こんにちは。ABYSS開発チームの前田です。今回は前回に続いて、ABYSSについて、ご紹介します!
皆様、前回のABYSSの記事を読んでくださいましてありがとうございます。今回は主に、ABYSS内部のコンポーネントについてより詳しく説明して行きます。
ところで先日、ABYSSのロゴが完成しました!
現在チーム内ではリリースに向けて、ラストスパートを駆けています。ロゴが完成したこともあり、ABYSSチームではリリースに向けてモチベーションもますます上がる一方となりました。ここまで来たら、もはやチームのモチベーションも計り知れません!
しかし、諸事情により皆さんにロゴをお見せできないのが本当に残念ですʅ( ‾⊖◝)ʃ
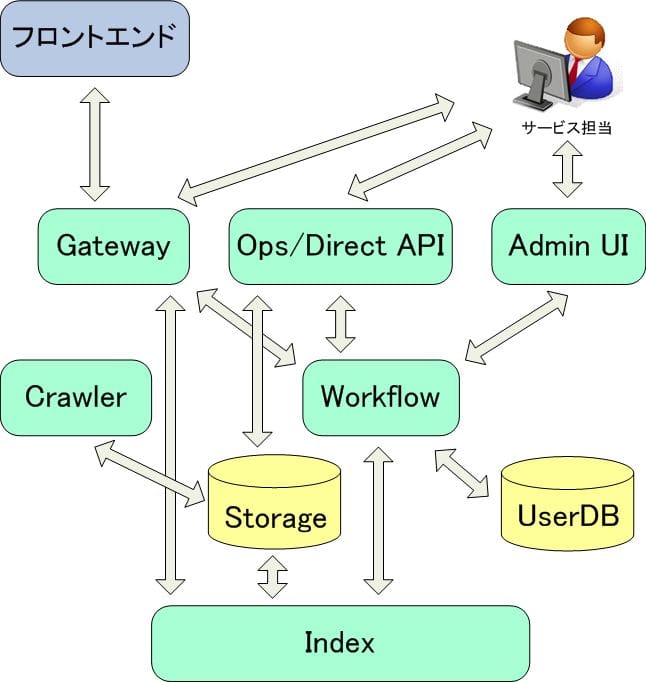
さて、ABYSSの主要コンポーンネントについて詳しく見ていきたいと思います。まず、簡単にABYSSの特徴についてもう一度まとめてみますと、
- 利用者は検索エンジンのためのサーバーを用意する必要がない。
- WebAPIからの操作で簡単に検索エンジンを構築できる。
などがあります。そのほかに独自にランキングの重み付けができたり、また各設定をいじるだけで検索エンジンのチューニングを行うことができ、ABYSSを利用することで簡単に検索システムを構築することが可能となります。
全体の概要については前回の記事を参考にしていただければと思います。
ではABYSSを利用する流れを簡単に説明します。
以下に各コンポーネントで行われる処理についてまとめました。
- Gateway
フロントエンドからの検索APIのエントリーポイントとしてリクエストを受け付けます。そしてACLチェックを行ったり、フロントエンドからのクエリをIndexに対して実行し、検索結果を返す機能を提供します。
- AdminUI
検索の設定や管理を行うウェブインターフェースの管理ページを提供しています。利用者はウェブからこの管理ページにアクセスして各種設定を行います。
- Ops/DirectAPI
全件更新、差分更新はOpsAPIで行われ、DirectAPIでは1件づつリアルタイムにインデックス更新が行われます。インデックス更新時にはHadoop上で更新処理が行われ、インデックスに反映します。また、各設定ファイルなどはOpsAPIを経由してアップロードされます。
- WorkFlow
ABYSSのほとんどの処理はこのWorkFlowを経由して行われます。主な機能として、Indexサーバーの各種情報(空き容量、空きサーバーなど)取得、Indexサーバーへの処理依頼、Hadoopからの情報取得、UserDBのデータ更新などがあります。ほかにもWorkFlowではさまざまな処理を行っていて、各コンポーネントの状態を制御、管理を行っています。
- UserDB
ABYSSで利用される各種情報や状態を管理します。
- Storage
StorageではHadoopを利用しています。
インデックス用の生データ、差分用ファイル、クロールからのデータなどをここに保存され、検索インデックス用のデータを作成します。主に、各バッチ処理を行ったり、ランキング処理やログ解析などのさまざまな処理が行われます。 - Clawler
クローラは利用者から自由に各設定を行う事ができ、ウェブ上のコンテンツを収集し、Indexを作成するためのデータを Storage(Hadoop) へ送ります。また、インデックス用データだけではなくランキング組成やログ解析に必要なデータもクローラから Storage(Hadoop) へデータを送ります。 - Index
複数のインデックスをサポートするインデックスクラスタです。Yahoo! JAPANで作られ、実績のある検索エンジンをベースに作られています。高速、高精度な日本語全文検索エンジンです。大規模な検索処理が実行できるように実装されています。また、今回大幅にバージョンアップを行っております。
まず、検索エンジンのインデックスを作成するために、以下のような設定ファイルをABYSSにアップロードします。これらは AdminUI と呼ばれている管理画面を通じてウェブ上から行う事ができます。また各設定ファイルは OpsAPI を通して Storage へと送られます。
インデックスファイルとはインデックスの各フィールドがどのようなインデックスの構造なのか(形態素解析,Ngramなのか?)を記述したりなど、インデックスの構造に対してさまざまな設定を記述したXMLファイルをイメージしてください。またクエリ設定ファイルとは検索時にどのような形で検索結果を表示するかなどの検索時に使われる設定ファイルをイメージしてください。
- XML形式のインデックスの設定やクエリ設定ファイル
- 検索用データファイル
- 検索結果用のテンプレートファイル
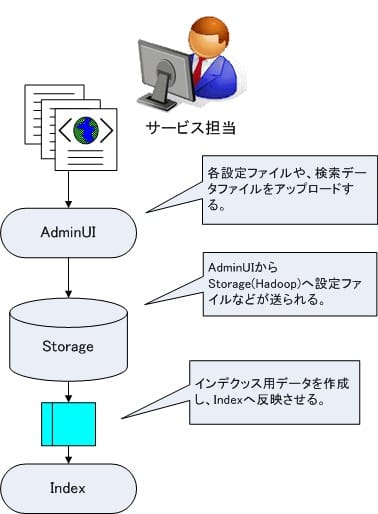
これらのファイルをアップロードし、初期設定をした後に、検索の初期インデックスを作成します。その後のインデックス更新処理には全件更新、差分更新、リアルタイム更新などがあります。これらの更新処理は Ops/DirectAPI を経由して行われます。
検索クエリの実行では Gateway を介してクエリの実行、結果取得をしフロントエンドへ返します。
さて、ここまで各コンポーネントについて説明しましたが、クローラはどこでどうつかうの?? と思われた方もいると思います。上のABYSSの利用の流れでは主に社内の各サービスが利用することを想定した説明となっていまして、実は初期のABYSSではクローラの機能は入っていません。
しかし、これから社内の各サービスでもクローラを利用したABYSSの利用の話などもありますし今後、外部にABYSSを公開するとなれば当然クローラの機能も必要となってきますので現在ABYSS用の大規模クローラの開発を着々と進めております。実は私はABYSSクローラの開発を担当しており、今後クローラ部分の紹介も出来ればと思っています。
前回もお話したように、ABYSSはあくまでも社内のプラットフォームの技術であるため、皆さんが直接ABYSSの恩恵を受けるわけではありません。
とはいえ、開発に役に立ちそうな各コンポーネント特有の技術の解説など今後、コンポーネント別に詳しく技術解説や役立つトピックスについて解説できればと思います。
今後も新検索プラットフォームABYSSをよろしくお願いします!
(R&D統括本部 前田英行)
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました



