はじめに
こんにちは。Yahoo! JAPANでHadoopに携わっているエンジニアの浅沼です。Hadoopは大量のデータを分散処理するためのオープンソースソフトウエアです。この夏にリリース予定のバージョン3.0系には、HDFSの新機能であるErasure Codingが導入されます。Yahoo! JAPANではHadoopコミュニティーでErasure Codingの実装に参加してきました。本記事ではErasure Codingの仕組みを詳しく解説し、弊社での運用事例を紹介します。
既存のHDFSの課題
Hadoopの中核をなす分散ファイルシステムのHDFS(Hadoop Distributed File System)は、マスターノードであるNameNodeと複数のスレーブノードであるDataNodeから構成されています。データの実体はDataNodeに分散して保存され、そのメタデータをNameNodeが保持しています。
サーバーの障害などからデータを守るためには、何らかの方法でデータを冗長化する必要があります。バージョン2系までのHadoopでは、HDFSにアップロードされたデータは複数のブロックに分割され、さらに各ブロックは3つのDataNodeにコピーされます。この仕組みをレプリケーションと言い、コピーされた3つのブロックのことをレプリカと言います。
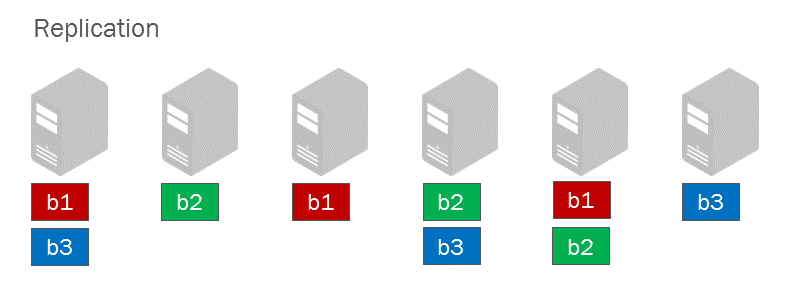
レプリケーションはシンプルながら強力な冗長化の手法です。高い耐障害性を保ち、MapReduceジョブにデータのローカリティを提供します。
しかしながら、レプリケーションにはストレージコストが高いという欠点もあります。3つのノードにブロックをコピーするということは、元のファイルサイズに対して3倍のストレージ容量が必要となり、200%のオーバーヘッドが生じます。企業が収集するデータ量は年々増加し続けていますが、データ量が増えるほどこの欠点は顕著になります。Hadoopのバックアップクラスタを構築するとストレージコストはますます増大します。
Erasure Codingとは
Erasure Coding(発音はイレイシャーコーディングが近いようです。以下ECと略します)はレプリケーションと並ぶ冗長化の手法です。レプリケーションと比較すると少ない冗長性で同等かそれ以上の耐障害性を提供します。Google File Systemの後継であるColossus, WAS(Window Azure Storage), Ceph, QFSなどでも採用されています。
ECでは元のファイルから複数のデータブロックとパリティブロックを生成します。あるデータブロックが消失しても、残りの正常なデータブロックとパリティブロックから元データを復元できます。データブロックからパリティブロックを作成することをエンコード、パリティブロックを使ってデータブロックを復元することをデコードと言います。ECの標準的な符号化であるリード・ソロモン符号(Reed-Solomon Coding)は、数学の補間多項式を応用したアルゴリズムを利用しています。
