こんにちは、データ&サイエンスソリューション統括本部所属の後藤泰陽(@ono_matope)です。少し時間があいてしまいましたが、9月19日にお茶の水女子大学で開催された WebDB Forum 2017 において、分散オブジェクトストレージ “Dragon” について講演しました。良い機会なので、本エントリでもDragonについてご紹介させていただきたいと思います。
発表資料
WebDB Forumでの発表資料については以下をご覧ください(講演時の内容と一部異なります)。
日本語版
英語版
Dragonとは?
Dragonは、ヤフー・ジャパンで開発された分散オブジェクトストレージシステムです。Amazon S3互換のWeb APIを実装しており、Yahoo!ニュースやヤフオク!など、社内で250以上のチームやシステムがDragonを利用しています。2016年1月のリリース以来、国内2カ所のデータセンターで稼働しており、現在までに合計で200億個以上、データサイズにして11ペタバイト(物理データサイズでは33ペタバイト)のオブジェクトを格納しています。
なぜ作ったの?
ご存じの通り、弊社では非常に多くのサービスやアプリを開発してユーザーの皆様に提供していますが、そうしたサービス開発のなかで、メディアコンテンツの管理からログ解析まで、多様なストレージのニーズが発生します。2011年からは内製のオブジェクトストレージ Octagon が稼働していましたが、残念ながら社内のニーズに十分に応えることができず、サービスごとに独自に(OSSやエンタープライズアプライアンス製品を含め)ストレージシステムを運用しているといった状態でした。
このような状況では開発者が本来のサービス開発にフォーカスできないため、社内サービス開発の要件を満たし、将来のデータ需要の急激な増加に耐えられるスケーラビリティを持つ、全社横断的なオブジェクトストレージ基盤を目指して開発されたのが Dragon です。既存のOSS製品の採用も検討されましたが、一部サービスでの採用事例や事前検証から弊社のスケールとトラフィックで安定的に運用するのは難しいと判断され、完全に独自なシステムの開発がスタートしました。
名前の由来は?
ドラゴンの伝説は世界中に存在し、ときに万物の始原とされますが、特に水中に棲み空を飛ぶ日本や中国の龍は古来より水の神として信仰され、神通力を持つ宝珠を守護します。まさに雲(クラウド)の源としてデータを守るオブジェクトストレージにピッタリな名前なのです。
特長は?
Dragon は、高速、高可用性、高スケーラビリティ、高コスト効率といった特長を持っています。
- 高速: Goの効率の良いI/O処理の効果などにより、高い性能を獲得しています。また後述するダイナミック・パーティショニングなどの工夫により、オブジェクト数が増えても書き込み性能が維持されます。
- 高可用性: 全てのコンポーネンネントに単一障害点がないため、無停止運用を実現しています。
- 高スケーラビリティ: MetaDBとStorageノードが分離したアーキテクチャにより、コンシステントハッシュを採用した分散ストレージよりも素早くスケールアウト可能です。
- 高コスト効率: ハードウェアとして60~90HDDベイを備えた高密度ストレージサーバーを採用することなどによって、高いコスト効率を実現しています。
パフォーマンスは?
スライドでは Riak CSとの性能比較を紹介しましたが、ここではDragonを実際の環境に近い試験用ハードウェアで動作させた場合の性能をご紹介します。
- 計測条件:
- クラスタ構成
- API x1ノード: (Xeon E5-2630 1.80GHz / 2CPU / 64GB RAM / 10GBase-T )
- Storage x3ノード: (Xeon E5-2630 1.80GHz / 2CPU / 128GB RAM / 10GBase-T / SAS HDD 4TB * (1+10) )
- Cassandra x3ノード: (Xeon E5-2630 1.80GHz / 2CPU / 128GB RAM / SATA SSD 4 * 400GB )
- NW帯域10Gbps
- 性能測定ツールにCOSBenchを使用
- クラスタ構成
- 結果
- 1KBオブジェクト
- ダウンロード: 最大約28,000rps / アップロード: 最大約10,000rps
- 100KBオブジェクト
- ダウンロード: 最大約10,000rps / アップロード: 最大約3,200rps
- 1KBオブジェクト
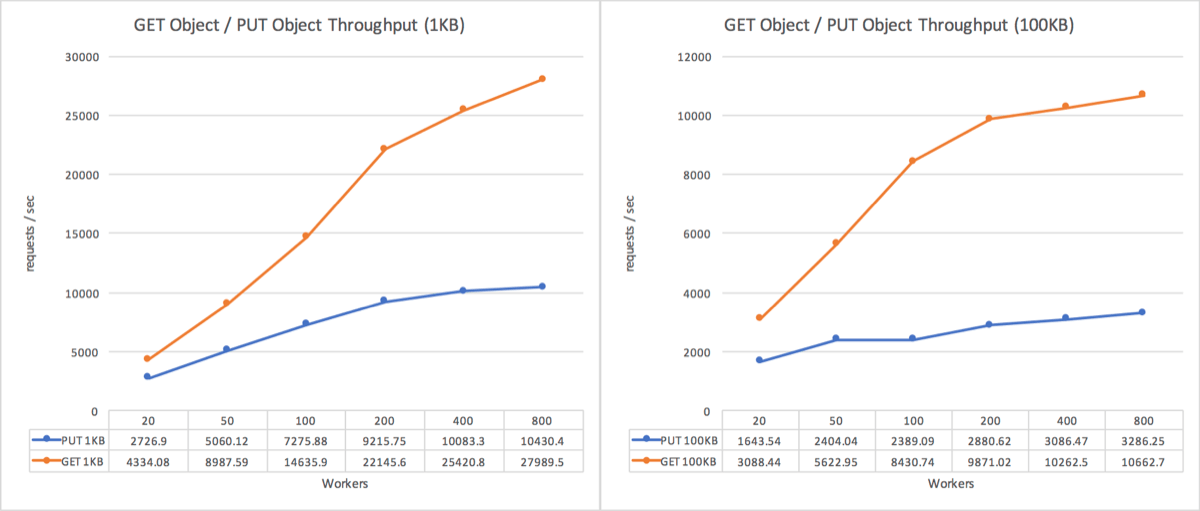
小規模構成の性能としては十分に高速と言えるパフォーマンスを達成しています。特に100KBでは、アップロードではデータを同時に3ノードにレプリケーションすることを考えると、上り下りともネットワーク帯域10Gbpsのうち8Gbp前後を使い切ることができています。 以前のOctagonと比べても、書き込みで20倍、読み込みで3.5倍の高速化を実現しています(150KBのオブジェクトへの10並列リクエストのスループット)。
アーキテクチャは?
Dragonのアーキテクチャは、下の図のようにAPI, Storage, MetaDBの3コンポーネントで構成されています。
- APIノード
- Amazon S3互換APIを提供し、全てのユーザーリクエストを受け付けるレイヤーです。
- Go言語で開発されています。
- Storageノード
- ユーザーがアップロードしたオブジェクトのBLOB(データ実体)を保存するストレージサーバーです。
- 通常3台のStorageノードでVolumeGroupを構成します。VolumeGroupに属するStorageノードは互いにデータを同期(アンチエントロピー・リペア)しているため、Dragonのデータ実体はVolumeGroup内の3ノードが同時に障害を起こさない限り安全に保持されます。
- Go言語で開発されています。
- MetaDB
- アップロードされたオブジェクトのメタデータを保存するApache Cassandraクラスタです。メタデータには、オブジェクトのサイズやアクセス権限などの情報のほかに、BLOBの格納位置の情報を含んでいます。
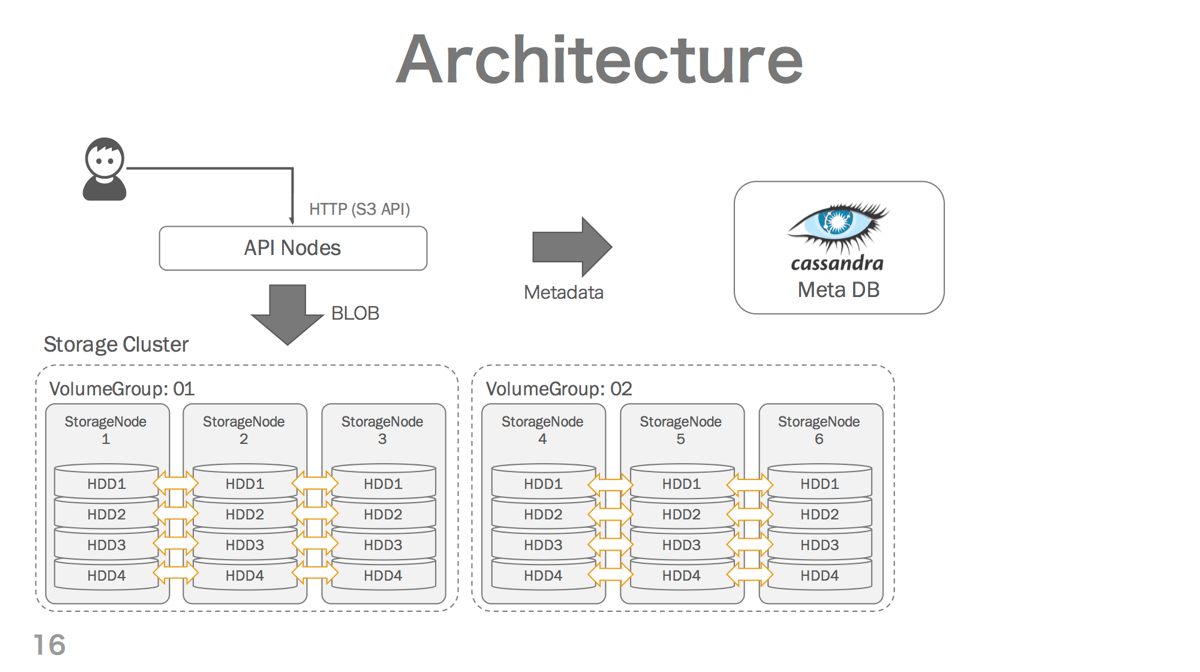
ユーザーによるアップロード、ダウンロードの操作は以下のように実現されます。
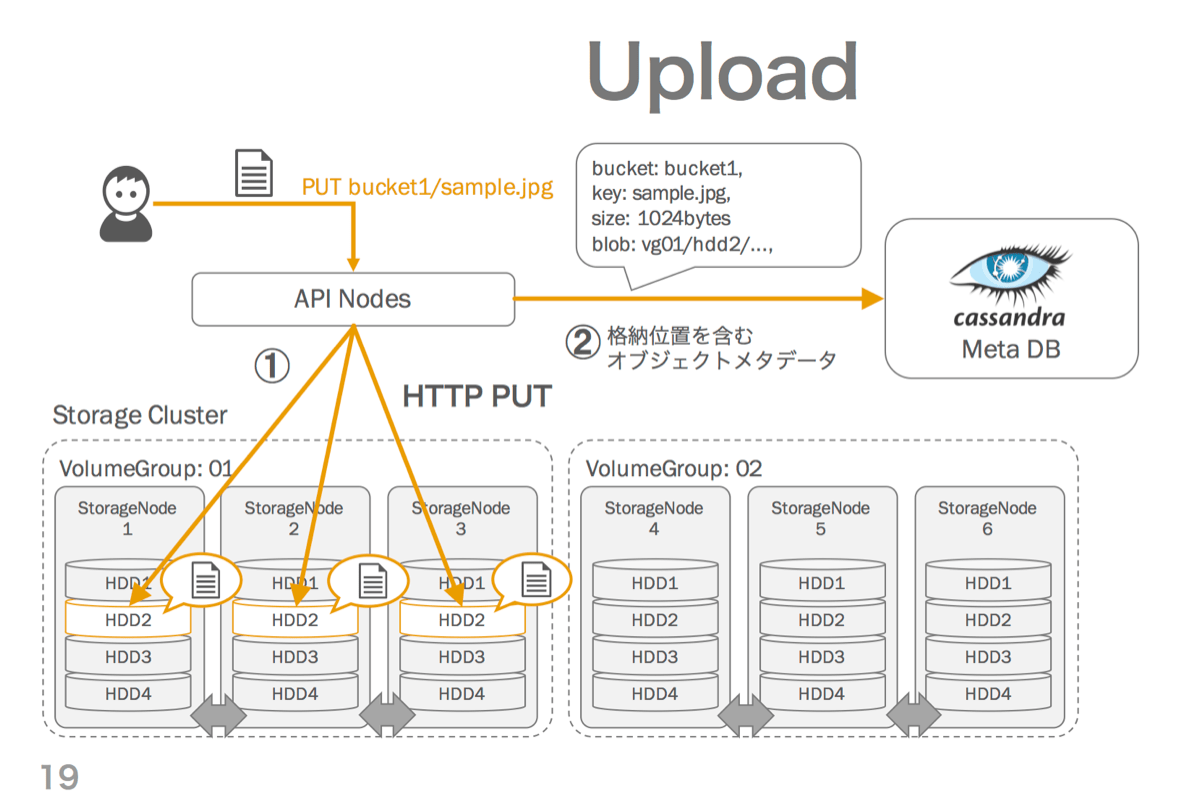
アップロード操作
アップロード時、APIはランダムに選択したVolumeGroupのStorageノード3台にHTTPのPUTリクエストでBLOBを並列転送し、そのBLOBロケーションを含むメタデータをMetaDBにストアします。
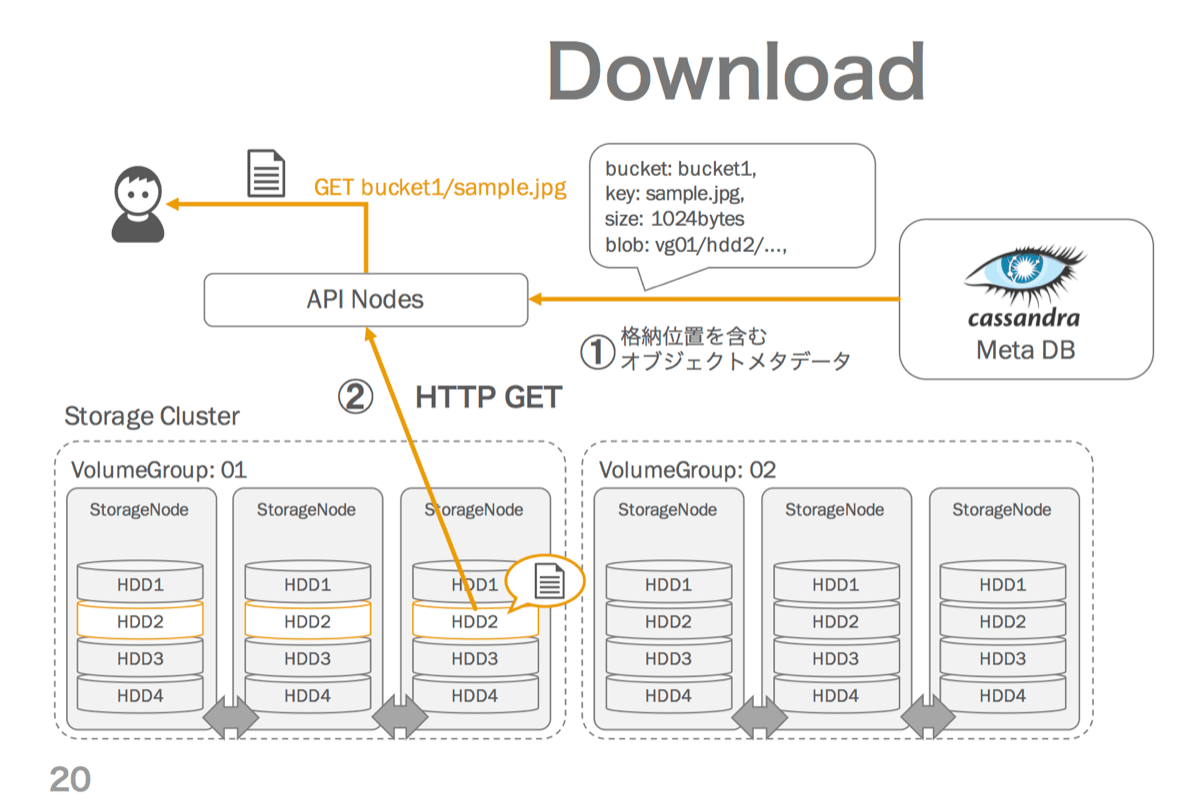
ダウンロード操作
ダウンロード時、APIはMetaDBからメタデータを取得し、それに含まれるBLOBロケーション情報をもとにStorageノードにHTTPのGETリクエストを発行し、レスポンスをユーザーにレスポンスします。
分散アーキテクチャについて
ここまで説明したDragonのアーキテクチャは、オブジェクトの名前からデータ実体の格納位置へのマッピングをデータベースを用いて管理する、いわばマップ型のアーキテクチャと言えます。他方、多くの分散KVSやRiak CS、OpenStack Swiftなどのオブジェクトストレージ製品が採用する、コンシステント・ハッシュなどを用いたハッシュ型のアーキテクチャでは、マッピングをハッシュ関数の計算で求めることができるため、マップを管理するデータベースが必要ありません。
しかし、ハッシュを用いた分散アーキテクチャの場合、ノードの追加や離脱時に 「全体のデータ量/変更後のノード台数」のデータをリバランスのためにノード間で転送する必要があります。オブジェクトストレージシステムは、一般的な分散KVSよりも使用されるハードウェアのデータ容量が大きいという特徴があるため、この転送が問題になります。たとえば1ノードのストレージ容量が720TBの場合、データが100%ロードされた10ノードのクラスタに1ノードを追加するときには
720 TB * 10 / 11 = 654 TB
のリバランス転送が必要になります。この転送に平均2Gbpsのネットワーク及びI/O帯域を割り当てた場合、リバランス転送は1ヶ月にも及びます。リバランス転送が終わらないとキャパシティのさらなる追加はできないので、このリバランス転送はキャパシティプランニング上の大きな制約になる可能性があります(言い換えれば、クラスタのスケールアップ速度がリバランス転送帯域によって制限されることになります)。急なデータ需要の増加に柔軟に対応できないということは、Webサービスプロバイダとして大きなリスクなので、Dragonではハッシュ方式ではなく、スケールアウト時のリバランス転送が不要なマップ方式の分散アーキテクチャを採用しました。
