
こんにちは。ヤフーの橘(@moja_0316)です。
私は2018年に新卒でデータ統括本部に入社し、データパイプライン領域でエンジニアとして働いています。
今日は皆さんにヤフーのデータパイプラインの役割と、私たちが取り組んだデータパイプラインの信頼性を高める取り組みについてご紹介します。
ヤフーのデータパイプライン
ヤフーは検索やEコマース、ニュースをはじめとした多くのサービスを運営しています。それらのサービスが保持するデータは非常に量が多く、かつ価値の高いものです。特に近年はデータソリューションサービスをはじめとして、さまざまなサービスのデータを横断して適切に利活用することで皆様の生活をより便利にする取り組みを多く始めています。
さて、サービスのデータを横断的に利活用するためには、まず各サービスのデータを効率的かつ簡単にデータレイクと呼ばれる場所に収集したり、さまざまなシステムとデータを受け渡したりする工程が発生します。以下の図のようにこの工程を担い、効率的にデータをやりとりするシステムをデータパイプラインと呼んでいます。
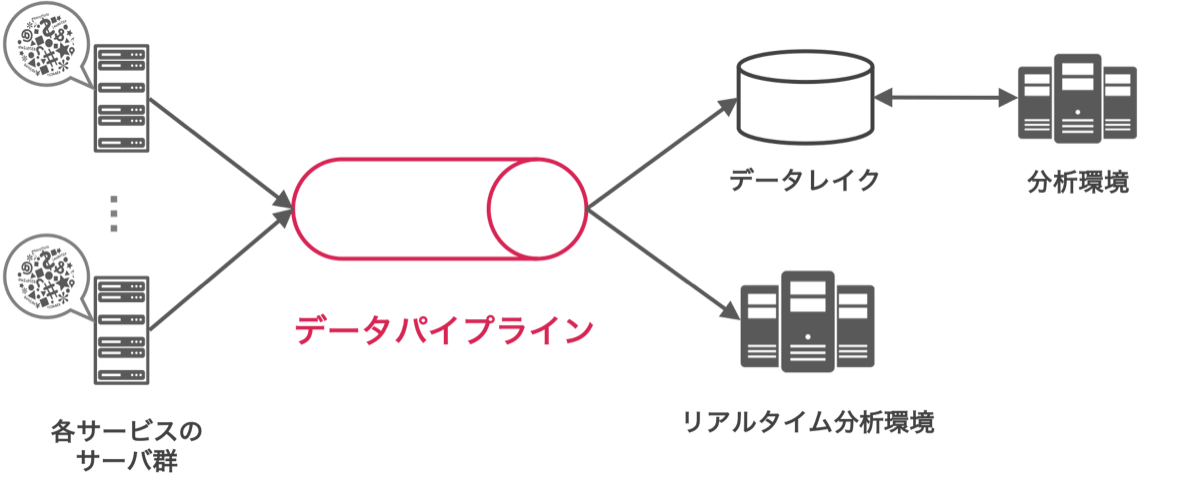
データパイプラインを作る場合、メッセージングキューイングシステムと呼ばれるソフトウエアを活用して作る例が多いです。ヤフーでは他の基盤システムとの連携やコミュニティーの将来性などを鑑み、Apache KafkaというOSSをベースにデータパイプラインを構築しています。
Apache Kafkaとは
今回寄稿した内容を理解する上での前提知識として、Apache Kafkaとその一部の概念をご紹介します。
Apache Kafkaは、Publish/Subscribeアーキテクチャを採用した分散メッセージングシステムと呼ばれるOSSです。メッセージを送信(Publish, KafkaではProduceと呼ばれる)するProducer、メッセージを購読( Subscribe, KafkaではConsumeと呼ばれる)するConsumerと、中央でメッセージキューの役割を担う複数台のBrokerで構成されます。 Kafkaには Topic と Partition という概念が存在します。Topicとはメッセージの種類を示す概念です。「サービスAのメッセージはTopic Aに、サービスBのメッセージはTopic Bに...」というように異なるカテゴリーのメッセージを1つのKafkaクラスタで扱うことができます。PartitionとはKafkaに実際にTopicのメッセージをキューイングする時の並列処理数を表す概念です。ここまでの内容を図に示すと以下の通りです。