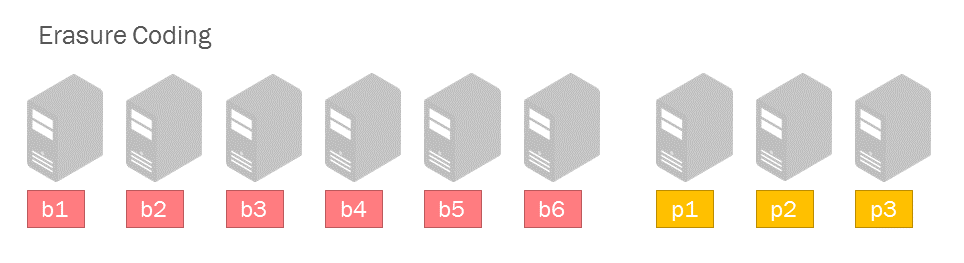
上の図はb1~b6がデータブロックで、p1~p3がパリティブロックを表しています。復元に必要なブロックはデータブロックの個数と一致します。この場合3個までならどのブロックを失っても、残りの6個のブロックがあれば元データを復元できます。このとき元データに対して必要なストレージ容量は1.5倍で、冗長化によるオーバーヘッドは50%です。
| レプリケーション(3) | Erasure Coding(6,3) | |
|---|---|---|
| 損失の許容できるブロック数 | 2 | 3 |
| 冗長化のオーバーヘッド | 200% | 50% |
ECはレプリケーションと比べて書き込むデータ量が少なくなるので、書き込み時のネットワーク帯域やディスクIOも減少させます。ただし、壊れたブロックを復元する際はエンコード/デコードの処理をするため、逆に負荷が増加します。
ECブロックの実装の詳細
HDFSで採用されたECのブロックの実装について説明します。レプリケーションのブロックにはデータが連続して書き込まれていますが、ECのブロックはストライプ状になっています。ストライプの大きさやデータブロックとパリティブロックの数には選択の余地があり、その方針をECポリシーと言います。HDFSにはあらかじめいくつかのECポリシーが用意されています。どのECポリシーが適しているかはユースケースにより異なります。
以下はよく使われるECポリシーである データブロック6個・パリティブロック3個・セルサイズ64KBのストライプ方式 を用いたときの、クライアント側の書き込みフローです。
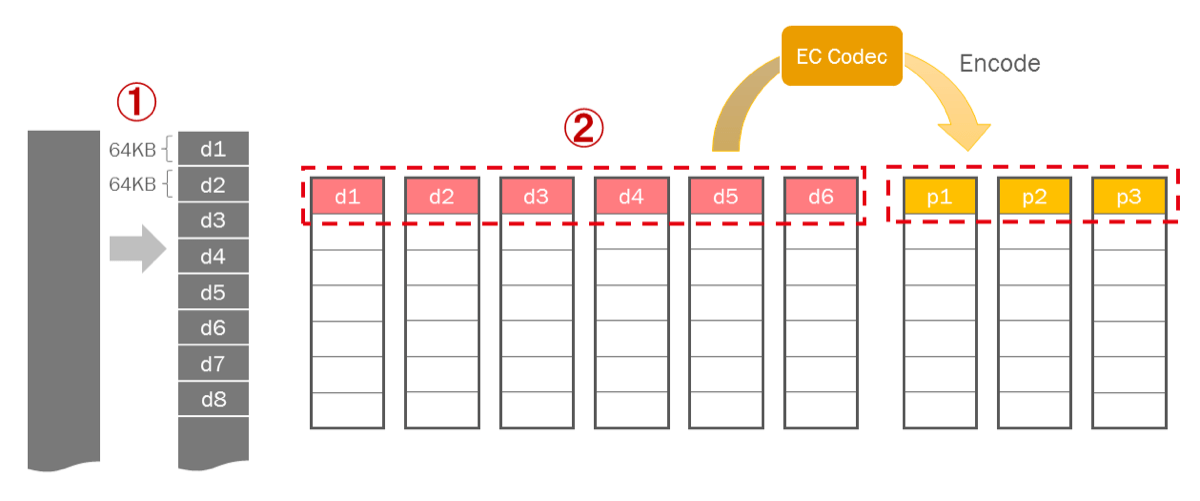
(1)元のデータを64KBごとのセルに分割します。
(2)6つのデータセルをエンコードして3つのパリティセルを作成し、各ブロックに格納します。こうして1列目のストライプが作成されます。
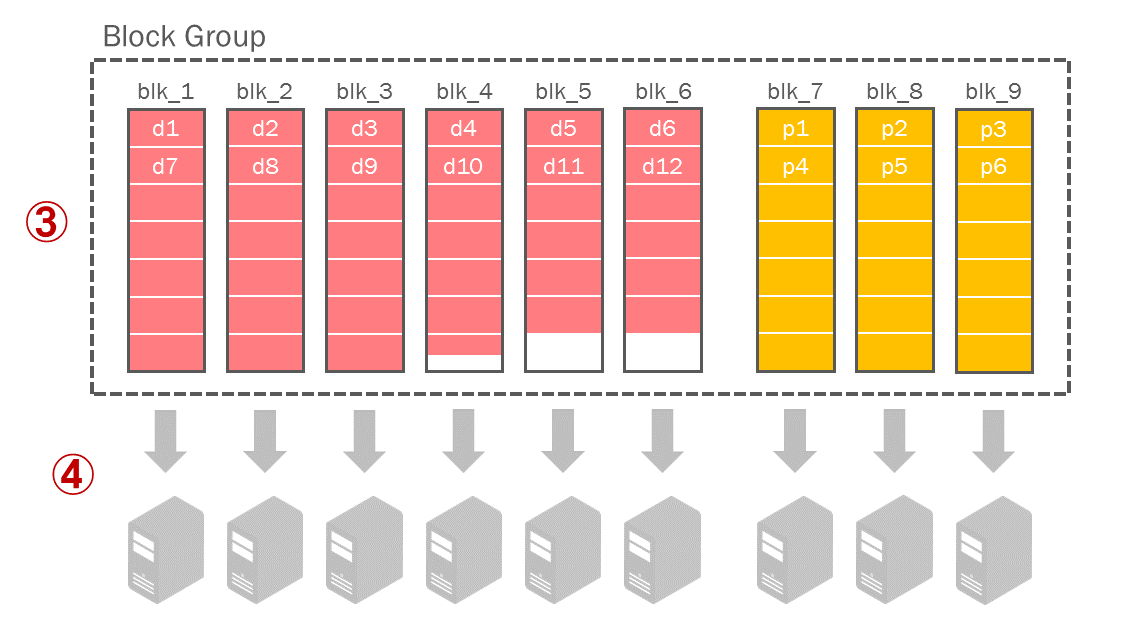
(3)同様に後2列目以降のストライプも作成します。
(4)ストライプの作成と並行して9台のDataNodeへ転送します。各DataNodeへの転送も並行に行われます。
この9つのブロックの組をブロックグループと言います。1つのブロックサイズはレプリケーションと同様に現在のデフォルトで最大128MBです。元のデータが128MB × 6(データブロックの数)= 768MBよりも大きい場合は、2組目のブロックグループが作成されます。図のようにデータブロックの最後のストライプの途中でデータ書き込みが終わっても、残りのデータセルは0バイトであるという情報を元にエンコードが行われるため、パリティブロックの生成に影響はありません。
ストライプ状にデータを保存することのメリットは何でしょうか? もしもレプリケーションと同じようにデータを連続で書き込むと、元データが128MB以下である場合、データブロック1個・パリティブロック3個のストレージ効率の悪いブロックグループが作成されてしまいます。弊社の大規模Hadoopクラスタは多様なサービスに利用されていますが、保存されているファイルのうち約75%が128MB以下のファイルであり、他の多くの企業でも同じような状況が想定されます。ストライプ状に保存することで、数MBの小さなファイルでも9個のブロックが作成されて効率よく冗長化できます。さらにデータの読み書きは複数のDataNodeに対して並行に行われるため、ディスクのアクセスも分散されてIOのスループットが高まります。
一方でデータがストライプ状に保存されているが故に、MapReduceなどの処理においてはデータのローカリティが失われるというデメリットもあります。そのためストライプ方式のECは、それほど頻繁に処理されないようなコールドデータに向いています。実際のユースケースでは、三カ月を過ぎたログデータは分析する頻度が減るためECファイルに変換しておく、などといった運用が想定されます。
ただしこの場合でも、ネットワーク帯域を十分に確保できる環境においては、ローカリティの有無はあまり問題にならなくなります。
HDFSのコンポーネントに対する拡張
Hadoopのバージョン2系までのHDFSはレプリケーションを前提として設計されています。バージョン3.0系ではECの仕組みを導入するにあたって、HDFSのコンポーネントやツールに大規模な開発が行われました。ここでは主要なコンポーネントに対して行われた拡張について説明します。
NameNode
NameNodeはメタデータとしてファイルとブロックのマッピング情報を管理しています。レプリケーションの場合ブロックサイズ(デフォルトで128MB)以下のファイルは1つのブロックに収まりますが、ECでは小さなファイルでも9個のブロックが生成されるので、1ブロックごとに管理しているとメタデータが増大してしまいます。そこで、ECファイルの場合はブロックグループごとにまとめて管理することで、メタデータの最適化が図られています。
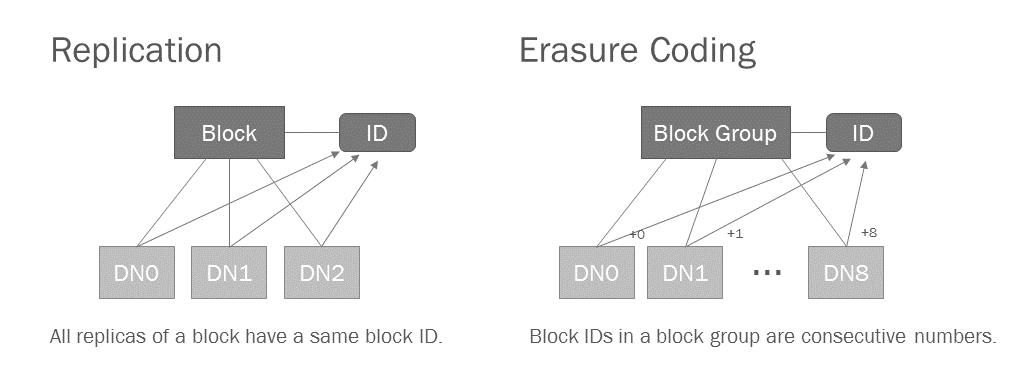
実は同じブロックグループの中のブロックのIDは、連続した番号が割り振られるようになっています。NameNodeはブロックグループの先頭のブロックIDだけ管理すれば、残りのブロックIDは必要な時に割り出すことができます。またレプリケーションのブロックIDが正の値であるのに対し、ECのブロックIDはマイナスの数値が割り振られているので、ブロックIDからECかどうかを判断することも可能です。
クライアント
書き込み
前述の通り、クライアントはデータの書き込み時にブロックグループを作成して9台のDataNodeへ並行に転送します。もしもDataNodeに問題が生じて、ブロックが転送できなかったらどうなるでしょうか? ECの場合は6個のブロックがあれば元のファイルは復元できるので、3個までなら書き込みが失敗してもクライアント側では何もせずに無視します。損失しているブロックは後述のDataNodeのECWorkerによって、バックグラウンドで自動的に復元されます。書き込み時に4台以上失敗したら全体的な書き込みとしてもエラーになります。
読み込み
書き込みと同様に、読み込みも複数のDataNodeに対して並行に行われます。
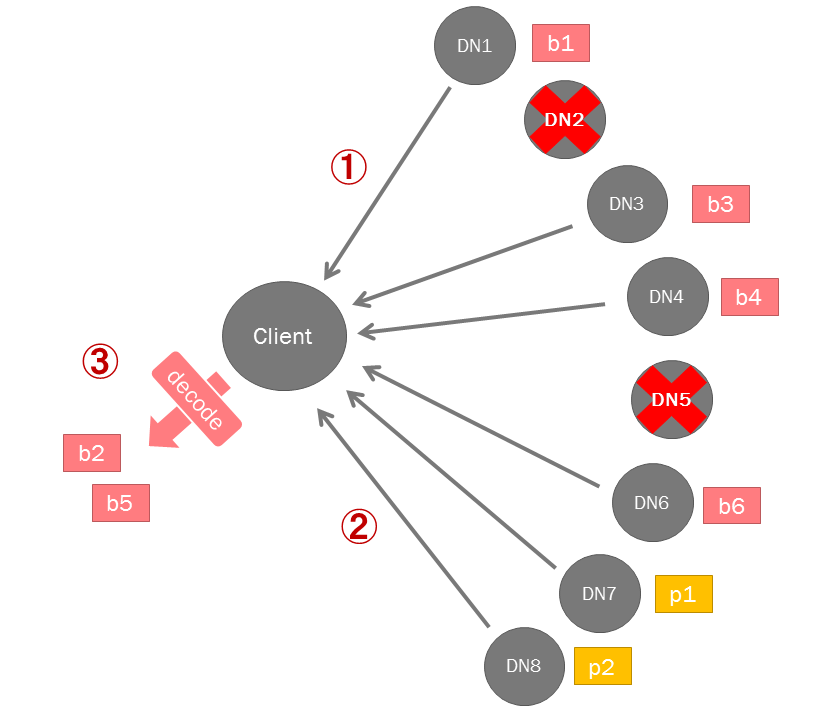
クライアントはデータブロックを優先的に読み込もうとします(1)。もしもデータブロックが消失していれば、その分だけパリティブロックを読み込み(2)、デコードして元データを復元します(3)。4つ以上のブロックが損失・破損している場合は、読み込みはエラーになります。
クライアント側で復元したブロックがHDFSに転送されることはありませんが、クライアントは問題のあるブロックをNameNodeに報告し、NameNode側で復元作業がスケジューリングされます。
DataNode(ECWorkerとブロックの復元作業)
ブロックが壊れたり失われたりしても、復元可能な範囲であればHDFSは自動的に回復しようとします。
DataNode側でも定期的に保持しているブロックの整合性をチェックをしており、問題を見つけるとすぐにNameNodeへ報告します。クライアントやDataNodeからの報告に基づいて、NameNodeは危険度の高いものから優先的に復元作業のスケジューリングを行います。例えばレプリケーションであればレプリカが1つしかないブロック、ECであれば正常なブロックが6個しかないブロックグループは復元の優先度が高くなります。
レプリケーションの場合は正常なレプリカを再度コピーするだけですが、ECではエンコードやデコードを行ってブロックを再作成します。このECブロックの復元作業を行うために、DataNode内にECWorkerという新たなコンポーネントが実装されました。以下ではECWorkerによる復元作業のフローを説明します。
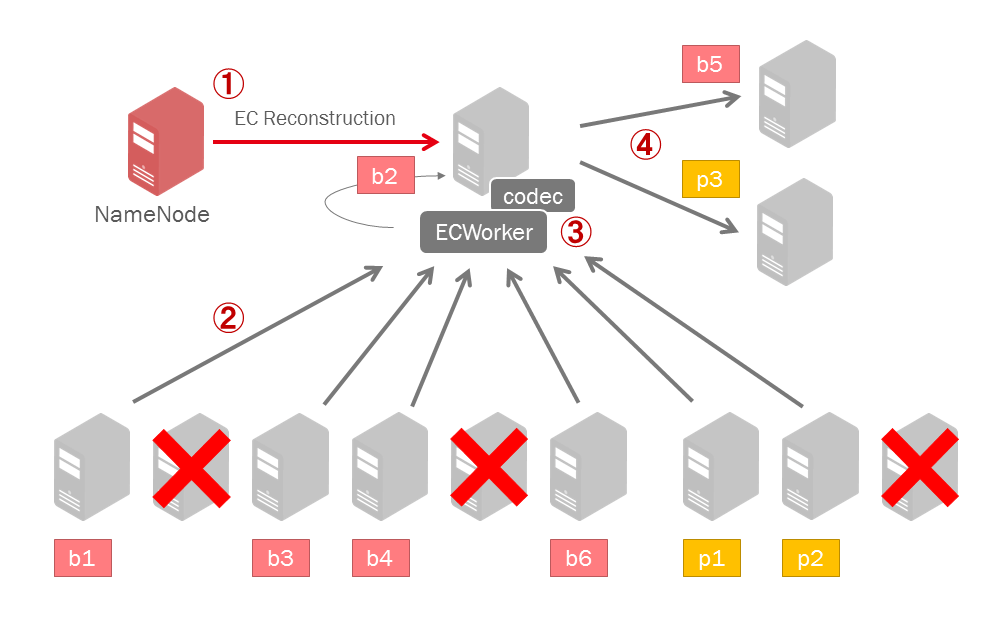
スケジューリングに基づいて、NameNodeはある新しいDataNodeへブロックを復元するための命令を送ります(1)。NameNodeから送られてくる命令には正常なブロックを保持しているDataNodeの情報が含まれています。ECWorkerはこの情報に基づいて正常なブロックを読み込み(2)、エンコードまたはデコードを行います(3)。そして復元したブロックを正常なDataNode(1個は自分自身)へ転送します(4)。
DataNodeはNameNodeから復元の命令を受け取った時にだけECWorkerを起動するため、通常時はECWorkerによるオーバーヘッドはほとんど発生しません。
初期リリースでは実装されない機能
ECに関する以下の機能は開発が予定されていますが、バージョン3.0の初期リリースでは見送られることになりました。
- hflush/hsync および append/truncate
appendはログコレクター系のエコシステムなどで利用されています。ECファイルに対してはできないので注意してください。
- レプリケーションのファイルをECファイルに変換するコンバーター
初期リリースではレプリケーションからECへの変換はdistcpで行います。distcp元のデータは必要なければ削除する必要があります。
- データが連続した(ストライプ状ではない)ECブロック
小さなファイルには向いていないことを説明しましたがローカリティを保つことができるなどのメリットもあり、HDFS-8030で開発が予定されています。
ECファイルの作成例
ここでは実際にhadoopコマンドを使ってECファイルを作成してみます。
※ここで紹介するコマンドはバージョン3.0の正式リリース時には変更される可能性があります。
EC用のディレクトリを作成します。
$ hadoop fs -mkdir /erasure-coded利用できるECポリシーを確認します。本記事で紹介してきたECポリシーはRS-6-3-64kです。
$ hdfs ec -listPolicies
Erasure Coding Policies:
RS-10-4-64k
RS-3-2-64k
RS-6-3-64k
RS-LEGACY-6-3-64k
XOR-2-1-64kポリシー名はECの実装方法を表しています。
<符号化の方式>-<データブロックの数>-<パリティブロックの数>-<ストライプのセルサイズ>RS-6-3-64kのECポリシーを設定します。設定はHDFSの特権ユーザーで行う必要があります。
$ sudo -u hdfs hdfs ec -setPolicy -path /erasure-coded -policy RS-6-3-64kECポリシーを設定したディレクトリ配下にファイルを書き込むと、ECファイルが作成されます。1GBのECファイルを作成してみます。
$ hadoop fs -put file_1G.data /erasure-codedfsckを実行してみます。1GBのファイルは1ブロックグループ(768MB)よりも大きいので、2つのブロックグループが作成されていることが確認できます。
$ hdfs fsck /
...
Status: HEALTHY
Number of data-nodes: 10
Number of racks: 1
Total dirs: 2
Total symlinks: 0
Replicated Blocks:
Total size: 0 B
Total files: 0
Total blocks (validated): 0
Minimally replicated blocks: 0
Over-replicated blocks: 0
Under-replicated blocks: 0
Mis-replicated blocks: 0
Default replication factor: 3
Average block replication: 0.0
Missing blocks: 0
Corrupt blocks: 0
Missing replicas: 0
Erasure Coded Block Groups:
Total size: 1073741824 B
Total files: 1
Total block groups (validated): 2 (avg. block group size 536870912 B)
Minimally erasure-coded block groups: 2 (100.0 %)
Over-erasure-coded block groups: 0 (0.0 %)
Under-erasure-coded block groups: 0 (0.0 %)
Unsatisfactory placement block groups: 0 (0.0 %)
Average block group size: 9.0
Missing block groups: 0
Corrupt block groups: 0
Missing internal blocks: 0 (0.0 %)
...Hadoopコミュニティーにおける開発について
バージョン3.0の初期リリースに向けたECの開発はおおむね完了しており、現在はバグ修正や改善が行われています。以下は開発の中心となっている親チケットです。
Yahoo! JAPANではHortonworksと協力しながら開発とシステムテスト/パフォーマンステストを行ってきました。弊社で行われたテスト結果は昨年のメルボルンのHadoop Summitで発表を行いました(HDFS Erasure Coding in Action)。他にはCloudera, Intel, Huaweiといった企業が積極的な開発とテストを行っています。
Yahoo! JAPANでのECの運用
Yahoo! JAPANではプロダクション環境の700台規模のクラスタにECをデプロイして、半年以上の運用をしてきました。
アーカイブディスクの併用
弊社ではECをArchival Storageと組み合わせて利用しています。Archival Storageはブロックを保存するディスクの種類を指定できるHDFSの機能です。ECはコールドデータに向いているので、この機能を使ってECファイルをアーカイブディスクに保存すると、さらに効果を発揮できます。アーカイブディスクとはデータの保存に特化したディスクのことで、弊社のケースでは通常のディスクと比べてストレージコストを30%ほど削減できます(ただしディスク速度は半分程度になります)。ECと合わせて約65%ものストレージコストを削減することができました。
運用からコミュニティーへのフィードバック
昨年の秋頃にECにまつわるバグが原因で、DataNodeからNameNodeへ送信されるブロック情報が適切に処理されず、ブロックの復元作業が停止してしまう事故が起こりました。このバグまれな状況で発生するため開発段階で見つけるのは難しく、三カ月ほどECを運用して初めて表面化した問題でした。事故後は原因を特定してすぐにコミュニティーへフィードバックしました。この他にはクリティカルな問題は起こっておらず、おおむね安定して動いています。現在でも細かなバグ修正や改善などの貢献をしています。
今後のロードマップ
現在までにHadoopコミュニティーからバージョン3.0のα1版、α2版がリリースされました。今後もういくつかテスト版がリリースされたのち、今年の夏頃に正式版(GA)がリリースされる予定となっています。Erasure Codingの正式リリースに向けてYahoo! JAPANでは今後も積極的にHadoopコミュニティーへ貢献していきたいと思います。



