こんにちは。Yahoo!広告のデータマーケティングソリューション開発担当の岩崎です。
Yahoo!広告では広告出稿サービスとともに、データを活用して広告主のビジネスを支援するソリューションを提供しています。本記事では、検索広告のキーワードを機械学習で評価し発掘する「ポテンシャルKW(キーワード)」と学習データ不足ケースに対する工夫を紹介します。概要は下記です。
- 【効果的な検索キーワードの発掘】キーワードからコンバージョン(獲得)ポテンシャルを予測する
- 【学習データ不足ケースへの対応】学習データが少ないアカウントに対して、類似アカウントをDice係数で探索しデータを増やす
効果的な検索キーワードの発掘
ポテンシャルKWとは
検索広告(リスティング広告)は下記のようにユーザーの検索クエリーに応じて、広告主が登録したキーワードと関連性の高い広告を出稿します。(ヤフーの検索広告について)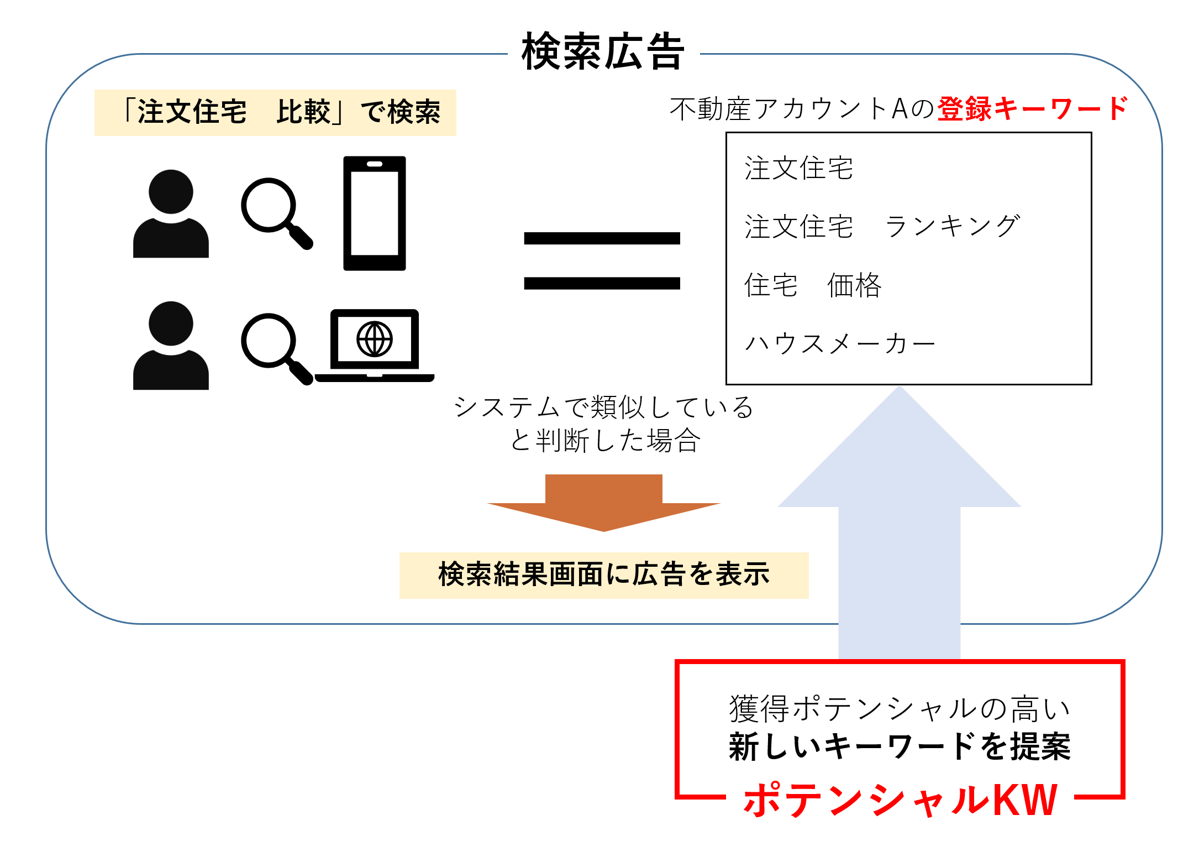 キーワードには商材や業界に関するワードを単体もしくは組み合わせで登録することが多いですが、コンバージョン(商品購入、会員登録、資料請求など成果の総称)の獲得ポテンシャルが高いキーワードを多く見つけるのは時間がかかる作業です。それに対するソリューションとして、検索クエリーや業界全体のキーワードなど大量の候補を抽出し、獲得ポテンシャルを機械学習で予測することで発掘する仕組みを提供しています。これがポテンシャルKWの全体像です(より詳細は動画をご覧ください)。
キーワードには商材や業界に関するワードを単体もしくは組み合わせで登録することが多いですが、コンバージョン(商品購入、会員登録、資料請求など成果の総称)の獲得ポテンシャルが高いキーワードを多く見つけるのは時間がかかる作業です。それに対するソリューションとして、検索クエリーや業界全体のキーワードなど大量の候補を抽出し、獲得ポテンシャルを機械学習で予測することで発掘する仕組みを提供しています。これがポテンシャルKWの全体像です(より詳細は動画をご覧ください)。
ポテンシャルKWのアウトプットは下記のようになっています。
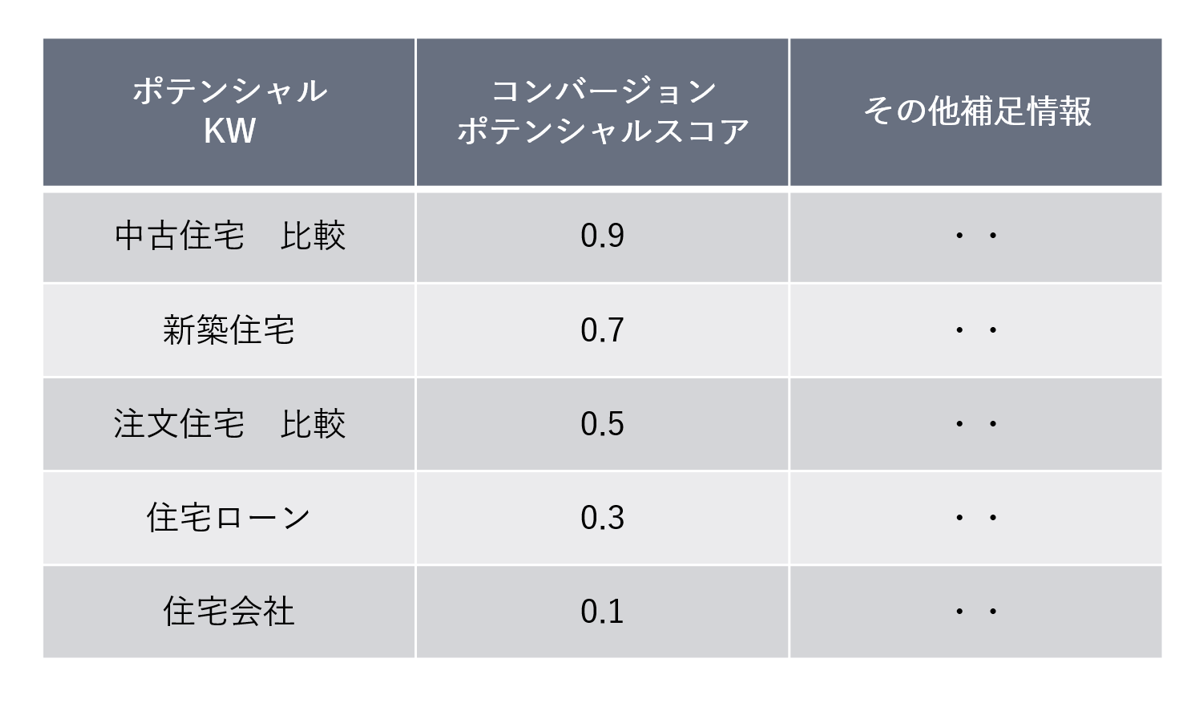
候補のキーワードにそれぞれコンバージョンポテンシャルのスコアを付与しています。基本的にはスコア上位のキーワードが入稿候補ですが、中位以下のキーワードも比較用に表示しています。スコア以外にはキーワードの検索流入数、入稿推奨広告キャンペーン等の情報も提供しており、キーワードを選抜・入稿する際の参考情報として活用できます。最終的にはポテンシャルKWの結果を営業担当が精査した上で広告主や代理店の方に提案します。続いてシステムの全体像と機械学習モデルの詳細を説明します。
システム概要
システムの全体像を下記の図を元に説明します。
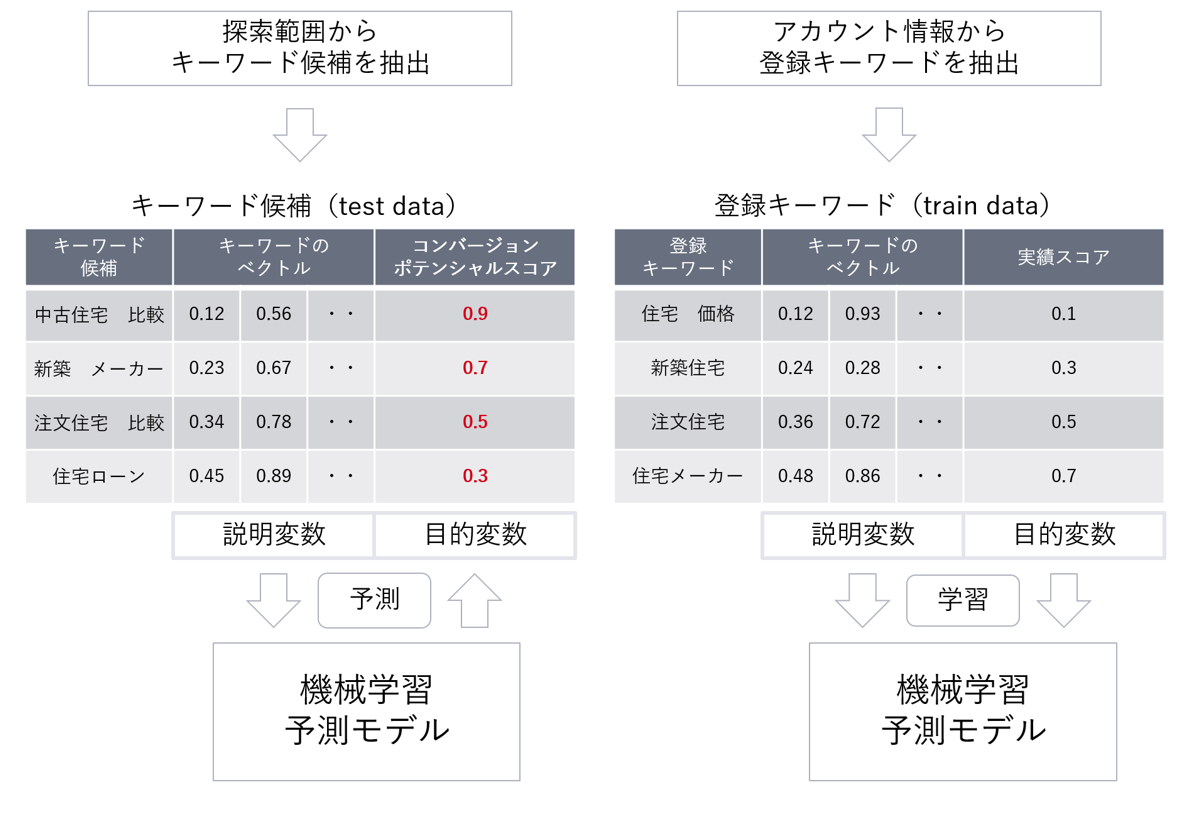
まず、設定した探索範囲から検索クエリーや業界全体のキーワードを探索し、その中からキーワード候補を抽出します(図の左側のtest data)。キーワードのベクトル化では、キーワードを機械学習モデルの特徴量とするために、前処理や形態素解析を行った後に変換モデルでベクトル化しています(単語や文章をベクトルに変換するモデルはWord2Vec,fastText,BERTなどがあります)。
次に、広告主ごとに存在するアカウントの登録キーワードも抽出し同様にベクトル化します(図の右側のtrain data)。train dataのキーワードのベクトルから実績スコアの傾向を機械学習モデルで学習させます。
このモデルでtest dataのキーワード候補のコンバージョンのポテンシャルを予測することが可能です。ポテンシャルKWは、各アカウントの営業担当が社内ツールでいつでも抽出できる仕組みを整えています。
このシステムは、アカウント単位で予測モデルを作成する点に特徴があります。理由としては、全く同じキーワードでも登録するアカウントによってコンバージョンのポテンシャルは異なるためです。例えば「住宅 価格」というキーワードに対応する検索意図として、住宅を購入したい、住宅を売却したい、単に情報として関心があるなど複数のケースが考えられます。このキーワードがどれだけコンバージョンを獲得できるかどうかは、注文住宅、分譲住宅、不動産仲介などそれぞれのアカウントで変わる可能性が高く、アカウント別にモデルを作ることで全体で一つのモデルを作るより精度が良くなります。
学習データ不足ケースへの対応
課題
しかし、必ずしも1アカウントに機械学習モデルを作るために十分なデータがあるとは限りません。キーワードのコンバージョンポテンシャルを予測するモデルは個別のアカウントごとにつくりたいですが、一方で1アカウントでは学習データとなる登録キーワードが足りないクライアントも存在します。特に新設アカウントほどキーワードを追加する労力が大きく、ポテンシャルKWによるキーワード追加が重要なのにもかかわらず、学習データとなる登録キーワードや実績スコアが不足するという課題がありました。このように学習データが少なく、初期に予測モデルを作れない課題に対するアプローチとして、アカウントの上位階層のデータを使うアプローチが考えられます(類似の課題:機械学習の階層モデルの適用でコールドスタート問題に対処する 〜 広告コンバージョン予測の事例)。
社内ではアカウントごとに対応する業種カテゴリーが割り振られており、上位階層のアカウントを見つけることはできましたが、検証した結果十分な予測精度が出ませんでした。この要因としては業種カテゴリーだと、アカウントの商材と比較して範囲が広すぎるためと考えています(例えば、不動産カテゴリーでも「住宅 価格」のように同業種でも扱っている商材が多様なため)。本課題に対応するために、細かいカテゴリーを新たに作るアプローチも考えられますが、カテゴリーを何個に分けるか、新設アカウントをどのカテゴリーに分類するかなどかなり工数がかかる作業です。
類似アカウントの自動抽出
そこで、適切なアカウントを自動で抽出するロジックを開発しました。ロジックの特徴は以下です。
- アカウントに登録されている「キーワード集合」によりアカウント間の類似度を計算
- 類似度計算には「集合の類似度」を測るDice係数を利用
キーワード集合とはアカウントに登録されている複数のキーワードの集まりのことです。登録されているキーワード集合がアカウント間で似ていると広告を出す目的も似ているという発想のもと、アカウント間の類似度計算時のロジックで参照する対象として採用しました。また類似度計算には検証の結果、Dice係数を採用しました。以下では下記の図を元に3アカウントの例でロジックを説明いたします。 まず比較元アカウントのキーワード集合(以後集合Aと呼びます)と他の比較先2アカウントのキーワード集合(集合B、集合Cと呼びます)をリストアップします。集合Aと集合Bの共通要素数を2倍したものがDice係数の分子にあたり、集合Aと集合Bの各要素数を足し合わせたものがDice係数の分母に該当します。これを計算することで集合Aと集合BのDice係数が求められました、これをアカウントの類似度とみなします。同様に集合Aと集合CについてもDice係数を計算します。今回の例だと集合Aと集合CのDice係数の方が集合Aと集合Bより高く、集合Aにとって集合Cの方がより似ているアカウントであることがわかります。
まず比較元アカウントのキーワード集合(以後集合Aと呼びます)と他の比較先2アカウントのキーワード集合(集合B、集合Cと呼びます)をリストアップします。集合Aと集合Bの共通要素数を2倍したものがDice係数の分子にあたり、集合Aと集合Bの各要素数を足し合わせたものがDice係数の分母に該当します。これを計算することで集合Aと集合BのDice係数が求められました、これをアカウントの類似度とみなします。同様に集合Aと集合CについてもDice係数を計算します。今回の例だと集合Aと集合CのDice係数の方が集合Aと集合Bより高く、集合Aにとって集合Cの方がより似ているアカウントであることがわかります。
同様の計算をすべてのアカウントに対して行い集合Aに対するDice係数を算出した上で、Dice係数上位のアカウントをリストアップします。これらの複数アカウントのデータを用いて予測モデルを作った結果、学習データが少ないアカウントでも精度が良い予測モデルを作ることが可能になりました。※データを増加する際には、個別のアカウントの状況が強く出ないよう相当数のアカウントの集合体になるように考慮しております。
検索広告のアカウントは数多く存在しますが、Dice係数を算出する際の共通要素数はINNER JOIN、各要素数はCOUNT()で求められるなどSQL上で計算することができ、処理速度についても許容できるものでした。
検証過程では、キーワードのコサイン類似度上位で測定する方法も試しましたが、同質なキーワードが集まりすぎたためか予測精度が十分でなかったほか、処理速度等のパフォーマンスの観点から集合の類似度を使う方法を選択しました。また集合の類似度を測る指標にはDice係数以外にもJaccard係数やSimpson係数が存在しますが、SQLでの表現のしやすさや予測精度を踏まえ今回はDice係数を採用しました。
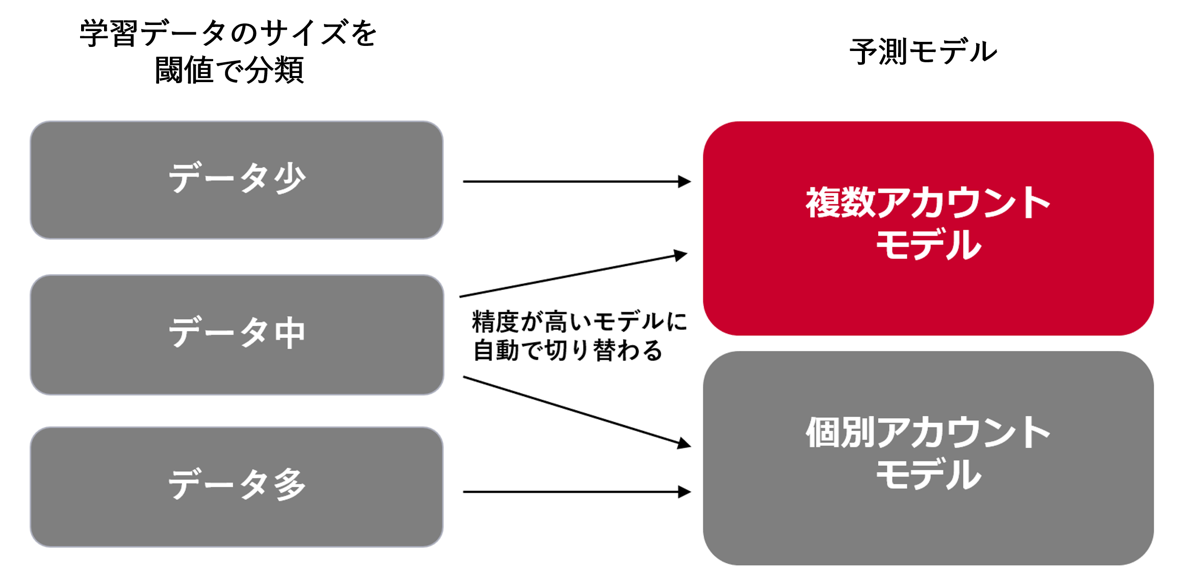
複数アカウントモデルと個別アカウントモデルどちらを使うか
複数アカウントによって学習データ数自体は大幅に増やすことができますが、一方で個別アカウントの特徴をとらえるために個別アカウントでモデルを作るという本来の方針からは離れます。また、複数アカウントモデルは処理時間やコストがある程度かかり、データが多いアカウントだとその傾向は強まります。多くのアカウントで検証した結果、機械学習のモデルを作る際にデータが少ない場合には複数アカウントモデル、データが多い場合は個別アカウントモデルの方が精度が良い傾向がはっきり見えました。データが中程度の場合は精度に関して一貫した傾向が見えずどちらが良いか迷いました。そこでデータが中程度のケースについては、両パターンでモデルを作成し、精度が良い方を採用するフローとしました(下記フロー)。下記の通り学習データ量に応じて下記3パターンに分岐させて運用しています。
おわりに
以上の工夫により、これまでデータが少ないためにポテンシャルKWが提案できていなかったアカウントにも結果を届けることができるようになった他、パターン分岐させることによって、処理時間やコストを抑えつつ多くのアカウントで精度を向上させることに成功しました。
本記事では、機械学習で検索広告のキーワードを発掘し提案する「ポテンシャルKW」というソリューションについて紹介しました。また、学習データが少ない課題に対して、集合の類似度を用いて類似データを増加する取り組みも紹介しました。今後もシステムやモデル改善を行い、より高精度、短時間でポテンシャルのあるキーワードを提供していきたいと思います。
私のチームで開発しているソリューションの他の記事も、ぜひご覧ください。
- 数千万ユーザーのビッグデータに機械学習モデルを適用するには(広告配信ソリューション実現の工夫紹介)
- 協力ゲーム理論を活用した広告効果分析(シャープレイ値で広告貢献度の公正な分配を実現)
- 大規模言語モデルを使って広告文を自動生成する
最後までお読みいただきありがとうございました。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました
- 岩崎 祥太
- データアナリスト
- Yahoo!広告のデータマーケティングソリューションを開発しています。音楽、野球、Kaggleが好きです。



