はじめに
こんにちは。データ&サイエンスソリューション統括本部データプラットフォーム本部の蔵元&古山です。今回は、Apache KylinをYahoo!ショッピングのレポート機能に適用した事例を紹介します。
なお、この事例はApache KylinのPowered Byページに以下のように記載しているものの詳細版です。
Yahoo! JAPAN uses Apache Kylin to generate tailored report for Yahoo! Shopping. Apache Kylin contributes to minimize the latency for viewing the report. Consequently, the platform team has been released from ad hoc tasks to improve performance and it has become possible to focus on adding functions for users.
また、2017年のStrata Data Conferenceで、Apache KylinのVPであるLuke Hanによって紹介されていたりもします。
Yahoo!ショッピングのストア向けレポート
Yahoo!ショッピングでは、Yahoo!ショッピングに出店しているストアに各種のレポート機能を提供しています。そのレポートの一つに、日付や商品ごとのインプレッション数・クリック数・注文実績などを可視化するものがあります。このレポートは、主にストアの出店者が注文実績を参照するために使われており、また、弊社のストア営業が出店者に効果的なプロモーションの方法を提案するためにも使用されています。
レポートの入力となるデータ量は大きいテーブルだと数千億レコード程度あり、RDBMSで扱うことが困難なので、クエリ機能を備える分散ストレージをミドルウエアとして使用する必要があります。以前はこのレポートのバックエンドにApache Impalaを採用していました。Impalaが動作するハードウエアの保守期限満了に伴い、ミドルウエアについても再度検討することにしました。
なお、この検討にあたって、レポート表示までの時間が約1分程度かかっており、これを短縮したいという要請がありました。
Apache Kylinとは
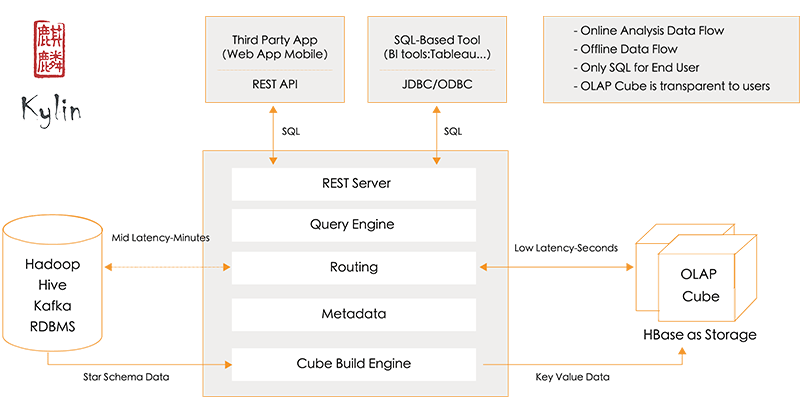
Apache Kylinは、いわゆるMOLAPのOSS実装で、キューブとよばれるクエリの結果キャッシュ的なものを事前集計することにより、クエリ実行時のレイテンシを低減することを企図して設計されています。
キューブの定義のうち主要なものは下記のとおりです。
- Table
- どのテーブルを対象にするのか
- Dimension
- どのカラムごとに集計するのか
- Measure
- どのように集計するのか(SUM, COUNT, MAX, MIN etc…)
キューブの生成にはHadoop MapReduceやSpark(バッチでビルドすることも、Spark Streamingによるマイクロバッチでビルドもできる)を使っており、生成されたキューブはHBaseに格納されます。クエリの実行時には、Kylinのクエリサーバーに対してSQLを含むAPIリクエストを発行し、クエリサーバーがHBaseにあるキューブのデータ構造をいい感じに解釈してスキャン(ベストケースでは1レコードのLookupですが、Coprocessorによるクエリ実行時の集計が走ることもあるのである程度複雑)して結果セットを返します。このため、クエリの性能の支配的要因となるのはレコード数ではなくCardinalityであり、データの分布の歪み(Cardinalityごとのレコード数の多寡)に影響されません。
基本的にアプリケーションエンジニアは元データに対してSQLを投げるように実装すればよく、キューブのデータ構造を考慮してアプリケーションを書き換える必要はありません。また、実行時にはHBaseに格納してある集計結果を取得するだけでよいため、低レイテンシを実現できます。
Kylinのアプローチには欠点もあり、キューブが生成されていなければクエリを発行しても結果を返せないこと、生データを返す機能がないことなどがアプリケーションにかかる代表的な制約です。
2016年に古山がHadoopソースコードリーディング 第20回で発表した資料に、もう少しだけ細かい機能概要の説明があるので、興味のある方はこちらも併せてご参照ください。
Apache Kylinを採用したことによるユーザー体験の改善
Apache Kylinを採用した結果、1秒以内でレポートを表示するといった大幅な改善が達成できました。
以下が1日を通じたクエリのレイテンシの平均値で、多い時間帯で数千クエリ/hourくらいのリクエストに対して、ほぼ1秒以内でレスポンスを返せています。
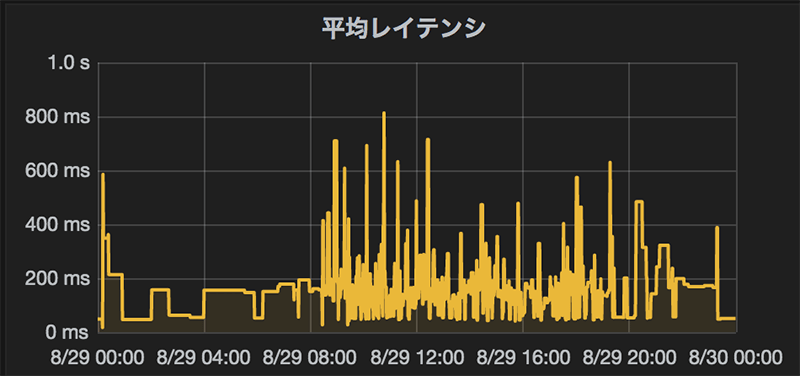
レポートの表示速度を大幅な改善したことによって、時系列でのグラフ表示や今までになかった指標をレポートに表示するなど、レポート自体の機能拡充が進みました。このApache Kylinへの刷新は2017年4月に実施しましたが、現在まで約1年半程度大きな障害も起きることなく安定運用ができています。
また、Apache Kylinのクエリ性能はデータの分布の歪みに依存しないため、今回の場合だと、インプレッション数・クリック数・注文実績が多い(より多くの人に見られている・より多くの注文を受けている)ストアのレポートを出す場合でも、ユーザー体験が損なわれないという価値がもたらされています。人気があるストアがわれわれにとって良いストアであるというわけではないですが、商売繁盛によってレポート利用者のユーザー体験が損なわれるのはシステム屋としては敗北であるとも考えられますし、好ましい性能特性であると思います。
一方で、ストアごとの取扱商品数の多寡はクエリ性能に影響を及ぼします。結果を返すのに数秒程度かかることもありますが、システム更改前との比較で言えば、改善されていることは明白であるといえるでしょう。
ストア向けレポートシステムの構成配置における特徴
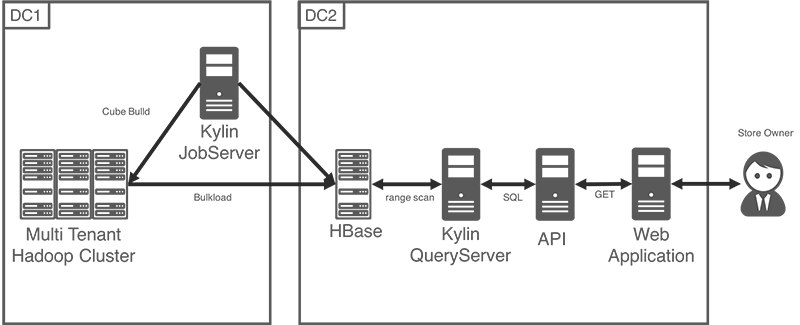
今回、DC1にあるマルチテナントのHadoopクラスタ上でキューブをビルドし、DC2にあるKylin用に構築したHBaseクラスタへビルド結果を格納するアーキテクチャを採用しました。。たいていのユースケースではキューブのビルド環境もクエリの実行環境も同一データセンターに配備するため、Lukeを含むKyligenceのメンバーと情報交換した際に非常に興味深く特徴的であるという指摘をうけたため、これについて紹介します。
DC1には、データレイクであるマルチテナントのHadoopクラスタとKylinのJobServerを配備しており、日次でHadoop MapReduceを使ってキューブをビルドします。ビルドしたキューブは、物理的にはHFileとして生成され、これをDC2のHBaseにロードします。この際に特別な設定や工夫は必要なく、Kylinの設定ファイルに出力先のHBaseのホスト名を指定したうえで、ネットワーク的な疎通がなされれていれば普通に動きます。DC2にはアプリケーションのフロントエンドと、Kylinのクエリ機能を担うQueryServerと、先にふれたHBaseを配備しています。キューブのビルドのステップの後半でマルチテナントのHadoopからHBaseにデータをロードするところにのみインタラクションがあり、クエリの実行時にDC2からDC1にアクセスすることはありません。
このアーキテクチャには以下のメリットがあります。
- DC1にマルチテナントのHadoopクラスタがあったため、その既存の計算資源を有効に使えること
- DC1は広域ネットワークのラウンドトリップにかかるレイテンシが相対的に高いため、レイテンシが低いDC2のみでクエリ実行を完結させられること
また、より一般的に考えると、この構成には以下のような応用例があると言えそうです。
- データがグローバルに近距離になく(HQが海外にありデータセンターもそこにある、コストメリットのため海外のAZに生データを配備している、など)インタラクティブな分析が高レイテンシによって阻害されるような場合に、キューブを任意の分析者近傍に置けるため、生データの移動を伴わずに分析のユーザー体験を向上させることができる
- 統計化されたデータを異なる主体と共有したい場合に、データの解像度を極端に下げずに抽象化された状態で渡すことができる(OLAPができるデータ構造でデータ提供ができる)
- クエリ可能なデータを複数拠点に配備することによって、生データ全量をコピーせずにクエリ機能の複数拠点化ができる(Kylinに複数のHBaseを出力先にする機能はないはずなので、キューブのHFileをコピーするような作りこみが必要にはなる)
技術選択
このアプリケーションにはもともとImpalaを使っていたので、アーキテクチャの検討時期にリリースされたApache Kuduを使用するという選択もありましたが、採用はしませんでした。Impala+Kuduの設計意図はデータの発生からクエリを実行可能にするまでのレイテンシを低減することに主眼が置かれているものとみており、日中に参照される定型レポートの生成に対しては、そのメリットよりも、クエリ性能がデータの分布の歪みに依存しないことのほうが高いと考えました。
また、仮にImpala+KuduやPresto/Phoenix/SparkSQL/Hive+LLAPなどを採用しても、データ量に鑑みて1秒を切るためにはアプリケーションによるデータの事前集計が必要になるものと思われます。なお、これらのクエリエンジン/ストレージの組み合わせは年率2x-4xで性能改善されるというちょっと前のレポートもあり、社内でも似たような性能向上のトレンドを継続して観測しているため、各々の最新安定版を使えばこの限りではないかもしれません。蛇足が続きますが、どのミドルウェアを使用するかに拘泥するよりも、最新安定版に追従できるオペレーションを考えることのほうが重要であるということもできます。非機能だけでなく機能も日進月歩です。
Druidは上記のものたちと比べてKylinと近い位置づけであり、生データのリストを作成する、Hiveテーブルと結合するなど、OSSのKylinでは実現が難しいこともできますが(前者は Kyligence Enterpriseで実現できる)、今回は既存のマルチテナントの資産が使えるという条件があったため、採用しませんでした。
Apache Kylinの難しさ
これまでKylinの良い面を強調してきましたが、難しいところもいくつかあります。
- データアーキテクチャがシンプルになる反面、システムアーキテクチャは複雑になる: アプリケーションはキューブのデータ構造を意識せずにクエリでき、事前集計をアプリケーションで行わなくてよいため、データアーキテクチャはシンプルであると言えます。一方で、システムアーキテクチャにおいては、HBaseやそれが使うZooKeeper, Kylinのコンポーネント群を運用管理しなければならないため、複雑さは増します。
- クエリを実行する人にキューブの設定に関する知識が求められることがある: 上記のアーキテクチャにおけるトレードオフと関連しますが、クエリを効率的に実行するにはキューブの設定をチューニングする必要があります(本稿ではキューブの設定についての説明は割愛しているため、興味のある方は公式ドキュメントを参照してください)。
キューブについてあまり考えずアプリケーション機能を追加すると性能が出ないということになります。チューニングはちょっと勉強すればできるようになるので極端に難しいということはないですが、データに対して透過的にクエリ性能を向上できるメリットがアプリケーションエンジニアの負担を減らすという意味ではあまり機能しないということになります。 - ユースケースの見極めが困難: 集計前データについてはKylinを通してクエリしないという大きな見切りが必要なため、これでいいか決めるのは悩ましいところです。多くの場合、ほかのクエリエンジンやRDBMSのオフロードを目的として、それらと組み合わせて使うことになるのでそれ自体は問題ではないと見立てることもできます。ただ、やはり、アプリケーションで事前集計して性能向上を頑張るアプローチよりも常によい選択になるというほど自明な効用があるとはいいがたいところがあります。
また、HBaseを使っているので、データやアプリケーションの変化に対するコントロールの難しさはありそうですが、われわれのユースケースではバッチ処理でキューブビルドしてHFileをバルクロードしているだけなので、前述のとおりほとんど問題は起きていません。Kylinはキューブのストリームビルドも可能なので、その機能を使う場合はこの限りではないものと想像します(いまのところ使ってないのでなんともですが)。
今後について
このユースケースについては安定運用されていて、バージョンも若干古いものを使用していますが、あまりいじる用事がないので余裕があるときにそのときの最新安定版にアップグレードしようと考えています。また、別のユースケースについても使えそうなものが出てきたので、それがうまくいったら引き続きコミュニティにフィードバックしようと思います。



