
ベクトル近傍検索や、それを利用した物体認識・類似画像検索の研究開発を行っているYahoo! JAPAN研究所の岩崎です。最近ではテキスト、画像だけではなく商品やユーザーなどのさまざまなデータから深層学習を用いてそのデータの特徴を表すベクトルデータを生成した上で元データの代わりに検索することが一般的になってきています。ヤフーは、そのようなベクトルデータを検索するソフトウエアであるNGTをOSSとして公開しています。詳しくはこちらをご覧ください。
ベンチマーク結果
先日NGTの最新バージョンのベンチマーク結果がann benchmarksで公開されました。NGTのアルゴリズムの変更はありませんが、検索時の内部係数の最適化機能を改良したり、実装の高速化を行うことにより、トップレベルの結果になっています。ベンチマーク結果のグラフが公開されており、グラフの右上であるほど、性能が良い(精度が高く、処理が高速)であることを意味します。グラフ中のfaiss-ivfはFacebookが開発したソフトで、FLANNは画像処理ソフトのOpenCVにも実装されているソフトです。ご覧いただくと分かるように高精度側(グラフ右側)では、データセットglove-25-angular以外のすべてにおいてNGTがトップとなっています。つまり、NGTは高精度かつ高速性を両立した上でトップであることを意味しています。その上で、他のソフトウエアと比較して、NGTではデータの追加や削除が可能であったり、複数プロセス間でのインデックスの共有ができたりと、実用面の考慮もされています。実用面の機能が充実しているからこそ、実際に複数のヤフーのサービスに利用されています。例えば、最近発表された類似ファッション検索もその1つで、性能面のみならず実用面からもNGTが利用されている良い例です。
では、この機会にこのベンチマークテストを提供しているann benchmarksも紹介します。
ann benchmarksとは
ann benchmarksは近傍検索用のベンチマークテストであり、高次元ベクトルの近傍検索の研究分野では有名なテストです。近傍検索ツール annoy(Spotify)の開発者Erik Bernhardssonがこのベンチマークの開発者でもあります。コペンハーゲンIT大学のMartin AumüllerとAlexander Faithfullがann benchmarksをサポートしているようです。
このベンチマークの作者によるannoyはもちろん、FLANN、faiss(Facebook)、hnsw などの主要な近傍検索の手法がこのベンチマークで比較評価されています。ベンチマークには画像系やテキスト系の多様なデータセットが使用されていて、かなり難しいものになっています。25から960次元までの多様な次元のデータセットを対象としていますが、データ数は最大でも118万なので、近年の研究トレンドからするとデータ数としては比較的少ないです。距離関数は各データセットで決まっており、ユークリッド距離、コサイン類似度(正確には1-コサイン類似度)が利用されます。
検索時には1クエリごとに10件(変更可)のk最近傍検索の処理時間を測定します。バッチ検索も実装されていますが、通常使われていません。評価尺度は再現率対処理クエリ数(毎秒)であり、そのグラフが公開されています。
ベンチマーク対象の個々の手法は以下のように別々のdockerのコンテナ内で動作するので完全に独立しています。
