Yahoo! JAPANアプリのトップページの上部には、編集者によってピックアップされた「トピックス」と呼ばれるトップニュースが6本並んでいます。編集者が選定した質の高い記事を提供していますが、必ずしも各ユーザーの興味に適した記事が表示されているとは限りません。そのため、スクロールすると、記事推薦システムによって各ユーザーの好みを考慮した記事が自動で表示される仕組みになっています。
ニュース記事の推薦で特に重要なのは「即時性」です。ニュース記事では、情報が更新されると古い記事は役に立ちません。そのため、入稿された記事がいち早く推薦対象になることが重要になります。
たとえば、事前にユーザーごとの推薦記事一覧(レコメンドリスト)を作成しておくという方法は適していません。レコメンドリストを生成してからユーザーがサービスに訪れるまでの間に入稿されたニュース記事が、候補から抜け落ちてしまうためです。 また、協調フィルタリングのように、記事のクリック実績に依存してしまう手法も望ましくありません。こちらの理由は、記事が入稿された直後は実績がなく、すぐに推薦対象にならないからです。
そこで私たちは、ユーザーが訪れた瞬間に、最新の記事からレコメンドリストを作りつつ、計算量を減らしてレイテンシを抑える工夫を行っています。
下図が記事推薦システムの全体構成です。ユーザーが訪れる前に事前に計算しておく部分と、ユーザーが訪れた瞬間にその場で計算を行う部分の2つに大別されます。複雑な機械学習モデルが関係するのは事前に計算しておく部分で、1つの「PV Prediction Model」と2つの「Vectorize Model」の部分に配置されています。
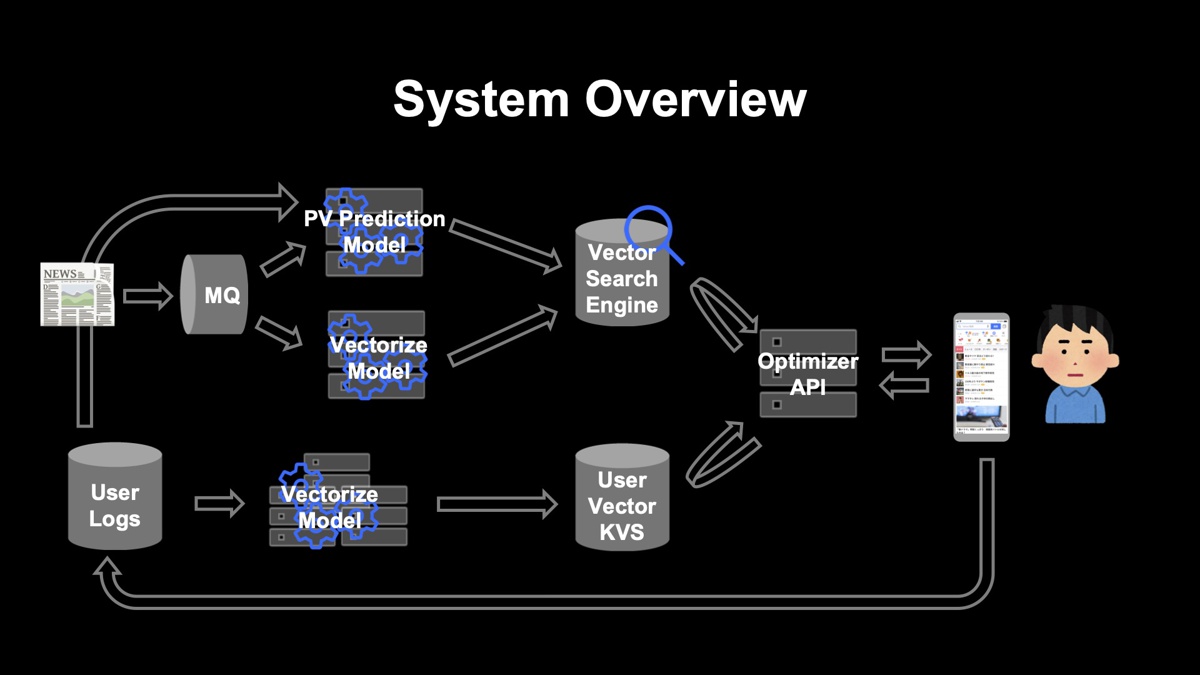
事前に計算しておく部分
「UserLogs」から「User Vector KVS」の処理(図の左下)
各ユーザーの行動ログからユーザーの特徴量を抽出してベクトル化し、ユーザーIDをキーとしたKVSに格納します。この処理は、ユーザーが起こした行動が、ユーザーが次回サービスを利用するときまでに反映されていれば良いため、リアルタイムに処理する必要はなく、1日に数度のバッチ処理を分散環境で実施しています。
記事入稿から「Vector search Engine」の処理(図の左上)
