
こんにちは。サイエンス統括本部で音声認識の技術開発を担当している木田です。
この年末年始、帰省や旅行でお出かけの際にカーナビを利用される方が多いのではないでしょうか?
ヤフーではYahoo!カーナビというサービスを提供していますが、2018年12月に音声によるハンズフリー操作機能が導入されました(2019年12月現在はAndroid版のみ対応)。
今回はその技術の裏側をご紹介します!
 写真:アフロ
写真:アフロ
使い方とシステム構成
それでは、この機能の使い方を説明します。
まずはYahoo!カーナビを起動し、こちらのページに記載している設定を行うことで、ハンズフリー操作が有効になります。
設定ができたら、「ねぇヤフー」と呼びかけてみてください。
ピコッという音と共に音声入力画面が表示されますので、続いて「東京スカイツリーに行きたい」のようにカーナビの操作内容を発話すればOKです。
スマートスピーカーや音声アシスタントでもおなじみの操作方法ですね。
ちなみに、このハンズフリー操作機能はYahoo!音声アシストにも導入されています。
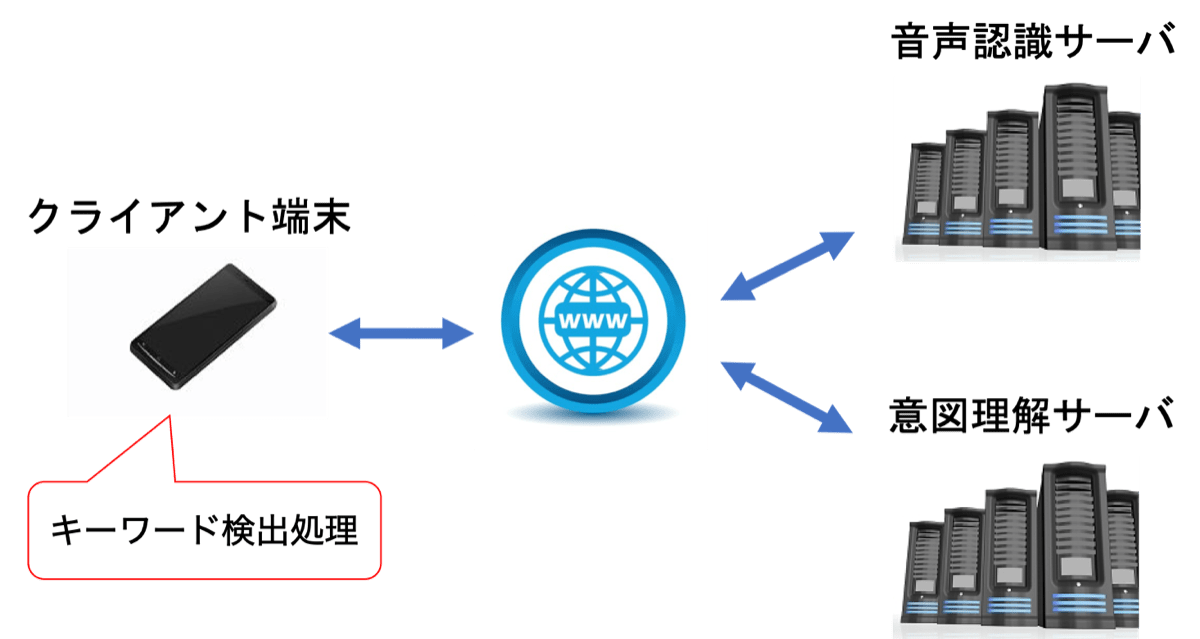
次に、この機能を実現するシステムの構成を以下に示します。
 画像:アフロ
画像:アフロ
はじめに、音声認識を起動させるトリガとなるキーワードを検出します。
Yahoo!カーナビのキーワードは「ねぇヤフー」です。
キーワードを検出する処理はスマホ内部で常時実行しています。
キーワードを検出すると、後続の命令部分の音声を音声認識サーバーに送信し、認識結果を受け取ります。
私たちのチームはYJVOICEという音声認識エンジンを開発しており、ヤフーのさまざまなアプリに活用されています。
YJVOICEの技術的な詳細はこちらの論文に詳しく記載してありますので、興味のある方はご参照ください。
次に、今度は認識結果の文字列を意図理解サーバーに送信し、ユーザーの意図するカーナビの操作コマンドに変換することで、カーナビの操作を行うことができます。
キーワード検出アルゴリズム
それでは、この機能を実現する上での鍵となるキーワード検出のアルゴリズムを説明します。
キーワード検出はかなり古くから研究されている技術ですが、現在はディープラーニングを使ったものが主流となっています。
私たちは現在、その中でも時系列データのモデル化に特化したLSTM(Long Short-Term Memory)を使っています。
アルゴリズムの概要を以下の図に示します。
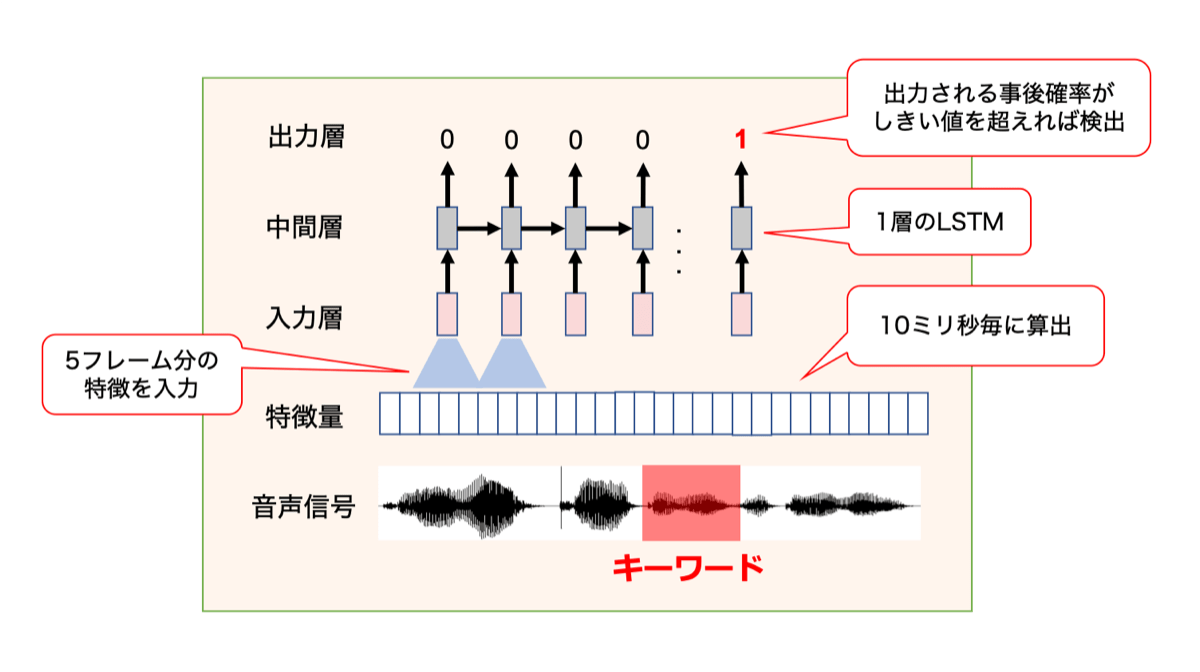
まず、音声信号をフレームと呼ばれる短い時間に区切り、各フレームを特徴量に変換します。
ここでは、音声の特徴量として最も一般的な対数メルフィルタバンクを使っています。
次に、5フレーム分の特徴量を連結してLSTMに入力します。
LSTMからは、キーワードが存在する事後確率が出力されるので、事後確率に適切なしきい値を設定することでキーワードを検出できます。
LSTMの学習時には、キーワードの終端部分にのみ1、それ以外に0を付与し、クロスエントロピー誤差が最小となる基準で学習を行います。
これによって、キーワード全体の特徴を読み込んだ上でキーワードかどうかを判断するようにLSTMを学習させることができます。
このように、開発したキーワード検出は非常にシンプルなアルゴリズムで動作しています。
もっと複雑なアーキテクチャを構築すれば精度は向上できるのですが、キーワードの検出処理はスマホで常時動作させるため、計算量の多いモデルだとCPUを使い過ぎてすぐにスマホの電池を消耗してしまいます。
そこで、小さなモデルを使うことに加え、計算するフレームを間引いたり、複数フレーム分の行列演算をまとめて実行したりするなどの計算上の工夫を行うことで、消費電力の増加を抑えています。
リリース、そして問題発生
以上がキーワード検出の概要ですが、システムを実際にリリースするまでにはそれなりに苦労がありました。
というのも、モデルの精度を高めるためには、大量の音声データを使ってパラメータを学習する必要があります。
今回のキーワード検出は、主に走行中の車内で使われると考えられますので、走行中の車内で「ねぇヤフー」と発話した音声でモデルを学習するのが理想的です。
しかし、まだサービスをリリースしていない段階では、当然ながら実際の音声データは全くない状態です。
そこで、室内でスマホを持ちながら「ねぇヤフー」と発話した音声を収集し、別途収録した走行中の車内の雑音を発話に重畳することで、車内環境を模擬したキーワード発声を作成しました。
この音声データを使って学習したモデルを使って2018年12月にファーストリリースを行いましたが、いざリリースしてみると、またもや問題が発生しました。
「ねぇヤフー」と発話していない時にも頻繁にキーワードを誤って検出する、という報告があったのです。
ログを分析してみると、ウィンカーやカーステレオの音声など、車内で発生する多種多様な音に反応して誤検出を起こしているようでした。
誤検出が頻繁に発生すると、スマホから鳴る音が運転中のユーザーにストレスを与えてしまいますし、その後の音声認識結果によっては意図しないカーナビの操作が行われる可能性もあります。
アプリのレビューにも改善の要望があり、この時はかなり焦りました...
教師ありモデル適応による改善
一口に車内の雑音と言っても、車種によって遮音性能は大きく異なりますし、路面の状況やスピード、窓の開閉によって車内の雑音は大きく変動します。
また、カーステレオから流れるラジオや音楽、同乗者との会話もキーワード検出にとっては反応すべきでない雑音です。
私たちがモデル学習に利用していた雑音は、このように多様なユーザーの発話環境を十分にカバーできておらず、モデルにとって多くの雑音が未知であったことが誤反応を起こした要因だと考えられました。
そこで、アプリをリリースしたことで得た音声データのログを使った教師ありモデル適応を行うことで、問題の解決を図りました。
教師ありモデル適応とは、あらかじめ学習したモデルのパラメータを初期値として、正しいラベル(キーワード発話かそうでないか)の付いた少量のデータでモデルのパラメータを更新する技術です。
幸い、音声の利用にご協力いただいた方から集まったデータが既にたくさん集まっていたので、早速適応を実施したところ、実際の車内で収録した評価セットでの誤検出を8割以上削減する効果を確認できました。
私はメーカー出身なのですが、実データを使うことの意義を改めて痛感したと同時に、リリースとフィードバックのサイクルを素早く回せるヤフーの開発体制の力強さを感じた瞬間でした。
新しいモデルは既にYahoo!カーナビにリリース済みですので、ぜひ一度試していただけるとうれしいです。
おわりに
私たちのチームはアルゴリズムのさらなる改善に取り組んでいて、9月に開催された音声分野のトップカンファレンスINTERSPEECHではキーワード検出の新方式を発表しました。
今後もハンズフリー操作を使ってたくさんの課題を解決したいと考えていますので、ヤフーのキーワード「ねぇヤフー」をこの機会にぜひ使ってみてください!
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました



