こんにちは。前回のHadoopの記事では、HadoopやMapReduceについての概要を説明しましたが、
今回は一歩踏み込んで、Hadoopの使いこなし方について書きたいと思います。
今回は、ある程度Hadoopを使ったことのある方、Hadoopのインストールをして、
オフィシャルページのMapReduceチュートリアルなどを試してみた方を対象としています。
こちらでオフィシャルページの日本語訳もされていますので、試していない方は一度試してみることをおすすめします。
前回の記事では、map関数とreduce関数と、その組み合わせが、MapReduceの肝だという話をしましたが、
ある程度複雑な処理を行う場合は、map関数とreduce関数だけでなく、それ以外のポイントをどうカスタマイズするかも重要になってきます。
まず、MapReduceの詳細なフローを紹介した上で、カスタマイズできるポイントを紹介、最後に実例を紹介していきたいと思っています。
MapReduceの詳細なフロー
では、MapReduceの詳細なフローを見ていきましょう。
なお、カスタマイズポイントを紹介するための説明ですので、詳細な部分は省いています。
まずはMap処理です。
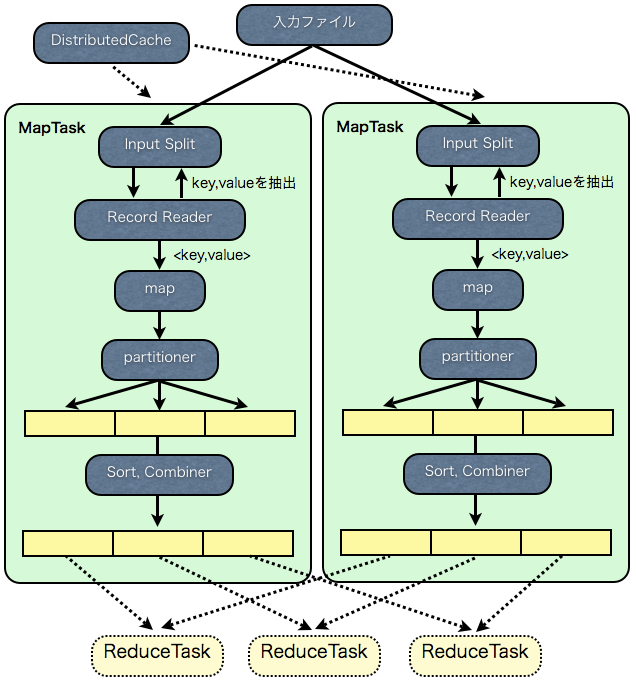
入力ファイルは、InputSplitと呼ばれる単位に分割され(
1
)、多くのマシンに分散されます。
一つのInputSplitごとに一つのMapTaskが割り当てられます。MapTaskとはMap処理を実行する単位のことで、多くのマシン上でMapTaskが並列に動くことになります。
MapTaskでは、InputSplitを読み込み、ユーザが定義したMapper(Map処理)を実行(
2
)します。
RecordReaderを使って、InputSplitからKeyとValueを抽出(
3
)し、map関数に引数として渡します。
map関数の出力は、PartitionerによりPartitionに分割(
4
)され、それぞれが次に処理されるReduceTaskに割り当てられます。
デフォルトのPartitionerでは、Keyのハッシュ値をもとに分割されます。
最後に各Partitionごとにソート( 5 )が行われます。そして、MapTaskが実行されているマシンのローカルのディスクに書き出され、ReduceTaskからコピーされるのを待ちます。
なお、オプションでDistributedCacheと、Combinerを指定できます。
DistributedCache(
6
)は、Taskが実行される前に、処理に必要なファイルを各マシンにコピーします。
ファイルは、Mapper, Reducerで自由に利用することができます。
Combiner(
7
)は、Mapperの出力をさらに集計します。Combinerの新たな出力が、MapTaskの出力として書き出され、ReduceTaskからコピーされます。
いわば、ミニReducerと呼べるものですが、MapperとReducerの間に入り、MapTask内で行われる点が、Reducerとは異なります。(次回の記事で詳しく解説します)
では、ReduceTaskの流れを見ていきましょう。
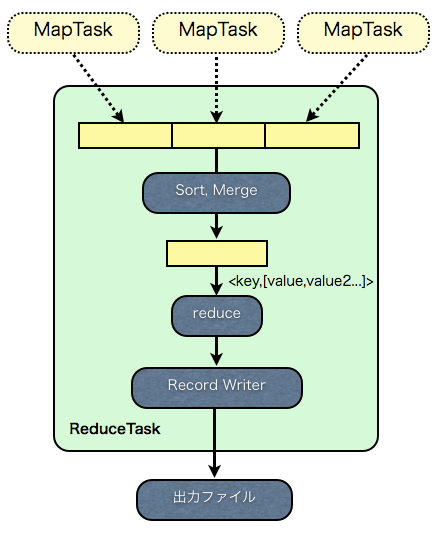
ReduceTaskでは、まず、各MapTaskが走っているマシンから、自分に割り当てられたPartitionのファイルをコピーします。
コピーは終了したMapTaskから順に行われます。
次に、ソート( 8 )が行われ、ファイルがまとめられます。
最後にユーザが定義したReducerを実行(
9
)します。
Valueをグルーピング(
10
)し、Keyとともにreduce関数に引数として渡します。
reduce関数の出力は、RecordWriterによって書き込まれ( 11 )、MapReduceの出力となります。
では、これらのフローの中で、カスタマイズできるポイントを紹介しましょう。
カスタマイズできるポイント
フロー中の処理と、カスタマイズするポイントの対応表は以下の通りです。
カスタマイズポイントに書かれたクラスをカスタマイズして、MapReduceの初期化時にJobConfなどで指定します。
文中の番号 処理の説明 カスタマイズポイント 1 入力ファイルをInputSplitに分割 InputFormatクラスのgetSplit関数 2 Map処理 Mapperクラス及び、MapRunnerクラス 3 InputSplitからKey/Value抽出 InputFormatクラスのgetRecordReader関数で任意のRecordReaderクラスを生成 4 Partitionの分割処理 Partitionerクラス 5 MapTaskでのソート Comparatorクラス 6 DistributedCache DistributedCacheのstaticメソッドで設定 7 Combiner Combinerクラス 8 ReduceTaskでのソート Comparatorクラス 9 Reduce処理 Reducerクラス 10 Valueのグルーピング Comparatorクラス 11 出力の書き出し OutputFormatクラスのgetRecordWriter関数で任意のRecordWriterクラスを生成
まず、 1 の入力ファイルを分割する方法は、InputFormatクラスの、getSplits関数を上書きすることで、カスタマイズできます。
また、
3
のInputSplitから、KeyとValueを抽出する処理も、InputFormatクラスを通じてカスタマイズできます。
InputFormatのgetRecordReader関数を通じて、RecordReaderクラスを生成するのですが、これに任意のRecordReaderクラスを指定すればOKです。
2
のMap処理ですが、ユーザが指定したMapperクラスの処理を実行します。
Mapperクラスは、MapRunnerクラスを通じて、初期化処理、map関数を繰り返す過程、終了処理といった一連の流れを実行します。
MapRunnerクラスをカスタマイズすれば、こうした流れを制御することができます。
0.20.0からの新しいMapReduce APIでは、Mapperクラス自体のrun関数で、流れを制御できます。
4 のPartitionの分割処理は、Partitionerクラスを指定することでカスタマイズできます。
6
のDistributedCacheは、MapReduceの初期化時にDistributedCacheのstaticメソッドを通じて、配布したいファイルを指定します。
7
のCombinerは、Combinerクラスを指定することでカスタマイズできます。
5
と
8
のソートで、Keyを比較する方法は、Comparatorクラスを指定することでカスタマイズできます。
10
のValueのグルーピングもComparatorクラスによってカスタマイズできますが、ソートの比較に用いるクラスとは別のクラスを指定できます。
9
のReduce処理ですが、ユーザが指定したReducerクラスの処理を実行します。
新しいAPIでは、初期化処理、reduce関数を繰り返す過程、終了処理といった流れを、Reducerクラスのrun関数を通じて行えます。
11
のReducerの出力の書き出しは、OutputFormatクラスを通じてカスタマイズできます。
OutputFormatのgetRecordWriter関数を通じて、RecordWriterクラスを生成するのですが、これに任意のRecordWriterクラスを指定すればOKです。
最後にフローには書いてはいませんが、MapperやReducerのKeyやValueに使われる、Writableクラスのカスタマイズも重要なポイントになってきます。
Writableクラスは、例えば、Textクラス、IntWritableクラスといったものです。
JobConfでのこれらのカスタマイズポイントの設定例をのせておきます。
JobConf job = new JobConf(Test.class); //JobConfを初期化
job.setInputFormat(CustomizeInputFormat.class); //InputFormatクラスを指定
job.setMapperClass(CustomizeMapper.class); //Mapperクラスを指定
job.setMapRunnerClass(CustomizeMapRunner.class); //MapRunnerクラスを指定
job.setPartitionerClass(CustomizePartitioner.class); //Partitionerクラスを指定
DistributedCache.addCacheFile(new Path("test.conf").toUri(), job); //DistributedCacheでファイルを配布
job.setCombinerClass(CustomizeCombiner.class) //Combinerクラスを指定
job.setOutputKeyComparatorClass(CustomizeComparator.class); //Keyの比較を行うComparatorクラスを指定
job.setOutputValueGroupingComparator(CustomizeGroupingComparator.class); //Valueのグルーピングを行うComparatorクラスを指定
job.setReducerClass(CustomizeReducer.class); //Reducerクラスを指定
job.setOutputFormat(CustomizeOutputFormat.class); //OutputFormatクラスを指定では、それぞれのカスタマイズポイントについて詳細にみていきましょう。
なお、MapReduce APIには、0.20.0からの新しいAPIと、従来のAPIがあります。
新しいAPIはまだ、MultipleInputsやMultipleOutputsに対応していないなど発展途上であり(0.20.1現在)、
オフィシャルページのMapReduceチュートリアルも従来のAPIで書かれていることから、特に断りのない場合は、従来のAPIで記述していますので、ご注意下さい。
InputFormat
InputFormatのインターフェースは以下のようになっています。
public interface InputFormat<K, V> {
InputSplit[] getSplits(JobConf job, int numSplits) throws IOException;
RecordReader<K, V> getRecordReader(InputSplit split,
JobConf job,
Reporter reporter) throws IOException;
}getSplitsが、入力するファイルを分割する方法を定義する関数で、InputSplitの配列を返します。
getRecordReaderは、InputSplitからKeyとValueを抽出する、RecordReaderクラスを返します。
RecordReaderのインターフェースは以下のようになっています。
public interface RecordReader<K, V> {
boolean next(K key, V value) throws IOException;
K createKey();
V createValue();
long getPos() throws IOException;
public void close() throws IOException;
float getProgress() throws IOException;
}おおまかな流れとしては、コンストラクタなどで、InputSplitを受け取り、createKey, createValueで、KeyとValueを初期化、
next関数を繰り返し呼んで、KeyとValueに値をセットしていきます。
例えば、Hadoop ArchivesがどうInputFormatをカスタマイズしているか見ていきましょう。
Hadoop Archivesは、小さなファイルなどをまとめて一つのファイルにでき、MapReduceの入力としても使える便利な機能ですが、
実際にファイルをまとめる処理はMapReduceで動いています。
Hadoop Archivesでは、MapReduce処理を行う前に、まず入力として受け取ったファイルのリストを書き出します。
SequenseFileという、MapReduceのKeyとValueをそのまま扱える形式で書き出され、
Keyが実際のファイルのサイズ、Valueがファイルへのパスなどになっています。
なお、実際にはValueはもっと複雑な形式になっていますが、説明のためファイルへのパスということにしておきます。
126787 /path/to/fileA
15666 /path/to/fileB
322137 /path/to/fileC
412738 /path/to/fileDMapperはこのファイルリストを入力とします。
map関数では、Valueにファイルのパスがセットされますが、ここからmap関数内で実際にファイルを読み出し、MapTaskごとにまとめて一つのファイルとして出力します。
しかし、デフォルトでは、ファイルリスト自体のサイズにもとづいて、InputSplitが分割されるので、Mapperでまとめたファイルの出力サイズに大きな差が出てきてしまいます。
そこで、HadoopArchivesでは、KeyのファイルサイズにもとづいてファイルリストをInputSplitに分割するという処理を行っています。
例えば、上の例のファイルリストを2つに分割したい場合、デフォルトだと、
126787 /path/to/fileA
15666 /path/to/fileB
---------------------
322137 /path/to/fileC
412738 /path/to/fileDというようにfileBとfileCの間で分割されますが、Hadoop Archievesでは、
126787 /path/to/fileA
15666 /path/to/fileB
322137 /path/to/fileC
---------------------
412738 /path/to/fileDというように、Keyのファイルサイズを読んで、ファイルサイズの合計がなるべく均等になるように、fileCとfileDの間で、分割します。
ちなみに、Reducerでは、Mapperでまとめたファイルにおける実際のファイルのインデックスなどの情報を書き出すようになっています。
なお、元から用意されているInputFormatでも、入力テキストを区切り文字でKeyとValueに分割して、Mapperの入力のKey/Valueとして扱えるKeyValueTextInputFormat,
小さいファイルをまとめて扱えるCombineFileInputFormatなど便利なものが多くありますので、調べてみてください。
直接は関係ありませんが、入力ファイルに応じて複数のMapperクラスやInputFormatを割り当てられる、MultipleInputsという仕組みもあります。
残りは次回
次回は、残りのカスタマイズポイントを解説します。
P.S.
GoogleがMapReduceの特許を取得したことには驚きました。
Hadoopに影響するのかどうか気になるところですね。
(R&D統括本部 吉田一星)
2010/03/01追記 Hadoopを使いこなす(2)2010/05/27追記 Hadoopを使いこなす(3)