入稿された記事を解析し、特徴量ベクトルに変換してベクトル検索エンジンにインデックスしています。記事入稿があるたびに実行されますが、ユーザーのアプリ利用とは独立して、事前に計算します。加えて、記事の入稿直後の閲覧数を推定し、特徴量の1つとして検索エンジンに入れておきます。
ユーザーが訪れた瞬間にその場で計算を行う部分
ユーザーがサービスに訪問してきたら、ユーザーIDをキーにして、KVSからユーザーの特徴量ベクトルを取得します。それをクエリとして、ベクトル検索エンジンにリクエストし、ユーザーベクトルに近い記事リストを取得します。これに重複排除処理を加えてユーザーへのレコメンドリストが完成します。ユーザーからのリクエストを受けてから行う処理は、ほぼ類似ベクトルの検索処理だけのため、高速で結果を返せます。
ユーザーの行動は、ログとして後にフィードバックされ、次回ユーザーがサービスを利用するときまでにユーザーの履歴に反映されて、特徴量が更新されます。
入稿直後は推定だった記事の閲覧実績は、ユーザーからのログがたまれば、実績値に置き換えます。数日たったらその間にたまったデータを使い、各モデルの再学習を定期的に実施してモデルを差し替えます。
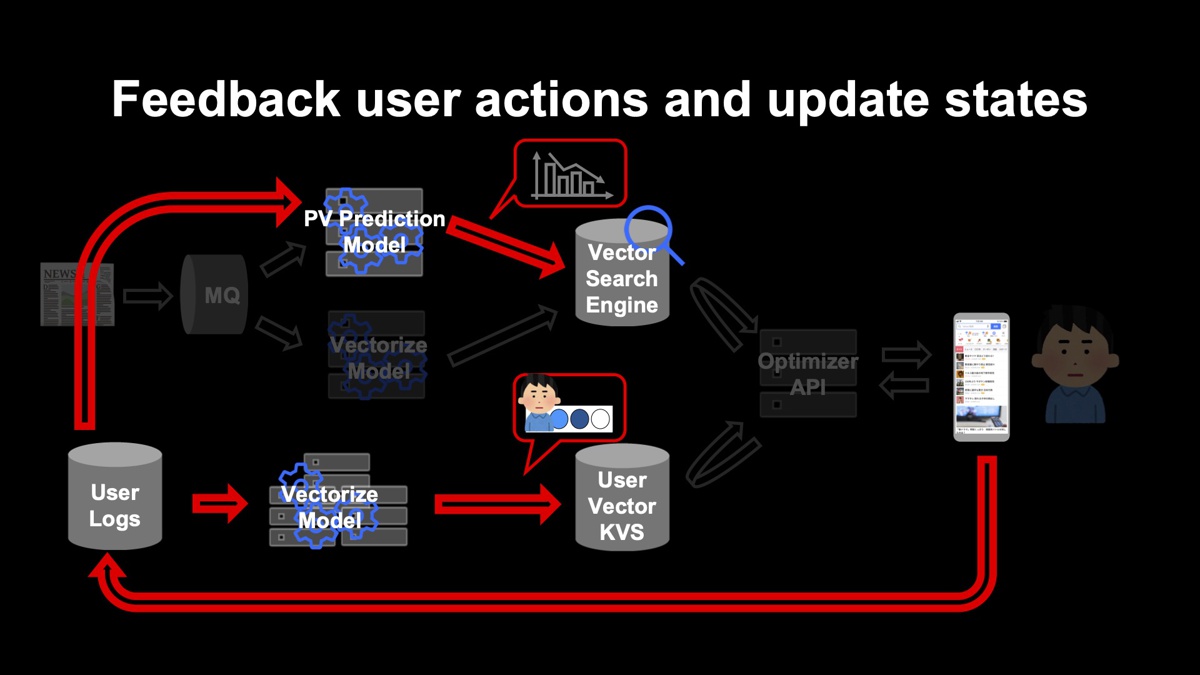
機械学習モデルの学習方法
ここでは、特徴量ベクトルを抽出する「記事をベクトル化するモデル」と「ユーザーをベクトル化するモデル」の2つに絞って説明します。これらは、最終的にユーザーベクトルをクエリとして記事ベクトルを検索できるようにするため、同時に学習しています。
モデルの学習は、記事データだけを用いた「事前学習」と、記事データとユーザーの行動履歴データを突き合わせて行う「本学習」の2段階のフェーズに分かれています。
事前学習フェーズ
大量の記事データを使用して自然文で書かれた記事を解釈するBERTモデルを学習します。
BERTモデルは、汎用的なコーパスで事前学習された日本語のものも配布されていますが、私たちのチームでは過去にヤフーに入稿されたニュース記事をたくさん持っているため、それを用いて学習したものを使っています。ニュースの見出しと本文を入力し、MLM(Masked Language Model)とNSP(Next Sentence Prediction)を行っています。
本学習フェーズ
事前学習モデルで得られた記事特徴量をユーザーの行動履歴に基づいて集約し、実際のクリック情報と突き合わせることで、記事ベクトルモデルのファインチューニングとユーザーベクトルモデルの学習を行います。
ここではユーザーの過去の閲覧記事の履歴を、BERTを用いてベクトル列に変換します。それを、リカレントニューラルネットワーク(RNN)を通して一つのベクトルに集約します。こうしてできたものをユーザーベクトルと呼んでいます。
このユーザーベクトルと、後にユーザーに推薦してクリックされた記事の記事ベクトル、推薦したがユーザーがクリックしなかった記事ベクトルの3つを突き合わせます。そして、クリックされた記事ベクトルにユーザーがより近くなり、クリックされなかった記事ベクトルから遠くなる「メトリックラーニング」と呼ばれる学習を行い、このRNNとBERTの一部をチューニングします。
ユーザーの履歴を集約する部分では、単なる履歴の記事ベクトルの平均ではなく、閲覧順を加味できるRNNを用いることで、クリック数を10%程度改善できました。
次にレコメンドシステムに関連した、最近注力している課題と対応策を3つ紹介します。
1. 推薦コンテンツの多様性
1つ目は、推薦コンテンツの多様性についての課題です。多様性を考慮せずに、推薦システムをそのまま適用してユーザーの関心度が高い順に推薦した場合、同じ内容の記事が並んだ推薦リストになることがあります。
その理由の1つは、ヤフーが複数の媒体から入稿された記事を扱っているためです。世間の関心が高い出来事が起こると、複数の媒体がその出来事を扱ったニュースをそれぞれ入稿してきます。そのため記事在庫には、媒体が違うだけのほぼ同じ内容の記事がたくさん入ってきます。
もう1つの理由は、類似ベクトル検索を用いたレコメンドを適用すると、その記事のスコアが、記事内容とユーザーの興味を反映したユーザーベクトルとの距離で決まるからです。内容が近い記事はベクトルも近くなり、必然的に近いスコアとなります。似たような記事がたくさん入稿されれば、近いスコアのそれらの記事が連続して並びます。そのため、類似ベクトル検索を行った後に、結果から重複を省く処理が必要です。
この問題について2つのアプローチを試しました。
1つ目は、記事ベクトル間の類似度を基に重複を判定する方法です。類似したコンテンツでは、内容を表す記事のベクトルは非常に近くなります。例えば、コサイン類似度を測って「0.98」という値が出たとしたら、それが一定のしきい値を上回っていた場合に、両方の記事を掲載するのではなく、片方をスキップして非表示にするというアプローチです。
2つ目は、クラスタリングを用いる方法です。事前に記事ベクトルをいくつかのクラスタに分割するモデルを学習しておき、その上で表示されたコンテンツが特定のクラスタの記事に偏った場合、それ以上は同一クラスタの記事が表示されないようにスキップするアプローチです。この手法は、1つ目の方法と比較して、やや粗い粒度で同一のジャンルで出面が埋まることを防ぐ効果があります。
2つの方法を組み合わせて使うことで、重複した同一記事の掲載は抑制され、全体のクリック数も増加しました。 一方で、これらの手法では限界があることも感じています。
世間の関心度が高いニュースの場合、数百件単位で類似コンテンツが入稿される場合があります。すると、例えばしきい値を0.8に設定するなどしてスキップしようとしても、数百件のうち2~3件はしきい値をわずかに下回り、抜けてしまうことがあります。たとえ一定のスキップが機能していたとしても、結局似た記事が並んでいるように見えてしまいます。
対応策
そこで、次の打ち手としてディストリビューション・アウェアなリランキングを考えています。 これまでの方法では、例えば、記事x のスコアは、その記事よりも上部にどんな記事が掲載されているかは加味されず、その記事の内容とユーザーの興味の近さによってのみ決まっていました。
Score(x | selected) = Relevance(x)
これに、トピック分布によるペナルティを付け加えることを検討しています。ユーザーごとに理想と思われる話題の分布「p」をあらかじめ設定しておきます。第2項は、既にそのユーザーに掲載したコンテンツに新しく1件付け加えたときに、表示されているコンテンツの分布が理想の分布pからどの程度離れてしまうかが表現されており、それによってペナルティがかかるようになっています。
Score(x | selected) = Relevance(x) ‐ λ KL(p,selected + x)

既に上部にたくさん掲載されているトピックの記事の場合は、第2項のペナルティが大きくかかるため、相対的に順位が下げられます(下図内の赤い矢印)。一方で、第1項の興味度が中程度だったために、上部のコンテンツに押し出された別のトピックコンテンツは、ペナルティが相対的に小さくなり、上部に引き上げられてコンテンツの途中に差し込まれます(下図内の青い矢印)。こうして、スコアが同程度の重複コンテンツが大量に固まっている場合でも、下から上に差し込まれるコンテンツによって、多様性が確保できます。
