
こんにちは! ヤフー株式会社の栗原と申します。私は現在、キューイング, Pub-Sub, ストリーミングなどを実現するためのメッセージングプラットフォームを社内向けに提供するチームに所属しています。
OSS Apache Pulsar(以降、Pulsarと記載します)を紹介するこのシリーズも4回目、今回は先日行われたPulsar Summitの参加報告をしたいと思います。
Pulsarの仕組みや基本的な使い方については過去の記事をご覧ください:
- メッセージングPF「Apache Pulsar」の使い方(入門編)
- メッセージングPF「Apache Pulsar」の使い方(クライアント編)
- メッセージングPF「Apache Pulsar」の使い方(クライアント編2)
ヤフーとPulsarの関わり
私の所属するチームはPulsarがOSS化される2016年9月頃から携わっており、Pulsarのコミッターも複数名在籍しています。このチームではヤフーの各プロダクト向けにPulsarを運用しつつ、社内における需要・事例をもとに機能拡張・バグ修正などの開発を通じたOSSへの貢献を行っています。
詳細については別記事を投稿しているのでこちらもご覧ください。
Pulsar Summitとは
Pulsarに関連する発表に焦点を当てたカンファレンスです。
これまでApacheConやFlink ForwardなどでPulsarに関連した発表を行うことはありましたが、Pulsar単体でのカンファレンス開催はこれが初めてです。主催はStreamNativeとSplunkで、どちらもPulsarを利用したメッセージングプラットフォームをエンタープライズ向けに提供している会社です。主催以外にもいくつかの企業がスポンサーとして参加しており、ヤフーもその1つです。
開催地はもともとSan Franciscoが予定されていましたが、昨今の状況を鑑みてオンラインで開催されることになりました。2日間で31件の発表があり、内容はユースケース・エコシステム・特定の機能の詳細など多岐にわたっていました。また私自身もヤフーにおける利用例についての発表を行いました(時差があるため録画でしたが)。今回の記事ではそれらのいくつかを紹介したいと思います。
気になった発表
すべての発表スライド/ビデオはPulsar Summitのページから見ることができます:
https://pulsar-summit.org/schedule/first-day
今回発表のあったセッションは合計で31で、カテゴリーの内訳は下記のようになっていました:
| Category | # sessions |
|---|---|
| Keynote | 4 |
| Use Case | 10 |
| Operations | 2 |
| Technology Deep Dive | 9 |
| Ecosystem | 6 |
Use Caseではさまざまな導入事例が紹介されており、今後Pulsarの導入を考えている方には有用な発表だったと思います。次いで多いのはTechnology Deep Diveで、こちらは主にPulsar FunctionsやPulsar SQLなど機能の詳解が多かった印象です。またEcosystemではKafkaとの比較やSpark, Flinkなど各種データ処理基盤との連携についての発表がありました。
すべては紹介できませんが、以下に(独断と偏見で)気になった発表を紹介していきます。一部についてはスライドも載せていますので、併せてご覧ください。
Keynote
Pulsar Summitは6/17, 18の2日間開催されましたが、両日とも最初の2件はKeynote sessionとなっており、計4件の発表がありました。
個人的に特に気になったのは、やはり初日最初の講演であるPulsar: Messaging and Event Streaming - Adoption, Use Cases and the Future of Pulsarです。
発表者はMatteo Merli & Sijie Guo, 両名ともPulsarの黎明期から開発に携わってきた人物で、現在はApache PulsarおよびApache BookKeeperのPMCとして積極的に活動されています。
発表ではまずPulsar Summitそのものの案内・説明がありました。今回の参加人数はなんと550人以上! Pulsar単体の初のカンファレンスでありながらこれだけの人数が集まったということで、注目度の高さがうかがえます。
続いてSijie氏から近年のPulsar導入事例についての説明がありました。Pulsarは2018年にApache FoundationのTop Level Projectになって以来順調に導入企業が増えてきており、現在では600以上の会社において利用されているようです。また2020年初頭にPulsarを現在使っている人たちを対象に行われたSurveyの結果の報告も行われました。Surveyには30以上の項目があったのですが、例えば”What are the top 3 highlights for Pulsar?”という設問に対する回答のTop3は
- Architecture Design
- Scalability
- Resiliency
だったとのことで、CloudNative / Microserviceの時代においてPulsarのスケーラブルで柔軟なアーキテクチャが評価されているという印象を受けました。
最後はMatteo氏から今後追加予定の機能について説明がありました。個人的に特に気になったものは以下の2つです:
Readonly Brokers
Readonly Brokersは(produceではなく)consumeのみを受け付けるBrokerを設定する機能です。これまではトピックごとに担当のBroker(1台)が決まっており、すべてのProducer/ConsumerはこのBrokerに接続する必要がありました。そのためsubscription数が膨大なときは1台のBrokerに大量のConsumerが接続されることになり、トラフィックが偏るという問題がありました。Readonly Brokerを設定することで、Consumer側のトラフィックを分散させ、より高いスケーラビリティを得ることができます。
参考: PIP 63: Readonly Topic Ownership Support(外部サイト)
Partitions auto-scaling
Pulsarにはパーティションドトピックと呼ばれる機能があります。これは1つのトピックを複数のパーティションに分割し、担当Brokerを複数台に分散させることで、スループットを向上させる機能です。しかしパーティション数は手動で設定・変更を行う必要があり、適切な値を決めるのが難しいという課題がありました。これを負荷に応じて自動的に増減させる機能を開発中とのことで、利用者はもはやパーティション数の設定に悩む必要がなくなります。
どちらもPulsarのスケーラビリティをさらに高める機能追加で、ヤフーにおいても今後ますますの利用者数増加が見込まれているため、大きな期待を寄せています。
以上、特に”Pulsar: Messaging and Event Streaming - Adoption, Use Cases and the Future of Pulsar” について書きましたが、他の3つのKeynoteも興味深いのでぜひご覧になってください。Why Splunk Chose Pulsar, Finding your pulse for a global enterprise communications nervous system!ではそれぞれSplunk, TIBCOがなぜPulsarを採択したか、どのように使っているかの話を聞くことができます。またUnified Data Processing with Apache Flink and Apache PulsarではPulsarとFlinkの連携について述べられており、Flinkユーザー必見の内容です。
利用事例
まず気になったのはVerizon MediaのPulsar Storage on BookKeeper - Seamless Evolutionです。
この発表ではPulsarのストレージ部分であるApache BookKeeperに焦点を当て、アーキテクチャおよび利用するデバイスの変遷についてまとめられていました。
BookKeeperには
- Journal(先行書き込みログ用、容量より書き込み速度が重視される)
- Ledger(メッセージ永続化用、書き込み速度より容量が重視される)
という2種類のデータ保存領域があります。それぞれのデバイスについて、Verizon Mediaでは2015年から2020年にかけて下記のような変遷があったようです:
- Journal: HDD(RAID10)→SSD→SSD(NVMe)→PMEM
- Ledger: HDD(RAID10)→SSD→SSD(NVMe)
JournalにPMEMを使う現在の構成は”Ultra high throughput with low latency”とのことで、実際に各デバイスごとのパフォーマンスの差異をグラフで示していました。ちなみにヤフーではJournalにSSD, LedgerにHDD(RAID10)を使っており、今後の構成を考えていく上でとても参考になる発表でした。
Verizon Mediaからの発表は2件あり、もう1つのFive years of operating a large scale globally replicated Pulsar installation.では実際にどのようなフローでPulsarを運用しているかについて話されていました。Pulsarを生み出し最も古くから使い続けているVerizon Mediaの貴重なノウハウを聞くことができ、こちらも興味深い発表でした。
他には請求処理の基盤として使っている例としてHow Apache Pulsar Helps Tencent Process Tens of Billions of Transactions Efficiently, ストリーム処理や機械学習の基盤として使っている例としてEasily Build a Smart Pulsar Stream Processor_Simon CrosbyとFeature Stores: Building Machine Learning Infrastructure on Apache Pulsarがありました。どの発表も実運用上の構成例や利用方法などがわかり、非常に有益な発表でした。
他のメッセージングシステムとの比較
Apache Pulsarとよく比較されるソフトウェアとして、RabbitMQやApache Kafkaがあります。
Scaling Customer Engagement with Apache PulsarではRabbitMQからPulsarへの移行例が紹介されており、どんな課題があったか、なぜPulsarを選択したか、どのように移行を進めたかについて語られています。
Kafkaについては、Pulsarとの差異・比較に関する発表が2件ありました:
- Ten reasons to choose Apache Pulsar over Apache Kafka for Event Sourcing (CQRS).
- Pulsar for Kafka People
「現在Kafkaを使っているけどPulsarも気になっている」という方にとっては一見の価値ある発表かと思います。
関連して下記の発表もオススメです:
KoP(Kafka on Pulsar)とはKafkaのProtocolでPulsarにアクセスできるようにする機能です。Pulsarにはプラグインとしてプロトコルを追加する仕組みがあり、Kafkaの他にAoP(AMQP on Pulsar)やMoP(MQTT on Pulsar)などの追加が予定されています。これにより、現在他のメッセージングシステムを利用している場合でもすぐにPulsarを使い始めることが可能です。
参考:https://github.com/apache/pulsar/wiki/PIP-41%3A-Pluggable-Protocol-Handler
Pulsar Functions
Pulsar FunctionsはPulsar上で動く軽量なメッセージ処理の仕組みです。トピックに流れているメッセージに対するちょっとした加工処理やフィルタリングを、他のコンポーネントを立てることなくPulsar上で簡単に行うことができます。Pulsar Functions Deep Diveではその仕組み・実装について語られています。今後追加が予定されている機能の紹介もあり、例えばFunction Mesh: 複数のfunctionを連携できるようになる仕組みの追加など、さらなる進化にますます期待が高まりました。
Function Meshについてはこちらも参考にしてください:https://github.com/apache/pulsar/wiki/PIP-66%3A-Pulsar-Function-Mesh
またPulsar FunctionsをIoTにおいて使った例がUsing Apache Pulsar to Provide Real-Time IoT Analytics on the Edgeで紹介されています。こちらもぜひご覧ください。
Pulsar SQL
Pulsarには
- 保存されているメッセージをSQLで検索する機能(Pulsar SQL)
- メッセージをBookKeeperから別の(低コストの)ストレージにオフロードする機能(Tiered Storage)
があり、これらを組み合わせることでPulsarをデータストアとして活用できます。Interactive querying of streams using Apache PulsarではそんなPulsar SQLの仕組みや利点について説明されていました。こちらもPulsar Functionsと併せてストリーム処理を支える重要な機能として発展していくことが期待されます。
ヤフーの発表
ヤフーとしても1つ発表を行ったので紹介します。
Large scale log pipeline using Apache Pulsar:
この発表ではヤフーにおいてどのようにPulsarを使っているかと、最近大規模なログ・メトリクス転送プラットフォームとして使い始めたことについて説明しています。ちなみに以前にも同様の内容を日本ユーザー会のイベントにて発表していますので、こちらも併せて見るとよりわかりやすいと思います:
ヤフーにおけるPulsar - マルチテナントなメッセージングシステム
ヤフーではPulsarをマルチテナントなプラットフォームとして使っています。すなわち、ヤフオク!・Yahoo!ショッピング・Yahoo!メールなどさまざまなサービスが1つのPulsarを共有して使っています。
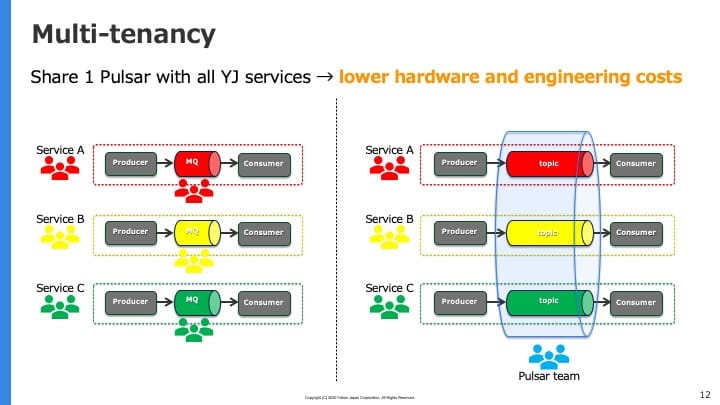
Pulsarを導入する前は上図の左側のように、各サービスがそれぞれ独自のメッセージキューを運用している状態でした。Pulsarを導入することで上図の右側のようになり、サービスはメッセージキューの運用を専門のPulsarチームに任せ、それぞれのサービスの改善やユーザー価値の創造に集中できるようになりました。またヤフー全体で見た時のサーバーなどハードウェアの台数を減らすことができ、コスト削減にもつながっています。
このように、Pulsarの持つマルチテナンシーは100以上のサービスを持つヤフーにおいて極めて重要な性質となっています。
昨今のユースケース - ログ・メトリクス転送のパイプライン
ヤフーではこれまで多くのサービスにおいてPulsarを活用してきました。利用用途はさまざまですが、典型的な利用例は
- 通知
- ジョブのキューイング
などでした。
これに加え、最近ではPulsarを大量のログ・メトリクスを転送するための基盤として使うプロジェクトが進められています。
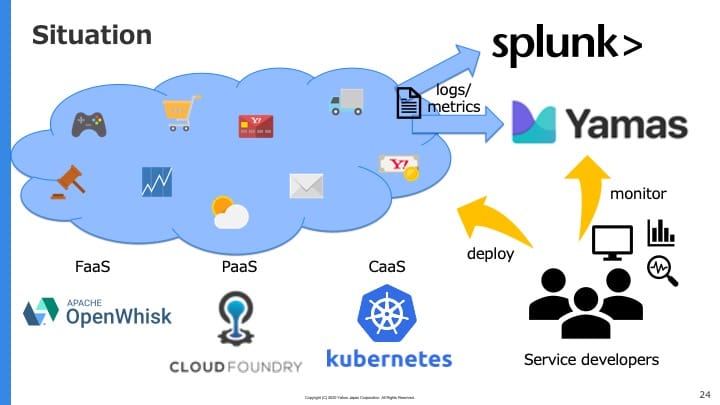
ヤフーではPaaS(Platform as a Service)やCaaS(Container as a Service)を自社運用しています。各サービスのアプリケーションはこれらの上にデプロイされ、稼働しています。
またアプリケーションのログやメトリクスはSplunkやYamas(Verizon Mediaで開発されているモニタリングプラットフォーム。近々OSSとして公開される予定)に送信され、閲覧・検索・可視化・監視などを行うことができます。
ヤフーの大半のサービスがこの仕組の上で動いており、流れるログ・メトリクスの総量はかなりの規模になっています。例えば
- PaaSでは15,000のアプリケーションが75,000のコンテナ上で動いている
- Splunkに流れるログの量は1.4~3.8TB/h
といった具合です。またこれらは現時点での値であり、今後さらに量が増えていくことが想定されています。
このログ・メトリクス送信を行う(旧)アーキテクチャを模式的に表したのが次の図です: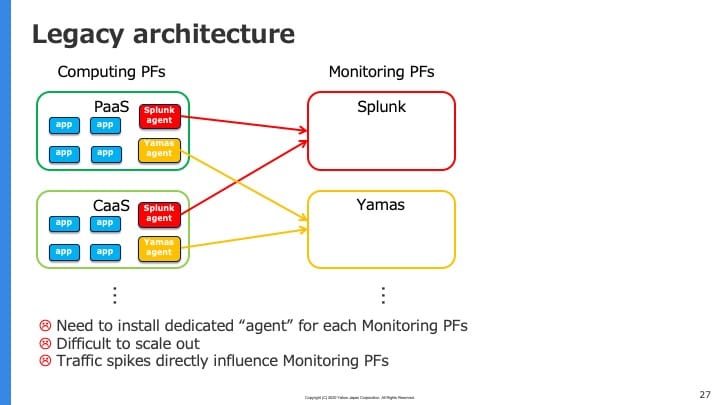
PaaSやCaaSなどコンピューティングプラットフォーム側に送信先ごと個別の”agent”ライブラリをインストールし、送信を行う形になっています。しかしこれは密結合な構成になっており
- 送信先ごと個別のagentのインストールが必要
- スケールアウトしにくい
- 送信側がスパイクすると送信先にも直接影響が出てしまう
などの問題がありました。
これらを解決するため、中継点としてPulsarを使うようにした(新)アーキテクチャが次の図です: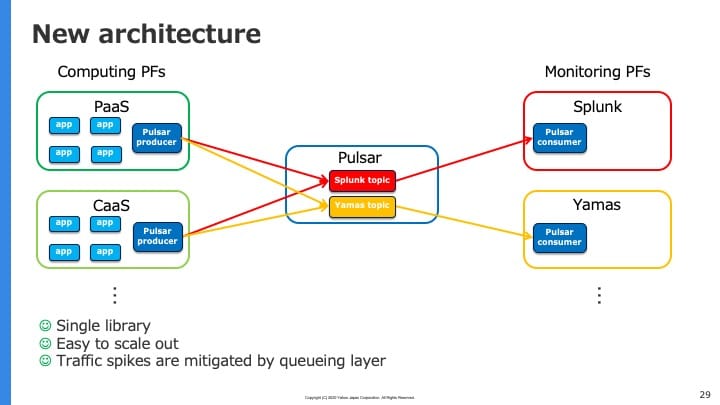
この変更により疎結合な構成になり
- インストールするのはPulsarのライブラリだけで済む
- スケールアウトしやすい
- 送信側がスパイクしてもPulsarにおいてキューイングされ送信先への影響は緩和される
という恩恵を得ることができました。
今後の展望
上述の通り、Pulsarを使うことで大規模なログ・メトリクス転送を疎結合な構成で実現することができました。今後の展望としては連携するプラットフォームを増やしたり、メッセージの配信率をUIで可視化することなどを考えています。
またトピックの構成変更も検討中です: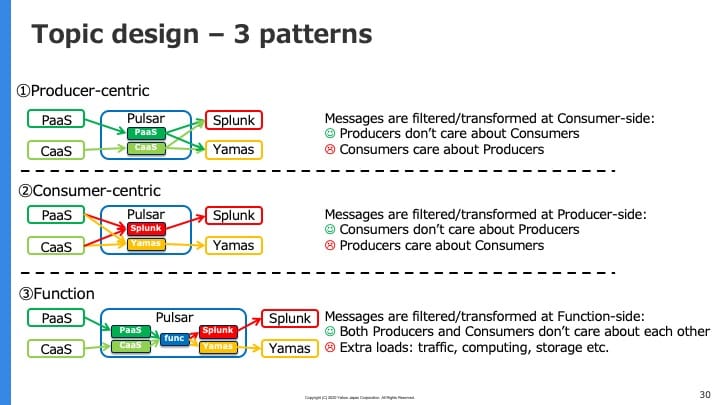
現時点では”Consumer-centric”, すなわちSplunk, YamasなどのConsumer単位でトピックを作成しており、ProducerであるPaaSやCaaSがそれらConsumerトピックに対して送信する形を取っています。この構成だとConsumer側は自分のトピックのみを意識すれば良い一方、Producer側はトピックの増減を把握する必要があり、今後連携するプラットフォームが増えたときにスケールしづらいという課題があります。そこで上図における”Function”パターン, すなわちProducerは各々のトピックにメッセージを送信し、それらをPulsar Functionsを使って加工・変換し、最終的にConsumer側のトピックに渡すような構成への変更を考えています。これにより、Producer/Consumerの変更に強いアーキテクチャになることが期待されます。
おわりに
今回の記事では初のPulsar単体のカンファレンスであるPulsar Summitを取り上げ、いくつかのセッションの紹介とヤフーの発表について書かせていただきました。記事で紹介した以外にもたくさんの興味深い発表がありますので、ぜひスライドやビデオを見ていただければと思います。私はPulsarがOSS化した時から関わっているのですが、今や多くの企業で使われ始め、単一のカンファレンスが開かれるまでコミュニティーが大きくなったことは非常に感慨深いものがあります。ヤフーとしては今後も一利用者としてPulsarを使いつつ、バグ修正・機能改善を行いコミュニティーに貢献していきたいと考えています。さらなる盛り上がりを見せるApache Pulsarからますます目が離せないですね!
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました
- 栗原 望
- バックエンドエンジニア



