
こんにちは、システム統括本部でPrivate PaaSを担当している増田彬(@Go_zen_chu)と水落啓太(@keitam913)です。 僕たちはPaaSチームとして3年半ほど、ヤフー社内で利用されるPrivate PaaSの運用と関連システムの開発に携わってきました。
その中でどのようにPaaSを通じて利用者へ利便性を提供し、安定して稼働する体制作りをしてきたのかをお話しします。
PaaSとは?
PaaS(Platform as a Service)という単語はさまざまな用途で利用されますが、その中で僕たちが提供しているのは、「社内のエンジニアが簡単にアプリケーションを動作することができるプラットフォーム」です。
この「簡単に」というのがポイントで、具体的にはHeroku®やGoogle App Engine™のような「1コマンドでアプリケーションを稼働できる」環境を提供しています。
ヤフー社内では数千人のエンジニアが新しいウェブサービスをユーザーの皆様へ提供するために、アプリケーション開発を日々行っています。 仮想サーバー上でアプリケーションを動作させる場合、下記のような手順を踏む必要がありました。
- 仮想サーバーのイメージを用意して、新しいインスタンスを作成する
- 作成した仮想サーバーに実行したいアプリケーションに必要なライブラリやランタイム(Java Runtime, Tomcatなど)をインストールする
- アプリケーションの実行
手順として多くないように見えるかもしれませんが、数多くのサービスを開発するエンジニアにとって環境のセットアップが簡単なほど、サービスの新機能開発などに時間を費やすことができます。
PaaSの場合は、
$ cf pushで上記の手順と同様の作業が実施できます。さらに、このアプリケーションが稼働するマシンの運用はPaaSチームが実施するため、社内のエンジニアはアプリケーションの開発により集中できます。
PaaSの実体としては、コンテナ実行プラットフォームのOSSであるCloud FoundryをベースとしたPivotal Application Service®(以下、PAS®)と呼ばれる製品を利用しています。 製品を利用しているとはいえ、インストールから運用まですべてをヤフー社内の環境にあわせて行い、さらに利便性を上げるための関連システム開発をPaaSチームでは実施しています。
ヤフーのPrivate PaaSは社内で広く利用されているプライベートクラウド*(OpenStack など)上で構築されています(PAS® on OpenStack)。 プライベートクラウドを利用することで、パブリッククラウドと比べてコスト面で大きなメリットがあるほか、PaaSを動作させる上でのカスタマイズ(CPUのオーバーコミットの設定やオブジェクトストレージのチューニング)が柔軟に行えるなどのメリットがあります。
*Yahoo! JAPANのサービスを支える巨大インフラはどう運用されているのか? - クラウド Watch にヤフーのプライベートクラウドの試みが記載されています。
利用者ファーストなプラットフォーム作り
現在、PaaSの上では約40,000コンテナが本番環境で稼働しています(PAS® としてはアジア最大級の規模での運用)。しかし、ここまでの道のりは平坦なものではなく、さまざまなチャレンジがありました。 この節では、PaaSが社内の利用者を獲得するためにどのようなシステムを開発したのかを説明します。
できるだけ早く利用できる環境を増やす
PaaSを本番環境で提供しはじめてから問題となったのは、デプロイしたいアプリケーションの数に対してプラットフォームのキャパシティが追いつかないことでした。
キャパシティを増加させるために、PaaSクラスタを増設する必要があるのですが、それには大きく分けて2つの課題がありました。
- PAS®のインストールや、社内でPaaSを利用できるようにするための権限の設定、基本的な監視の導入など社内での提供に向けたさまざまな関連設定に工数がかかる
- 社内へのリリース時に「本当にこの設定で問題ないか」をチェックしてシステムの品質を保つ必要がある
これらの課題のため、PaaSクラスタを提供するのに時間がかかってしまい、クラスタの構築を開始してから利用者へ提供するまでに数カ月かかる状態となっていました。 そこで、これらの課題を解決するため、
- クラスタ構築を自動化するツール(図1)
- 構築したクラスタの設定に問題はないかどうかの品質をチェックするツール(図2)
をGo言語で開発しました。Go 言語で開発した理由として、
- Cloud Foundry がGo言語で開発されており、関連ライブラリもGoで開発されている
- チームの誰でもなじみやすく、パフォーマンスの必要なコンポーネントの開発もしやすい
- チームメンバーの開発環境であるMacでLinux用にビルドして、実行する環境へデプロイできる
があります。PaaSチームはさまざまな関連システムを社内の利用者へ提供している(後述)のですが、結果的にほとんどすべてのシステムをGoで開発することができ、チームの学習コストを低減することができました。
開発したこれらのツールをCI/CDなどの自動化ツールであるConcourse CI 上から実行できるようにし、誰でもすぐにクラスタの構築や設定チェックが行えるようになりました。
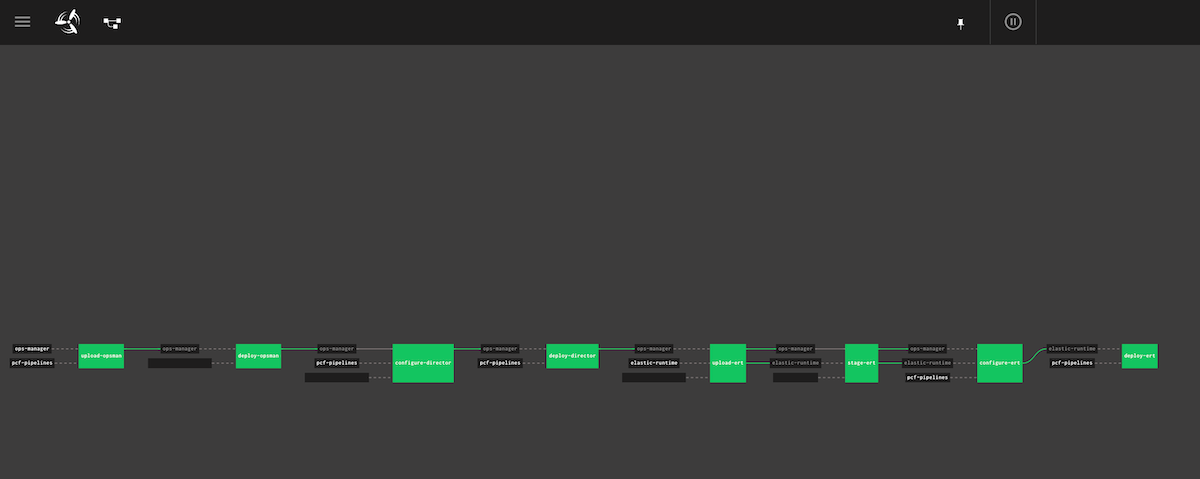
図1.PaaSクラスタの構築をUIから行えるツール。内部ではコンテナが各ステップごとに起動し、クラスタの構築に必要な手順が実行される。具体的には、upload-opsman, deploy-opsman ではOpsManagerと呼ばれる管理系コンポーネントのデプロイを行い、その後、deploy-directorなどでPAS®のデプロイを実施する
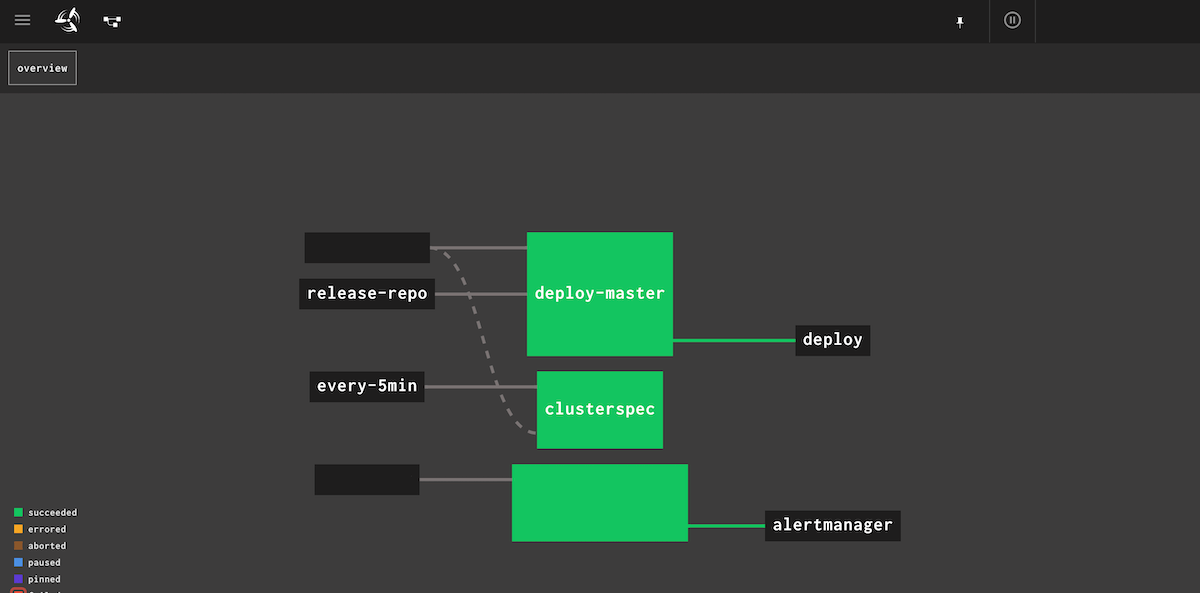
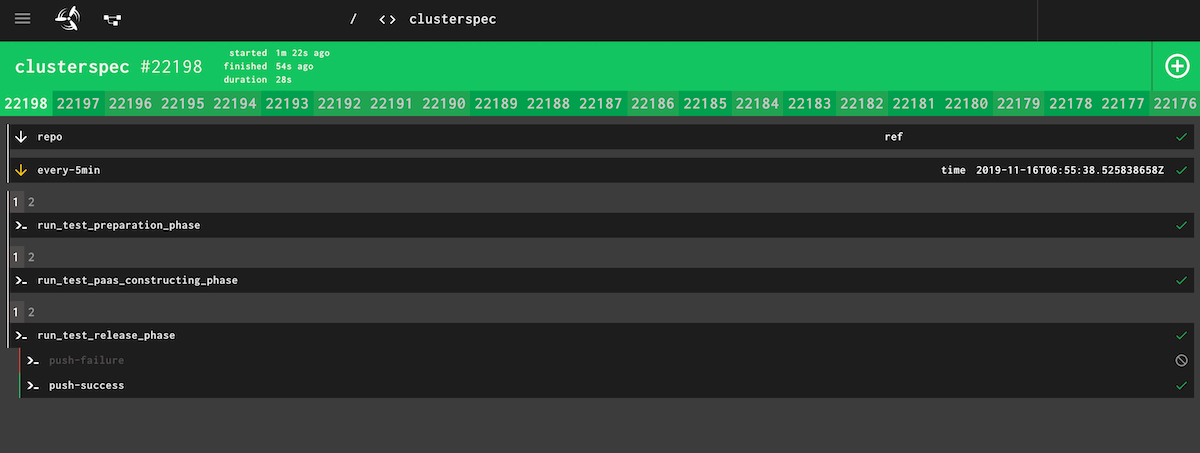
図2.PaaSクラスタが正しく構築できているかを定期的にチェックするツール。内部ではGinkgoというGo言語製テストツールを使い、証明書の設定や各コンポーネント間の疎通に問題がないかどうかを調べる
これらのツールの開発により、1クラスタを社内の利用者に提供するまでの時間を3分の1に減らすことができるようになりました。
利用者に運用の手間をかけさせない
先にも述べたとおり、Private PaaSはいかに簡単にアプリケーション開発と運用が行えるかを重視しています。 クラスタ構築の自動化により、多くのPaaSクラスタを社内のエンジニアに提供できるようになった一方で、「たくさんクラスタがあり、アプリケーションを冗長化するまでの設定が大変」という声をもらうようになりました。
そこで、PaaSチームはPaaSが簡単に使い始められるようにするためのシステム開発を行いました。 ここでは、その中の2つの事例について説明します。
1.Web UI でCI/CDなどの設定を簡単に
まず、利用者がPaaSを使い始める際、OrgやSpaceというグループを作成するのですが、新しいクラスタが提供されるごとに作成申請を行っていては手間になってしまいます。 そのため、複数のクラスタにまたがってグループを作成・管理できるようなWeb UIの開発を行いました。 PaaS利用者はこのUIからPaaSの新しいクラスタについてもすぐに利用開始できます。
また、ヤフー社内のCI/CDプラットフォームとして Screwdriver.cd を多くのPaaS利用者が利用しているのですが、デプロイできる環境が増えるとCI/CDの設定も煩雑になります。 上記のUIではScrewdriver.cdとの連携機能が提供されており、簡単な操作でCI/CDに必要な権限の設定が実施できます(図3)。 これによって、新しいクラスタでのアプリケーションのデプロイが簡単に実施でき、冗長化の対応が簡単に行なうことができます。
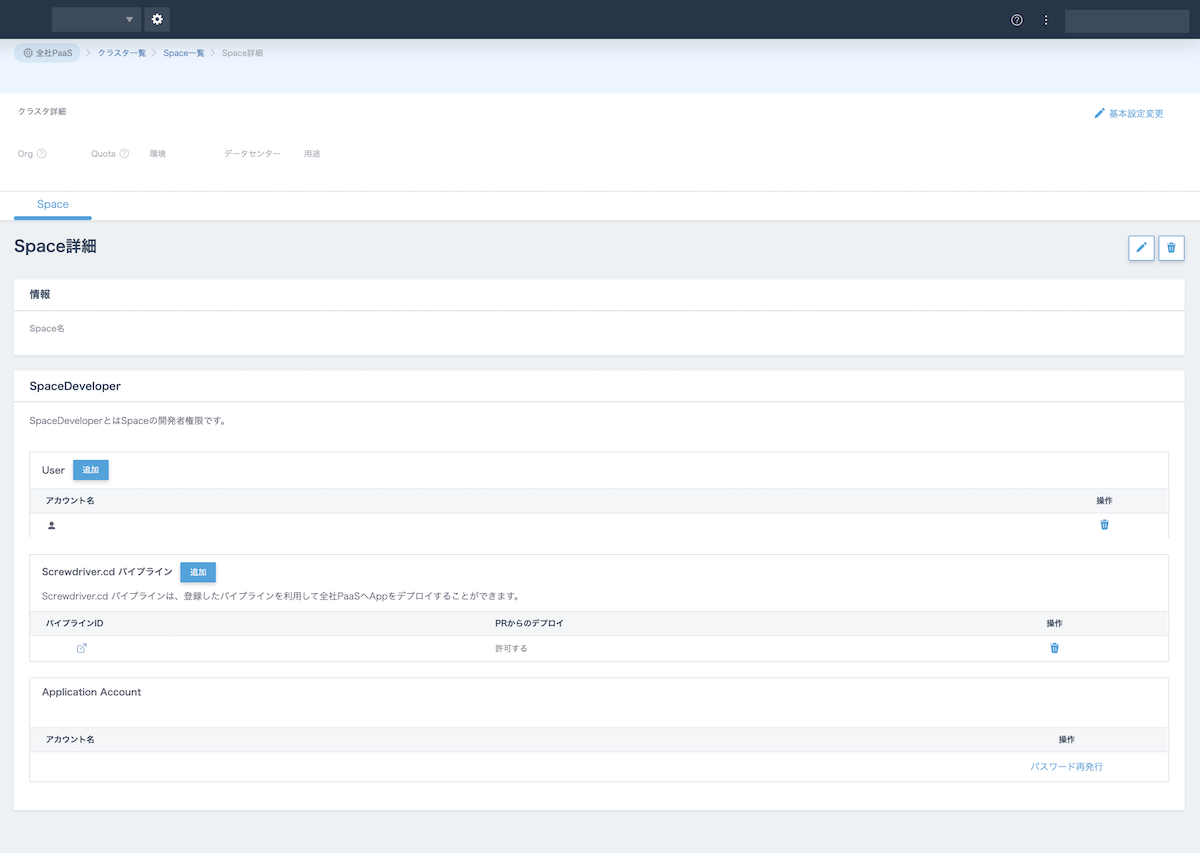
図3.社内で提供されている設定ツール。AWS Management Console のように、さまざまなプラットフォームの設定を実施でき、PaaSも対応している
2.GSLB ServiceBroker
次に、マルチクラスタでの対応で必要になったのは、アプリケーションへのロードバランシングでした。
本番環境で稼働するアプリケーションではBCP(Business Continuity Plan; 事業継続計画)の観点から1クラスタのみで動かすことは通常ありません。 複数のクラスタで冗長化し、もしどこかのクラスタが障害などで利用できなくなった場合でも自動的に稼働している別のクラスタでリクエストを受けられるようにする必要があります。
httpリクエストのロードバランスの代表的な手法としてGSLBがあり、ヤフー社内でも広く利用されていますが、十数ものPaaSクラスタが存在するとその設定はPaaS利用者の負担になってしまいます。 そこで、GSLBへのサービスインやアウト、ヘルスチェックの設定を自動的に行う ServiceBroker を開発しました(図4)。
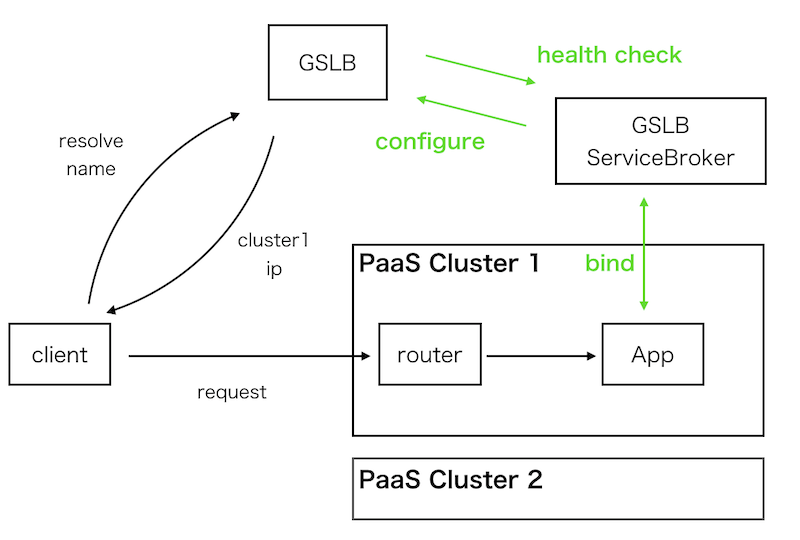
図4.GSLB ServiceBrokerの概要図。緑の線をServiceBrokerが受け持っている
ServiceBrokerとはアプリケーションと連携して拡張機能を提供する API 仕様です。 PaaSチームが開発したGSLB ServiceBrokerの例ですと下記のようなコマンドでGSLBへのサービスインやサービスアウトを行うことができます。
cf bind-route-service prod.app.domain gslb-service --hostname prod-app
cf unbind-route-service prod.app.domain gslb-service --hostname prod-appシンプルなコマンドで実現されていますが、このコマンドを受け取ったServiceBroker内ではヘルスチェックを行ったり、GSLB機器の設定を依頼するなどの処理を行っています。
これらの事例以外にも、PaaSチームではログやメトリクスをログ分析プラットフォームへ送信するためのServiceBrokerや、アプリケーションログを適切なログサイズに抑えるようなライブラリの提供を行い、利用者のアプリケーション開発を支援しています。
NPS®による利用者満足度の測定
システムを提供する立場として、上記のような機能改善が実際にPaaSの利便性向上につながり、社内利用者にとって良いものになっているのか知ることは重要です。 PaaSチームでは利用者の満足度を知るための定量的な指標として NPS®(ネット・プロモーター・スコア)を活用しています。
NPS®では利用者に対して、「あなたがこのプロダクトを薦める可能性は、10点満点で表すとどのくらいですか」というような質問を含むアンケートへの回答を依頼します。 そして、回収したアンケートの結果を集計し、対象のサービスやプロダクトをどれほど他の人に薦めたいと感じているのかを算出します(NPS®アンケートは社内の専門チームによって定期的に実施されています)。
PaaSの場合は、僕たちが開発・運用しているシステムを利用者がどれほど社内のエンジニアに薦めてもらえるのかを示す指標ということになります(図5)。 この指標が高いほど利用者満足度が高く、PaaSが社内利用者の役に立っているといえます。
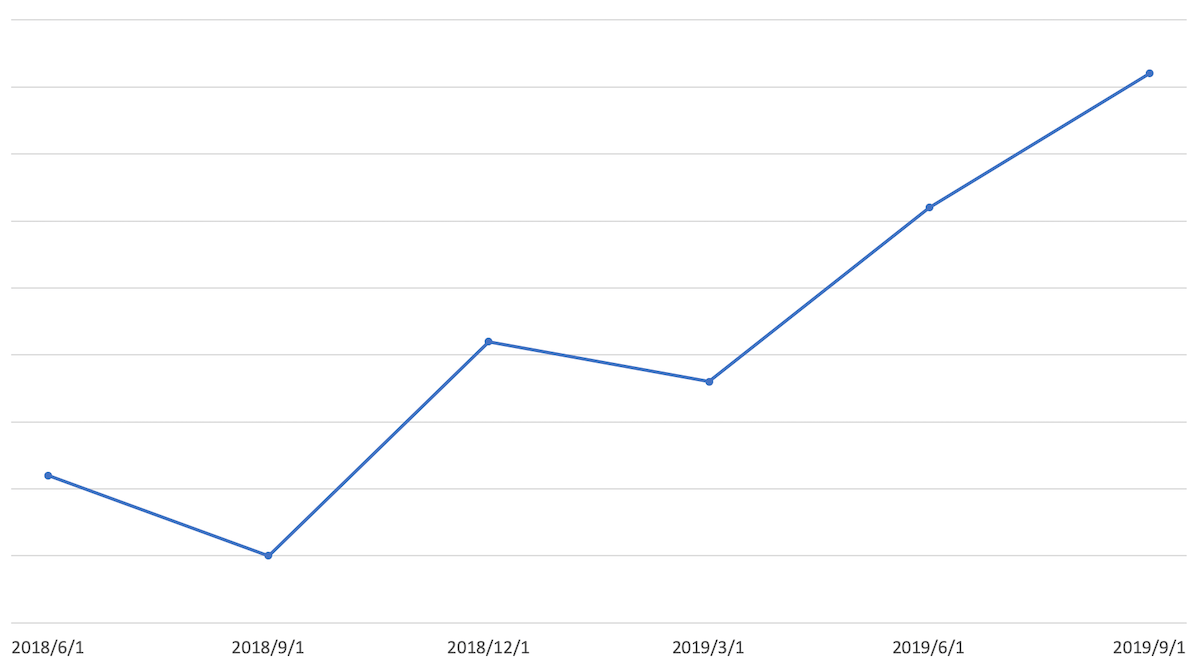 図5.PaaSのNPS®の推移。NPS®をベースとしたプロダクトの改善により、最近では利用者のポジティブな印象が増えている
図5.PaaSのNPS®の推移。NPS®をベースとしたプロダクトの改善により、最近では利用者のポジティブな印象が増えている
ヤフーでは、Private PaaSの他にも Kubernetes as a ServiceプラットフォームやOpenStackなどのアプリケーションプラットフォームが提供されており、どれを利用するかは利用者に委ねられています。 もしPaaSの NPS®の値が極端に悪い場合、PaaS利用者は他のプラットフォームを採用してしまうことが考えられるため、社内のエンジニアから得られたフィードバックはプラットフォーム提供の上でとても大切です。
また、この指標以外にも定性的なフィードバックとして、利用者にはプロダクトに対するコメントの記載もお願いしており、これらの情報を総合してPaaSチームは機能改善を実施しています。
安定稼働という当たり前を実現するために
ここまでの施策で、ありがたいことに数多くのアプリケーションがPrivate PaaS上で稼働するようになりました。 その中には実際に Yahoo! JAPANのサービスを利用する皆様が利用されているサービスのアプリケーションも含まれています。
本番環境で提供されているアプリケーションに何か異常が起こるとページが見ることができなくなったり、レスポンスが不安定になったりするような不具合が発生してしまいます。 しかし、ヤフーで稼働しているアプリケーションは「動いているのが当たり前」であるため、その実現のためにPaaSチームは何を行ったのか説明します。
ブラックボックステストで利用者への影響を把握する
システムの安定化のためにまず第一に考える必要があるのは、いまシステムは利用者に影響がある状態なのかどうか をすぐに判断できるようにすることです。
「利用者に影響がある」というのはどういう状態でしょうか?
例えば、アプリケーションへのリクエストが突然受け付けられなくなったり、クラッシュしてエラーメッセージを返してしまうことが挙げられます。 それ以外にも、PaaSにアプリケーションがデプロイできないことやアプリケーションのスケールアウトなどの操作が実行できないことも利用者への影響があると言えます。
PaaSチームでは数分間隔でこれらの利用者への影響を確認するブラックボックス* テストツールを開発・運用しています(図6)。
*システムの内部の状態に関係なく、利用者から見た機能が正しく提供できているか(外部監視)
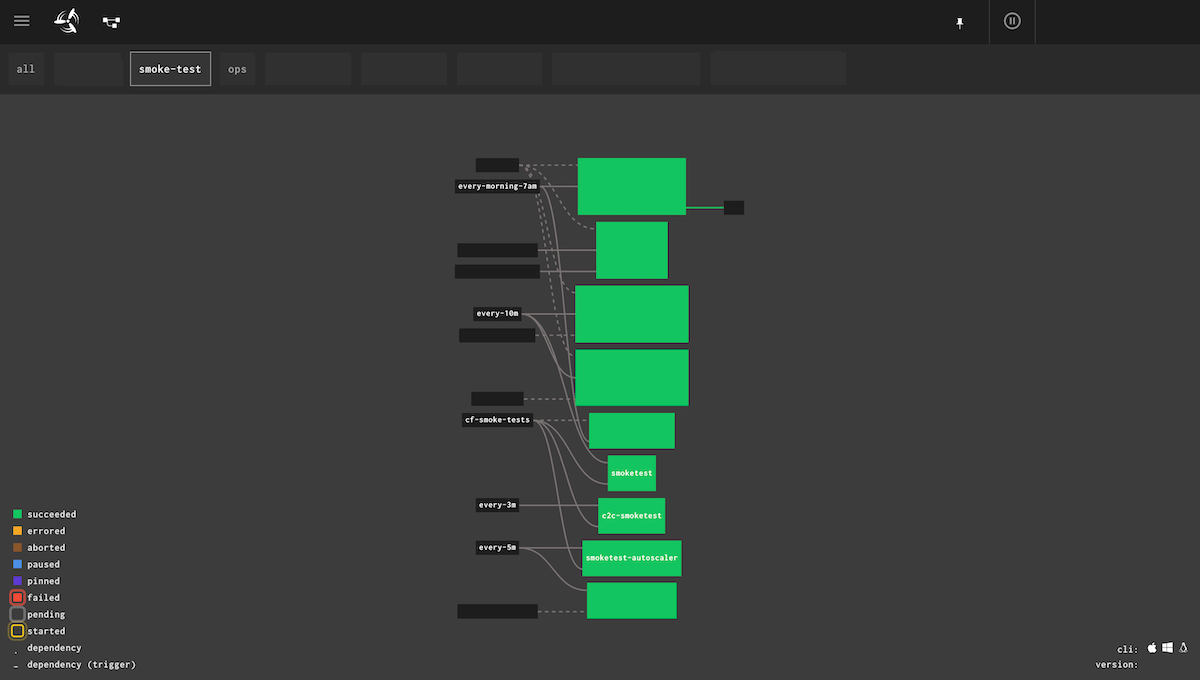
図6.PaaSのブラックボックステスト。アプリケーションのデプロイが行えるのか、削除が行えるのかなどを継続的にテストしている。このテストが失敗するとPaaSチームへアラートが飛ぶ
システムを運用する際、オペレーターは 必要なときのみ行動する のが大切です。 例えば、CPU使用率についてサービスのユーザー影響がない閾値でアラーティングをしてしまうと深夜や休日にアラートが飛んでしまい、オペレーターが疲弊してしまう可能性があります。 すると、いざというときに重要なアラートを見逃してしまう可能性があります。
そのため、アラートはオペレーターが実際に行動を起こす必要があるときのみ発生するようにしなければなりません。 その意味でも、ブラックボックステストを通じて利用者への影響を常に把握し、本当に問題があるときにアラートが発生するようにします。
メトリクスで未然に障害の兆候をつかむ
次に、安定的なシステム運用のためには、未然に障害へ至る兆候をつかむ必要があります。
よくある障害の原因として、ネットワーク帯域、ディスクや inode といったリソースの枯渇が挙げられます。 さらに、こうしたリソース残量のメトリクスに加えて、システム特有のメトリクスを監視して、何か問題になる前にアクションを起こす必要があります。
これらは、ブラックボックステストと対比して、ホワイトボックス* 監視と呼んでいます(図7)。 PaaSチームでは確実に障害につながるメトリクスについてアラートを設定しています。
*システムの内部の状態について表す。メトリクスの異常が必ずしもサービスへの影響につながるとは限らない
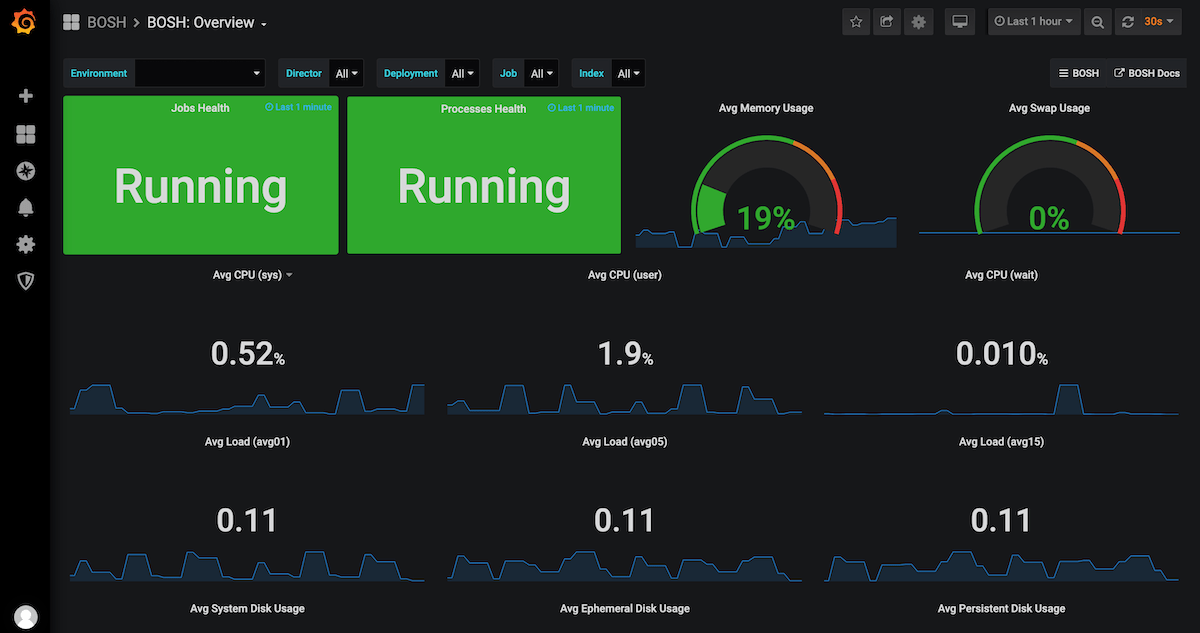
図7.Prometheusで取得しているメトリクスの一部。運用している全てのマシンからメトリクスを取得している
システムの代表的な監視手段として、ログ監視もありますが、PaaSの場合はほぼ全ての監視をメトリクスで実施しています。その理由として下記が挙げられます。
- メトリクスはデータのサイズがログと比べて軽量なため、長時間の保存や高頻度な取得が可能
- ログでは実施が難しい統計的処理(合算やパーセンタイルの算出)がメトリクスでは行えるため、柔軟なアラーティングの条件を定義しやすい
- 時系列に取得しているメトリクスは過去との比較やトレンドがわかりやすく、見た目で異常に気づきやすい
前述のブラックボックステストの実行結果や実行にかかった時間もメトリクスとして取得しており、普段よりも処理に時間がかかっていないかどうか調べられるようにしています。
SLO駆動オペレーション
ブラックボックステストや各コンポーネントからメトリクスを継続的に取得できるようになると、自分たちがどれほどのサービスレベルで運用しているのかがわかります。 サービスレベルの一部はSLA(Service Level Agreement)として社内の利用者に公開されていますが、PaaSチームでは内部目標であるSLO*(Service Level Objective)も決めています。
*SLOやSLAについて:SLO、SLI、SLAについて考える: CREが現場で学んだこと | Google Cloud Blog
なぜチーム内部でSLOを決める必要があるのでしょうか?
SLAとして定めている値を守ることはPaaSチームのメンバー全員が同じ認識でしたが、PaaS以外の関連システムの品質についてどこまで守っていけばよいかチーム内で不透明な状態でした。 そのため、現在開発している案件を進めることと関連システムのサービスレベルを高めることのどちらを優先すべきか、チーム内で頻繁に議論が起こりました。
そこで、チームで合意したSLOを決めて、関連システムについてもどれくらいのサービスレベルを維持すべきかを明確にすることで、「いま何を優先すべきか」がわかりやすくなりました。 また過剰な品質を設定しないことで、チームメンバーが疲弊してしまうのを防ぐことができます。
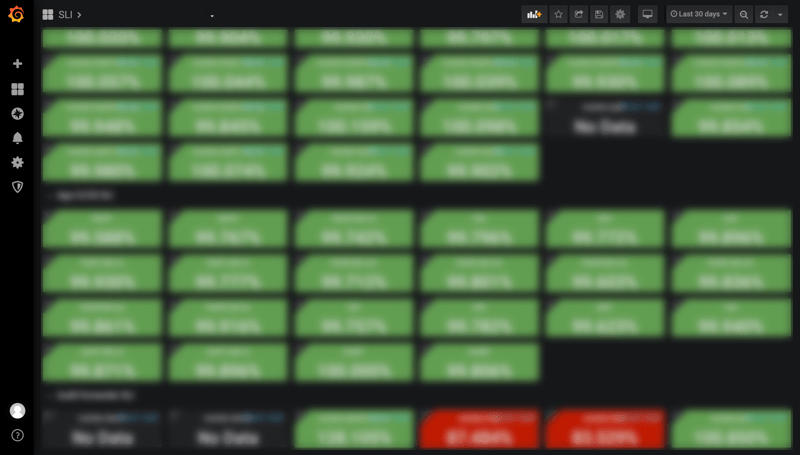
図8.PaaSチームのSLOダッシュボード。正常な場合は緑で、赤になっている場合は何か問題が発生しているため、オペレーターは調査を行う
このダッシュボードをチームの朝会で確認することで、PaaSチームが管理しているPaaSならびに関連システムに問題がないかどうか一目でチェックできます(注:SLO駆動オペレーションの前提として、まずは当たり前の品質であるSLAを守ることが必要です)。
障害対応ロールプレイ ~ もし今、障害が発生したら ~
最後になりますが、システムの安定化が進むと障害対応を行う回数が減るため、オペレーターの練度は下がっていきます。 また実際のシステム運用では全オペレーターが均等に障害対応を行うわけではないため、オペレーターの間でも障害対応の練度が異なってしまいます。
しかし、システムの障害はいつどんな理由で発生するかわかりません。そのため、PaaSチームでは、「もし今、システム障害が起きたらどう動くか」という障害対応ロールプレイを実施しています。
ロールプレイの基本的な考え方は避難訓練と同じで、「今、この環境でこういった報告を利用者から受けたらどうしますか」という問いかけに対して、何名かのグループで対応を行います。 どのような対応を行うかはグループごとに付せんで時系列にまとめ、最後に対応方法を共有して、うまくできたところ、できなかったところを振り返ります。
少人数のグループで行うことで実際に障害対応にあたる際の状況を再現し、また発生しうる障害をロールプレイの題材にすることで事前に障害が発生したときの動き方を確認できます。
障害対応ロールプレイは特に新しいメンバーが加入したときや、システム構成が変わったタイミングで有効です。 新メンバー加入時は、
- どこに見るべきドキュメントがあるのか
- 必要なコマンドは打てる状態にあるのか(権限がついているのか)
- いざというときに、誰に連絡を行えばいいのか
を確認することができ、システム構成が変わった際は、
- 新しい構成の場合、これまでと比べてどう対応を変える必要があるか
- 構成が変わったことに伴い、コマンドレファレンスなどのドキュメントが古くなっていないか
を確認できます。
PaaSチームで実施した際は、「深夜の時間に本番環境で稼働している2つのクラスタへのリクエストが不安定になっているという報告を利用者から受けた」という想定でロールプレイを実施しました。 まずは、新メンバーのみのグループでどのように対応するかのセッションを行い、その後、既存メンバーと一緒にロールプレイを行うことで適切な対応方法について学びが得られるようにしました。
最後に
ここまで説明した取り組み以外にも、PaaSチームはシステムの利便性や安定性の向上のためにさまざまな取り組みを行い、社外へ発信しています。 最近ではアメリカのオースティンで開かれたSpringOne Platform 2019でPrivate PaaSの事例を発表しました。
また、PaaSチームによる安定化の取り組みにつきましても、2020年1月開催のSRE NEXT 2020にて発表する予定です。
これからも、より簡単に使えるアプリケーションプラットフォームとして、Private PaaSは歩みを進めていき、積極的に発信していきたいと思います。
注:ネット・プロモーター、ネット・プロモーター・システム、NPS、そしてNPS関連で使用されている顔文字は、ベイン・アンド・カンパニー、フレッド・ライクヘルド、サトメトリックス・システムズの登録商標です。
注:当ウェブサイト上に掲載されている社名、製品名、サービス名及びサイト名等は、各社の商標または登録商標です。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました



