こんにちは。サイエンス統括本部の井上と小出です。
本記事では、MLOps推進チームとして継続的に取り組んでいるMLOpsの導入、改善に関する取り組みをご紹介します。具体的には、各プロダクトのMLモデル開発の品質を計測し、可視化できる仕組みの構築、並びにその結果を活用した施策事例についてご紹介します。
(なお、本記事ではMLOpsについての説明は割愛します。MLOpsの概要について理解したい方にはGoogleが公開しているこちらの記事を、技術的な詳細について理解したい方にはAIエンジニアのための機械学習システムデザインパターンをお薦めします。)
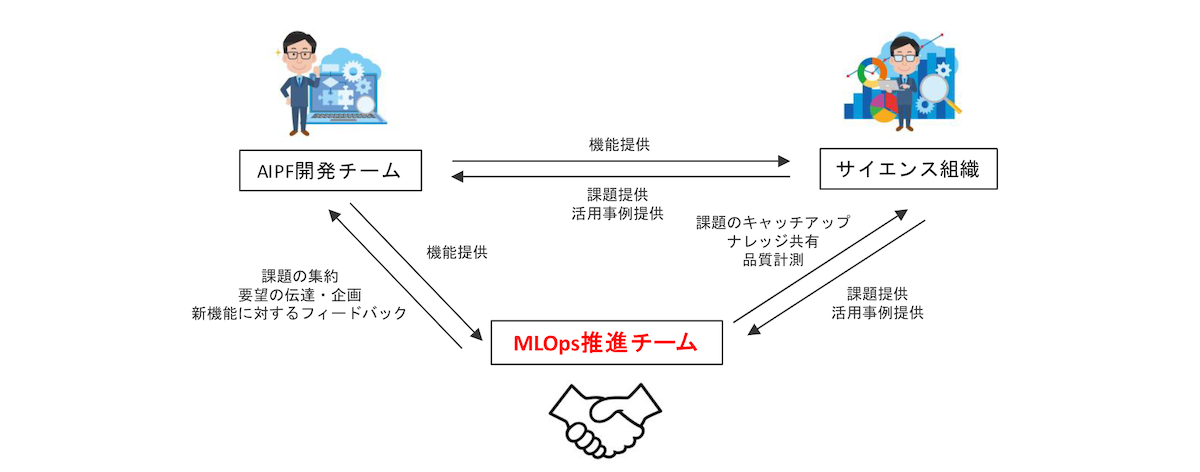
なぜMLOpsを推進する組織があるのか
ヤフーのサイエンス組織では広告、コマースを中心に50を超えるプロダクトが日々機械学習モデル(以後MLモデル)の開発をおこなっています。ヤフーでは内製された機械学習基盤(AIプラットフォーム、以後AIPF)が提供されており、多くのプロダクトがAIPFを活用しています。
2022年12月現在においてはすでにMLOpsを実現するための数多くの便利な機能が提供されていますが、提供開始当初はコンピューティング以外の機能はほとんど提供されていない状態でした。この状況下において、AIPF開発チームが次にどのような機能を提供することが利用者の課題解決につながるのかをサイエンスの立場から要望する役割が必要となりました。また、サイエンス組織の各プロダクトがAIPFへの移行、ならびに活用を進めていくことで、MLモデル開発の効率や品質が実際に向上していることを確認し、MLOpsを推進することの価値を示していきたいという考えがありました。
こういった背景から、MLOpsを推進する組織を立ち上げ、サイエンス組織とプラットフォームを提供する組織の間をつなぐ役割としての活動をおこなってきました。
(提供:アフロ)
MLOps推進チームがおこなっていること
ここからは実際にわれわれが行っている代表的な活動を紹介します。
MLモデル開発の品質計測
各プロダクトのMLモデル開発の品質が向上しているかを確認するために、定期的に状況を可視化できる仕組みが必要になりました。
先行事例を調査する中で、メルカリが取り組まれていたワークショップの記事を参考に、ML Test Scoreを活用することにしました。ML Test ScoreはGoogleが2017年に論文として投稿した機械学習システムの信頼性を数値化する仕組みです。下記の4つの領域について、それぞれ7つの項目に答えていきます。
- TESTS FOR FEATURES AND DATA(以後、特徴量・データ領域)
- TESTS FOR MODEL DEVELOPMENT(以後、モデル開発領域)
- TESTS FOR ML INFRASTRUCTURE(以後、インフラ領域)
- MONITORING TESTS FOR ML(以後、モニタリング領域)
具体的な質問例を下記に示します。
| 領域 | 質問内容 |
|---|---|
| 特徴量・データ領域 | 新しい特徴量は素早く追加可能か |
| モデル開発領域 | 全てのモデルはハイパーパラメータチューニングされているか |