この手法のその他のメリットとして、MetaDBとStorageノードの分離により、Storageノードの実装がプラガブルになり後から変更や追加が容易になる、メタデータの分散ストア部分を安定した既製品に移譲することで開発コストを抑制できるなど、副次的な効果もありました。 デメリットとして、ストレージ負荷が不均一になりがちという問題がありますが、これはノード増設とは独立したリバランス処理や、古いデータをアーカイバルストレージに退避させるなどのアプローチで対応しようと考えています。
Storageノード
ダイナミック・パーティショニングとは?
DragonのStorageノードでは、ユーザーがアップロードしたひとつのオブジェクトのBLOBを、ひとつのファイルとしてファイルシステム上で永続化しています。これは、枯れたファイルシステム(ext4)を利用することで、開発スコープを抑えるともにデータ保持の信頼性を上げることを狙った設計上の判断ですが、一般的にファイルシステムは非常に大量のファイルをうまく扱うことはできません。例えば、OpenStack Swift も Dragon と同様にファイルによる永続化を採用していますが、ファイル数が多くなると書き込み性能が低下することが報告されています。Dragon では、この問題を回避するために、私たちがダイナミック・パーティショニングと呼んでいるテクニックを使用しています。
Swiftをはじめとして、ファイルシステムに大量のファイルを格納する場合の典型的な戦略は、事前に作成した一定数のディレクトリに、ハッシュなどを用いて均一にファイルを作成していくというものです(ディレクトリ構成は実装により差異があります)。
一方でDragonは、ファイルを格納するディレクトリ(パーティション)を連番で管理し、APIノードは常に最新のパーティションにファイルを書き込み要求するという手法を採用しました(ファイルの書き込み先パーティションはオブジェクトのメタ情報としてMetaDBに格納します)。Storageノードはパーティション内のファイル数を監視し、ファイル数が一定の値(例えば1000ファイル)を超えると、次のパーティションを作り、APIノードに知らせます。
ふたつの手法でファイルを作成した場合のストレージ書き込み性能の推移を示します。横軸は累計のファイル数、縦軸は書き込みリクエストの秒間処理数です。ハッシュ手法ではファイル数の増加に伴い書き込みスループットが低下していますが、ダイナミック・パーティション手法ではファイルが増えても性能の低下がほとんど見られません。この結果から、Dragonの手法では一台のHDDに対して、少なくとも1000万ファイルまで書き込み性能が維持されることが分かります。
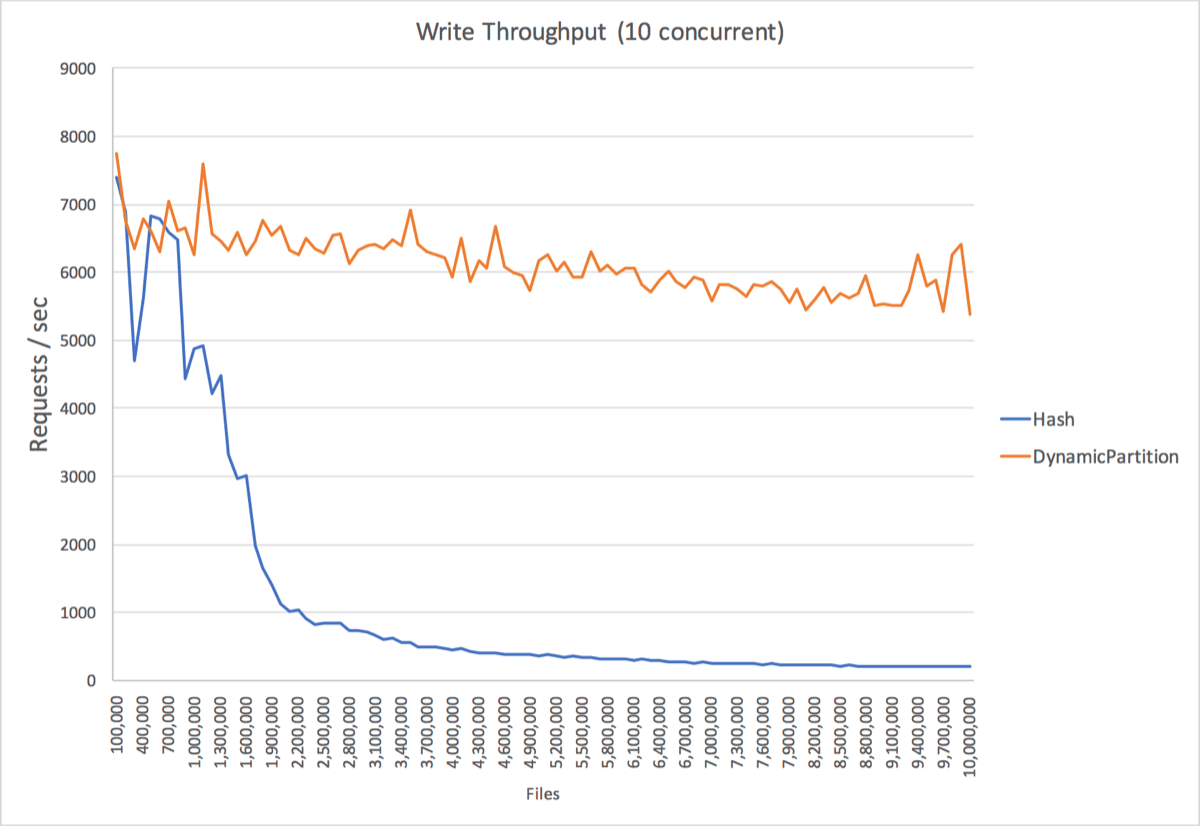
計測条件:両手法によるファイル作成部分を実装した簡易なHTTPサーバーを実装し、ローカルホストからabを用いて10並列で1000万ファイルまで50KBのファイルをアップロードした結果。10万リクエストごとに性能を計測し平均秒間リクエスト数を採用し、dirty pageの影響を排除するために各計測前にsyncとdrop cacheを実行した。
しかし、なぜこのような結果になるのでしょうか。下の図は、両手法での書き込み実行中に発生したWriteブロックI/Oの様子を blktrace および seekwatcher で計測した結果です。ハッシュ手法(上)はファイルの増加とともにI/Oオフセット(論理アドレスブロックで示されるブロックデバイス上の書き込み位置)の範囲が広がり、シーク回数が増え、結果としてスループットが低下していることが分かります。一方でダイナミック・パーティション手法(下)では、ファイルが増えてもI/Oオフセットが全体的に正方向に推移し、I/Oオフセットの範囲が狭いまま保たれ、シーク数が増加せず、高いスループットが維持されることが分かります。
