本記事では最初にYahoo! JAPANでApache Hadoop(以下Hadoop)コミッタが普段どのような活動をしているか紹介します。また、1月末にシリコンバレーで開催されたApache Hadoop Contributors Meetupに参加してきたので、meetupで発表があった新機能のうち特に注目している機能を2件紹介します。本記事は前編と後編に分かれており、データプラットフォーム本部でHadoopコミッタとして活動している鯵坂(@ajis_ka)が前編を担当します。
Hadoopコミッタの活動
社内での活動
Yahoo! JAPANでは、自社が提供している多種多様なサービスのログを分析してサービスの強化に役立てるため、1000台/数10PB規模のHadoopクラスタを複数運用しています。定常運用および運用改善に関する業務はDevOpsチームが担当しているのですが、これらのクラスタで複雑なトラブルが発生したときのソースコードの解析や、トラブル解決のためにパッチを作成・適用する業務を私たちが担当しています。また、今後もHadoopクラスタで蓄積・処理するデータ量は増え続けていく傾向にあります。そのため、Hadoopの新機能のうちスケーラビリティをより高めるための機能の調査・検証を実施しています。Yahoo! JAPANではHDFSの新機能であるRouter-based Federation(以下、RBF)の利用を検討しており、現在はその調査・検証に注力しています。
社外での活動
Hadoopコミュニティーに日々投稿されるパッチのレビューを実施することはもちろん、RBFの検証結果のフィードバックとしてバグ修正や機能改善のパッチを投稿するほか、Javaのバージョンアップについても重要課題だと意識して取り組んでいます。現在Javaの最新バージョンは11ですが、Hadoopで現在対応しているバージョンは8です。Java11では一部のパッケージの削除・移動などの非互換な変更が多数あるため、ビルドを通すためだけでも50以上の修正が必要でした。また、Hadoopが利用しているJavaのライブラリも11対応のものに上げる必要があるため、結局のところHadoopのほぼ全てのコンポーネントでソースコードを修正する必要があります。このようにJava11対応は非常に手数がかかって大変な作業なのですが、HadoopのJava11対応が進まないとHadoopに依存するプロジェクト(例:Apache Hive, Apache Spark)のJava11対応も進まないため注力して取り組んでいます。Java11へのバージョンアップを完了し、Java9で新たに導入されたProject Jigsawに対応させることで、Hadoopが依存する大量のライブラリによってもたらされた複雑な依存関係(jar hell, もしくはdependency hellと呼ばれる)を解消して利用者にとってHadoopをさらに使いやすくしていきたいと考えています。
また、ソースコードを修正する以外でもHadoopコミュニティー内外でさまざまな活動を実施しています。これまでに以下の活動を実施してきました。
- Hadoop 2.9.2のリリースマネージャを担当 (関連記事:Hadoop 2.9.2をリリースした話)
- CVE(Common Vulnerabilities and Exposures)のアナウンス(CVE-2018-1296, CVE-2018-11766, CVE-2018-8009)
- db tech showcase Tokyo 2018 での発表: Apache Hadoop HDFSの最新機能の紹介(2018)
- TechBlogの執筆: HDFS Erasure Codingの紹介とYahoo! JAPANにおける運用事例
Apache Hadoop Contributors Meetupについて
Apache Hadoop Contributors Meetupは、Hadoopの開発者が集まって自ら開発している機能について紹介し合うイベントです。今回は100人以上の登録があり、50人を超える開発者が集まりました。参加者のうちHadoopのコミッタが半数以上を占め、世界で最も多くHadoopコミッタが集まるイベントとなっています。シリコンバレーで不定期に開催されており、前回から4カ月ぶりの開催です。
Meetupの資料は後からSlideShareなどで公開されますが、今回発表があったRBFについてスライドで公開されない生の情報を現地で直接開発者から仕入れるため、また、直接RBFの開発者と会って顔なじみとなることで今後のコミュニティーでの開発をスムーズに進められるようにするため1、シリコンバレーに出張することに決めました。本Meetupは不定期開催のため急な出張費の申請が難しいところでしたが、OSSデベロッパー活動費を使うことで参加することができました。OSSデベロッパー認定制度については昨日の記事(ヤフーにおけるOSS開発・貢献がどのように行われているか)にて紹介されていますが、この制度には非常に感謝しています。
本Meetupのアジェンダは以下の通りで、Hadoopの最新機能の紹介と今後の開発方針に関するディスカッションが行われました。
- TensorFlow on YARN and Beyond(LinkedIn)
- HDFS Encryption(File & Column)and the Key Management Service (Cloudera, Uber)
- HDFS Scalability & Consistent Reads from an Observer NameNode (LinkedIn)
- Router-based Federation & HDFS Tiered Storage (Uber)
- HDDS and Ozone (Cloudera)
- Dynamometer and a Case Study in NameNode GC (LinkedIn)
- Hadoop on Azure (Microsoft)
- Mounting Remote Stores in HDFS (Microsoft)
Breakout Sessions(Discussion):
- Treatment of Java versioning
- The right way to handle RPC Encryption
- Discussion of community support for a 2.10 bridge release
- The future of HDDS & Ozone
前編では、Yahoo! JAPANでも検証中のTensorFlow on YARN and Beyondのセッションについて紹介します。RBFのセッションについては後編で紹介します。
TonY: TensorFlow on YARN and Beyond
TonYの開発者であるLinkedInのAnthony Hsu氏とJonathan Hung氏による発表で、発表資料はこちらです。
TonYとは
TonYは、LinkedInが開発しているDeep Learningのためのオープンソースの分散処理フレームワークです。TensorFlowをYARN上で動作させることからTonY(TensorFlow on YARN)と名付けられましたが、現在はYARN上でのPyTorchの実行もサポートしており、現在はRのサポートに向けた開発が進んでいます。
TonYが開発された経緯
LinkedInではすでに大規模なHadoopクラスタを運用しており、HDFS上のデータに対してHadoopクラスタ上でDeep Learning処理を分散実行しています。分析者は機械学習におけるフィードバックループを高速に回すためインタラクティブに開発を進める必要があり、そのためにLinkedInではJupyterを利用していました。しかしながら、セキュリティー上の制約でJupyterから直接HDFSにアクセスすることができず、Spark Jobを実行するためのREST APIを提供するApache Livy経由でTensorFlow inside Spark Jobという形でDeep Learning処理を分散実行していました。しかしながら、エラーが多発する、timeoutに引っかかってよくジョブが落ちる、そもそもSpark Jobという形で実行する必然性がない、という理由により根本的な改善が必要でした。

図1. 機械学習のための分散処理フレームワークの比較
そこで、オープンソースで利用できるものがないか調査しましたが、Hadoop上で動作しかつGPU isolationが可能なものがなかった(図1)ため、独自にフレームワークを開発しました。それがTonYです。TonYは2018年9月にBSD 2-Clauseライセンスでオープンソース化され2、自由に使えるようになっています。
TonYのアーキテクチャ
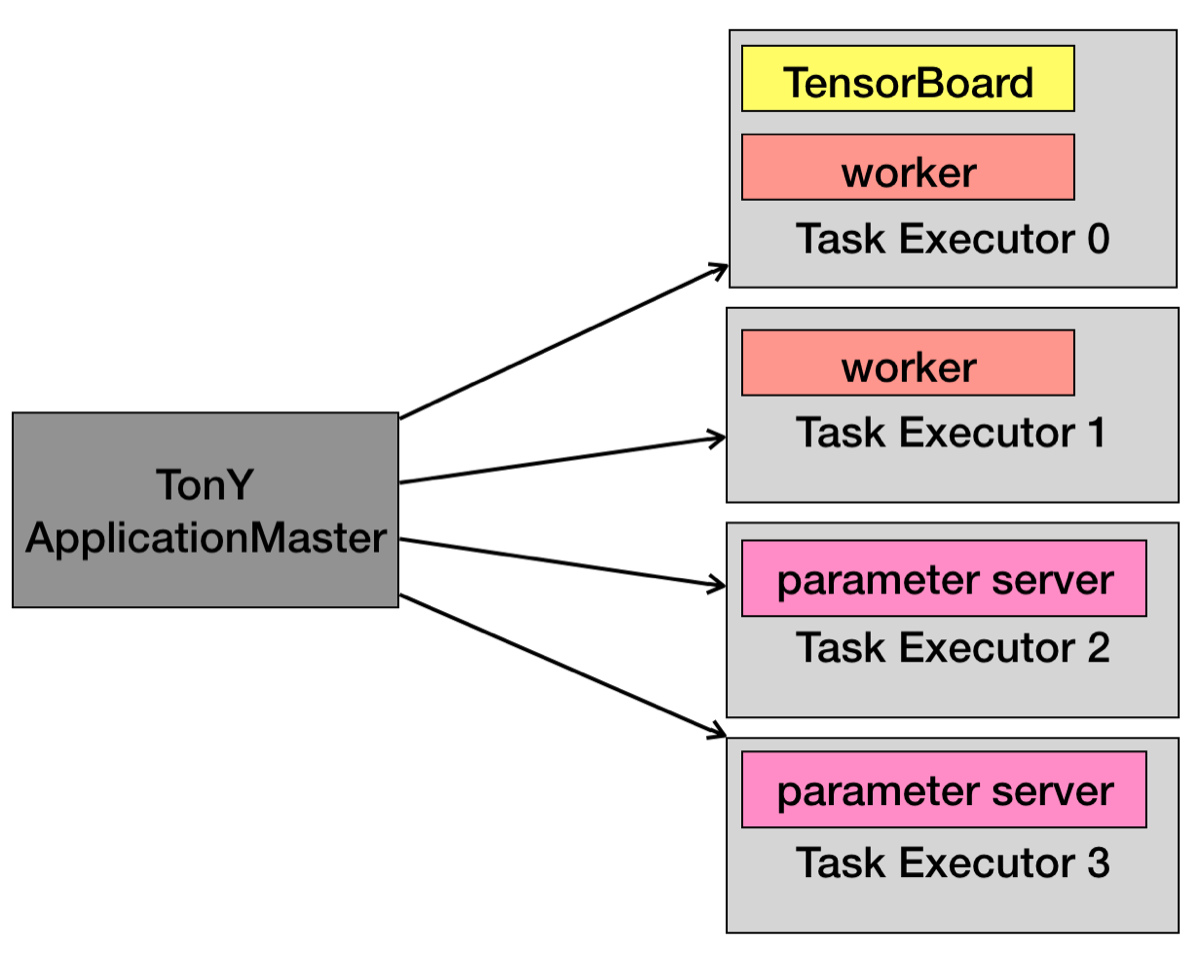
図2. TonYのアーキテクチャ
YARNのResourceManagerにTonY jobをsubmitすると、最初にTonY ApplicationMasterが起動します。TonY ApplicationMasterは必要な計算リソースをYARNから確保してもらい、確保されたリソースの範囲内で複数のTask Executorを起動します(図2)。そしてTask Executorはparameter serverやworkerを起動して、Distributed TensorFlow jobを実行します。ApplicationMasterが1つ、Task Executorが複数起動しているという構図は通常のYARN Applicationと同じです。ここで0番のTask ExecutorはTensorBoardを起動しており、TonY ApplicationMasterのウェブUIから1クリックでTensorBoardにリダイレクトするようになっています。この機能が実装されるまでユーザーは学習結果をローカルにコピーしてローカルでTensorBoardを起動していましたが、今ではそのような面倒な作業を実施する必要はありません。また、Hadoopのバージョン3.1以降ではGPUもまたCPUやメモリと同様に1つのリソースとして扱うことができます。実際に利用したGPUリソースがYARN経由で確保したリソースを上回らないようcgroupsで制御しており、これによってGPUのリソース競合が発生しないようになっています。
今後の展望
今後の展望として、以下の3点が挙げられていました:
- TonY jobのログを管理、閲覧するためのHistory Server
- TonY jobのメトリクスおよびDr. Elephantとの連携
- TonY runtime for{Submarine}
Dr. ElephantはLinkedInによって開発され、オープンソース化されたHadoop MapReduce jobとSpark jobのチューニングを支援するためのツールです。ジョブのメトリクスを収集・分析し、より効率的にジョブを実行するためのパラメータ設定をユーザーに提案できます。TonY jobにもメトリクスを実装しDr. Elephantにそのメトリクスを収集・分析させることで、YARNで確保したメモリやGPUのリソース量は適切かどうかといったTonY job自体のチューニングを効率化することが狙いです。また、LinkedIn出身のOSSとの連携という観点で見るとTonYはすでにAzkabanというワークフローマネージャにも対応しています。
{Submarine}はHadoopコミュニティーで開発されている、YARN上でDeep learning処理を分散実行するためのフレームワークです。{Submarine}はTonYと非常によく似ており、現地で直接{Submarine}の開発者に聞いても「TonYとあまり違いはないよ」という答えが返ってくるほどでした。本記事を執筆するにあたって両方のドキュメントを読んだのですが、本当にあまり違いがないように思えました。TonY側でも{Submarine}と連携させる仕組みが整っていく予定とあり、ユーザーはどちらを利用しても特に問題はないように見えますが、それゆえに、どちらを利用すべきか悩ましい状態になりそうです。今後の開発動向を注意深く追っていく必要があるように思えます。
最後に
浅沼さんが担当するApache Hadoop Contributors Meetup出張報告(後編)は、RBFに関する技術情報だけでなく、実際に海外の開発者に会ってみてもどうだったかについて執筆してくださっています。
- コミッタは誰からのパッチでもレビューすべきですが、心理的には全く知らない開発者からのパッチよりすでに知っている開発者からのパッチのほうがレビューしやすいところがあります。
- Open Sourcing TonY: Native Support of TensorFlow on Hadoop (LinkedIn Engineering)
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました