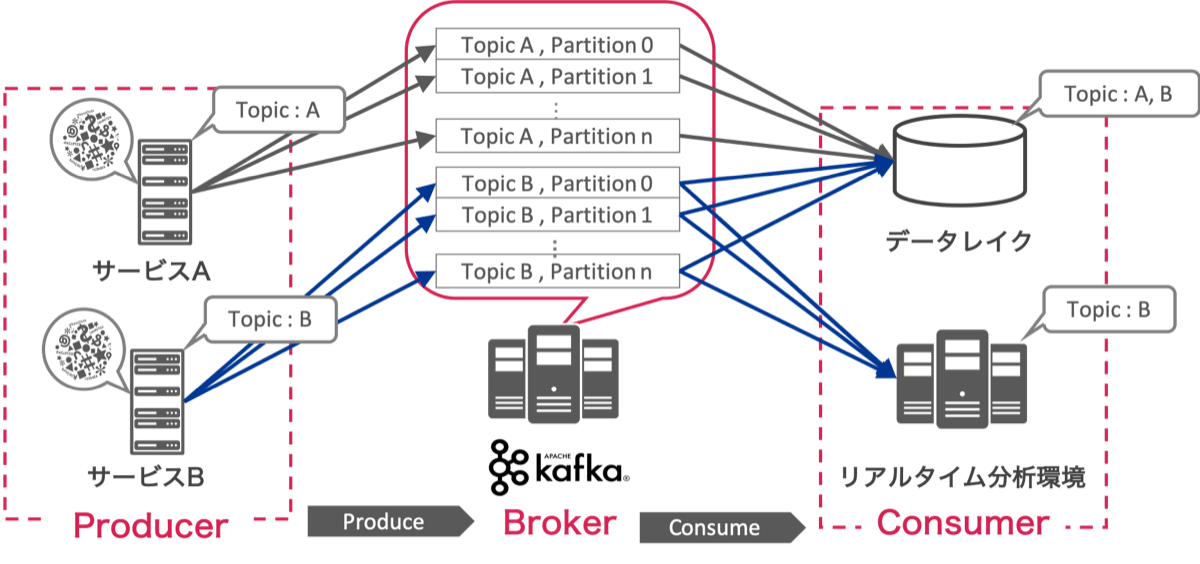 特にPartitionはKafkaでの処理の分散やメッセージの保持を行うために非常に重要な概念です。一般的に1つのTopicは複数のPartitionに分かれており、Producerは一定のルールに従って複数のPartitionにメッセージを振り分けながらProduceします。さらにPartitionはメッセージの欠損を防止するため以下の図のように複数のReplicaというキューで構成されており、名前の通りReplica同士でメッセージを複製しながらキューイングしていきます。以下の図の例では2つのPartitionがそれぞれ3つのReplicaで構成されています。
特にPartitionはKafkaでの処理の分散やメッセージの保持を行うために非常に重要な概念です。一般的に1つのTopicは複数のPartitionに分かれており、Producerは一定のルールに従って複数のPartitionにメッセージを振り分けながらProduceします。さらにPartitionはメッセージの欠損を防止するため以下の図のように複数のReplicaというキューで構成されており、名前の通りReplica同士でメッセージを複製しながらキューイングしていきます。以下の図の例では2つのPartitionがそれぞれ3つのReplicaで構成されています。
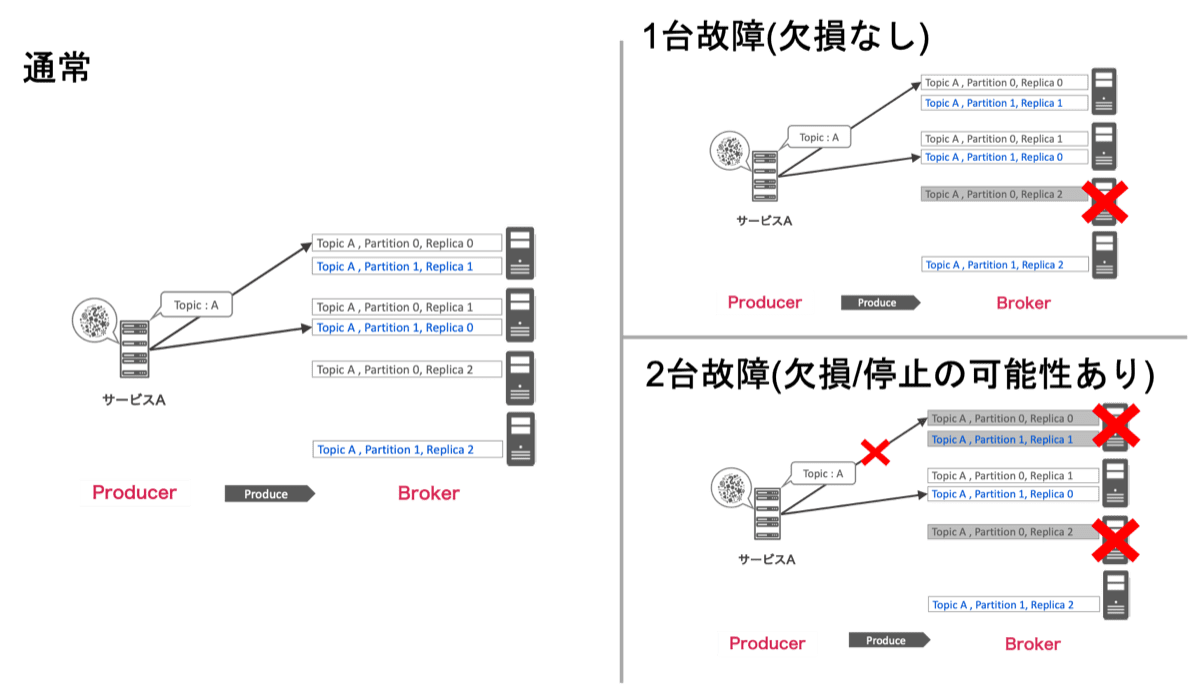
Kafkaでは、メッセージが欠損しないことを担保するために 常に2つ以上のReplicaが同期している 必要があります。同期しているReplicaがあれば、片方のReplicaがダウンしても全てのメッセージを保持したReplicaが他に存在しますが、同期したReplicaがない状態で全てのメッセージを保持したReplicaがダウンするとメッセージを失ってしまいます。一方、2つ以上のReplicaが同期していればよいため、上記の図のようにReplicaをそれぞれ異なるホストに配置し適切な設定を行うことで、設計上は (Replica数 - 2)台まで Replicaの存在するマシンに故障が発生してもメッセージが欠損しない状態を担保して稼働できます。もしそれ以上の故障が発生した場合、Partitionは「欠損する可能性を受け入れながら稼働を続ける」か「Replicaが復帰するまでメッセージがProduceされることを拒否する」のいずれかの動作を行います。上記の図の例では、全てのPartitionでReplicaは3つ存在するため、1台故障しても欠損は発生しませんが、2台故障するとPartition 0のReplicaは1個になってしまうため、Partition 0はメッセージの欠損もしくはProduceの停止が発生する可能性があります。
メッセージの欠損防止と可用性を低コストで両立するために
メッセージ欠損の発生シーンと一般的な対策
サービスのデータをより横断的に利活用できる環境は、いつでも確実に必要なデータが用意できなければ成り立ちません。データを集める役割を担うデータパイプラインの品質はこのような環境の品質に大きく影響を与えます。そのため私たちはパイプラインの品質の目標として「メッセージを始点から終点まで欠損なく運びつづけること」「パイプラインが常に稼働を続けていること」の2点を掲げています。 先ほども書きましたが、メッセージを欠損なく保持し、稼働しつづけるためには、(Replica数 - 2)台を超えるサーバーの故障を同時に起こしてはいけません。もちろん複数のサーバーが同時多発的に故障することはめったに発生しませんが、万が一発生してしまった時の影響の大きさを考えると、これを阻止する方法を構築する必要がありました。
最も単純なのは、「Replica数を増加させる」という方法になると思います。ただしReplica数を増やすことはサーバー台数を増やすこととほぼ同義であるため、相応の設備投資が必要になり経済合理性を得るのが難しくなります。またReplica数を増やすということは、その分だけReplica間の複製処理やトラフィックの負荷が大きくなるということであり、クラスタ全体へのパフォーマンスにも影響を与えかねません。そしてReplica数をいくら増やしても、「(Replica数 - 2)台を超えるサーバーの故障が発生した場合Replica数が1以下になってしまい、メッセージの欠損もしくはProduceの停止が発生しうる」という状況の打破には至りません。加えて、私たちの要件を満たし解決の参考になる他の事例は見当たりませんでした。
そこで私たちは、Replica数が1以下になったPartitionが発生してもメッセージ欠損や可用性低下の被害を最小限に抑える という構成をソフトウエアで作り上げることができないか考えました。
ソフトウエアで欠損や可用性の低下を防ぐ ~ PartitionerのFailover ~
先ほど「Producerは一定のルールに従って複数のPartitionにメッセージを振り分ける」と書きました。この振り分ける動作で重要なProducerのコンポーネントをPartitionerと呼びます。私たちは、このPartitionerに Failoverの機能を追加する アプローチでこの課題を解決することにしました。
具体的には、同期したReplica数が2つを下回ったPartitionを検知して、安全に使用できない「Offline Partition」とみなし、Offline PartitionにProduceする予定だったメッセージを、同期したReplicaの数が十分存在する「Online Partition」に振り替えてProduceします。この振り替えてProduceする動作を私たちはFailoverと呼んでいます。
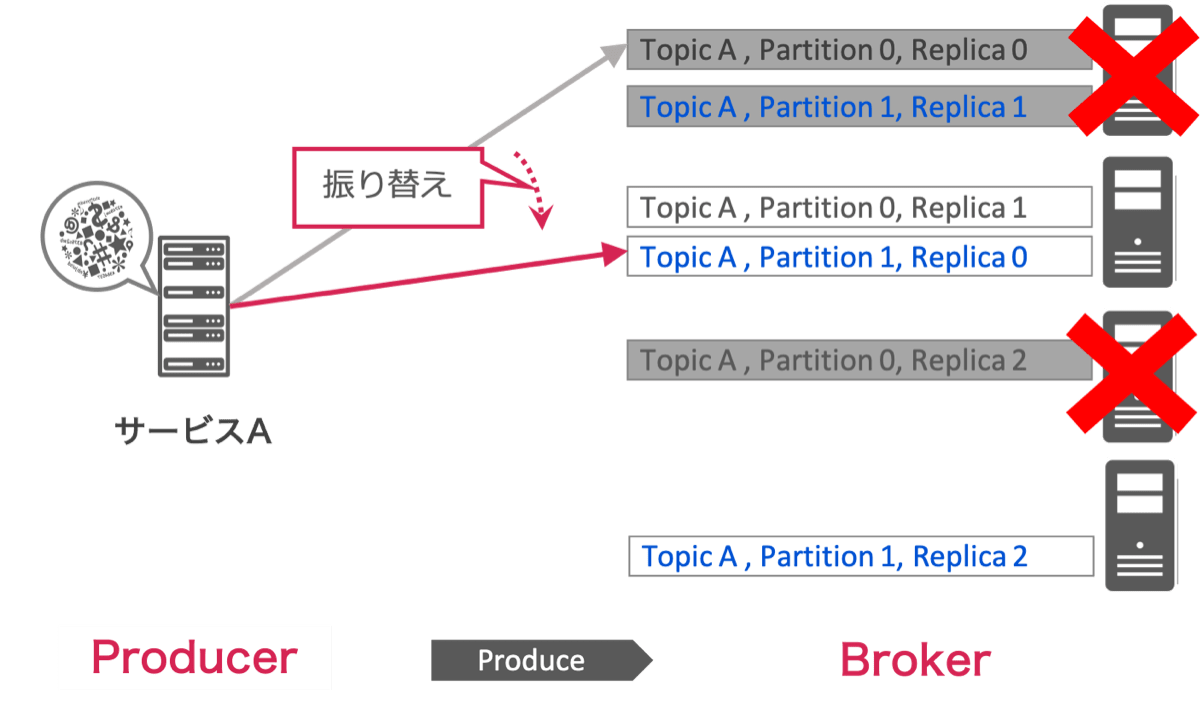
上の図はFailoverの概念を簡潔に表した図です。Replicaが3つ存在する環境で2台のマシンが故障し、Partition0のReplicaは1つしか生存していない状態に陥ったとします。Partitionerはこの状態を検知し、Replicaが2つ以上生存しているPartition1にProduce先を振り替えてメッセージを送信します。Failover動作によってOffline PartitionにメッセージをProduceすることがなくなるため、本質的にメッセージの欠損を抑えながら稼働を続けることが可能になります。
理由などの詳細は省きますが、この考え方でFailoverを行うためには以下の条件をクリアする必要があります。
- Failover対象のPartitionのReplicaで使用しているサーバーとは別のサーバーに、Replicaを配置しているPartitionが存在すること
- メッセージの順序が多少崩れることを何らかの形で許容できること
- メッセージの重複を何らかの形で許容できること
- 後続の処理で、全てのPartitionに本来のルール通りメッセージが振り分けられる前提で作られた処理が存在しないこと
幸いなことに、私たちの要件では上記のいずれの条件もクリアすることができたため、Failover化したPartitioner(Failover Partitioner)の導入を決定し、実装を進めることができました。
実装において苦労した点
この実装において最も苦労した部分は、不良を検知して切り替える瞬間のメッセージを正しくFailoverさせる制御の難易度が非常に高かった点です。 Kafkaはいわゆるストリーミング処理を担うシステムですので、メッセージは常に流れ続け、途切れる瞬間はありません。また、Partitionが実際にOffline状態になってから、ProducerがそのPartitionをOfflineになったと認識するまでにはタイムラグが発生してしまいます(詳しくは省略しますが、メッセージをBrokerにProduceするタイミングとPartitionの情報をBrokerに取得するタイミングは異なるため、数秒程度のタイムラグがあります)。
すなわち、Offline Partitionができた直後は OfflineになってしまったPartitionにProduceしようとしてしまうメッセージがかなりの数発生してしまいます 。加えてKafkaは正常な状態でないPartitionにProduceを試みた場合エラーを出して一定回数Produceを再試行しますが、再試行の際にメッセージを別のPartitionに割り当て直すことは行えない構成となっています。
そのためPartitioner以外に、エラーを起こしたメッセージを失敗用キューに一度ため込み、再び新たなメッセージとしてProduceを行うためのリトライ用コンポーネントを新たに設計/実装し、図のようなアーキテクチャにすることになりました。
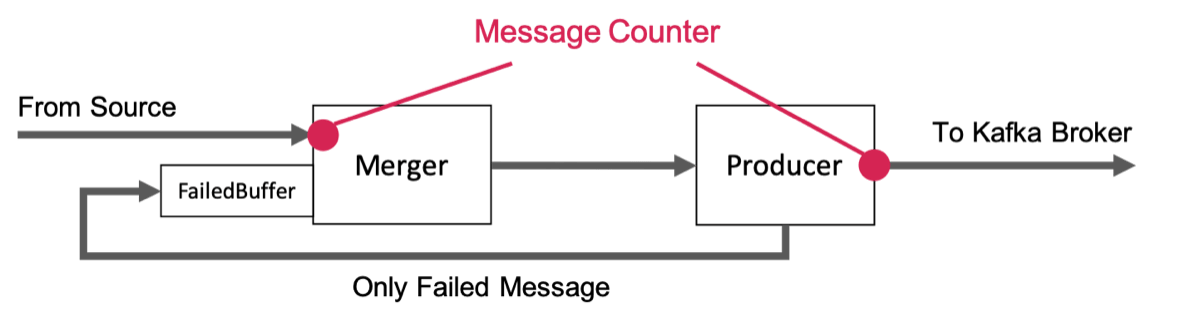
ここからは少々実装寄りの話になりますが、私たちはKafkaのProducerをsaramaというGolang製のクライアントライブラリを利用して作成しています。saramaではKafkaをProduceするメソッドはgoroutineとchannelを用いて実装されています。そのため失敗したメッセージを受け取りそのままProduceするchannelを作ってしまうと、メソッドのoutputがそのまま自身のメソッドのinputに直接つながり、goroutineがデッドロックの状態に陥ります。
これを防ぐためchannelにBufferを持たせることになりますが、Producerに流れるメッセージの流量やReplica数の変化を認識するまでのタイムラグは毎回異なるため、必要十分なBufferのサイズを見積もることが困難でした。また考えられるBufferサイズの最大値を設定した場合、Failoverする数秒間のために、ある程度まとまったメモリ容量を確保することになり、あまり許容できるものではありませんでした。
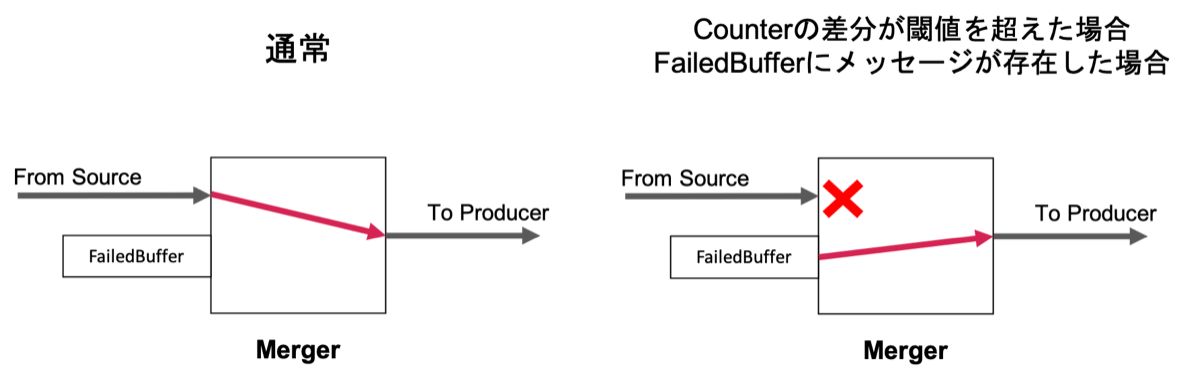
そこで私たちは失敗したメッセージが大量にあると判断した場合、予め新たなメッセージのProduceを停止する制御を追加しました。具体的には、Produceするメソッドにinputしたメッセージ数とKafkaへのProduceに成功したメッセージ数をMessage Counterで保持しておき、2つの差分を比較することにしました。2つの値に大きな差分があった場合は失敗したメッセージが大量に存在すると判断し、以下の図のようにMergerと呼ぶコンポーネントで失敗したメッセージのみをProduceするように制御しました。この制御を追加し、Buffer溢れを防ぐことでFailoverを実行する瞬間に発生するProducerのデッドロックを防ぎました。
Partitioner自身の改良と合わせてこの改良を取り込むことで、欠損とパイプラインの停止を最小限に抑制するProducerを完成させることができました。
最後に
本記事では、ヤフーのデータパイプラインとそれに使用しているApache Kafkaについての解説と、データパイプラインで欠損や可用性の低下を抑制するためのFailover Partitioner実装の取り組みについてご紹介しました。
この機能追加を行ったProducerは、テストを経て今年の3月ごろに社内リリースを実施し、サービスのサーバーに多数導入され、私たちのデータパイプラインの品質向上に貢献しています。
今回の例のようにヤフーのデータプラットフォームでは、万が一の事態を考えて先回りして品質向上に取り組んでおり、今後も積極的に行っていく所存です。またデータパイプライン領域は他のビッグデータ処理領域と比べて認知度などは決して高くないですが、この記事をきっかけにデータパイプラインやその周辺の技術に興味を持ってくれる方が増えればうれしいです。
Apache Kafkaは、The Apache Software Foundationの米国およびその他の国における登録商標または商標です。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました



