「UPDATE 不正対策 〜誰もが安心できるeコマースを目指して〜」と題して、eコマースにおける不正対策の必要性について紹介します。
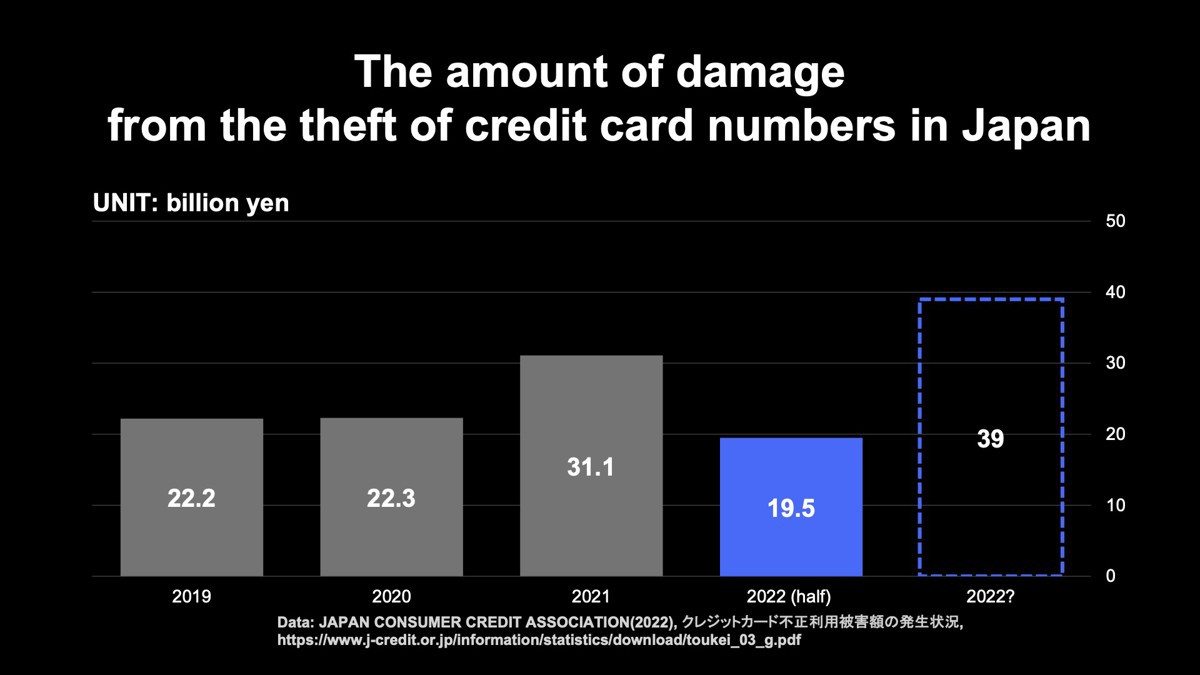
人間の日常はデジタル化しており、コンピュータやスマートフォンを1日に1回も触らないことはなくなりました。日本クレジット協会が発表する「クレジットカード不正利用被害額の発生状況」によると、非対面取引でのカードの番号盗用による被害額は増加しており、2021年には過去最悪の311億円を記録しました。さらに2022年の1月~6月の半年で既に195億円の被害が発生し、過去最悪だった2021年を超える見込みです。
このように、生活のデジタル化に伴い、不正者にとっての格好のターゲットが、eコマースにシフトしているという背景があります。
フィードバックループで不正検知を迅速化
不正はクレジットカード関連に限ったものではありません。W3Cの不正対策コミュニティグループがリストしている不正種別を見ると、eコマースが対策すべき不正は多岐にわたっています。例えば、アカウントの乗っ取りや、サービスの利用規約への違反も不正にあたります。また不正の手口は常に変化していきます。
このように種類が多く、変化が速い不正に対抗すべく、ヤフーでは独自の不正対策システムを開発しています。これはシステムと人が連携した汎用性の高い仕組みです。不正を検知するシステムを中心に、審査を行うチーム、データを分析してルールを管理するチーム、機能開発を行うチームが全て社内に存在し、これらが連携しながら、常に変化する不正への対策をアップデートしています。
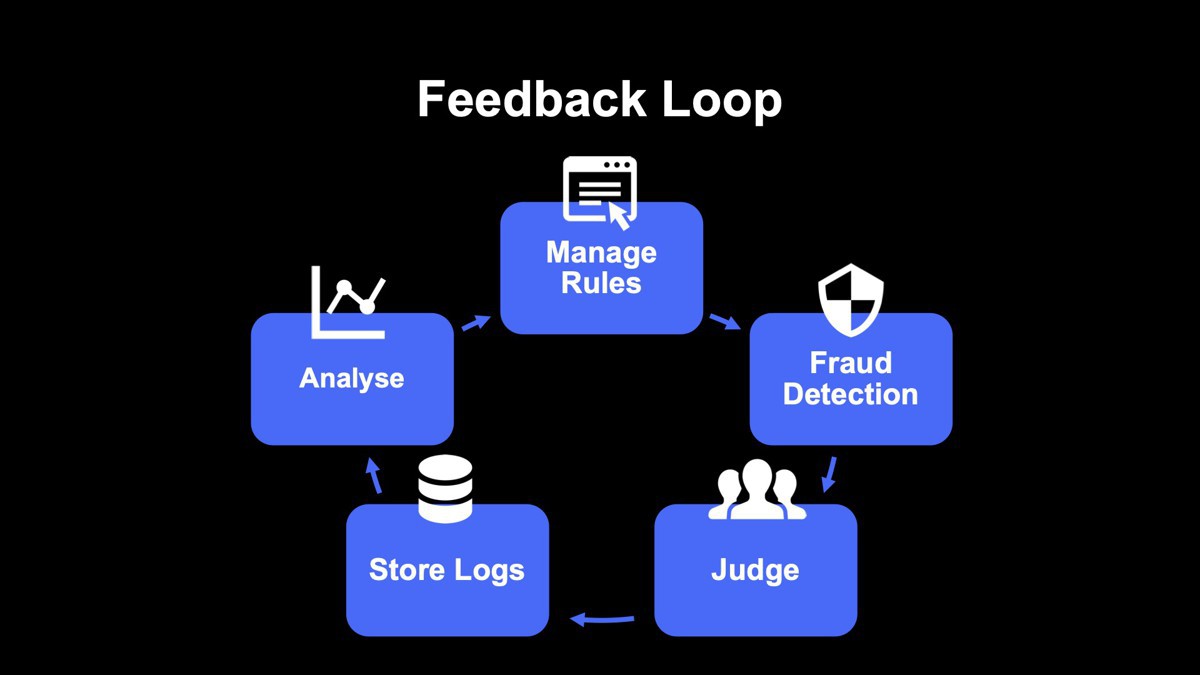
具体的には、フィードバックループを形成して連携・アップデートを行っています。まずは、不正検知を行うためのルールを設定し、不正検知システムがリアルタイムに自動的に不正判定を実施します。ここでシステムによる機械的な判定が難しい場合は、専門の審査チームにエスカレーションした上で、人の目で審査を行います。
そして、不正検知システムの判定ログと、審査チームの目視審査の記録を社内のデータウェアハウスにためていきます。そのデータを基にレポーティングを行い、これを参照しながら随時ルールを改善していく流れになっています。
不正対策システムの変遷と進化
このフィードバックループがいかにして形成されてきたのかを解説します。2014年ごろは不正アクセスへの対抗策として、例えばIPをブロックするような共通基盤はありましたが、サービス単位での不正対策ロジックは、サービスごとに実装するしかありませんでした。
本質的なビジネスロジック以外の不正対策の部分もサービスのコードに組み込まれている状態では、不正対策のロジックが複雑になればなるほど、見通しが悪くなりますし、エンジニアの対応コストも増加してしまいます。
そこで誕生したのが、初代の不正検知システムです。クライアント・サーバ形式のディナイリスティング(Deny-Listing)システムで、サービスごとの組み込みロジックや、統計的・機械学習的手法による学習機能を有し、特定のタスクに特化した機械学習モデルも搭載が可能でした。
初代の不正検知システムによって改善されたことが4つあります。1つめはサービス実装と不正対策ロジックの分離が可能となったこと。2つめはサービスごとのロジックのチューニングが可能となったこと。3つめは学習機能による柔軟な検知が可能となったこと。4つめは1トランザクションあたり2ミリ秒という、非常に高速な判定が可能となったことです。
ただし課題も残りました。サービスのコードから分離はできたものの、不正検知のロジックはハードコーディングされたままでした。また、不正検知システム側の機械学習モデルの更新コストが高く、検知対象の変動に対応しづらかったり、関連するサブシステムを含めて検知した不正の通知をする方法が多様で、審査メンバーがいろいろな場所を見に行く必要があったりといった状況でした。
これらの課題を解消するべく、後継のシステムでは決済トランザクションに対してルールベースの判定を行うWeb APIへと、大きく構造転換を行いました。
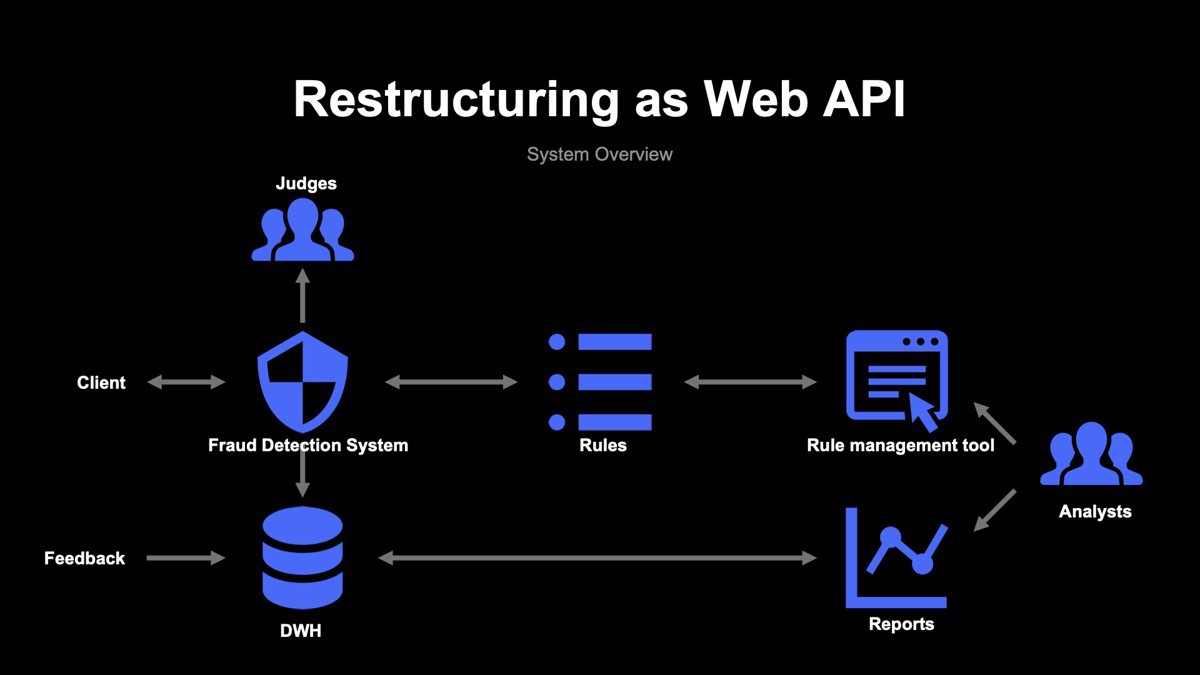
まずは、専用のWebツールを使用してルールを登録できるようにし、不正検知システムは随時ルールを読み取ってリアルタイムに不正判定を行います。ルールを保存するデータベースにはApache Cassandraを採用し、半構造化データであるルールについて、高速なデータのやりとりを実現しました。
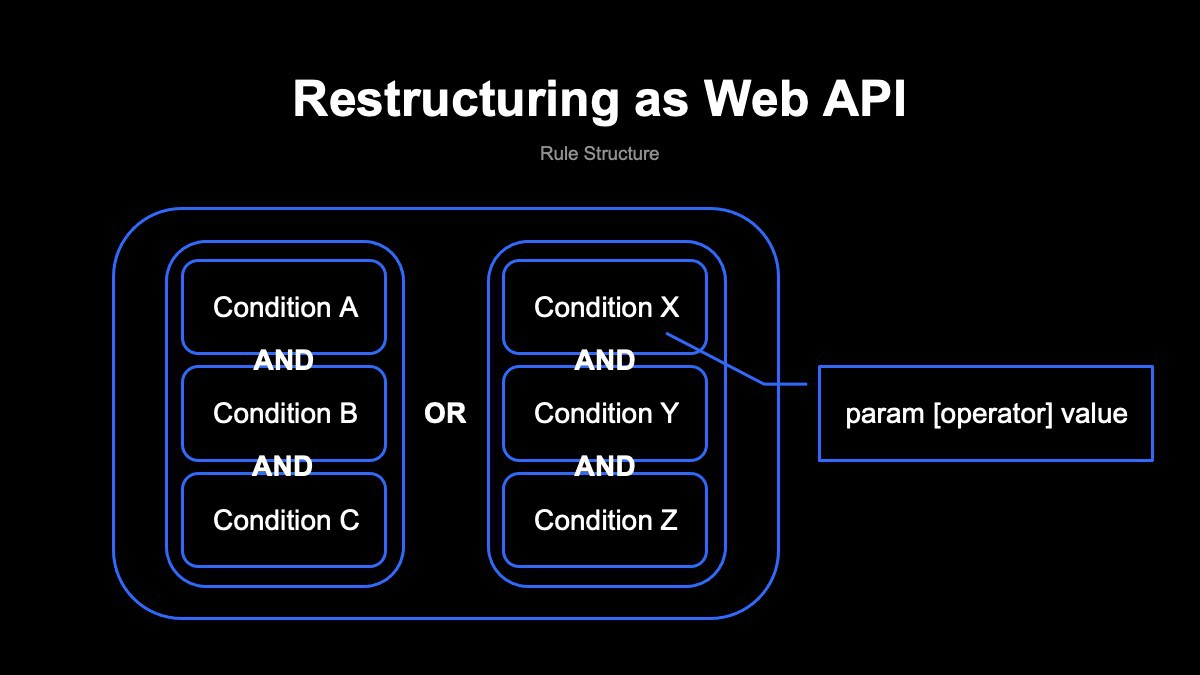
使用しているルールの構造について補足します。ルールは条件としきい値で構成され、複数の条件をAND、ORの論理演算子で組み合わせた形となっています。この構造によって、1つのルールに対して複数の条件設定が可能となり、柔軟なルール設定ができます。
Web APIへの構造転換によって、クライアントライブラリのインストールが不要になりました。そして、サービス側で不正判定ロジックが変更されたり、新たな手口の不正が発覚したりした場合などにも、即座に対応できるようになりました。
さらにサブシステムで判定していたものも含めて、1つのシステムに不正判定のロジックを集約することで、審査を行うメンバーの負担も緩和することができました。ただし、ルールが手動で管理されているという点については、課題が残っています。
人間が管理するルールベース判定で考えられる課題は、そもそも手動での管理が煩雑であること、ルールが高度になるほどルールの管理が暗黙知化してしまうこと、数多くのパラメータを組み合わせて不正を見つけ出すには人間では限界があることです。つまり、ルールを管理しやすくする、もしくはルールの管理を不要にするといった改善が必要です。
この課題に対して、機械学習とルールの融合、そしてデータドリブンなルール運用の2軸で解決を図りました。
ルールの自動化:機械学習とルールの融合
まず1つ目の軸、機械学習とルールの融合についてです。一度、不正判定の文脈の上で前提を整理します。不正判定では、不正なトランザクションを不正と判定することも大切ですが、正常なトランザクションを不正と判定しないことも同じく大切です。また、不正判定を行うにしても高い説明性が求められます。「自分たちが何を不正として見ているのか」がブラックボックス化してしまうと、たとえそれが本当に不正だったとしても、根拠を持って止めることができません。
つまり、不正判定に機械学習を導入するためには、偽陽性の判定を極力抑えて推論の説明性を担保しなければなりません。この前提のもと、主に3つの要素で機械学習を取り入れています。1つ目は「機械学習によるルールの自動生成と管理」、2つ目は「ルールのパラメータとしての機械学習」、そして3つ目が「不正傾向の変化に追従するためのモデルの自動更新」です。
1つ目の「機械学習によるルールの自動生成と管理」は、データウェアハウスに格納された過去の不正データを活用し、機械学習を用いて不正判定ルールを自動で生成して管理する機能です。
ここで採用しているアルゴリズムは決定木です。過去の不正データから決定木モデルを作成し、さらにそのモデルからジニ不純度の低いノード、つまり正確に不正を分類できているノードを選定します。そして選定したノードまでの分岐情報を抽出した後、ルールとして変換します。こういった方法で高い適合率と説明性を担保しています。
この機能によって、過去のデータに基づいたルールの更新を自動で行えますので、複雑なルールを手動で管理するコストを削減できます。決定木のモデルをそのまま使用するのではなくて、あくまでルールベースにシステムに融合させることがポイントです。既存の枠組みの中で、機械学習のうまみを活かすことができるわけです。
2つ目の「ルールのパラメータとしてのモデルの推論」は、勾配ブースティング決定木を採用し、モデルの推論スコアをルールのパラメータとして使用できるようにする機能です。
これにより、人間が管理する任意のルールに対して機械学習の推論を組み込むことが可能になります。こちらもモデルの出力をそのまま使用するのではなく、あくまでルールベースの体系の中で使用することがポイントです。
どの程度のスコアで検知対象とするのかを自由に調整できるようになりますし、他の条件と組み合わせたルール設定も可能になります。ルール自体はすぐに更新できますので、モデルのスコアに対してもリアルタイムな判定結果の変更ができるわけです。
この機能を実現するために、不正検知システム専用の推論APIを立てています。性能要件を満たすためにJavaのアプリケーション上でモデルの推論を行う必要がありましたが、勾配ブースティング決定木のライブラリであるYandexのCatboostを利用することで、Pythonでモデルの開発を行ってJavaで利用するという条件をクリアしています。
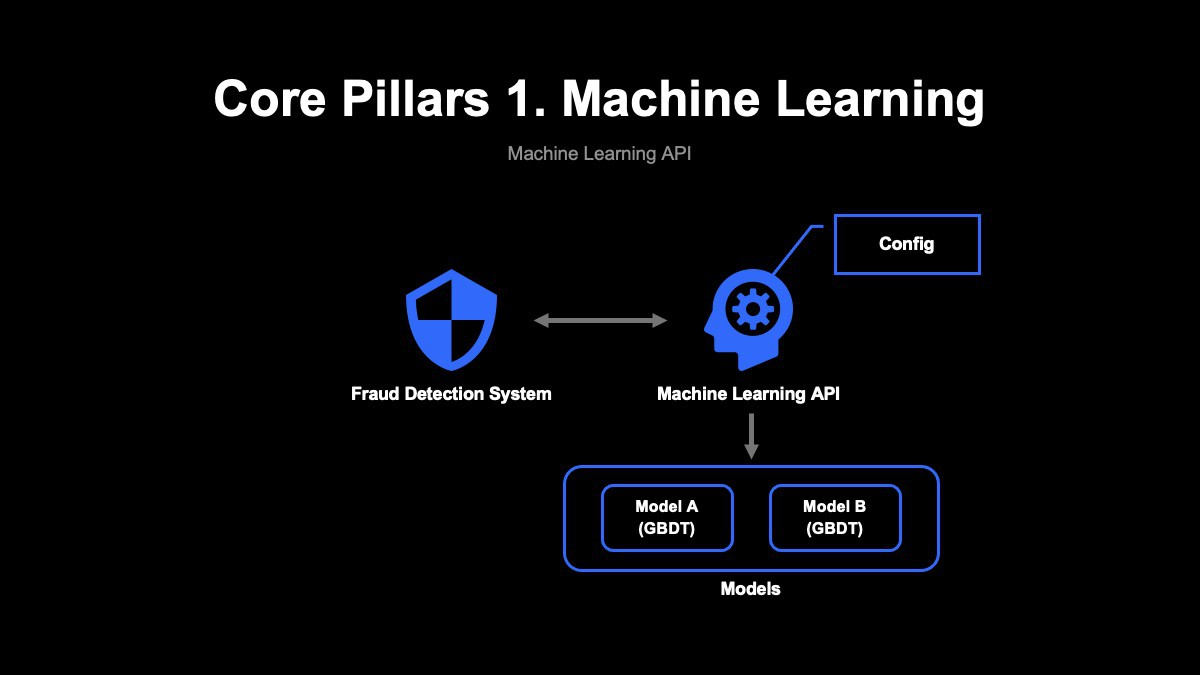
またこの推論APIは、不正検知システム本体とは疎結合なインターフェースを持っています。例えば不正検知システムのパラメータが変更されたり、推論API側のモデルが増えたりといった場合にも、互いに影響を受けません。
さらに、推論API自体もモデルの内容と疎結合なインターフェースを持っているので、設定ファイルを少し変更するのみで柔軟にモデルを搭載したり、または除去したりすることが可能です。 ただし、採用アルゴリズムが勾配ブースティング決定木であるという性質上、ユーザー入力などテキストベースのパラメータが推論に使用しづらいという課題が存在しています。
テキストベースのデータも活用するため、ユーザー入力のテキストを使用し、不正判定のスコアリングを行うというモデルをTensorFlowで構築しています。これにより、不正に狙われやすい商品などに関する人間の暗黙知を数値化するとともに、ルールの中に手動でテキストを羅列していくといった操作を代替できます。
TensorFlowのモデルに関しては、勾配ブースティング決定木モデル用に構築した自前の推論APIには搭載できないので、社内のマネージドなモデルサービング用プラットフォームであるCuttySarkを活用することで、運用コストを抑えながら、TensorFlow Servingでの高速な推論を実現しています。
3つ目の「不正傾向の変化に追従するためのモデルの自動更新」です。不正の手口は常に変化しているので、同じモデルをしばらく使用していると、新たな手口を知らない状態のモデルの推論は現実と合わなくなってしまい、劣化してしまいます。
単純に商品の流行り廃りで不正の傾向が変わることもあるのですが、モデルの推論自体も不正判定のルールに使用されているので、不正者にとってはモデルも回避の対象です。これを自動更新することで、変化する不正傾向に柔軟に対応できます。
ここまで紹介してきたように、自動でのルール更新、パラメータとしての推論スコア利用、そしてモデルの継続的な自動更新をもって、不正検知システムを機械学習の面からアップデートしています。
ルールの自動化:データドリブンなルール運用
2つ目の軸である、データドリブンなルールの運用について紹介します。データの分析や活用も、不正対策を継続的にアップデートするためには重要です。人間によるルールの運用に関しての課題をもう一度おさらいします。
手動での管理が煩雑であることについては、機械学習を融合させる手法で解消を図りましたが、まだ解消できていない課題があります。1つはルールが高度になればなるほど、管理が暗黙知化してしまう問題です。例えばルールを設定するといっても、何を設定するべきかは熟練が必要ですし、過去の不正情報だけでなく担当サービス以外の不正情報も知っていないと、最新の不正傾向に追従したルール管理は難しくなります。
もう1つの問題は、人間が数多くのパラメータを組み合わせて不正を見つけ出すことには限界があるということです。パラメータが数個であれば対応もできますが、システムが抱えるパラメータの数は膨大です。
これら残った課題に対して不正対策システムに加わったアップデートを紹介します。
まず運用の補助として、「不正なキーワードのランキングレポート」。そしてシステム面では、「ネットワーク分析を利用したディナイリスティング」、「全社データベースとの連携」が加わりました。
1つめの「不正なキーワードのランキングレポート」は、名前の通り、不正に狙われた商品に関係するキーワードの頻出度ランキングを算出するレポートです。ルールを管理しているメンバーは、具体的にどういった商材が狙われ始めているのか、または旬が過ぎてしまったのか、もしくは商材にこんな共通点があるということを、このレポートを見るだけで視覚的に把握できます。
各個人の頭の中にしかなかった傾向を数値化することで、根拠を持って不正検知のルールの管理に臨むことができるわけです。
次の「ネットワーク分析を利用したディナイリスティング」は、不正決済のネットワーク分析を行い、複数の不正決済にひもづく項目について自動でディナイリストを作成し、それを継続的に更新する機能です。懸念のある項目にひもづく決済を自動的にブロックすることができ、この機能によって、不正決済間の共通点を人間が見いだして、ディナイリストを手動で更新していく煩雑さを解消しています。
3つめの「全社データベースとの連携」について。ヤフー社内には、匿名化されたユーザーデータを全社横断的に活用するためのデータベースプラットフォームが存在しています。これによって、ユーザーデータをサービス横断で活用することが可能です。
また、全社的な不正の情報を共有するためのデータベースプラットフォームも存在しており、これを活用することで、他のサービスで不正に使用されたパラメータであるかどうかを判別することが可能です。ここでは、これら2つを全社データベースと表現します。
全社データベースとの連携を開始する前は、不正検知システムの利用サービスごとに、そのサービスが流すトランザクションの中にある情報でルールを設定するしかありませんでした。別のサービスで不正に使用されたパラメータを設定したい場合には、自分でデータを入手して手動で設定するしかなかったのです。
また、トランザクションの中にあるパラメータしか判定に使えないという課題もありました。例えば、そのユーザーがサービスを問わず、過去に不正を働いたことがあるかということもわかりません。全社データベースを活用することで、決済を行ったユーザーアカウントや過去の不正にひもづく情報が利用できます。
これによって、アカウントベースで怪しい動きがないかどうか、過去の不正にひもづくパラメータがないかどうかといった観点のルールを設定できます。つまり、事後の分析ではなく、リアルタイムに過去のデータを用いた不正検知ができるようになりました。怪しいユーザーのリスト、怪しいパラメータのディナイリストのようなものも、人間による手動管理は不要となりました。
決済トランザクションをまたいだ不正検知にも注力
ここまでをまとめると、ルールベースの不正検知システムは、人間によるルールの管理そのものが課題でした。そこで暗黙知が生まれやすい高度なルール管理、複雑なパラメータの分析、そして過去のデータとの照合、これらをシステムの仕組みとして持つことで、人間の負担を極力減らしたうえで、不正判定ルールをアップデートし続けることができるようになりました。
ここまでルールベースの不正検知システムと機械学習の融合、そしてデータドリブンなルール運用について紹介してきました。不正検知システム自体の機能強化とルール管理の利便性向上は、どちらも不正対策の文脈で欠かせないものです。どんなに素晴らしい機能を搭載したシステムでも、ルールを管理しづらければ対応が遅延しますし、逆にどんなにルールを管理しやすくしても、システム自体にできることが少なければ柔軟性に欠け、やはり後手の対応となってしまいます。そのため、システムと人のそれぞれに目を配りながらアップデートしていくことが重要です。
もう1つ。さらなる改善として、最近始まった新たな取り組みを紹介します。これまで紹介してきた不正検知システムは、決済のトランザクション、つまり単発の決済試行に関しての不正検知でした。不正検知システムにさまざまな機能を追加してはいるものの、それでも残念ながら見逃しは発生します。
不正者は、今までの手口が止められれば別の手口を試してきますし、単発だと不正に見えないような手口も存在します。このすり抜けを止めるためには、決済トランザクションをまたいだ不正検知が必要になります。これはもともと審査を行うメンバーによって目視で行われていた手法で、一定の成果が得られていたものでもあります。
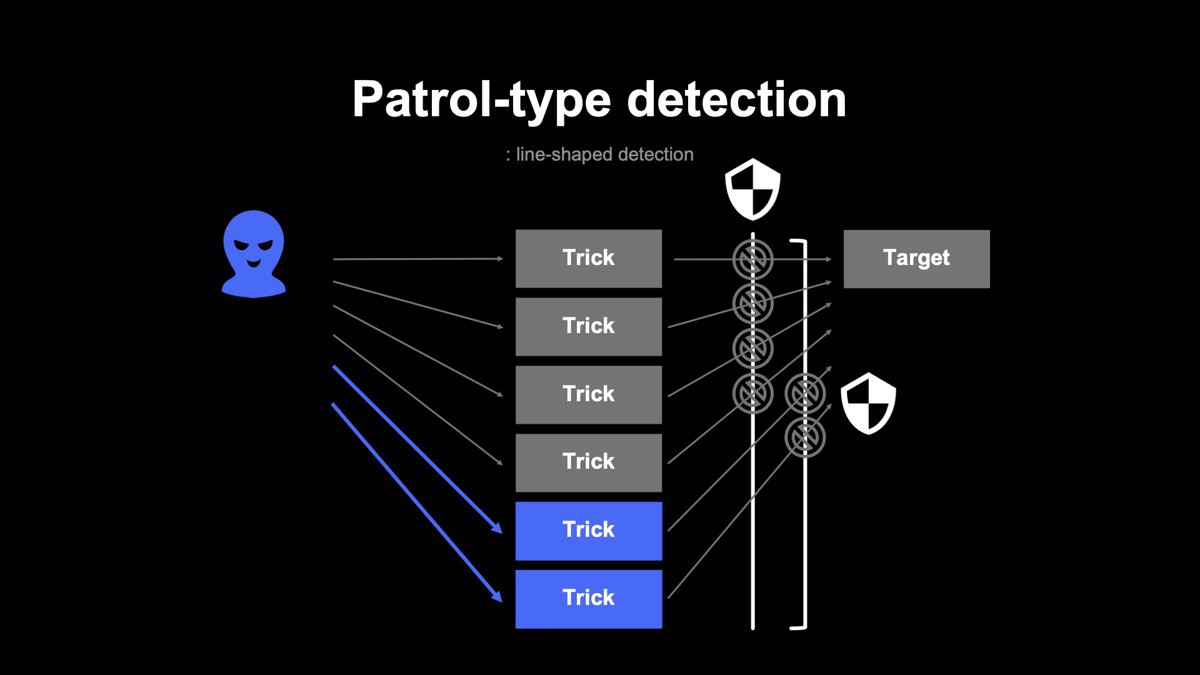
決済トランザクションをまたいだ不正検知をシステム化するべく、巡回型検知の導入に取り組んでいます。具体的には、不正検知システムの判定ログを利用して、複数トランザクションを横断しながら不正検知を行う機能です。自動で巡回して、短期のログを用いて非リアルタイムに不正検知を行う仕組みです。
この機能によって、単発のトランザクションに対する「点の検知」から、複数のトランザクションをまたいだ「線の検知」が可能になりました。
誰もが安心して利用できるeコマースへ
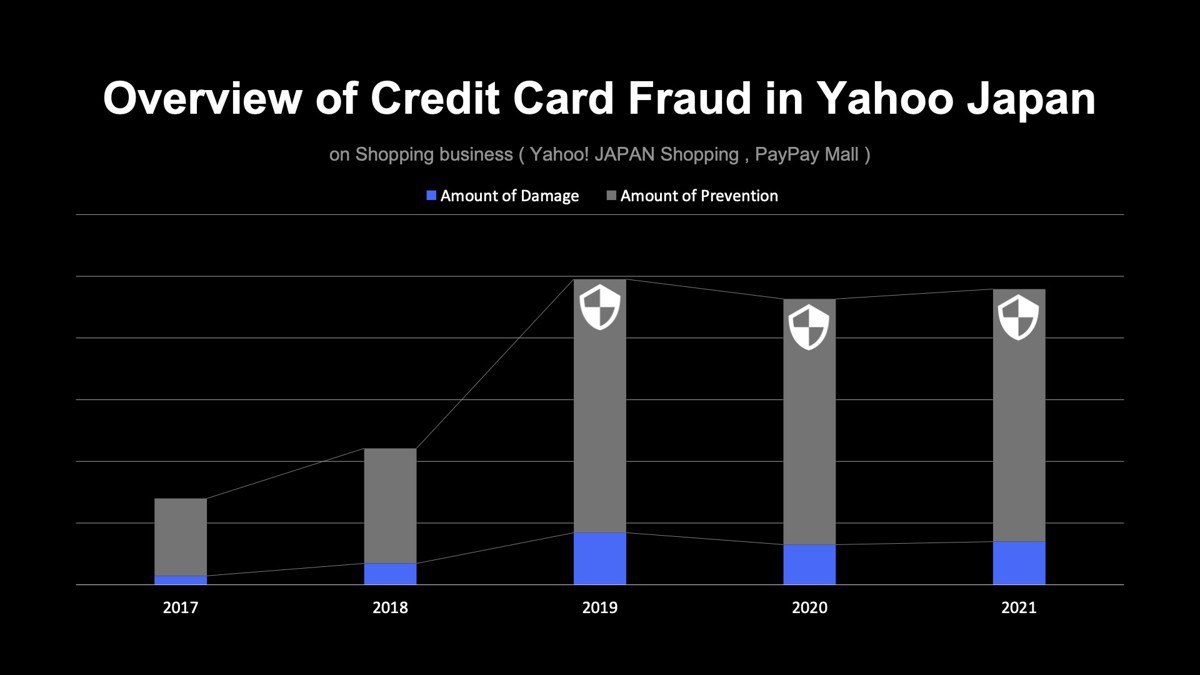
ヤフーは、より安全なeコマースを実現するために、より柔軟に、より高度な不正検知を行えるようアップデートを続けています。最後に、アップデートを重ねた結果として、冒頭で例を挙げたクレジットカードの不正利用の防止についての実績を紹介します。
ショッピング事業は急成長を続けていますが、売り場の取扱高とともに不正被害も大きくなっていました。しかし、2019年に再構築された不正検知システムの導入により、日本全体のクレジットカード不正利用の被害額が増加する中、被害額を横ばいに抑えることに成功しました。
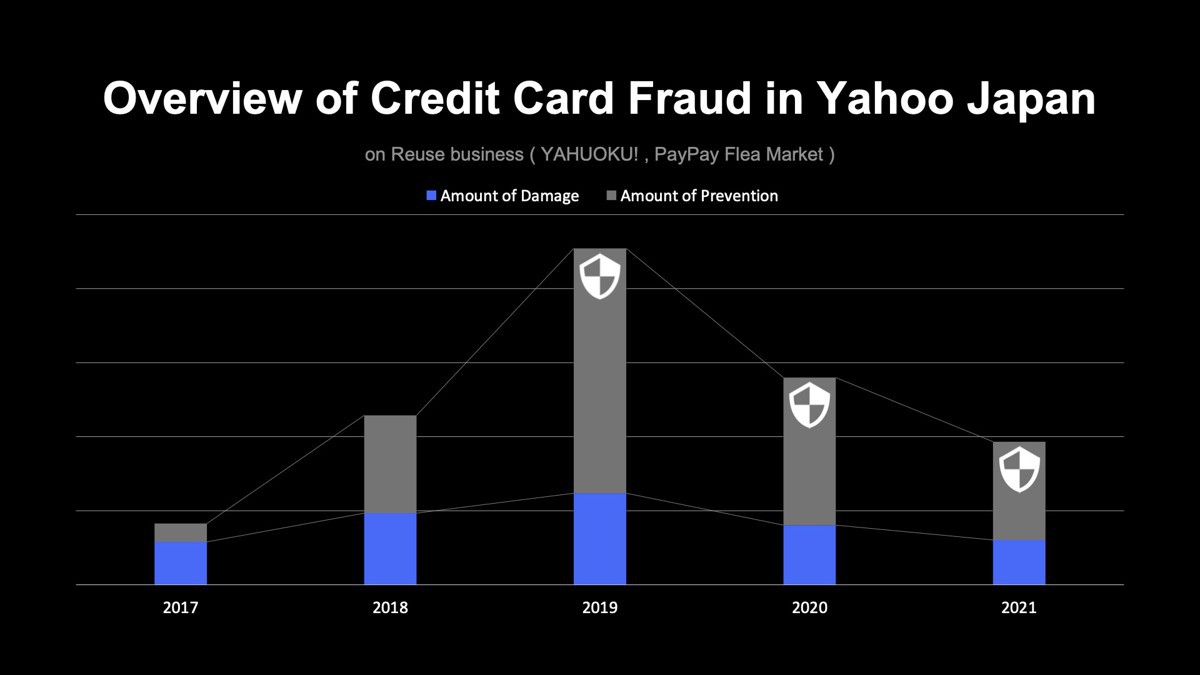
続けて、リユース事業についてです。こちらも売り場の成長に伴い、2019年に不正利用がピークとなっていましたが、不正検知システムの導入により、2019年と2021年を比較すると、不正利用自体を約60%減少させることに成功し、ショッピング事業以上に成果を得ることができました。
ヤフーは、eコマースをより安全にする取り組みについて、歩みを止めません。誰もが安心できるeコマースを目指して、不正を止められる、不正をさせない売り場作りを続けていきます。
アーカイブ動画
Apache®, Apache Cassandra™, 及びCassandraのロゴは、米国および/またはその他の国におけるApache Software Foundationの商標または登録商標です。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました

- 醍醐 旭裕
- 不正対策エンジニア
- 2021年ヤフー新卒入社。コマース領域の不正対策システムの開発に従事。最近は社内プロダクトへの不正対策システムの新規導入を担当。