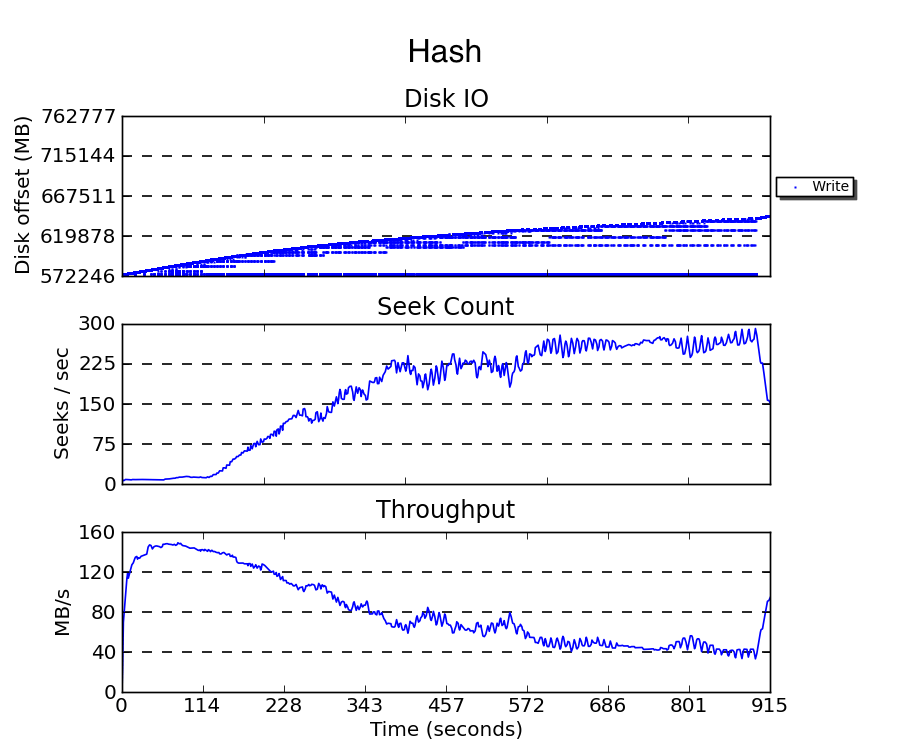
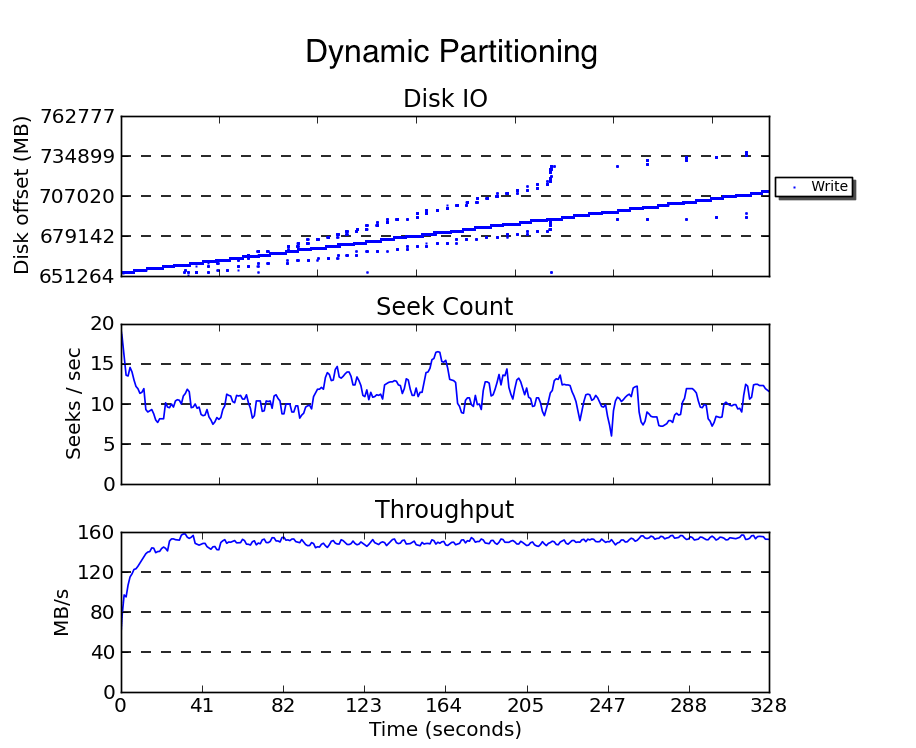
計測条件:上と同様の状況で300万ファイル作成した際のWriteのブロックI/Oをblktraceで計測しseekwatcherでプロットした。本計測では10万ファイルごとのpage dropは行なっていない。
ファイルの作成や削除には、ファイルのデータブロック、iノードブロック、そして親ディレクトリのデータブロックへの読み書きが必要になります。また、ディレクトリのサイズが大きくなると、ディレクトリのHTreeインデックス分割のために追加のランダムI/Oも必要になります。ext4では通常、ファイルシステムの最適化によりファイルのデータブロックは親ディレクトリと出来るだけ近くのブロックグループに割り当てられるため、更新されたページを効率的に(HDDのディスクヘッド移動を最小限に抑えて)ブロックデバイスにフラッシュすることができます(『詳解Linuxカーネル第三版』18.6章参照)。しかし、近傍のブロックグループが使い尽くされると新しいファイルは次第に親から離れたブロックグループに割り当てられ、ファイル操作に必要なI/Oがディスク上の広い範囲に散らばるため、書き込み性能が低下します。
ダイナミック・パーティショニングの場合は、一定のファイル数で書き込み対象のディレクトリが新たに作られるので、ファイルとディレクトリのデータブロックの近接性が保たれるため性能が維持されていると考えられます(その他にも、ディレクトリのサイズが一定以上大きくならないのでディレクトリのHTree分割や断片化が起こりにくいこと、同時に書き込まれるディレクトリが少数に限定されるので、データブロック割り当ての最適化効果が高まることも性能に貢献していると考えられます)。
アンチエントロピー・リペアとは?
