
写真:アフロ
データ&サイエンスソリューション統括本部、データインフラ本部、今野です。
早速ですが、今月開催の「Developers Summit 2016 (以下、デブサミ2016)」で当方が登壇する運びとなりました。気がつけば、前回の記事「分散システム処理モデルに関する動向について」から随分と日がたってしまいましたので、今回は、より広範囲な内容を整理してみたいと思います。
デブサミ2016の当方の講演テーマは「温故知新」です。今回は、このテーマにもつながる話題として、クラウド環境の代表的な分散プログラミングモデルやデザインパターンについて、一般的な考察をしてみたいと思います。
古典的なプログラミングモデルによる分類
まず最初に、クラウド環境のプログラミングモデルを、フリンの分類[1]に従って整理してみたいと思います。フリンの分類は、今となっては多少古典的で、コンピューターアーキテクチャによる大ざっぱな分類方法ですが、クラウド環境を取り巻く状況を説明するには、現状でも有用な方法と思っています。
フリンの分類では、コンピューターアーキテクチャを処理する命令(Instruction)とデータ(Data)の並列度から分類するものです。結果として、フリンの分類では命令とデータ種類の組み合わせにより、以下の4種類(SISD, SIMD, MISD, MIMD)に分類されます。
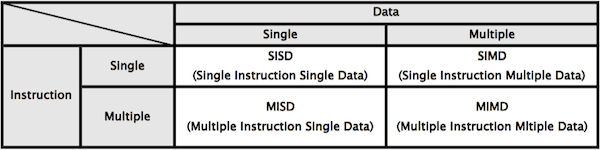
SISDは典型的なフォンノイマン型コンピューターで、一昔前の一般的なシングルプロセッサーのコンピューターが該当します。MISDは、単一のデータに異なる処理を命令する特殊な形式で、商用的に成功するコンピューターの実現までには至りませんでした。
残りのSIMDとMIMDについては現時点もで有用なコンピューターアーキテクチャで、現在のクラウド環境にも深い関係があります。
SIMD (Single Instruction Multiple Data)
SIMDは、単一の命令で複数のデータを処理する形式のものです。古くはIntelのMMXやSSE(Streaming SIMD Extensions)、近年のGPU(Graphics Processing Unit)もSIMDのコンセプトに影響を受けたものです。単一命令でのデータ加算処理を例にとり、SIMDとの比較を以下に示します。
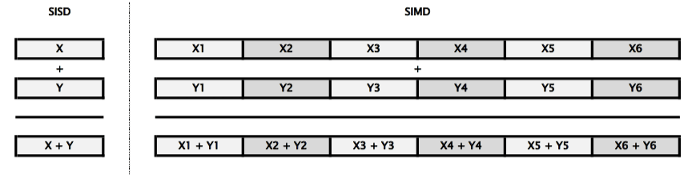
上記は、SISDでは1つの加算命令で1組の演算のみの実行ですが、SIMDでは1つの加算命令で同時に6組の加算演算を実行している例です。
SIMDは、コンピューターグラフィックスや機械学習などで多用される行列演算など、実行順序などの相互依存性がない(並列度が高い)データ並列処理とは非常に相性の良いコンピューターアーキテクチャです。
MIMD (Multiple Instruction Multiple Data)
MIMDは、SIMDをより柔軟にした最も汎用的なコンピューターアーキテクチャで、複数の命令で複数のデータを処理する形式のものです。
結論としては、現在のクラウド環境のサーバーで用いられるマルチプロセッサーや、複数のコンピューターから構成されるクラウド環境は、このMIMDアークテクチャーに分類されます。以下に、MIMDで複数命令で複数データを演算する例を示します。
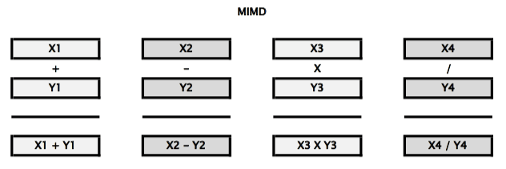
上記は、4つの命令(加算、減算、乗算、除算)と4組の演算を同時に実行している例です。
MIMDは、コンピューターアーキテクチャとしては各処理単位ごとに独立した処理ユニットとデータ処理用の(レジスタを含む)メモリを持つ形式です。結果的に、各処理単位でデータ処理が独立し結果が出力されるため、複数の処理単位が協調して目的を達成するには、何らかのデータ処理結果の共有方法が必要です。
MIMDのプログラミングモデルの分類
近年のクラウド環境は、フリンの分類上、MIMDモデルに分類されます。分散システムでは、フリンの分類の処理ユニットである命令はプロセスに相当し、クラウド環境でのプロセスはクラウドを構成するサーバーに相当します。
厳密には、クラウド環境を構成するサーバーは、マルチプロセッサーやマルチコアは内部的にもMIMDですし、最近のプロセッサやGPUなどの拡張ボードでも何かしらのSIMDに対応しています。そのため、厳密な分類では、現状のクラウド環境はMIMDおよびSIMDのハイブリッドなアーキテクチャですが、今回の記事の流れから、SIMD動向については割愛してMIMDを中心に話を進めています。
分散システムの目的
分散システムの目標は、各プロセスが協調して目的を達成する事です。MIMDモデルで協調して1つの目的を達成するには、各プロセスの処理状態や処理結果を、他のプロセスと共有する必要があります。
フリンの分類は命令とデータに注目した分類方法でしたが、MIMDモデルをさらに細分化する方法としてメモリ形式による分類があります。MIMDプラグラミングモデルをメモリ形式から分類すると、「共有メモリを持つ」か「共有メモリを持たない」かに大別されます。
分散共有メモリモデル
共有メモリモデルは、各プロセスが共通に参照できるメモリが存在するモデルです。各プロセスがデータを共有するには、この共有メモリを利用します。クラウド環境サーバーで用いられるマルチプロセッサは一般的にはこの形式で、複数のプロセッサに1つの共有メモリが存在しています。
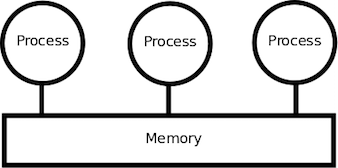
共有メモリを細分化すると、物理的か論理的かに大別されます。物理的な代表例としては前述のマルチプロセッサや並列コンピューターで用いられる対称形のUMA(Uniform Memory Architecture)や、非対称形のNUMA(Non-Uniform Memory Access)などの分類があります。
論理的なものは、物理的な共有メモリを持たずに仮想的な分散共有メモリが実現されているもので、オペレーテシングシステムやミドルウェアの機能として提供されています。クラウド環境では、一般的にミドルウェアとして論理的な分散共有メモリが提供される形式です。
また、クラウド環境で利用されるリレーショナルやNoSQLデータベースは(原子性や一貫性の程度などの差異ありますが)論理的な分散共有メモリと見なすことができます。また、後述するZooKeeperなどの協調(Coordination)サービスも、機能的に共有メモリを提供している場合も多く見受けられます。
分散メモリモデル (メッセージ交換モデル)
分散メモリモデルは、各プロセスが共通に参照できるメモリが存在せず、各プロセスに個別のローカルメモリが存在するモデルです。各プロセスが他のプロセスとデータを共有するには、必然的に通信が発生するためにメッセージ交換モデルとも呼ばれます。
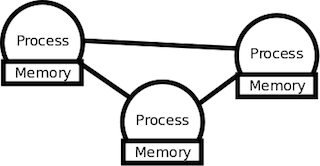
クラウド環境では、超並列コンピュータとは異なり、一般的には汎用的なコンピュータのサーバーから構成されます。その汎用的な数百から数千単位のサーバーをネットワークで接続することでクラスタを形成します。
クラウド環境では、超並列コンピュータのように物理的な共有メモリモデルが存在しないため、このメッセージ交換モデル上に、分散アプリケーションを構築することになります。
クラウドのデザインパターンの分類
次に、クラウド環境で用いられるデザインパターンを紹介してみます。クラウド環境では、分散アプリケーションを構築するために、各種の分散フレームワークが存在します。
この分散フレームワークは、クラスタのノード間の協調やリソース管理などを目的とする比較的低位レイヤを対象とするもの、Hadoopなどのアプリケーションを記述するための高位レイヤの対象とするものに大別できます。
今回は、これらの分散フレームワークで用いられているデザインパターン中から、代表的なもの幾つか紹介してみたいと思います。
マスタ・ワーカー (Master Worker)パターン
マスタ・ワーカーモデルはマスタ・スレーブ(Master Slave)モデルとも呼ばれ、一つのマスタがプログラムの実行を管理し、そのプログラム全体や一部の処理の実行をワーカーに割り当てるパターンです。
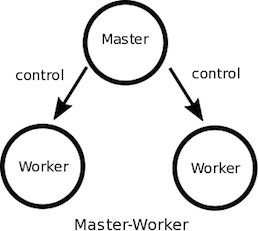
マスタ・ワーカーモデルは、インターネット環境で多用されるクライアント・サーバー(Client Server)モデルとは対照的に、反対にマスタ側からワーカーへ処理を割り当てるものです。クラウド環境では、Apache MesosやYARNがその代表例で、並列処理タスクの割り当てにマスタ・ワーカーパターンを用いています。
プロデューサ・コンシューマ (Producer Consumer)パターン
プロデューサ・コンシューマパターンは、各プロセスが対等な役割を持つタスクプール(Task Pool)パターンとは異なり、プロセスの役割をデータを登録(生産)するものと処理(消費)するものに区別しているパターンです。
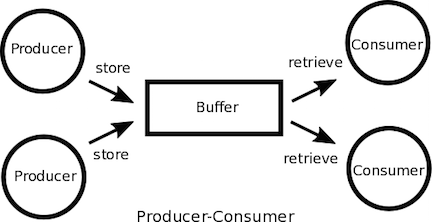
一般的な実装では、プロデューサーとコンシューマの間には仲介する有限のバッファが存在するため間接的に通信となり、両者間で非同期な通信となります。ます。この有限バッファがのデータ構造がキューである場合には、メッセージキュー(Message Queue)パターンとなります。
また、コンシューマーかプロデューサーからの登録データを受信する方法としては、同期ブロック、非同期ループ、通知などの方式などがあります。この中で、受信方法が通知方式となり、コンシューマ側で通知のフィルタ設定ができる場合には、出版購読(Publish-Subscribe)パターンとなります。
データフロー(Dataflow)パターン
データフローパターンは、データを処理するノードを点(Vertex)、処理対象のデータを辺(Edge)とするグラフ構造をもつパターンです。辺には方向があり(有向)で、各ノードは入力辺からのデータを処理し、その結果を別の辺に出力します。
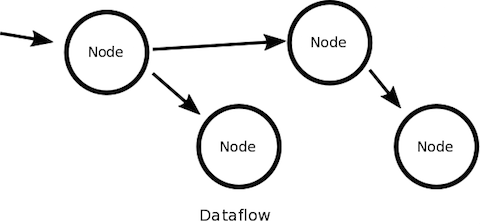
このデータフローパターンは、近年クラウド環境で閉路を含まない有向非巡回グラフ(DAG:Directed Acyclic Graph)タイプのものが多用されています。MapReduceもその代表例で、各ノードの入出力を1つに制限するなど、有向非巡回グラフをさらに単純化したパターンと言えます。
有向非巡回グラフには、閉路があるとグラフ構造的に無限ループが発生するため停止性の保証問題や、巡回による再帰処理による参照透過性の問題など、並列実行の諸問題を考慮しなくても良い利点があります。
クラウドのプログラミングモデルの分類
最後に、近年のクラウド環境で用いられるフレームワークを、前述のMIMDモデルの共有メモリモデルの有無と、デザインパターンを組み合わせて分類してみたいと思います。
クラウド分散フレームワークのレイヤ
前述のように、近年のクラウド環境の分散アプリケーション構築に用いられる分散フレームワークは、機能的な低位レイヤのものから、抽象度の高いレイヤのものなど多種多様なものがあります。今回は、便宜上この分散フレームワークのレイヤを以下のように3種類に分類してみます。
- 協調(Coordination)タイプ
- リソース管理(Resource Management)タイプ
- アプリケーション(Application)タイプ
協調(Coordination)タイプは各ノードの協調作業向け、リソース管理(Resource Management)サポートする比較的低位レイヤの対象としているフレームワークとします。
アプリケーション(Application)は、各々のプログラミングモデルで分散サプリケーションを記述する高位レイヤを対象とするフレームワークとして区分しています。
クラウド分散フレームワークの分類
近年のクラウド環境で主要な分散フレームワークを、利用者視点で明示的に公開されている仕様から整理してみます。前述の分散フレームワークレイヤ、MIMDモデルの共有メモリモデルの有無、デザインパターンを組み合わせて分類してみると以下のような表となります( *1)。
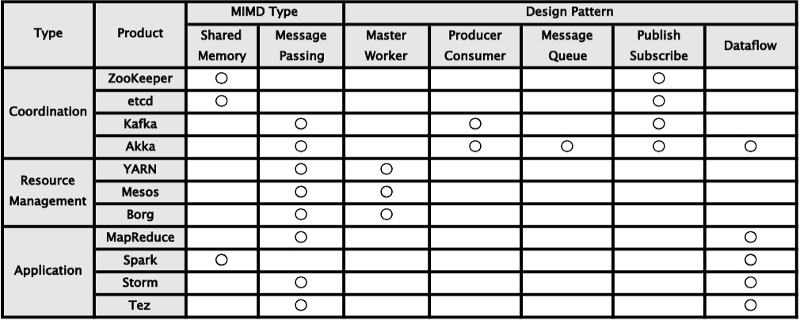
今回は代表的な分散フレームワークを選んでみましたが、MIMDタイプの分散共有メモリの有無は各フレームワークの特性で選択されています。また、デザインパターンについては協調やリソース管理の低位レイヤのものは機能的、アプリケーションの高位レイヤは抽象度の高いものが選択されている傾向が見受けられます。
また補足をすれば、アプリケーションレイヤより高位レイヤは、より抽象度が高いドメイン特化言語(DSL:Domain Specific Language)などが用いられるレイヤとなります。代表的なものはSQLですが、近年ではGoogle Dataflowなどのデータフロー分野の標準化は近年の特記すべき動向かと思います[2]。
(*1) 本分類は、利用者視点からの分類であり、実装上の非公開な部分などは除外したものです。例えば、Hadoopのタスク管理はマスターワーカータイプですし、リソース管理レイヤのものは共有メモリタイプの協調フレームワークを実装に用いているなどの背景はありますが、本分類では割愛している点を補足しておきます。
最後に
MIMDモデルの背景には何があるのか?
近年のMIMDモデルの隆盛には、2003年以降のクロック数の固定化傾向およびマルチプロセッサ化の背景もあります[3]。ムーアの法則が有効なだった2003年頃までは、プロセッサのクロック数で年間40%程度の性能向上が実現されていました。
逆に言えば、ムーアの法則が有効だった1990年代から2000年代前半には、MIMDモデルによる並行性は、性能面での貢献はそれほど優先度が高い問題ではありませんでした。むしろ、その当時は、GUI(Graphical User Interface)の急速な普及に伴い、特にデータフロー系は性能面よりもビジュアル言語としての活用が模索されていた時代でもありました。
再び脚光を浴びる並行性
しかし、2005年からプロセッサの性能向上の鈍化は顕著になり、近年のクラウドコンピューティングの普及と相重なり、MIMDモデルの並行性は再び重要度を増しています。
今から40年前、1970年代はプログラミングモデル的なデータフロー系の研究が活発な時代でした[4]。ちょっと年配の方であれば、トランスピュータを覚えてるのではないでしょうか?
インモス社のトランスピュータは残念ながら商業的には成功しませんでしたが、その理論であるCSP(Communicating Sequential Processes)[5]は、おそらくデータフロー系では最も広範囲に利用されている理論で、近年流行しているGo, Haskell, Clojureなどのプログラミング言語にも影響を与えています。
また、同年代のアクターモデル(Actor Model)[6]やFBP(Flow Based Programming)[7]も同様に多方面のプログラミング言語やミドルウェアの影響を与えています。
今後はどうなる?
今月、登壇予定のデブサミ2016では、今回の記事につながる話題を「温故知新」的な観点で、クラウド環境の分散システムを俯瞰した内容の講演を予定しております。
その他、デブサミ2016には弊社のエキスパートが登壇いたします。もし、本内容も含めてご興味がありましたら、ぜひ会場まで足をお運びください。
よろしくお願いします。
参考資料
- [1] Flynn, M., Some Computer Organizations and Their Effectiveness, 1972
- [2] Publickey, GoogleがClouderaらと共同で「Google Cloud Dataflow」のオープンソース化提案。Apache Incubatorプロジェクトとして, 2016
- [3] J. Held, J. Bautista, and S. Koehl. “From a few core to many: A tera- scale computing research overview.” 2006
- [4] Jack B. Dennis, First Version of a Data Flow Procedure Language, 1974
- [5] Joare, C.A.R., Communicating sequential processes, 1978
- [6] Carl Hewitt Peter Bishop
Richard Steige, A Universal Modular Actor Formalism for Artificial Intelligence, 1978 - [7] Flow-Based Programming: A New Approach to Application Development
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました



