こんにちは。CTO直下のR&D組織での技術開発およびサービス現場での展開を担当している湯川と申します。
現在、私が所属しているチームでは近似近傍密ベクトル検索エンジンのValdの開発を行っています。今回の記事では、そのValdについて開発背景から特徴や導入事例について紹介していきたいと思います。ベクトルを利用した類似検索を行いたい方、ベクトル検索の活用例を知りたい方の参考になれば幸いです。
Valdの概要

ValdはKubernetes上で動作するANN(Approximate Nearest Neighbor)を利用した密ベクトル近似近傍検索エンジンであり、NGT(後述)と同様にOSSとして開発されています。
※NGTはヤフーが開発・提供を行なっているOSSであり、Valdはヤフーが開発サポートしているOSSです。
※近傍検索については、こちらの記事をご覧ください。
ValdはCloud Nativeな設計思想に基づいてGoとC++を使用して開発されており、複数のコンポーネントを組み合わせることで動作します。(NGTの機能のみを利用するのであれば、後述するVald AgentをDockerで動作させることで利用可能です。)
数十億規模の特徴ベクトルデータからの検索が可能な水平スケーリング性を持ち、ユーザーの利用方法に応じて必要なリソースのみを利用して構築が可能です。
従来の課題と、Valdの開発背景
Valdの詳細に入る前に開発背景について述べていきます。
Yahoo! JAPANでは、高次元ベクトルデータ検索技術のNGT(Neighborhood Graph and Tree)を開発し、OSSとして提供しています。

NGTはANNベクトル検索エンジンの中でも世界トップレベルの高速高精度な検索エンジンとして知られています。
また、NGTのサーバー機能が実装されたNGTDがヤフーのOSSとして開発・提供されています。NGTDを利用するにあたり、以前から以下のような課題が存在していました。
障害発生時のリカバリー処理が別途必要
- NGTDではインスタンスのメモリ上にIndexを保存しています。障害発生時などにIndexをリカバリーするためには、メモリ上に保存されたIndexをバックアップして保存しておく必要があります。
複数VMを並列して利用する場合、メモリ使用率に偏りが生じやすい
- NGTDを並列で利用する場合、各インスタンスにIndexされるベクトルの数が均一にならないためメモリ使用率に偏りが生じやすくなります。
VMを変更する場合の運用が必要
- VMを変更する場合、インスタンスのプロビジョンニングやIPアドレスの変更など運用作業が発生します。
大量のデータを扱うためには、ハイスペックなマシンまたはシャーディングが必要
- 保存するIndex数の増加に比例してメモリの使用量も増加します。そのため、大量のデータを扱うためにはハイスペックなマシンリソースが必要です。これが難しい場合、シャーディングを行う必要性がありますが、シャーディングにもデメリットが存在します。
そこで、これらの課題を解決してNGTを活用することを目指してValdを開発することにいたりました。
代表的なコンポーネントの紹介
Valdには複数のコンポーネントが存在し、利用方法に応じて組み合わせて利用できます。その中でも、代表的なものを3つ紹介します。
Vald Agent
Vald Agentは、ValdのCore機能である近似近傍検索コアエンジンです。 具体的にはベクトルデータの登録、更新、削除と検索クエリに応じた近似近傍ベクトルの検索を行っています。
現在は、NGTをコアエンジンとして利用しています。Vald LB Gateway
Vald LB Gatewayは、その名の通りロードバランス機能を担当しています。 外部から受けたリクエストを各Vald Agentに流します。
Vald Discoverer
Vald Discovererでは、Kubernetes APIから取得した情報を基にサービスのディスカバリーを行います。
Valdの特徴
ここでは、Valdの大きな特徴であるIndex管理機能とFilter機能について紹介します。
Index管理機能
Valdを利用する上でベクトルのIndex管理は非常に重要です。Valdではこの管理を極力自動化することで運用者の負担を削減しています。具体的には以下の機能を実装しています。
バックアップ機能
バックアップ機能では、外部データベースまたはKubernetes Persistent Volume(以下、PV)を利用します。検索対象となるベクトルに対して、Insert/Update/Upsertいずれかのリクエストを受けた際に、利用している外部データベースまたはPVにメタデータのバックアップを保存します。
さらに、Index作成時にVolumeがある場合のみS3にIndex構造をアップロードできます。リカバリー機能
リカバリー機能では、Vald AgentのPod起動時に外部データベースとS3に作成されたバックアップからIndex情報を復元します。
これによって、運用者側で再度ベクトルをInsertする必要がなくなります。ライブ更新機能
新しいベクトルのInsert時に、サービス停止なしでIndexingを行うことができます。
レプリケーション機能
1つのベクトルデータに対して1つのVald Agent PodのみにIndexingしている状態でPodに障害が発生したり再起動した場合、当該PodにIndexingされているベクトルは検索結果として取得できません。
Valdでは複数のPodに一定量の重複したベクトルをIndexすることで、予期しないPodの再起動やローリングアップデートが起こった際にも、検索結果に影響が出にくい仕組みを実装しています。 (レプリケーション数は利用者で設定することができます。レプリケーション数の3倍程度のPodを起動することを推奨しています。)
- 補足
バックアップ機能、リカバリー機能を利用するためにはそれぞれ外部データベース、S3ストレージが必要になります。
Filter機能
Valdでは、現時点でVald Ingress Filterという名前のFilterを提供しています。ValdにIndexingする際、画像などのオブジェクトデータを機械学習モデルなどを用いて事前にベクトル化する必要があります。
Vald Ingress Filterでは、任意のデータをベクトルに変換し、そのベクトルを実際にIndexingすることを可能にします。現時点では、TensorFlowと連携をしています。
Valdの導入事例
Valdの概要や特徴についてご理解いただいたところで、実際にValdがどのようにサービスに導入されているか紹介していきます。
ヤフオク!
ヤフオク!では、商品出品時に登録する画像タイトルの推定に利用されています。
ラベリングされた画像を事前に学習した機械学習モデルを利用してベクトル化し、ValdにIndexingして利用しています。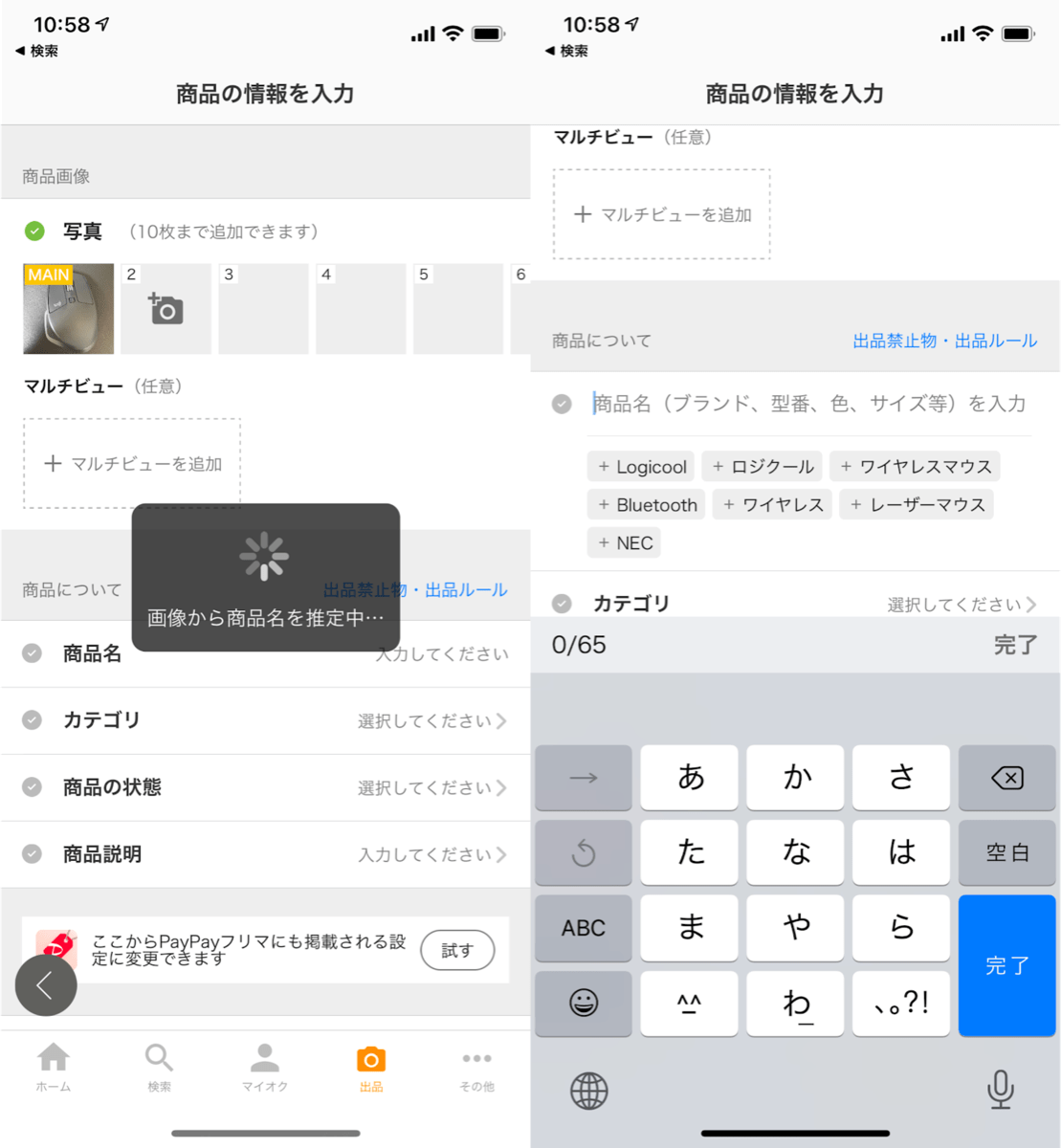
Yahoo!ショッピング
Yahoo!ショッピングでは、類似商品画像検索に利用されています。 (現在は、アパレルカテゴリ・インテリアカテゴリの商品のみが対象)
類似した商品同士のベクトル空間上の距離が近くなるように学習したモデルからベクトルを生成し、ValdにIndexingして利用されています。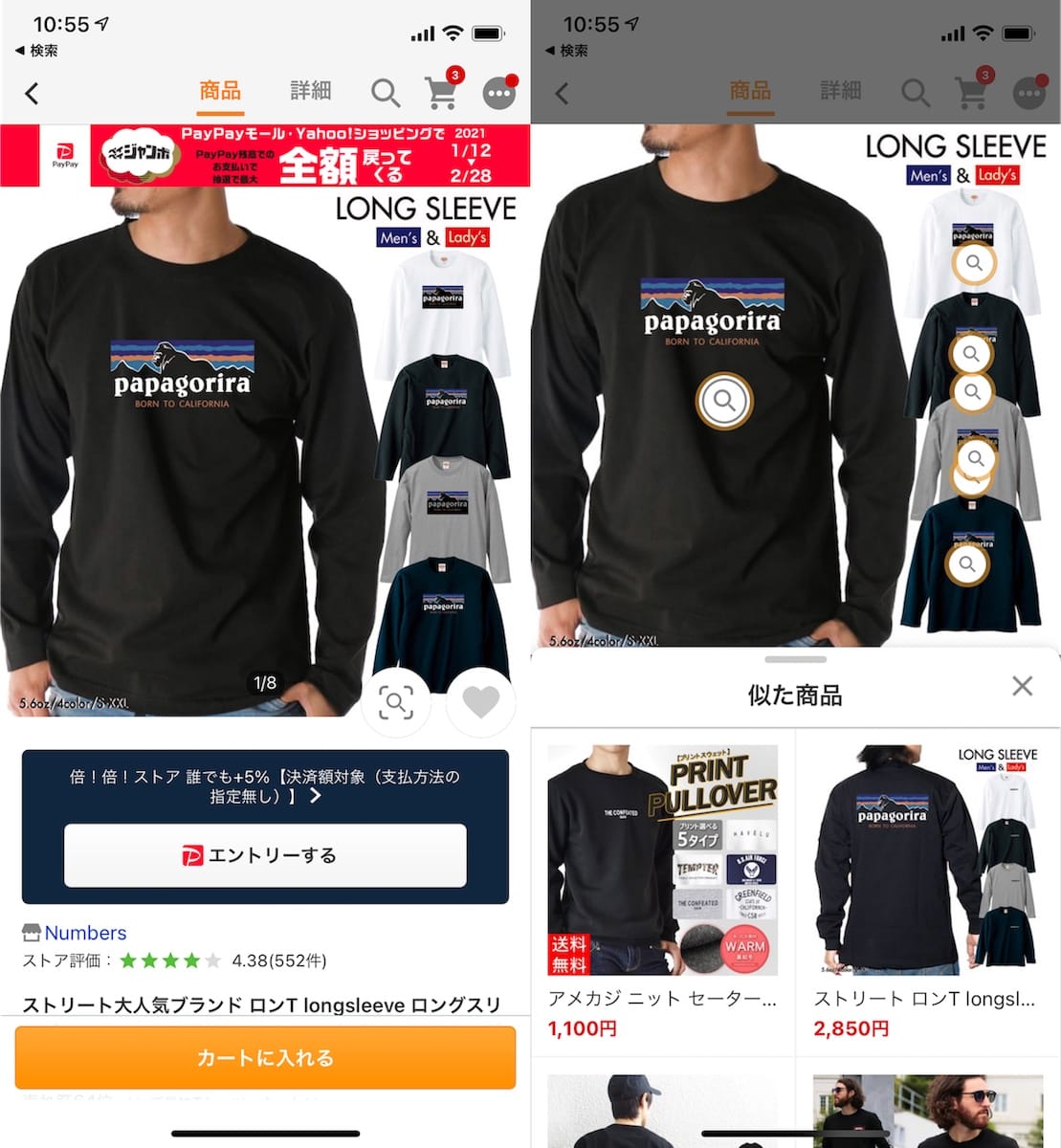 (引用:https://store.shopping.yahoo.co.jp/numbers/longsleeve-092.html)
(引用:https://store.shopping.yahoo.co.jp/numbers/longsleeve-092.html)mevie(Yahoo! JAPAN Hack Day 2021 Vald賞受賞作品)
先日オンライン開催で行われたハッカソン、Yahoo! JAPAN Hack Day 2021では、Valdは協賛として技術提供を行いました。 Valdを活用いただいたチームの中から、mevieという作品がVald賞を受賞しました。
mevieでは、音声データの自己紹介をテキスト変換し、BERTを用いてベクトル化を行います。 自己紹介文を利用して、自分と類似したユーザーを抽出しています。 作品プレゼン動画はこちらからご覧ください。
今後
現在のValdを利用する上で出てきた課題などを中心に新規機能として提供していく予定です。直近では、Vald Agentのメモリ使用率を平滑化させるためのRebalanceコンポーネントの開発やその他の新しい機能開発などを行う予定です。
気になった方はぜひ、Get Startedを試してみてください。
おわりに
近似近傍密ベクトル検索エンジンのValdについて開発背景から概要や事例紹介を交えて紹介しました。
OSSとして公開していますので、ぜひご覧になっていただければと思います。またValdのコミュニティが導入サポートも行っていますので、導入を検討している方はこちらからお気軽にご連絡ください!
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました
- 湯川 輝一朗
- CTOテックラボ エンジニア
-