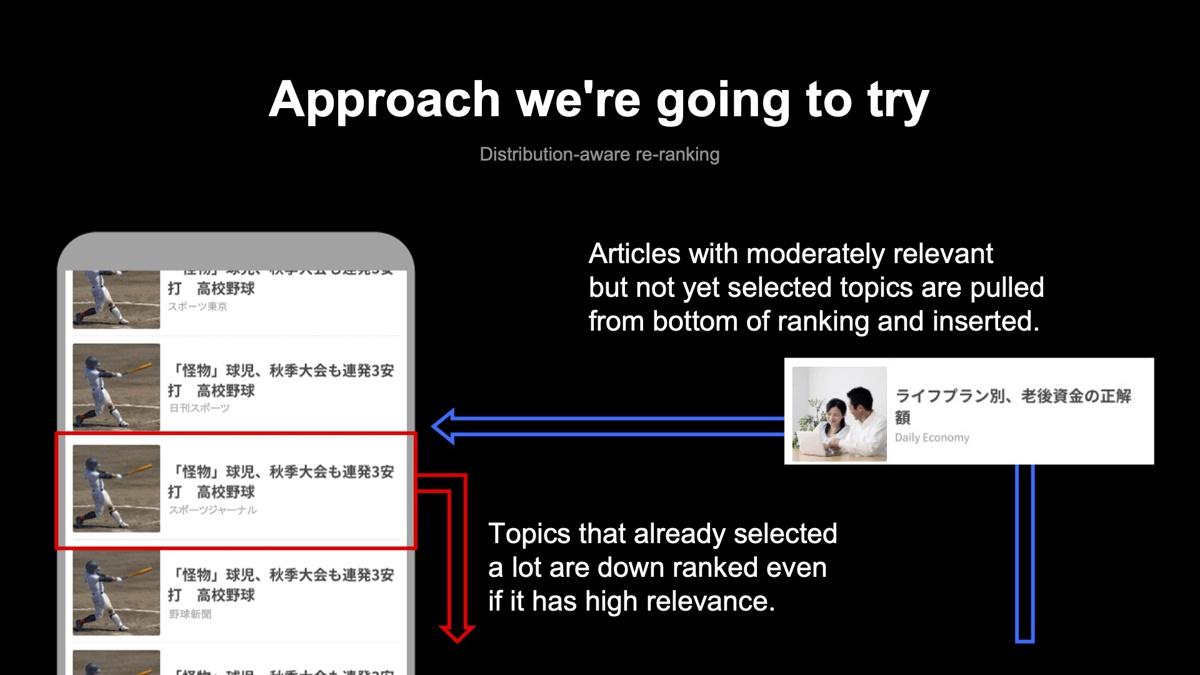
しかし、この手法を実際に使う場合、計算量の障壁があります。スキップベースの手法の場合は、記事のスコアは一度だけ計算すれば、あとはスコアが高い方からスキップするか否かの判定だけで済みます。一方で、多様性を考慮したリランキングを用いようとすると、掲載記事が1つ決まるごとにペナルティの項が変化するため、スコアを再計算して並び替える処理が1本選ぶごとに必要になってしまいます。現在は、この計算量を加味して効果を見ながら、より良いバランスを探している状況です。
2. ユーザーからネガティブなフィードバック(dislikeシグナル)を受けった際の挙動
推薦された記事が自分の好みと合わなかった場合に、類似の記事を減らすフィードバックを記事推薦システムに送る機能があります。(この機能は、Yahoo! JAPANアプリではまだ未実装で、Yahoo!ニュースアプリのみに実装されています)
この機能を実装するにあたって、推薦モデルに要求されていることは大きく2つあります。1つ目は、ユーザーからの減らしてほしいというフィードバック通りに、次回以降のセッションでそのユーザーに類似記事を推薦する割合を減らすこと。2つ目は、その記事を減らすだけではなく、他にどんなコンテンツを推薦するかまでを含めて、推薦全体の質を向上させることです。
この課題についても2つの方法を試しました。
1つ目は、ユーザーベクトルの学習時にユーザーの行動履歴を入力したのと同様に、dislikeシグナルを送った履歴も特徴量の1つして利用して、ユーザーベクトルを学習する方法です。もし、dislikeシグナルを送られた記事はユーザーにクリックされないのだとしたら、このレコメンドモデルは、dislikeされた記事のスコアを下げた方が良いことを学習すると考えました。
2つ目は、入力としてdislikeシグナルを利用するのに加えて、メトリックラーニングでdislikeした記事を負例として使い、dislikeした記事とユーザーベクトルの距離を離す学習を直接行う方法です。明示的に距離を離すように学習するので、必然的にdislikeされた記事はスコアが下がります。
下図は2つの手法を試した結果です。

1つ目の方法では、いくらシグナルを送っても、dislikeした記事と類似の記事の推薦はほとんど減りませんでした。理由は、ユーザーがあるジャンルの記事をdislikeするかと、そのジャンルの記事をユーザーがよくクリックするかどうかには、それほど強い相関が見られなかったためです。
dislikeしながらも、その類似記事をよくクリックするユーザーが一定数存在するため、学習されたモデルは、dislikeシグナルを受け取ってもスコアを減らす必要はないと判断して、次回以降も推薦を続けていました。
2つ目の方法では、次回以降のセッションでdislikeした記事の類似記事を減らす効果は実現できました。dislikeシグナルを考慮しなかった場合だと、次回に似たようなジャンルを推薦してしまう確率は約3割でしたが、1割ほどまで下げられました。
一方で、先述したようにユーザーはdislikeしているジャンルの記事もある程度クリックするため、非表示にすることで機会損失となり、クリック数は減ってしまいました。
対応策
2つのアプローチがうまくいかなかった原因の1つは、「類似記事を減らす」の「類似」の定義が非常に曖昧だったことです。例えば、映画の記事について減らすボタンを押したユーザーは、映画に興味がないという可能性がありますが、別の可能性として、映画は好きだけれど俳優が好みでなかった可能性もあります。もし後者のパターンであれば、このユーザーに対して、映画の記事を減らすことは失敗です。
単に減らすのではなく、「映画に関する記事を減らす」「この俳優の記事を減らす」「この媒体の記事を減らす」といったように、より具体的な選択肢をユーザーに与えて、ユーザーの意図を正しく読み取ることが必要だったと考えています。
もう1つの原因として、現状のランキングのアプローチだと、減らすジャンルを、ユーザーからのdislikeシグナルを無視して「そのまま残す」のか、あるいは「全部消す」のかという極端な2択になりがちなことです。
例えば、野球が好きで野球の記事をよく読んでいると、野球の記事がたくさん並んだレコメンドになります。このとき、「野球は好きだけど他の記事も少しは推薦してほしい」と思って、減らすボタンを押すこともあると考えられます。しかし現状のアプローチでは、次回利用時には、野球に関する記事が全て消えてしまいます。
興味度順にランキングするアプローチでは、そのジャンル全体のスコアを下げて推薦されにくくできますが、そのジャンルの中の記事を適度に間引いて割合を減らすという挙動は理論上できません。
つまり、dislikeシグナルを正しく実現するためにも、ただスコア順に並び替えるだけではなく、上部に表示されているものを考慮して間引くといった、分布ベースのリランキングのような仕組みが必要になってくると考えています。
3. 学習システムで見落としがちな罠
ランダムな初期値を基に学習すると、初期値の選び方によってモデルの精度が変化することに起因した落とし穴について紹介します。
あるA/Bテストを行ったときのことです。このテストでは、推薦モデルに新しい特徴量を追加したモデルを実験的に導入しました。ただし、追加した特徴量は、ごく一部のユーザーにしか影響を与えないことが事前に分かっていました。
1回目のテストでは、従来モデルの「コントロールバケット」よりも、新しい特徴量を追加した「テストバケット」のクリック数が少し増え、想定通りの結果になりました。数カ月後に本番導入することになり、期間が空いたため2回目のA/Bテストを行ったところ、今度は「テストバケット」よりも、「コントロールバケット」の方が、クリック数が多いという逆の結果になったのです。
下図の青枠で囲まれた部分はそれぞれ、コントロールバケットとテストバケットに割り当てられたユーザーです。それぞれの右下にある小さい枠は、テストバケットで追加した特徴量の影響を受けるユーザーを表し、色が濃いほど、そのユーザーには精度の良いレコメンドが提供できています。
1回目のテスト結果を見ると、コントロールバケットでは、右下のユーザーも追加の特徴量は利用していないので周りと同じ色になっています。一方で、テストバケットでは、右下のユーザーは新しく追加した特徴量が利用できるので、周りよりも少し高い精度で推薦できていることを表しています。僅差でテストバケットのパフォーマンスが勝っていました。
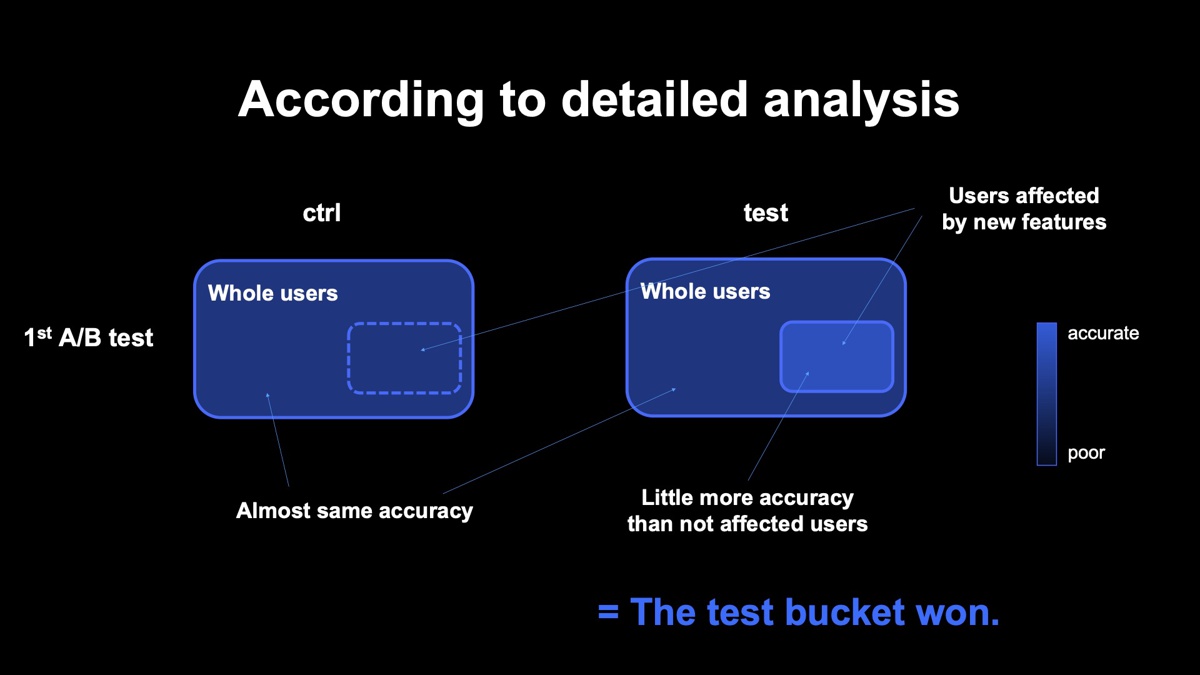
下図は2回目のテスト結果です。テストバケットにおいて追加した特徴量の影響を受けるユーザーが、周りのユーザーよりも性能が良くなっているのは1回目のテストと同じです。しかし、本来差がつかないはずの追加特徴量と無関係なユーザーの部分で性能差がついてしまい、コントロールバケットの方がトータルで性能が良い結論になりました。
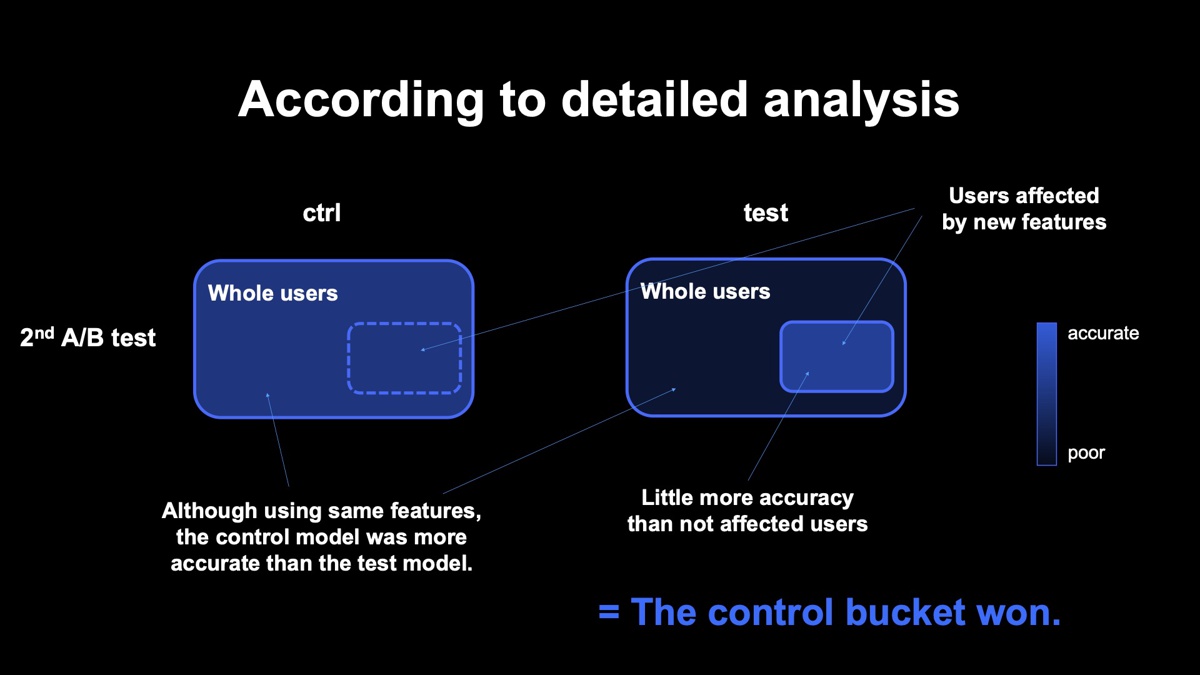
なぜ差が生まれてしまったのかは、モデルの再学習が原因であろうことが後になって分かりました。
1回目のテストでは、追加特徴量を利用した部分以外、両者はほぼ同じ精度のモデルができていました。2回目のテストまでに期間が空いたために、2回目のテスト直前に最新の学習データを用いて両者のモデルを再学習しました。
この再学習の際、テストバケット側の乱数での初期化で、運の悪い乱数シードを引き学習が想定ほどうまくいきませんでした。ほぼ同じアルゴリズムで学習している追加特徴量のないユーザーの部分についても、コントロールバケットほどの精度が出ず、全体として劣る結果となりました。
この件から、「ニューラルネットを利用したモデルは、初期化に用いる乱数に当たり外れがあり、それがモデル全体の精度に影響を与える場合がある」「影響範囲の少ない、一部のユーザーしか持っていない特徴量を使う機能の検証では、本来検証したい機能による差分よりも、乱数の当たり外れによる精度のブレが支配的になり、機能追加による差分が見えなくなる場合がある」という教訓が得られました。
モデル開発を行う場合、モデル開発中にパラメータチューニングを行う際には、複数回実行して、平均を取ったり良いものを選んだりといった検証をします。しかし、一度ハイパーパラメータを決めて運用フェーズに入り、パラメータを何もいじらずにデータだけ定期的に更新していくと、この操作はないがしろにされがちです。
対応策
この事例以降、パラメータの変更や構造のアップデートを含まない、定常的なモデルの自動再学習であっても、1回だけ実行してモデルを更新するのではなく、複数の乱数の初期化を用いて何度か学習を行い、その中で精度比較を行って良さそうなモデルを選んで本番導入するようになりました。
以上、実際に使われている推薦システムのシステム構成や学習方法といった基本的な事に加えて、実際にサービス運用をしていく上で上がってきたいくつかの課題について、事例を交えて紹介しました。参考になれば幸いです。
アーカイブ動画
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました

- 大倉 俊平
- エンジニア
- 第12代機械学習領域黒帯。ニュース記事を扱う各サービスにおけるユーザの行動分析、及び推薦システムを中心とした機械学習モデルの構築・改良をリードする。



