
ヤフーで音声に関する技術の研究開発に携わっている藤田です。ヤフーの音声認識技術の研究開発の取り組みをいくつかご紹介します。
2017年秋頃、日本語に対応したスマートスピーカーが発売され、音声を使ったユーザーインターフェース(Voice User Interface, VUI)が改めて注目されています。VUIではさまざまな技術が用いられていますが、一番最初の入り口、つまり音声をテキストに変換するのが音声認識技術です。この変換の精度が低かったり、遅かったりすると、おかしな返答が返る、返答が遅くなるなど、ユーザー体験を大きく損ねてしまいます。従って、音声認識は非常に重要な技術なのです。
ヤフーでは、独自の音声認識エンジン「YJVOICE」の開発を2011年から開始し、すでにいろんなアプリに組み込まれています。例えば以下の図はYahoo! JAPANアプリの検索窓の部分ですが、マイクアイコンがありますよね。これをタップすると、ヤフー独自の音声認識エンジンを使ってキーボードの代わりに音声で検索テキストを入力できます。ぜひ試してみてください。
また、Yahoo!カーナビでは「ねぇヤフー」と話しかけると声で操作できます。こちらもぜひお試しください。
音声認識技術の仕組み
まず簡単に、音声認識技術の仕組みをご説明します。以下の図が、音声認識処理の流れの概要です。図にそって説明していきます。
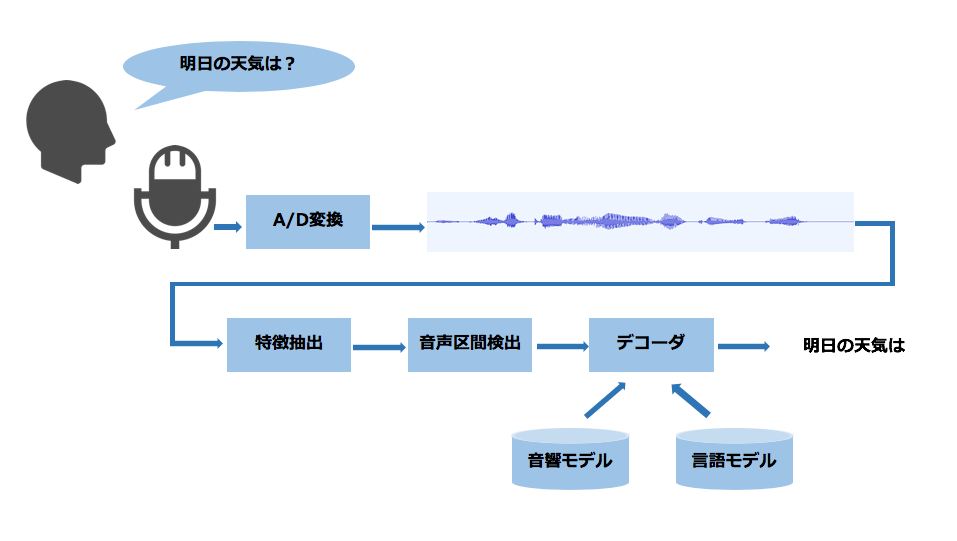
- マイクで収録された音声はA/D変換という処理でデジタル信号に変換され、1次元の時系列信号となります。
- 特徴抽出という処理をおこない、「あ」や「か」といった音の違いを捉えやすい特徴系列に変換します。
- 音声区間検出という処理により、実際に人の声が含まれている区間だけを切り出し、デコーダに入力します。
- デコーダでは、音響・言語モデルという2つの機械学習モデルを参照して、入力音声に対応するテキストを探索します。
- 音声認識結果のテキストが得られます。
音響モデルは、「あ」や「か」といった音の違いをモデル化したものです。近年はDeep Learningのモデルを使うことがほとんどです。このモデルの学習には数千時間規模の音声とその書き起こしのペアデータを用います。言語モデルは、文章の自然らしさを測るモデルです。こちらは大量のテキストデータから学習します。
また、音声認識エンジンを開発して運用してくためには、上記で説明した以外にさまざまな技術が必要です。われわれのチームではサーバー・クライアント型の音声認識エンジンを開発・運用していますので、スマホなどで取り込んだ音声を圧縮し、サーバーへ送信するSDKの開発も必要です。そして、大量のアクセスをさばけるようなサーバーの実装も必要です。他にも、最近年号が変わりましたが、新しい言葉が出てきたときはモデルの再学習が必要ですので、定期的なモデルの再学習とリリースも欠かせません。
このように音声認識エンジンの開発・運用にはいろいろな技術が必要で、全てをご紹介することは困難です。そこで今回は、音響モデルにDeep Learningを導入したときの取り組みと、スマートスピーカーのような遠距離から発話される遠隔発話音声の認識精度向上にチャレンジした時の取り組みをご紹介します。
なお、今回は触れませんが、トリガーワード検出と呼ばれる技術も開発しています。詳しくはこちらのブログをご覧ください。
音響モデルにDeep Learningを導入
詳しい解説をこちらの論文に書いたことがあるので、そこから抜粋してご紹介したいと思います。
2012年頃、音響モデルにDeep Learningを用いると音声認識の精度が大きく改善することがわかり、われわれも導入検討を始めました。そこで課題となったのが、モデル学習と推論の高速化でした。モデルの学習には数千時間の音声データを用いるので、当時最新のGPUを用いても学習に2週間ほどかかり、モデル構造の探索といったパラメータ調整に非常に時間がかかりました。そのため、複数GPUを用いた学習の高速化などに取り組みました。
モデルの学習は、待ち時間が長くても学習されたモデルの精度が十分ならば良いので、そこまで大きな問題はなかったのですが、推論の方はそういうわけにはいきません。認識したい音声の長さより早く処理しなければ、音声認識結果を得るまでの待ち時間が長くなり、ユーザー体験を損ねてしまいます。では、どれくらいの演算が発生するかというと、例えば入力特徴量が440次元、中間層5層、ユニット数1024、出力層が4000次元のニューラルネットワークだと、約10万回の浮動小数点の乗算が1秒間に100回発生します。
GPUや複数のCPUコアを用いれば大した計算量ではないのですが、われわれの音声認識エンジンでは大量のアクセスを処理するため、なるべく少ないCPUコア数で処理を行いたいという制約がありました。そこで、SIMD命令の利用やBLASライブラリの活用、コンパイラごとの性能比較などいろいろな試行錯誤を経て、特別にハイスペックなサーバーを購入せずにDeep Learningのモデルを動かすことができました。
ちなみに、上記の論文には書いていないのですが、BLASライブラリを用いた時、数値再現性が得られず困り果てたことがありました。SIMDやマルチコアを使った乗算では数値再現性を犠牲にして高速化を実現しているものがあり、テスト時は数値再現性を有効にするオプションをつけてコンパイルする必要があるのですが、当時はそういった知識やノウハウがなかったため、ハマってしまいました。ものづくりをする時には論文やソースコードを読んでいるだけでは分からないことがあると学びました。
遠隔発話音声の認識精度向上
スマホで音声検索を使うときは、口元にスマホを近づける人がほとんどだと思います。一方、スマートスピーカーでは、スピーカーまで近づいて話す人はほとんどいないと思います。口元とマイクまでの距離が長くなると、周囲の雑音や残響の影響をうけてしまい、音声認識の精度が大きく劣化します。このような状況での音声認識のことを遠隔発話音声認識と呼びます。
精度の改善には実際にマイクとの距離が離れた状況で収録された音声データが必要なので、以前こちらのブログでもご紹介した通り、スマートスピーカーを試作して音声データを集めました。また、データだけではなく、複数のマイクを使って特定の方向の音声を抑圧/強調するビームフォーミングと呼ばれる技術の開発にも取り組みました。
ビームフォーミングは、理論的にはそれほど実装は難しくなく、MATLABやPythonならば数十行で書けます。しかし、実際にプロダクトとして使うためにはいろいろな課題がありました。データから計算された行列の逆行列を計算する処理があるのですが、非可逆な行列になってしまった場合の例外処理や、抑圧したい雑音信号を何らかの方法で取得しなければいけない、強調したい音声の方向を取得する必要があるなど、教科書ではさらっと書かれているところをどうやって実現するか、試行錯誤が必要でした。
また、いろいろなデータを評価していると、1つ大きな課題が見つかりました。テレビの音声や他の人の話し声と被った状態で収音された音声の認識精度がなかなか改善しなかったのです。音声認識エンジンにとってはいずれも人の声なので両方の声を認識しようとして失敗してしまうようでした。そこで、音声認識したい声とそれ以外を分けてから音声認識エンジンに入力したいのですが、複数の音声を分離し、欲しい音声だけを抽出するのは容易ではありません。欲しい音声の特徴を事前に知る必要があるからです。
そこで、スマートスピーカーのような機器であれば、トリガーワード(例えば「ねぇヤフー」)を最初に発話することがほとんどなので、このトリガーワードを有効利用できないかと着目しました。任意の音声を分離する問題を少し易しくして、特定のキーワードの音声とそれ以外を分離する問題を最初に解かせ、分離されたキーワード音声から特徴を抽出し、その後の欲しい音声だけを抽出する、という方式を考案しました。この方式は難関国際会議に論文が採択されました。
まとめ
ヤフーでの音声認識技術の研究開発において、技術をプロダクト化するためには、論文やソースコードには書かれていないいろいろな試行錯誤やテクニックが必要だったこと、また、試行錯誤の過程で見つかった課題を解決した取り組みをご紹介いたしました。
音声認識に限らず、音声・音響信号からの情報抽出は、ユーザーのコンテキストを理解し、さらに便利なサービスを提供するために必須の技術と考えています。今後も研究開発を進めて参ります。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました



