こんにちは。ヤフーで画像認識技術の研究開発を担当している西村と土井です。
今年の7月、Yahoo!ブラウザー(Androidアプリ)にスポット検索機能がリリースされました。これは画像から検索できる「カメラ検索」の一部で、施設や観光名所などを撮影するかスマホ内の写真を選択すると、スポット名称・関連画像・住所・営業時間などの情報が表示されます。
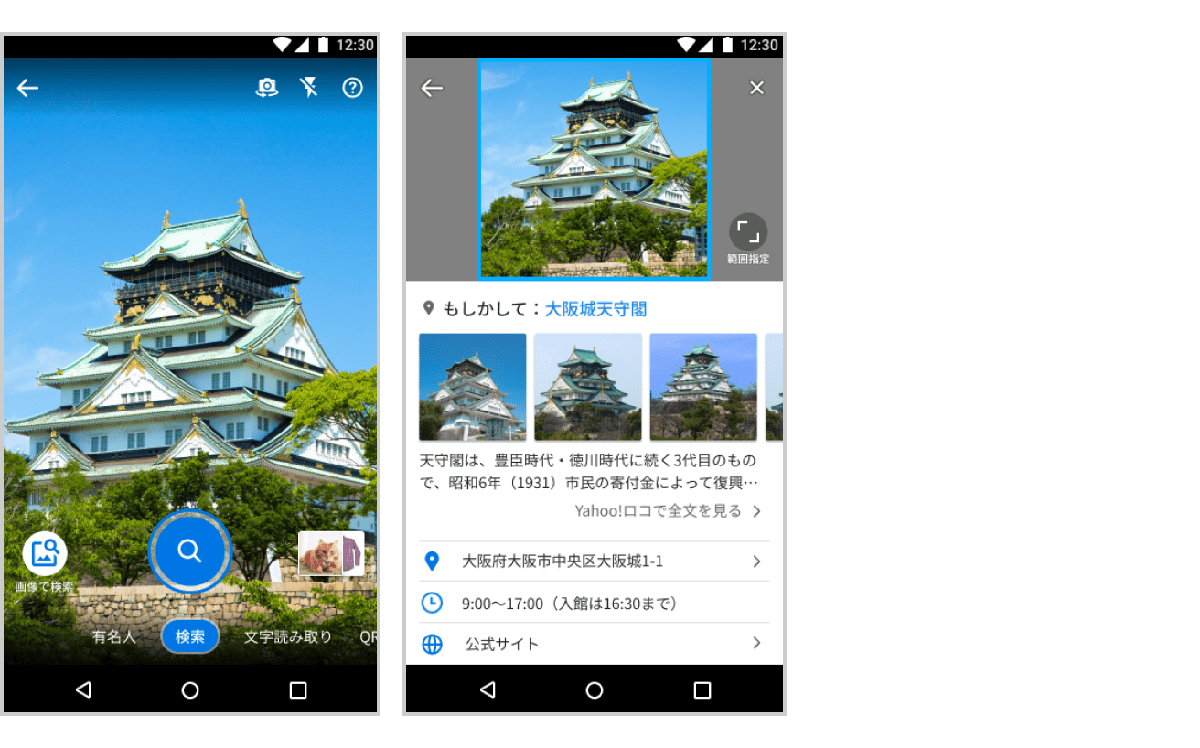
私たちのチームでは本機能のバックエンドで使用されているモデルから認識APIまでを開発、提供しています。本記事ではスポット検索技術開発の取り組みについて紹介します。
スポット検索の仕組み概要
Yahoo!ブラウザーアプリの機能上は『スポット検索』であり、『検索』の体験に主軸が置かれた名称になっていますが、私たちが提供している技術としては『認識』になります。また、認識対象のスポットは国内のランドマークとして一般的に認知されているスポットに限られます。
現在認識可能となっているランドマーク数は約2万です。
ランドマーク認識処理は、プレフィルター処理、画像の特徴量抽出処理、認識処理の3つで構成されています。
プレフィルター処理では、小規模な二値分類モデルを用いて、クエリ画像がランドマーク認識向けの画像かどうかを判定し、もし適切ではない画像であれば後続の処理を飛ばして、早期に結果を返却します。特徴量抽出は後述の特徴量モデルを用いて、画像から512次元の特徴量を抽出します。認識処理では、抽出した特徴量をクエリとして、予め作成してある特徴量インデックスを検索し、検索結果のshort-list(Top-K)から最終的な認識結果を決定します。
以下より、特徴量モデルやシステムの詳細を紹介していきます。
モデル開発
サイエンス統括本部画像処理チームの土井です。ここからはスポット検索に利用した各種モデルの開発についてご紹介します。
プレフィルター処理用モデルの開発
プレフィルターモデルとして、入力された画像がランドマークかどうかを2値分類するモデルを開発しました。学習データには、ランドマーク画像としてGoogle Landmarks Dataset v2を抜粋したものと、ランドマークではない画像として内製したデータセットを組み合わせたものを利用しました。
また、実際にサービスで利用することを想定したオンライン推論用の軽量なモデル(EfficientNet Lite0を利用)とオフラインでのインデックス画像のフィルタリング用途等を想定した精度重視のモデル(ResNeSt101eを利用)の2種類を作成することとしました。PyTorch Image Models (timm)の学習済みモデルをbackboneとし、2値分類用のheadに付け替えたモデルを上記のデータセットで学習し、分類精度(AUC)が0.9以上の2つのモデルを作成しました。
入力画像サイズや識別精度の詳細は下表の通りです。
| モデル用途 | backbone | 入力画像サイズ | 識別精度(AUC) |
|---|---|---|---|
| 速度重視モデル | EfficientNet Lite0 | 224x224 | 0.9028 |
| 精度重視モデル | ResNeSt101e | 256x256 | 0.9332 |
画像特徴抽出モデルの開発
画像特徴抽出モデルについては、社内の有志で過去に参加したKaggleのGoogle Landmark コンペ等で利用したモデルを採用しました。
モデルの学習にはGoogle Landmarks Dataset v2をベースにクリーニングを実施したデータセットとYahoo!ロコの画像等から構成される内製のランドマークデータセットを利用しています。
(※モデル作成にあたり、ヤフーではお客様のプライバシーの保護に細心の注意を払っています。詳しくはYahoo! JAPAN プライバシーセンターをご覧ください。)
データセットの詳細
Google Landmark Dataset v2 は約500万枚のランドマーク画像からなるデータセットです。昨年Kaggleで開催されたGoogle Landmark Retrielval/Recognitionコンペでは、このデータセットをベースにノイズ画像等を除去したサブセットのデータセット(約160万枚)が提供されていました(下表の参考に記載。このサブセットは過去のLandmarkコンペ優勝チームが作成したものです)。
今回開発した特徴抽出モデルの学習には、Kaggleで提供されたサブセットではなく、独自にクリーニング処理を実施したデータセット(クリーニング処理の詳細については後述のインデックスの生成とクリーニングを参照)と内製のランドマークデータセットを組み合わせて利用しています。内製ランドマークデータセットについてもクリーニング処理を実施しています。
また、Google Landmark Datasetには日本のランドマークも含まれているため、内製の日本国内のランドマークのデータセットと組み合わせる際に、同一のクラスはマージしています。
各データセットの詳細は下表のとおりです。
| データセット種別 | クラス数 | 画像枚数 | 対象地域 |
|---|---|---|---|
| Google Landmark Dataset(独自クリーニング版) | 137,130 | 1,689,380 | 全世界 |
| 内製ランドマークデータセット | 5,655 | 477,830 | 日本国内 |
| 学習に利用したデータセット | 142,753 | 2,167,210 | 全世界 |
| (参考)KaggleのGoogle Landmarkコンペ提供データ | 81,313 | 1,580,470 | 全世界 |
特徴抽出モデルの詳細 (eca_nfnet_l2)
モデルのbackboneにはPyTorch Image Models (timm)のeca_nfnet_l2を利用しており、モデルのpooling層とクラス分類層を外してbackboneとして利用しています。この特徴抽出モデルをCurricularFaceLossを使って学習しています。
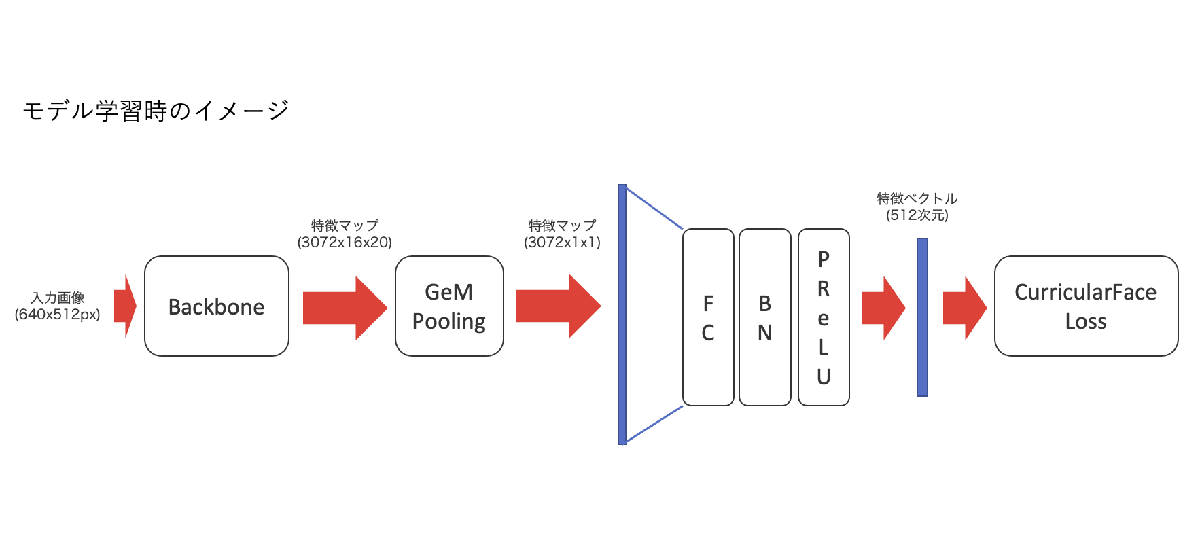
開発過程では、ArcFaceLoss等も試しましたが、CurricularFaceLossのほうが精度が良好だったため、こちらを利用しています。
インデックスの生成とクリーニング
CTOテックラボの西村です。ここからは前述の特徴量モデルを用いて、どのように認識システムが実現されているかを紹介します。
認識処理のコアとなる特徴量インデックスはYahoo!ロコをメインに国内のランドマーク画像により構築された内製のデータセットをベースに作成します。
認識のアルゴリズム上、前段の検索に用いるインデックスの質は認識結果の精度に直結します。Yahoo!ロコ等の画像にはノイズが多く、そのままインデックスに使うことは難しいという問題がありました。ノイズには大きく分けて以下の3種類があります。
- ランドマークとは関係の無い画像 (料理の写真、旅館の客室など)
- 対象ランドマーク以外のランドマークが同時に写り込んでいる画像 (東京タワー、富士山など)
- 異なるランドマークの画像が混ざっている (ホテルの近隣の観光名所を紹介するために投稿された画像など)
(1)に関しては、前述の精度が高い方のプレフィルターモデルでフィルタリングします。
完璧では無いものの、ある程度のノイズは除去できました。
(2)に関しては、Image Matchingのモデルを用いて他のランドマークが写り込んでいる可能性が高い画像を除去しています。まず重要度が高いと考えられる国内の有名なランドマークを1,000クラス抽出し、それらに対して人手でインデックスする画像を30枚程度選択します。この段階でこれら1,000クラスはノイズが無いことが確実になっています。
次にこれら1,000クラスの画像を参照画像、他の全画像をクエリとして、Image Matchingを実行し、除去すべき画像を抽出します。この処理を全ての組み合わせで実行するのは時間がかかるため、前述の特徴量モデルでの検索結果と組み合わせて計算コストを削減しています。現段階では、この処理は控えめな設定で実行しており、まだそれなりの割合でノイズが残っていますが、今後改善の余地があると考えています。Image MatchingにはkorniaのLoFTRを利用しています。比較したいくつかの手法の中で、この用途に関しては、LoFTRが精度、速度の両面で優れていました。
(3)に関しては、(2)である程度対応できるものの、(3)に起因する認識の失敗は特にユーザ体験の悪化に繋がりやすいと考えており、ホテル等のカテゴリに対しては、誤認識を減らすための追加の後処理を入れています。しかしながら、国内には観光地のランドマークとなっているようなホテルも多いため、今後の取り組みの課題としています。
システム

Yahoo!ブラウザーのスポット検索システムは比較的小規模であり、認識用インデックスもそれほど大きくないことから、認識APIはNVIDIAのTriton Inference Serverを用いてプレフィルター、特徴量抽出、認識をまとめて動かしています。(上図においてプレフィルター処理は省略されています)
私たちサイエンスチームからはこのTritonベースのDockerイメージをサービス側に提供し、Yahoo!ブラウザーチームはヤフーのAIプラットフォームのCuttySark上にデプロイすることで、運用コストを削減できています。
おわりに
本記事ではYahoo!ブラウザーアプリのスポット検索機能で使われている技術について紹介しました。
私たちの所属する画像処理チームでは、社内のさまざまなサービスと連携しながら、コンピュータビジョン、画像認識領域の技術開発や応用に取り組んでいます。現在、弊チームの機械学習エンジニアのポジションを募集しておりますので、ご興味がありましたら、ぜひご応募ください。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました
- 西村 修平
- CTOテックラボ 画像処理エンジニア
- 土井 賢治
- テクノロジーグループ サイエンス統括本部 機械学習エンジニア
- 社内のさまざまなサービスと連携しながら画像認識領域の技術開発や応用に取り組んでいます。
-