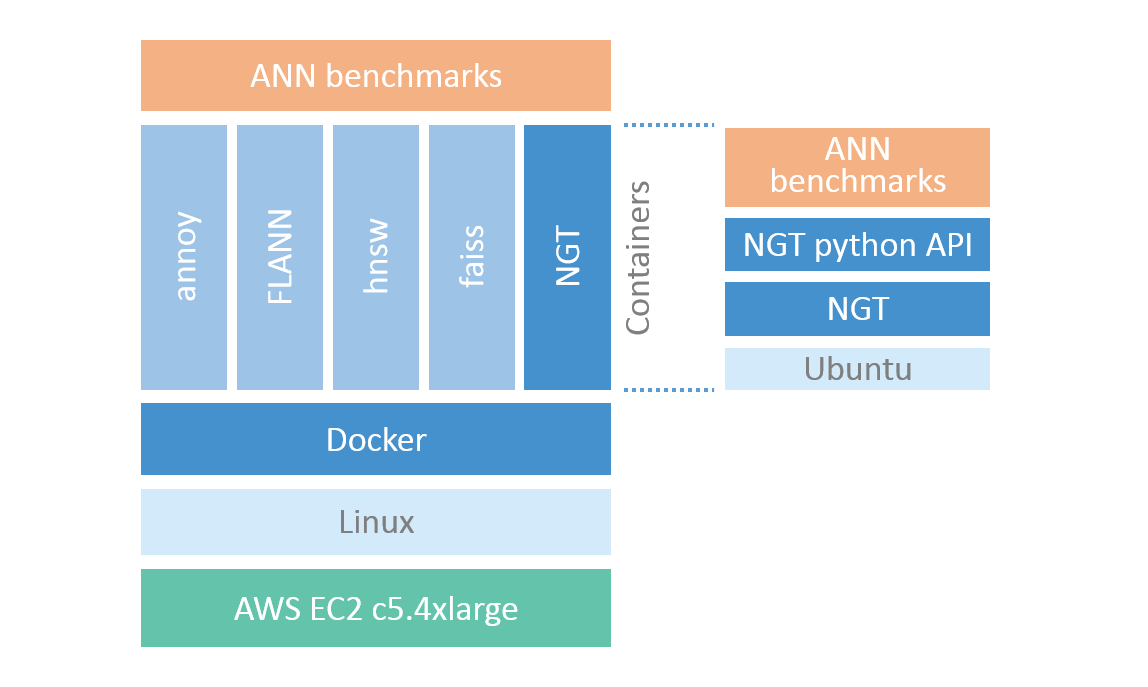
ベンチマーク実行時には各手法ごとのコンテナが1つずつ起動されます。コンテナ実行時にはCPUは1つに制限されるので、並列処理の実装の有無に影響されない公平な評価が行われます。新しい手法が提供された時にベンチマークが実行されて、その結果が公開されます。なお、ベンチマーク自体はAWSのEC2 c5.4xlargeで動かすことが指定されているので、誰でも、そのインスタンスでベンチマークを実行し、結果をプルリクで提供することが可能です。ただ、すべてを実行するのに2週間程度を要します。今回のベンチマーク結果はNGTのバージョンアップに伴い自前で実行したデータを提供しました。
組み込み方法
自前で近傍検索手法を実装している人は少ないとは思いますが、そんな人のためにann benchmarksに新たな近傍検索手法を組み込む方法を説明します。
実行単位となるコンテナはOSがubuntuなので、組み込みたい近傍検索手法はubuntu上で動作することが必須です。ベンチマーク自体はpythonで記述されているので、pythonからインデックスを生成、検索できればベンチマークに組み込むことができます。NGTの場合、インデックスの生成と検索はNGTのpython APIを利用していますが、NGTのグラフ生成後の最適化にはNGTのコマンドを実行しています。少なくとも検索部分は検索時間を最小限に抑える必要があるので、pythonのAPIから直接検索処理を呼び出すように実装する必要があります。
インデックス生成と検索を合わせた実行時間が5時間に制限されているので、並列処理を前提に実装している場合には、予想外にインデックス生成に時間が掛かりすぎて制限時間を超えるといったことがあり得ます。当初NGTも精度優先でインデックスを生成していたので5時間以内に終了しないデータセットがありました。
組み込む手法に対して手法独自の環境構築用のDockerファイル、pythonのAPIのクラス、そしてテスト時のパラメータを用意してalgos.yamlに記述すればベンチマークに組み込むことができます。Dockerファイルは他の手法の記述を参考にすれば特に問題ないはないでしょう。NGT(ONNG)のパラメータはalgos.yamlのこの部分に記述しています。このパラメータが渡されるpythonのAPIのクラス作成が組み込み作業の主要部分だと言えます。NGTのクラスを例に用意しなければならないクラスのメソッドを説明します。
- コンストラクタ
インデックス生成用のパラメータが渡されます。base_argsとargsが渡されるので、このパラメータをクラス内に保存します。 - fit()
インデックス生成のデータが渡されるので、保存しておいたパラメータに基づきインデックスを生成します。 - set_query_arguments()
検索用のパラメータが渡されます。query-argsのパラメータが1つずつ渡されるので、このパラメータをクラス内に保持します。 - query()
クエリデータが渡されるので、保存しておいた検索パラメータに基づき検索して結果を返します。
ann benchmarks の紹介は以上です。容易に組み込めてさまざまな手法と比較できるので、近傍検索手法の研究者や開発者は自身の手法を組み込んでみると良いと思います。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました



