こんにちは。Yahoo!広告にてデータアナリストをしている國吉です。
ヤフーでは、「Yahoo!広告」という広告出稿サービスを提供しており、それに付随して、広告を出稿するクライアントを支援するためのソリューションを提供しています。本記事では、私が開発に携わっている「Yahoo! JAPAN 予測ファネル」(以下、予測ファネル)という広告配信ソリューションについてご紹介します。予測ファネルを開発するにあたっては、ビッグデータを用いて機械学習モデルの作成と推論をするため以下の課題がありました。
- 学習時のメモリリソースの確保、推論時間の短縮が必要
- ソリューションのリリース後には数多くのモデルが作成されモデルの管理が煩雑になる
本記事ではこれらの課題をどのように工夫して解決したかについてご紹介したいと思います。
(※モデル作成にあたり、ヤフーではお客様のプライバシーの保護に細心の注意を払っています。詳しくはYahoo! JAPAN プライバシーセンターをご覧ください。)
予測ファネルとは
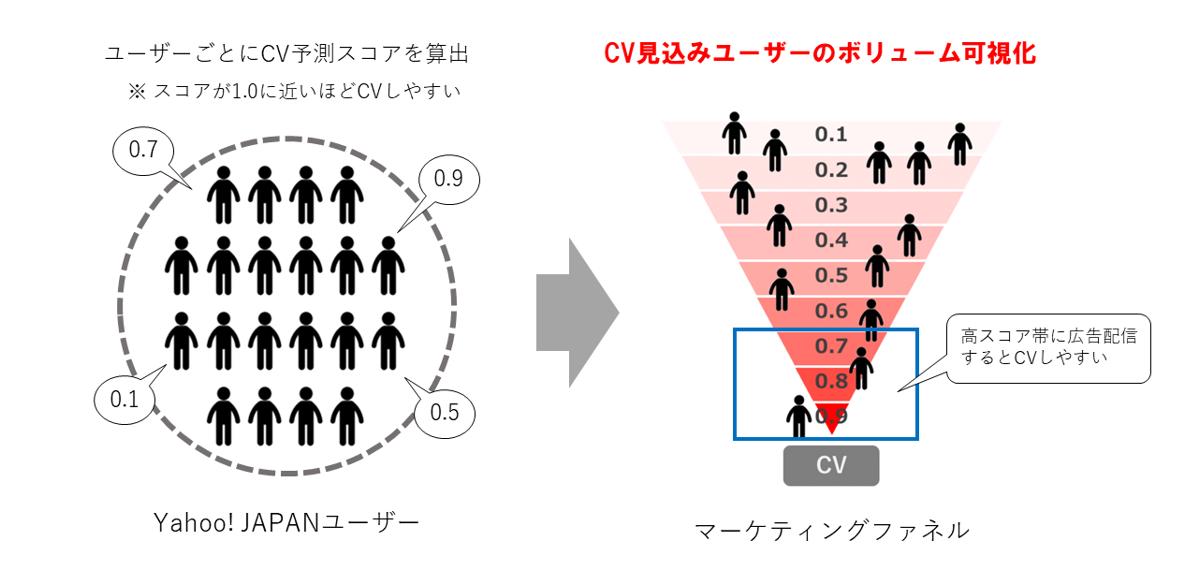
ある商材に対して見込みユーザーがコンバージョン(商材の購買、申し込みなど。以下、CV)に至るまでの行動過程を潜在層、顕在層など段階的に分けるフレームワークをマーケティングファネルと言います。予測ファネルとは、特定の商材に対してYahoo! JAPANを利用しているユーザーがどれくらいCVしやすいのかをユーザーごとに予測、数値化することで、その商材の潜在層、顕在層のボリュームをマーケティングファネルの形で可視化するソリューションです。
ソリューション概要
Yahoo! JAPANでは月間約8,400万のアクティブユーザーがサービスを利用していますが、ある商材Xの広告を配信する際にこの8,400万ユーザの中からやみくもにユーザーを選んで広告を配信しても高い広告効果を得ることはできません。そこで、予測ファネルでは、ユーザーの行動ログ、興味関心、属性などのデータから、ユーザーごとにCVする可能性を予測したスコアを活用して配信します。そして、スコア化した結果をマーケティングファネルに落とし込むことでCV見込みユーザーのボリュームを可視化します。この時、予測ファネルではユーザーが商材をCVする可能性を0~1.0でスコア化しますが、スコアが1.0に近いほどCVする可能性が高くなるため、高スコアユーザーに広告配信することでより多くのCVを獲得することが可能になります。また、ミドルスコアユーザーに広告配信することで商材に関する興味関心の意識を醸成し、将来的にCVするユーザーを育成することも可能になります。このように、予測ファネルを活用することでマーケティングファネル全体に適切な広告配信アプローチができます。
ソリューションの概要についてはクライアント向けの分かりやすい動画も用意してありますので、こちらも見ていただけると記事の内容を理解しやすくなると思います。
ソリューションの仕組み
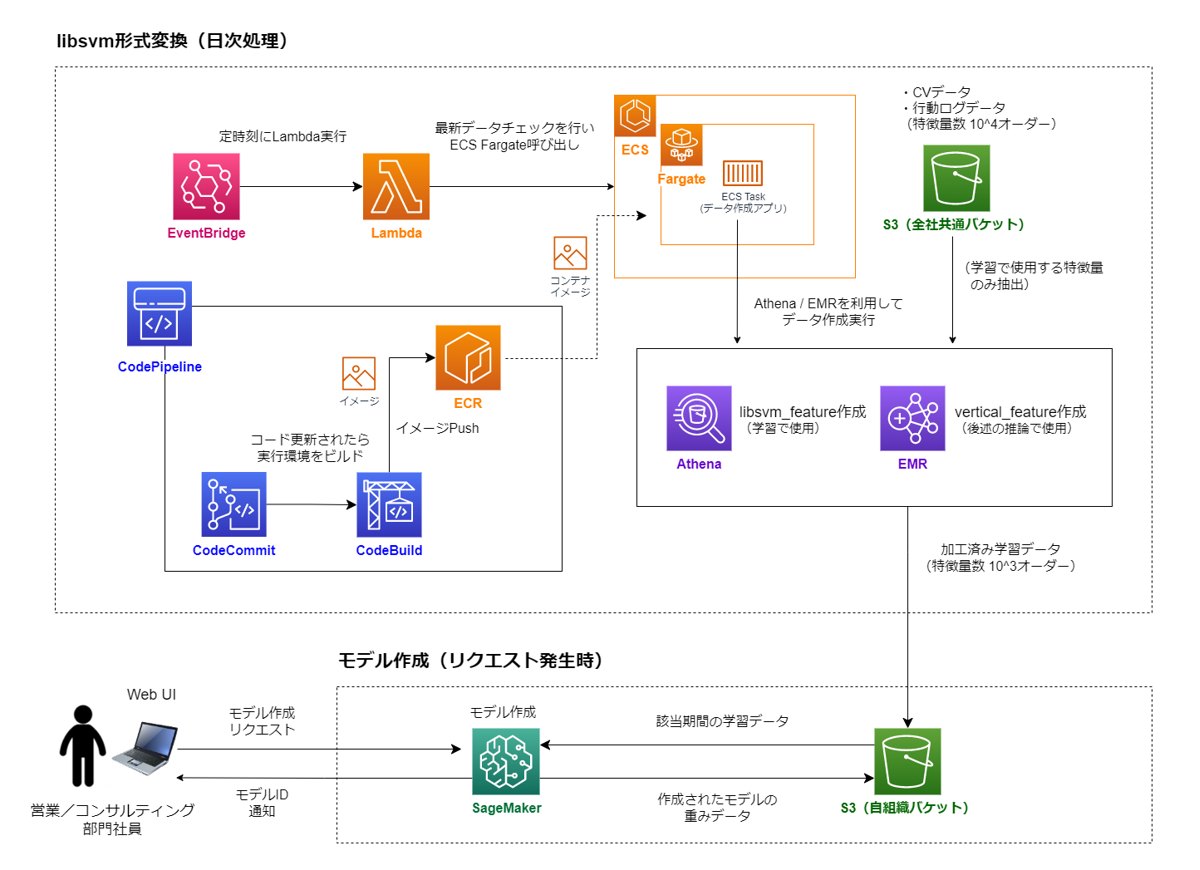
ここからはソリューションの仕組みや技術的な話の説明をしていきます。予測ファネルでは以下のような流れでCVを予測する機械学習モデル(CV予測モデル)を作成しています。
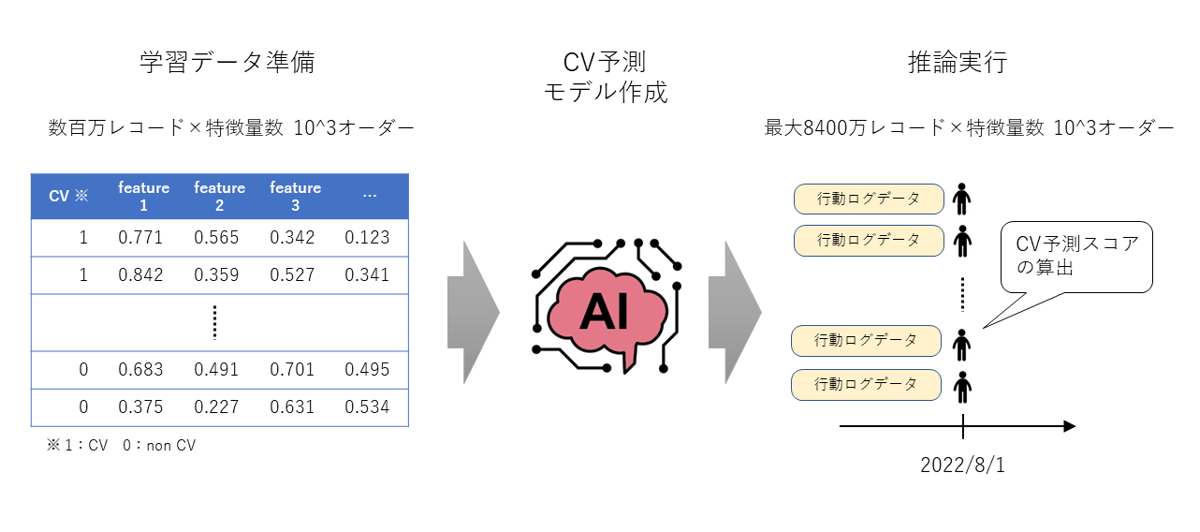
1. 学習データの準備
- ある商材Xに関する過去のユーザーのCVデータ(正例データ)を抽出します(多いもので数百万レコード)。
- CVデータに行動ログデータ(特徴量数は10^3オーダー)をマージします。
ここでマージする行動ログデータはユーザーがCVした時点より1カ月前のデータを抽出します(例えば、ユーザーAが2022/6/15にCVした場合、ユーザーAの2022/5/15の行動ログデータをマージ)。これは言い換えると、「ある時点の行動ログデータとその時点の1カ月後にCVしたかどうかをペアにしたデータ」を学習データとしているということです。 - CVデータと同様にnon CVデータ(負例データ)も抽出し、行動ログデータをマージします。これで学習データの準備ができました。
2022/4/1~2022/6/30のCVデータを抽出する例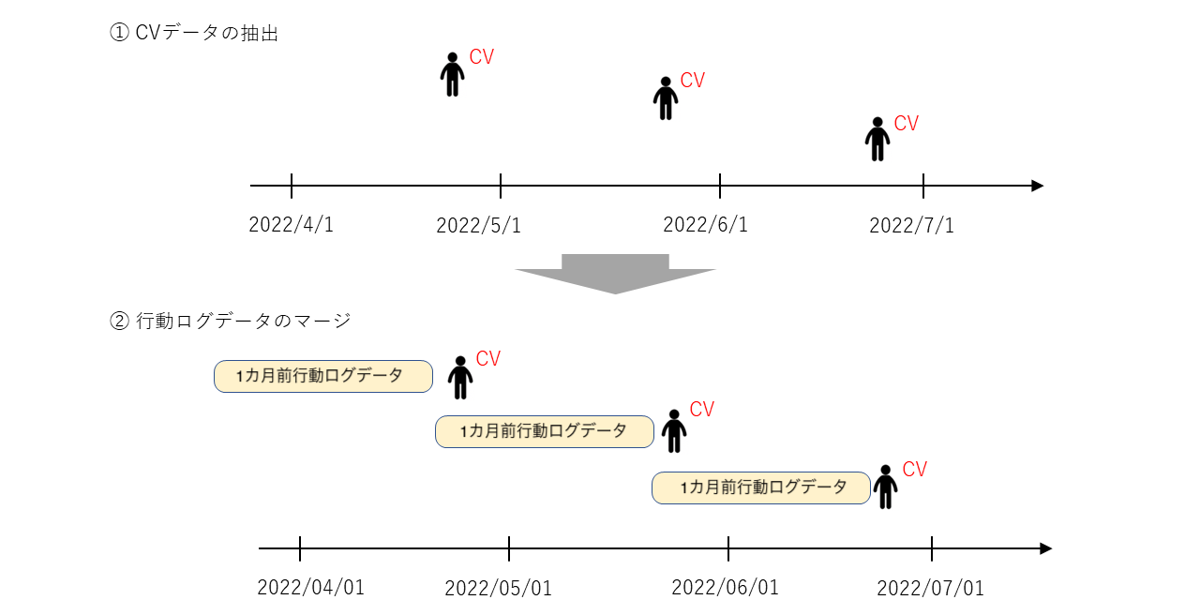
2. CV予測モデルの作成
上記で作成した学習データを用いて、ある時点の行動ログデータから1カ月後にCVするかどうかを予測する機械学習モデルを作成します。
3. 広告配信予定期間のデータに対して推論を実施
最大で8,400万ユーザーに対して推論(CV予測スコアの算出)を実施します。(図の例では、8月に配信する広告の配信ユーザーを決めるためにCV予測スコアを算出しています)
4. Web UIからのモデル作成、推論リクエスト
営業部門、コンサルティング部門の社員がソリューションを簡易に利用できるようにするため、ソリューション専用のWeb UIを設けており、社員が自由にモデル作成や、作成したモデルを使用して推論できる運用体制になっています。
予測ファネルの実現に向けた課題と工夫
予測ファネルのソリューション開発をするにあたっては、モデル学習時のメモリリソースの確保、推論時間の短縮が必要などの課題がありました。また、ソリューション化することで数多くのモデルが作成されることが予想されるため、モデル作成後のモデル管理方法が課題になると想定しました。
以降ではこれらの課題をどのように工夫して解決したかについて説明します。
課題1 : CV予測モデル作成に用いる学習データは多いもので数百万レコード、特徴量数が10^3オーダーと非常に大きいデータのためこのままモデルの学習を行うと膨大なメモリリソースが必要になる
ソリューションを開発するにあたってはAWS上でSageMakerインスタンスを立て、モデル作成のリクエストがあった際にモデル作成が開始する仕様になっています。つまり、常時稼働しているソリューションのため、メモリ量の多いハイスペックなインスタンスを常時稼働していると莫大なランニングコストが掛かってしまいます。
解決方法: 特徴量として用いる行動ログデータのlibsvm形式への変換
libsvm形式へ変換するためにAWS上で、もともと横持ちのデータとしてS3に格納しているデータをlibsvm形式に変換する前処理を実施しています。
libsvm形式とは
あまり聞いたことがない人も多いかと思いますが、libsvm形式とは以下のようにラベルと特徴量id:値で記述されたデータフォーマット形式です。DataFrameの場合、scikit-learnのモデルでの学習で使用できるようにするために密行列としてデータを保持しますが(行動のない項目には「0」が入る)、libsvm形式の場合、行動していないログについては値ゼロになりデータとして載ってこないため、この分、ファイル容量を抑制できます。
詳しい仕様は以下をご参照ください。(外部サイト)
https://www.csie.ntu.edu.tw/~cjlin/libsvm/
DataFrameとlibsvmの例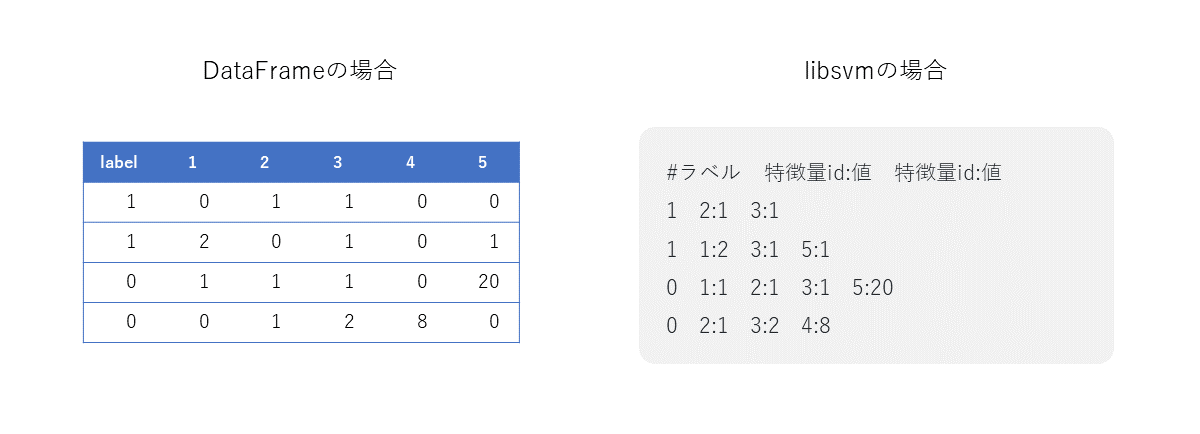
libsvm形式データでのモデル学習例
scikit-learnライブラリのload_svmlight_filesを使用してlibsvm形式のファイルを読み込めば、以降は通常のscikit-learnに搭載されたモデルを学習するのと同様の手順でモデル作成が可能です。
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_svmlight_files
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_auc_score
# 学習データの読み込み、分割
X, y = load_svmlight_files("train.tsv")
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
# モデルの学習
clf = LogisticRegression(random_state=42)
clf.fit(X_train, y_train)
y_pred = clf.predict_proba(X_test)[:,1]
auc = roc_auc_score(y_test, y_pred)
print(f"auc : {auc}")モデル作成におけるAWSアーキテクチャ
下図のAWSサービス構成で行動ログデータのlibsvm形式への変換処理や、モデル作成を実施しています。
行動ログデータのカラム数が非常に多く、クエリがAthenaで対応できる最大クエリ長を超えてしまうこと、分散処理(Apache Hadoop、Apache Sparkなど)により処理時間を短くできるためEMRを使用し、一日一回走る処理であることから、ランニングコストを抑えるためにサーバレスなFargateを用いています。
効果
libsvm形式に変換することで得られる効果は扱うデータにより異なりますが、予測ファネルで扱っているデータの場合、libsvm形式にすることでファイル容量をlibsvm形式変換前の3分の1以下に抑え、モデルの学習時に必要なメモリリソースも大幅に抑制することができました。
課題2: 作成したCV予測モデルでの推論対象が、多い場合で約8,400万ユーザーであり推論に非常に時間がかかる
今回はユーザーが商材に対してCVするかしないかを分類する問題であるため、ランダムフォレストなどの決定木モデルを使用することも可能です。しかし、決定木モデルでは膨大な推論時間がかかってしまうため、1日にいろいろなクラアイントの推論リクエストが入ると推論結果が出るのが次の日になるようなケースも発生してしまいます(複数インスタンスを起動することで対応も可能ですがランニングコストが多く掛かります)。
解決方法: ロジスティック回帰モデルを採用し、かつ推論をAthena上でSQL処理させることで高速推論を実現
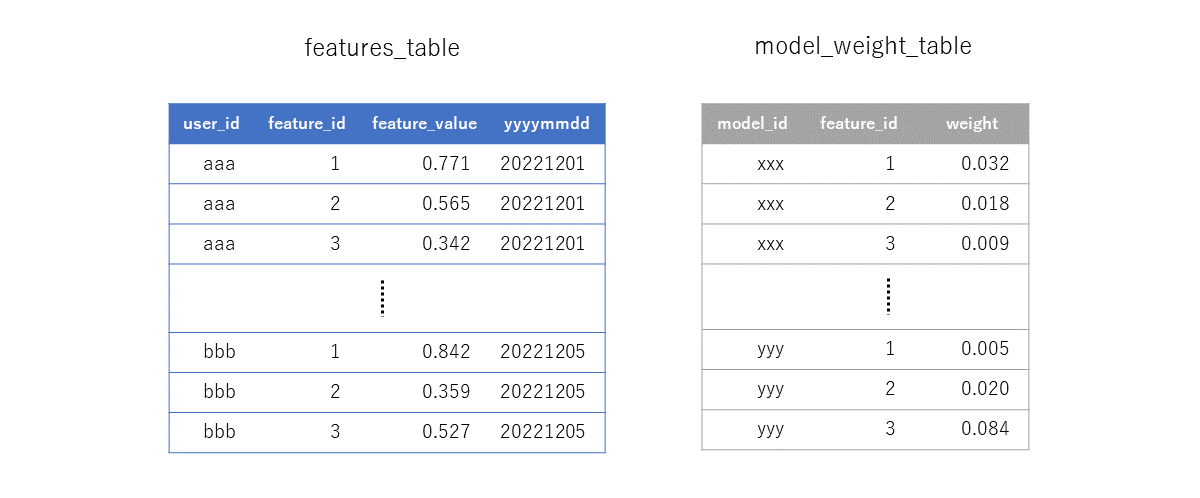
推論に時間のかかる決定木モデルなどは使わず、推論の速いロジスティック回帰を採用し、さらにAthena上で推論をSQL処理することで高速な推論を可能にしました(ロジスティック回帰モデルでも商用に耐えうる予測精度を担保できることも確認済み)。なお、SQLを用いた推論処理では縦持ち形式に変換した行動ログデータを使用します(学習用のlibsvm形式データ作成の際に縦持ち形式データも作成しています)。
ユーザーごとにCV予測スコアを算出するSQL例
使用するテーブル:features_table(縦持ち形式)とmodel_weight_table
(参考)ロジスティック回帰の確率式
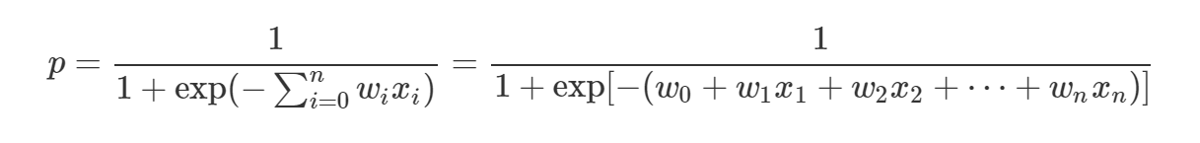
下記SQLの★印の行で上記のロジスティック回帰の確率計算を実施
select
user_id,
1/(1 + exp(-sum(weight*feature_value))) as score --★
from
features_table
inner join
(
select
feature_id,
weight
from
model_weight_table
where
model_id = {model_id} -- Web UI上で指定したモデルIDがここに入る
) using(feature_id)
where
yyyymmdd = {yyyymmdd}
group by
user_id
;効果
- CV予測スコア算出のための推論を、ロジスティック回帰を用い、推論処理をAthena上のSQLで行うことで、推論時間をおよそ1分に短縮することができました(1分は5000万ユーザーに推論した場合の時間)。参考に同じユーザー数に対して、Python上でscikit-learnのRandom Forestモデルを用いて推論する場合は2時間以上はかかります。
- SQLで推論できるため、データを保持することなく推論することが可能になり、データのIOを簡素化できました(仮にSageMakerやEC2で推論する場合、推論用データをS3やEBSに推論の都度、格納しないといけない)。また、SQLで他のテーブルと突合してユーザごとのスコアを活用した報告レポートの集計を柔軟に実施したり、コンサルティング部門社員がそのSQLをカスタマイズして別の集計に活用できるようになりました。
課題3 : ソリューションのリリース後にさまざまなCV予測モデルが作成され、各モデルの管理が煩雑化する
予測ファネルでは、Web UIから営業部門、コンサルティング部門社員がクライアントのCV予測モデルを自由に作成できることで社員が各自でモデルIDを管理するのが困難になることが予想されました。
解決方法: モデル作成時のログやモデルごとの月次予測精度の推移を確認可能な管理ページを用意
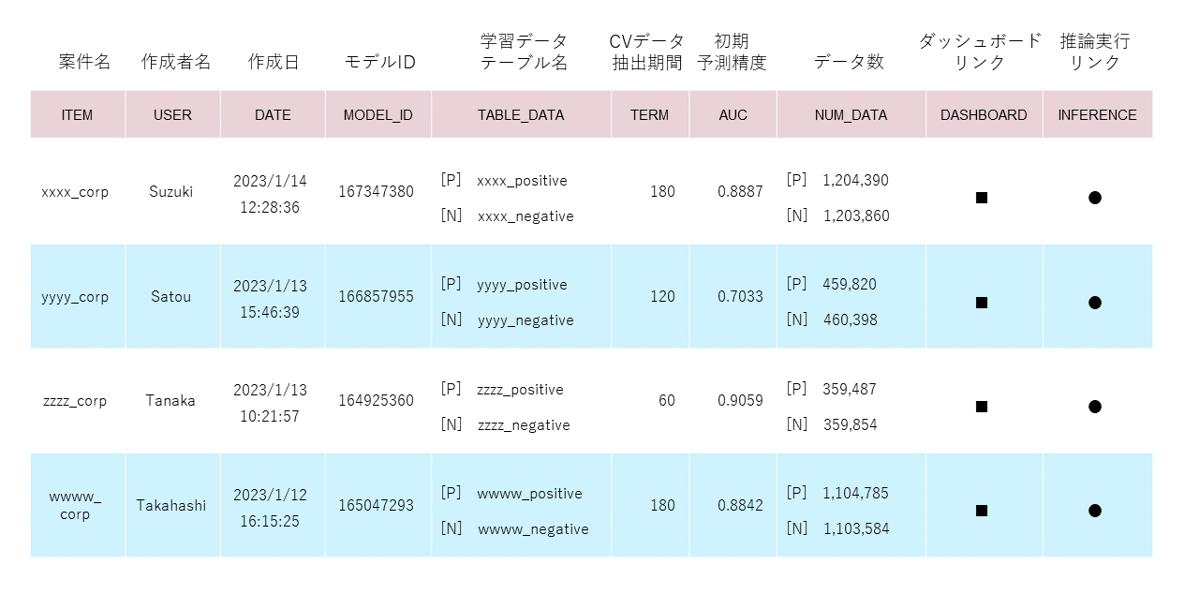
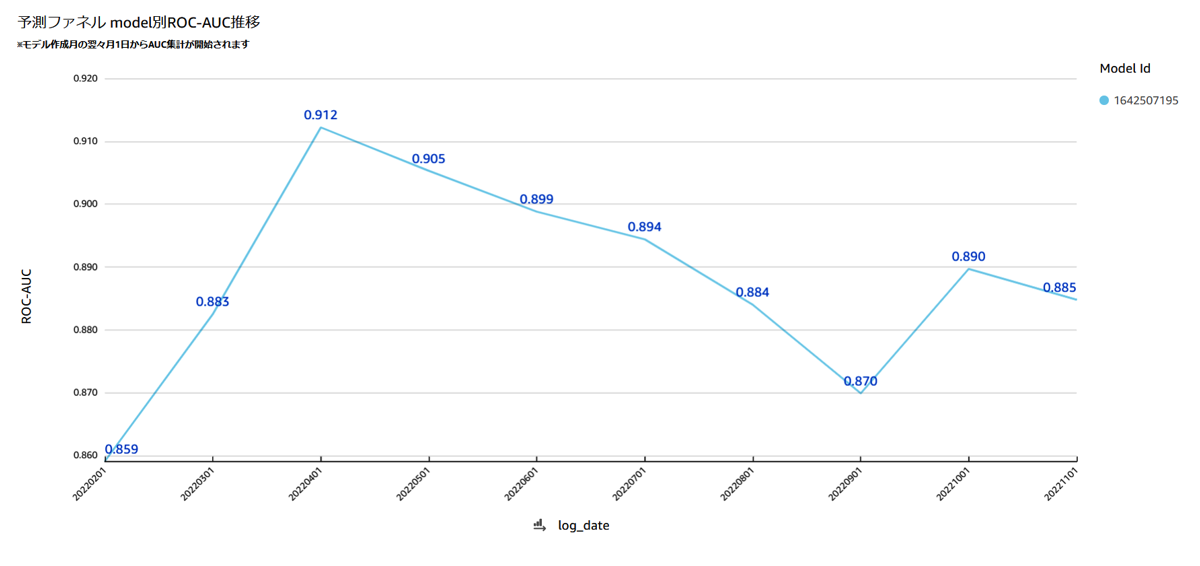
予測ファネルがソリューション化してから、これまでさまざまなクライアント、商材のCV予測モデルが作成されており、モデル数は1000を超えています。これらのモデルが、どのクライアントのどの商材向けのモデルなのか、学習に用いたデータ数がいくつだったか、時間経過に伴う予測精度の推移はどうなっているか、などを管理ページ上で一元的に確認できるようにしました。予測精度の推移については、毎月これまで作成した全モデルに対して予測精度の確認を実施し、その結果をAmazon QuickSight上のダッシュボードでモニタリングできるようにしています。なお、予測精度モニタリングにおいては、特定のルールに基づき計算された基準値を2カ月連続下回った場合は、モデルを再作成することを推奨しています。
モデル作成ログ管理ページ(イメージ)
これまでに作成された1000以上のモデルの作成ログを以下の表イメージのように掲載
※モデルID:社員がモデル作成した際にモデルごとに発行されるID、推論時のモデル呼び出しで利用
モデル予測精度ダッシュボード
これまでに作成されたすべてのモデルの予測精度を月次で計測(ダッシュボードはQuickSightにて作成)
効果
過去に作成したモデルの現時点での予測精度を簡易に確認できることで、「過去に作成したモデルの予測精度が劣化していることに気づかず、誤って広告配信ユーザーの選定に精度劣化したモデルを使用してしまう」というような広告配信事故の発生抑止につなげられています。
今後の取り組み
予測ファネルをより良いソリューションにするために以下の取り組みを現在実施しています。
- CV予測モデルの予測精度の向上
- 現行のソリューションでもモデル作成時に非常に多くの特徴量(行動ログ、趣味関心データ、属性データ)を使用していますが、まだ組み込めていない特徴量が多くあったり、特徴量同士を組み合わせて、精度に寄与する2次特徴量を作る余地もまだまだあるため、これらを実施していきます。
- 他のモデルの適用検討
- 現行では高速な推論実施のためにロジスティック回帰モデルを用いていますが、その他にも、SQL上でより予測精度の高いモデルで高速に推論できる方法がないかを検討しています。
おわりに
今回は、広告配信ソリューションである予測ファネルについてソリューションの概要と、ソリューション開発するにあたり工夫した点を以下の通りご紹介いたしました。
- libsvm形式データによるモデル作成時のメモリリソースの抑制
- ロジスティック回帰モデル、SQL処理による高速な推論の実施
- 管理ページ上でのモデル作成ログ管理や予測精度モニタリングの実施
社会的にもデータサイエンスへの興味関心が高まっている昨今、企業でビッグデータを用いた機械学習ソリューションを開発するケースも多くあると思いますので、今回の記事をひとつの参考にしていただけると幸いです。
Yahoo!広告では、今回紹介したソリューション以外にも、データマーケティングソリューションと呼ばれるクラアイント支援ソリューションを数多く用意しています。私のチームで開発しているソリューションの他の記事も、ぜひご覧ください。
- 協力ゲーム理論を活用した広告効果分析(シャープレイ値で広告貢献度の公正な分配を実現)
- 大規模言語モデルを使って広告文を自動生成する
- 機械学習でコンバージョンにつながるキーワードを予測する(学習データ不足でも推論可能にする工夫)
最後まで読んでいただきありがとうございました!
参考
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました

- 國吉 翔平
- データアナリスト
- Yahoo!広告のデータマーケティングソリューション開発に従事しています。Kaggleへの参加や技術記事の執筆が趣味です。
-