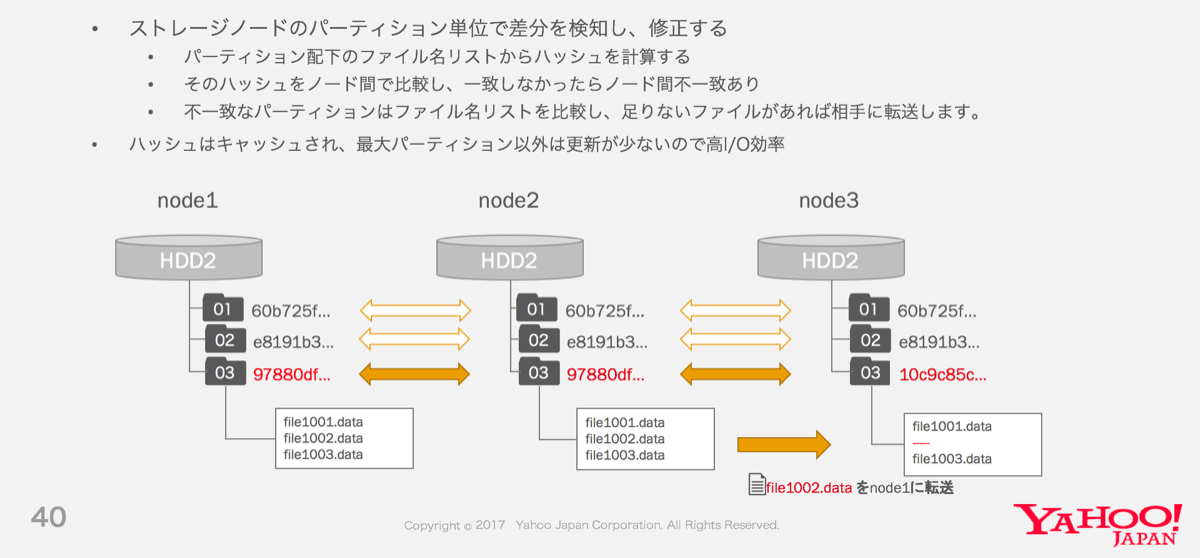
このダイナミック・パーティショニングは、Storageノード間のデータ同期でも効果を発揮します。Dragonは、VolumeGroupに属するノードが常に同じデータを保持するように、定期的にアンチエントロピー・リペア処理を実行します。このリペア処理は、各パーティションが持つファイル名のリストのハッシュをノード間で交換して不一致を検出し、欠けたBLOBファイルを転送するという手法で実装されています。
パーティション単位でコンシステンシを検証する点はOpenStack Swiftのリペア処理と同様ですが、Dragonの場合は、ダイナミック・パーティショニングの特性により、古いパーティションのハッシュの更新頻度が低いという特徴があります。Storageノード自体はパーティションハッシュのキャッシュを保持するため、パーティションハッシュのキャッシュヒット率が上がり、I/O効率の良いハッシュ交換が可能です。
MetaDB
オブジェクトのメタデータは?
Dragonではメタデータの格納先としてApache Cassandraを採用しています。Cassandraは可用性が高く、リニアに性能がスケールし、運用コストの低い、弊社でも普及したデータストアです。そのため2クラスタ合計で200億オブジェクトのメタ情報を低レイテンシでストアすることができています。一方で、Cassandraの一貫性サポートは結果整合性のみで、ACIDトランザクションのサポートがありません。そのため、書き込んだ内容がすぐに参照できる保証もなく、同一リソースへの同時更新も起こり得るという条件で、矛盾なくデータを管理するデータモデリングをする必要がありました。
Dragonのオブジェクトのメタ情報は、Cassandra上のObjectテーブルに格納されています。このテーブルの行は {バケット名,オブジェクトキー} のタプルのハッシュによりクラスタ内で分散して格納されます。それぞれのパーティション内では同名オブジェクトの複数のバージョンが、アップロード時刻のUUIDをクラスタリングキーとして、時系列の降順にソートされた状態で格納されてます。削除要求もひとつのバージョンとして書き込まれます。
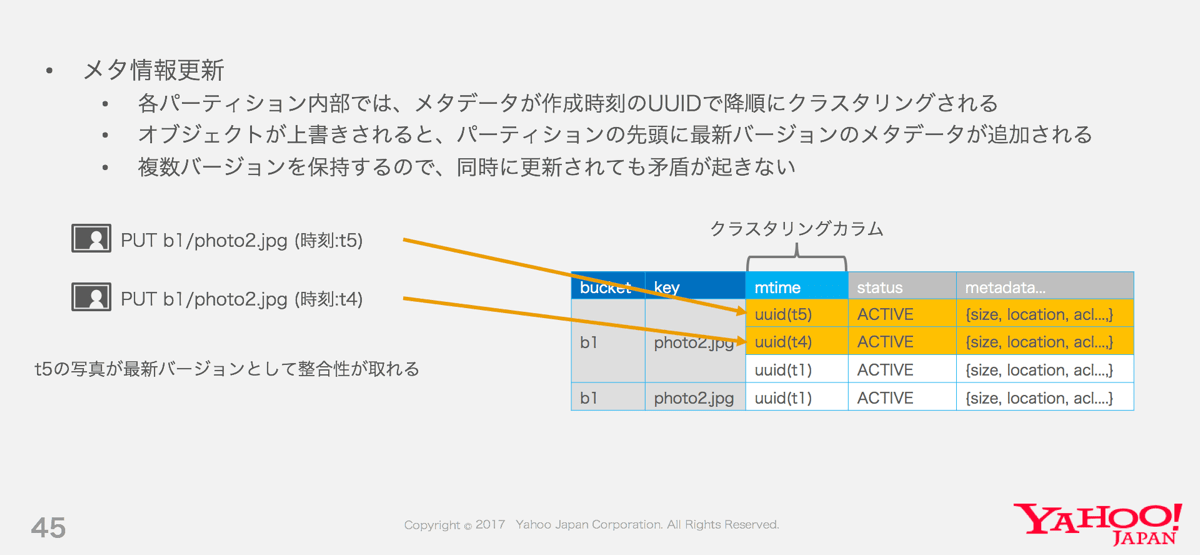
このデータモデルにより、オブジェクトのメタ情報の更新はRead-And-Writeではなく単体のINSERTですみ、参照はパーティションの先頭1行のSELECTで最新のメタ情報が取得できるため、効率的なユーザーリクエストの処理が可能です。また、各パーティションの2行目以降は常に不要なオブジェクトのメタデータなので、単純なテーブルのフルスキャンによって、オブジェクトのBLOBとメタ情報を削除(Object Garbage Collection)することができます。(GCのためにフルスキャンが必要なのは非効率に聞こえるかもしれませんが、ランダムアクセスよりも低負荷で実行できます)。

オブジェクトの一覧取得は?
S3 APIには、バケットに含まれるオブジェクトを辞書順にレスポンスする List Objects API が存在します。前述の通り、オブジェクトのメタデータはCassandraクラスタ上にランダムオーダーで分散して格納されています。そしてCassandraはパーティションをまたぐレンジ取得操作はサポートしていないので、ObjectテーブルだけではこのAPIを実装できません。
そのため、バケット名をパーティションキーとし、各パーティション内でオブジェクトのメタ情報が辞書順に格納された ObjectIndex テーブルを別途管理し、オブジェクト一覧の要求時には当該パーティション内をレンジ取得しています。データの更新はObjectテーブルと同一のAtomic Batchで行われるため、Objectテーブルの内容と自動的に同期されます。
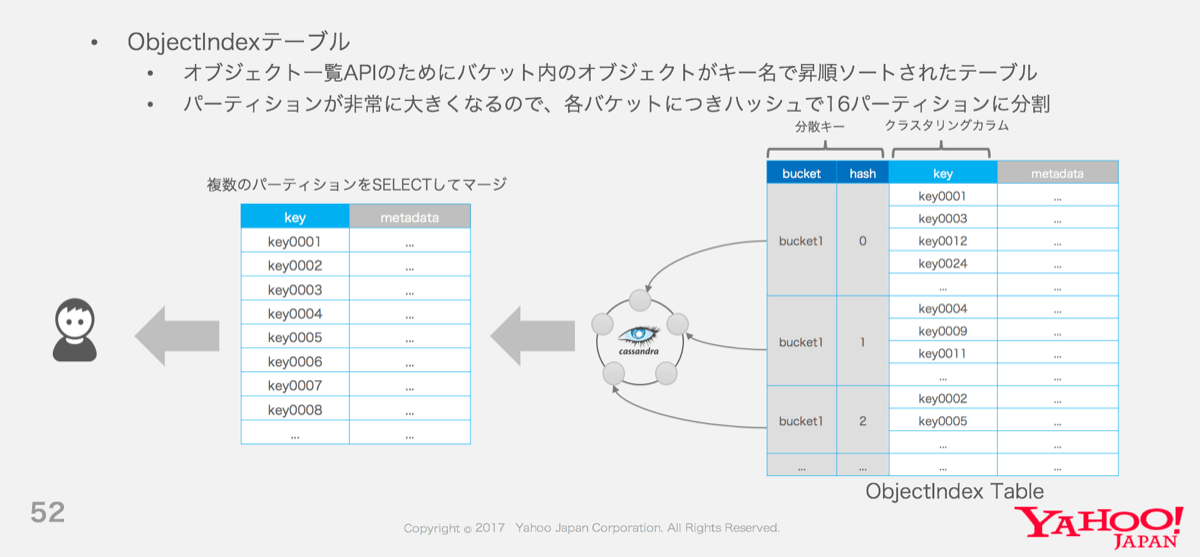
このObjectIndexテーブルはバケット内のオブジェクト数が増えるとそのパーティションが肥大化してロードバランス上の問題があるため、現在はさらにハッシュで16分割し参照時にマージするように対処しています。しかし、この方法ではCassandraへのクエリ数が増加しレイテンシが悪化する点や、Cassandra のパーティションサイズ制約によりバケットあたりのオブジェクト数が制限されてしまうという点に課題が残っています。これらの課題については、現在パーティションの動的シャーディングなどの工夫での解決を検討中です。
今後
Dragonは、ヤフー・ジャパンにおけるスケーラビリティの問題を解決するために設計されました。既存の手法の良いところを組み合わせ、また使える既存の実装を利用しながら、ある種分かりやすい、堅実な設計に落とし込めたのではないかと考えています。とはいえ、取り組むべき課題はまだたくさんあります。
- Multipart Upload機能やPolicyなどのS3 API実装
- オブジェクト一覧APIの性能を改善するためのデータモデル改善
- より最適化されたストレージエンジンの開発
- 社内MQサービスと連携したサーバーレスアーキテクチャの構築
- HadoopやPrestoなどデータミドルウェアとのインテグレーション
Dragonチームではこれらの課題に積極的に取り組んでいきます。
ヤフー・ジャパンでは、高度化する技術ニーズに対応するため、分散ストレージやDBの技術開発に積極的に取り組んでおり、この分野で活躍したいエンジニアを募集しています。巨大なスケールとトラフィックから日々発生する課題に向き合いながらインフラミドルウェアを運用・開発できる楽しい環境ですので、ぜひご応募ください。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました



