミュニティーにプロポーザルおよび実装を提出しました。本稿ではその内容についてご紹介します。
また、2021年6月17,18日(JST)に開催されたPulsar Summitにてこの機能の詳細について発表しました(ただし、本稿執筆時点では未登壇)。Pulsar Summitとは、Pulsarに関連する発表に焦点を当てたカンファレンスです。過去に登壇した際の報告記事がありますのでカンファレンスの雰囲気を把握されたい方は、ぜひこちらもご覧ください。
ヤフーとPulsarの関わり
私の所属するチームはPulsarがOSS化される2016年9月頃から携わっており、Pulsarのコミッターも複数名在籍しています。このチームではヤフーの各プロダクト向けにPulsarを運用しつつ、社内における需要・事例をもとに機能拡張・バグ修正などの開発を通じたOSSへの貢献を行っています。
詳細については別記事を投稿しているのでこちらもご覧ください。
登壇内容
おもに、PulsarのPartitioned topicsのProducerについて(詳細は後述します)改善を試みた内容について発表しました。下記にスライドがありますので、興味がありましたら参考にしてください。
まずは、課題から説明します。ここからは、Pulsar特有の用語をいくつか使用しています。簡単な説明をできるだけ加えていますが、前提知識としては拙著ですが下記の記事も多少参考になるかと思います。
課題
社内のPulsarのユースケースの一つに図1のようなログ・メトリクス転送のパイプラインというものがあります。左記リンクが詳しいですが、簡単に言うとアプリケーションのログ・メトリクスをモニタリングプラットフォームに転送するための基盤としてPulsarを使おうというプロジェクトです。
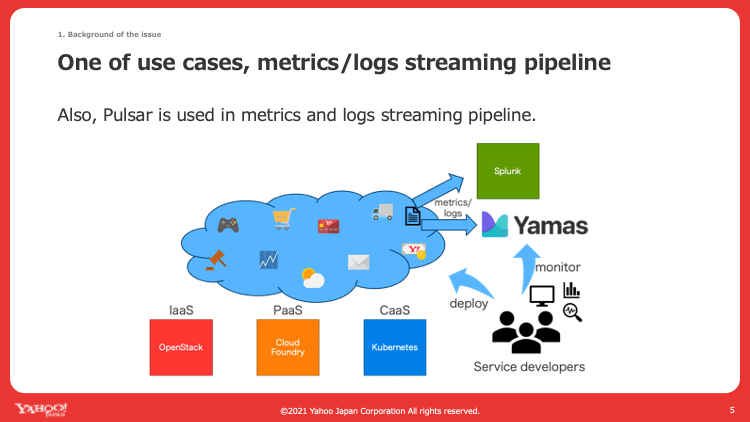
図1. ログ・メトリクス転送のパイプラインを説明したスライド
このプロジェクトを進める中で、Pulsar側の課題の中に下記のようなものがあることがわかってきました。図2では、それぞれの課題を模式図として示しています。
- Pulsar側の設定で1トピックあたりのProducer数上限を設定できるが、複数のコンピューティングプラットフォームから不特定多数のProducerを接続されることから上限を適切に管理することが難しい
- 1トピックあたりのProducer数上限はクライアント側でProducerを無制限に作成されてしまうような事象からBrokerサーバーを保護する目的で設定したい
- PulsarのPartitioned topicsという機能を利用する影響で、コンピューティングプラットフォームによってはある観点では冗長なProducerが大量に作成されてしまうことでリソースが消費される
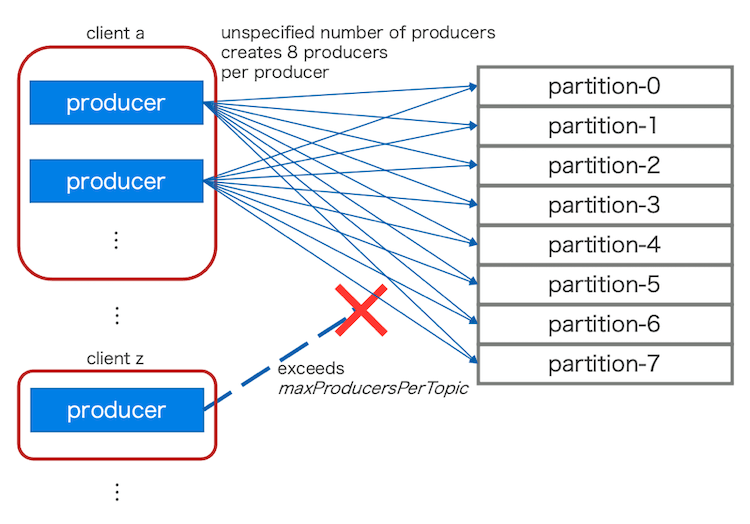
図2. 認識されていた課題の模式図
今回は、2点目の課題を解消するための方法をメインに議論を進めています。ある観点では冗長とは、たとえば下記のような例が挙げられます。図3はそれぞれの例を含んだ模式図です。
- Partitioned Topicが処理することのできるキャパシティーと比較して低いレートのProducer
- Partitioned topicsでは内部に複数のトピック(以降、パーティションとも呼ぶ)を作成することで利用するが、このパーティション数は必要なキャパシティーに応じて設定される
- Producerから見ると、パーティション数だけ内部にProducerを作成する必要がある
- キャパシティーに対してProducerの送信レートが低かったとしてもすべてのパーティションに接続する必要があり、これが余計である可能性がある
- 全Producerの送信レートが低く、かつ合計したレートも低いならばそもそもパーティション数自体を低く定義すればよいが、それ以外のレートが混在する場合などは低く定義するべきではない
- Partitioned topicsでは内部に複数のトピック(以降、パーティションとも呼ぶ)を作成することで利用するが、このパーティション数は必要なキャパシティーに応じて設定される
- SinglePartitionルーティングモードを利用するProducer
- SinglePartitionルーティングモードは最初に選出した1パーティションにだけメッセージを送信するモード
- ルーティングモード: Partitioned topicsで実際にメッセージをどのパーティションにどのようなルーティングで送信するかを選択する機能およびその設定
- 選出されなかったパーティションにも内部でProducerを作成しており、これが余計である
- SinglePartitionルーティングモードは最初に選出した1パーティションにだけメッセージを送信するモード
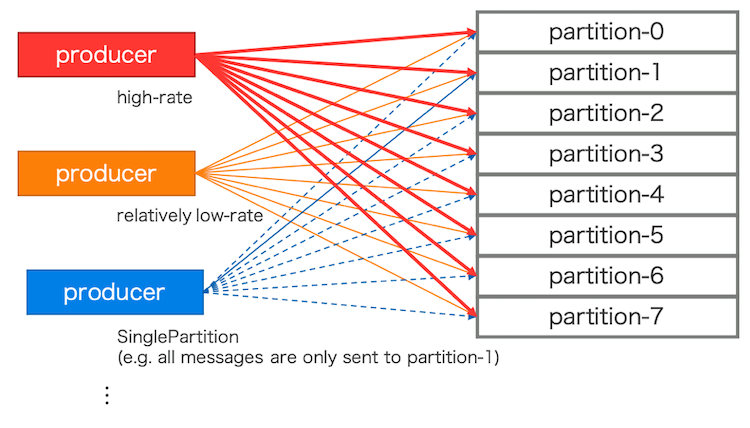
図3. 認識されていた課題の模式図 - 2点目の課題
これらの冗長なProducerを削減することによって、リソースをより有効に活用できないかを考えました。
解決策
解決策として、下記のような実装をしました。
- Partitioned topicsのProducerにて内部のProducer作成を遅延
- 一部パーティション内でのround-robinを実現するルーティングモードの作成
それぞれ簡単に説明します。
Partitioned topicsのProducerにて内部のProducer作成を遅延
Partitioned topicsの仕様ではルーティングモードに依存せず、まず全パーティションのProducerを作成するとなっていました。この仕様について、ルーティングモードに依存して必要なパーティションのProducerのみを作成するように変更したいと考えました。
この解決策としてProducerの作成を最初にすべて完了してしまうのではなく、ルーティングモードによってパーティションにメッセージを送信する際にProducerが作成されていなければ作成して送信するという、遅延作成の仕組みを導入しました。この結果、任意のルーティングモードで必要に応じてProducerが作成されるようになりました。たとえばSinglePartitionルーティングモードでは特定の1パーティションしか選出されないため、結果的に1 Producerしか作成されないというように動作します。
図4はこの仕組みを模式図で説明しています。遅延作成を取り入れることで、必要に応じて図中で言う破線のProducerが作成されるようになりました。
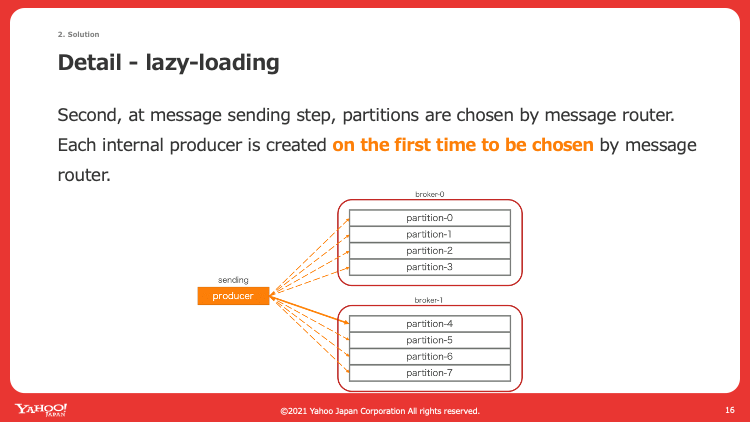
図4. Producer遅延作成の仕組みを説明したスライド
一部パーティション内でのround-robinを実現するルーティングモードの作成
上記によって内部のProducerはルーティングモードに依存して作成数が変わるようになったため、新たにルーティングモードを作成することにしました。具体的には、図5のように一部のパーティションを選出してその中でround-robinルーティングでメッセージを送信するという実装です。パーティション数はProducer側で独自に設定可能です。
これによって各Producerのレートに応じて必要なパーティション数にだけ接続しつつ、かつround-robinによる負荷分散が期待できます。
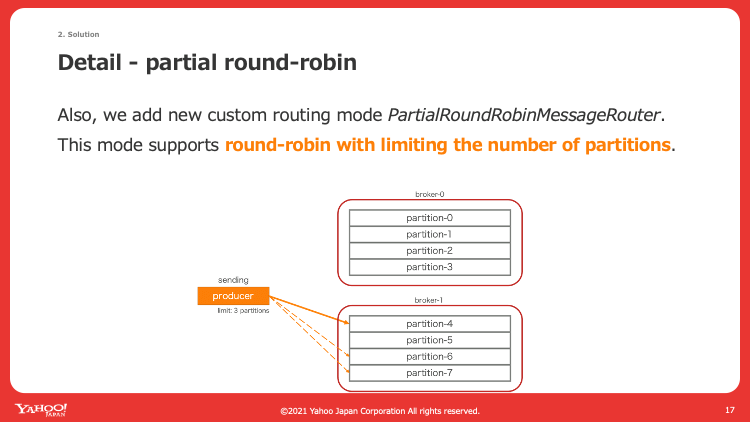
図5. 一部パーティション内でのround-robinを実現するルーティングモードの仕組みを説明したスライド
検証
前述の実装について、簡単な比較実験によって効果を検証することにしました。まず、前提は下記のとおりです。
- メッセージはバッチ処理しない
- ルーティングモードは一部パーティション内でのround-robin(提案手法のとき)か全パーティションでのround-robin(既存手法のとき)を選択
- Partitioned topicは30パーティションで作成
- メッセージは1024 bytes、5000 msgs/secで送信
次に、確認する指標は下記のとおりです。
- Brokerサーバーのヒープ使用量, CPU使用率
- クライアントのヒープ使用量, CPU使用率
- クライアント-Broker間のTCPコネクション数
- Producerの初期化時間
次に、実験手順は大まかには下記のとおりです。
b台のBrokerサーバーを起動- 一部パーティション内でのround-robinのときに設定するパーティション数は
lを設定 - 10分間メッセージを送信
- 統計情報を確認
実験結果自体はスライドで紹介しているので具体的な数値は省略します。ここでは、まとめた結果とそこから得られた考察を述べます。
クライアント側では次のような結果と考察が得られました。
- Producerの初期化時間は既存手法より早い
- TCPコネクション数は既存手法以下の数で収まる
- クラスタに十分なBrokerがあることを仮定したとき、TCPコネクション数は
ルーティングモードのパーティション上限数 + 1が上限になる - 現実にはBroker数も、この数値の上限になる
- クラスタに十分なBrokerがあることを仮定したとき、TCPコネクション数は
- ヒープ使用率は既存手法より小さい
- いくつかのケースでCPU使用率の変化は既存手法より安定している
Brokerサーバー側では次のような結果と考察が得られました。
- ヒープ使用率に大きな差異は見られない
- Broker間のCPU使用率の差が提案手法のほうが大きい
- おそらくパーティションへの負荷が分散しきっていないため
- レートに応じてパーティションの上限を適切に選択するか、あるいは現状のパーティションの負荷を考慮してルーティングするモードを実装するなどの工夫が必要
- 実際に稼働する(ヒープ・CPU使用率が増加する)Broker数は既存手法より少ない
- 実際に稼働するBroker数は内部のProducerが接続するパーティションに依存する(1トピックは1 Brokerが担当)ため
おわりに
登壇内容と本稿についてまとめます。登壇内容については、結論として次のようにまとめています。
- Producerの遅延作成と一部パーティション内でのround-robinを実装
- 既存手法との比較実験を実施して実験における特徴を確認
- 提案手法は主にクライアントのリソースとBrokerサーバーの負荷に影響を与えることを確認
- クライアントのリソース: 特にTCPコネクション数は既存手法以下となることがあり、期待したとおりリソース使用量を削減できた
- Brokerサーバーの負荷: 特にBroker間のCPU使用率の差は提案手法のほうが大きく、ケースによってはリソース使用量がBroker間で偏った結果、特定のBrokerでは期待に反してリソース使用量が大きくなる可能性がある
- 利用時はレートに応じてパーティションの上限を適切に選択する、現状のパーティションの負荷を考慮してルーティングするモードを実装するなどしたほうが良さそう
- 提案手法は主にクライアントのリソースとBrokerサーバーの負荷に影響を与えることを確認
- 今後の展望
- 今回の実装はJavaクライアントでのみ実装しているため、その他のクライアントでも同様の実装を導入
- e.g. C++, Go
- 今回の実装はJavaクライアントでのみ実装しているため、その他のクライアントでも同様の実装を導入
今回の登壇や記事の執筆について感じたことをまとめます。登壇した内容は執筆時点でプロポーザルおよび実装のPull-Request(以下PR)を提出している状態です。以前より何度かPRを出すことはありましたが、プロポーザルとしてOSSコミュニティーと対話しながら設計の議論を深めるのは筆者にとって初めての体験となりました。
印象的だったのは、コミュニティーのさまざまなメンバーからコメントをいただいた点です。社内で設計・実装をする場合には基本的に同一チームのメンバーやステークホルダーからのレビューをいただくことが一般的でした。当然かもしれませんが、OSSコミュニティーに出してみるとよりさまざまな見解や別方針の提案などをいただくことがありました。たくさんの方の意見をいただくことで機能をよりよく改善できるという利点や、方針が違った際にどうすり合わせていくかなどコミュニケーションが難しいといった課題点を再認識しました。
今回の体験を生かして、よりPulsarの改善に取り組みたいと考えています。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました
- 水嶋 雄里
- メッセージングプラットフォーム エンジニア
- Apache Pulsarをベースにしたメッセージングプラットフォームを開発・運用しています。