| インフラ領域 | モデルは、安全かつ高速に前のバージョンに戻せるか |
| モニタリング領域 | モデルは極端に古い状態ではないか |
質問内容に対して、手動で実行しその結果をドキュメントに残していれば0.5、CIなどに組み込まれ自動実行されている場合には1.0、どちらにも該当しない場合には0をつけます。各領域においてスコアを合算し、そのスコアの最小値が最終的なML Test Scoreです。従いまして、特定の領域でスコアが高くても、別の領域のスコアが低ければその結果が採用されることになるため、高スコアを得るには全ての領域で高スコアを取る必要がある厳しいものです。
一方、ML Test Scoreを進めるにあたり、同じプロダクトへの継続的な計測であっても回答者が変わった際に回答基準にぶれが生じる課題が発生しました。対策として、設問一つずつに対して社内の状況なども加味した判断基準を作成し、そちらをもとに回答をしてもらうようにしました。具体的には下記のようなものです。
特徴量・データ領域
- 質問内容:
- 新しい特徴量は素早く追加可能か
- 回答基準:
- 0:新しい特徴量を追加したオンラインテストについて、企画から平均で3ヶ月以上かかる
- 0.5:新しい特徴量を追加したオンラインテストについて、企画から平均1〜2カ月以内に実施できる
- 1.0:メイントラフィックのモデルに対して、新しい特徴量を企画から平均1〜2カ月以内に追加できる/定常的な学習においても同様の仕組みで性能の検証がパイプラインに組み込まれている
モデル開発領域
- 質問内容:
- 全てのモデルはハイパーパラメータチューニングされているか?
- 回答基準:
- 0:ハイパーパラメータをチューニングしていないモデルが有る
- 0.5:全てのモデルでハイパーパラメータチューニングを1度以上実施している
- 1.0:全てのモデルでハイパーパラメータチューニングが自動で実施されており、必要に応じてモデルが更新されている
インフラ領域
- 質問内容:
- モデルは、安全かつ高速に前のバージョンに戻せるか?
- 回答基準:
- 0:ロールバックの仕組みが整備されていない、あるいはモデルを作った人しかロールバックできない
- 0.5:ロールバックがドキュメントによる手順書に沿って手動で行われており、時間がかかる
- 1.0:ロールバックがCI/CDパイプラインによって自動化されており、誰でも簡単に、即座にロールバックできる
モニタリング領域
- 質問内容:
- モデルは極端に古い状態ではないか?
- 回答基準:
- 0:プロダクション環境のモデルがいつデプロイされたものか把握していない、モデルの定期的な更新をしていない
- 0.5:モデルの定期的な更新は実施しているが、モデルの状態についての監視はしていない。
- 1.0:モデルがいつデプロイされたものかがいつでもわかるようになっており、かつそのモデルの現状の性能が把握できるようになっている。 また、定義されたしきい値を下回った際に検知ができている。
このような対応をすることで、回答のぶれが小さくなり徐々に精緻な結果が得られるようになってきました。これまで半年に1回のペースで合計3回のML Test Scoreを計測しています。参考までにこれまでの計測の結果を掲載します。
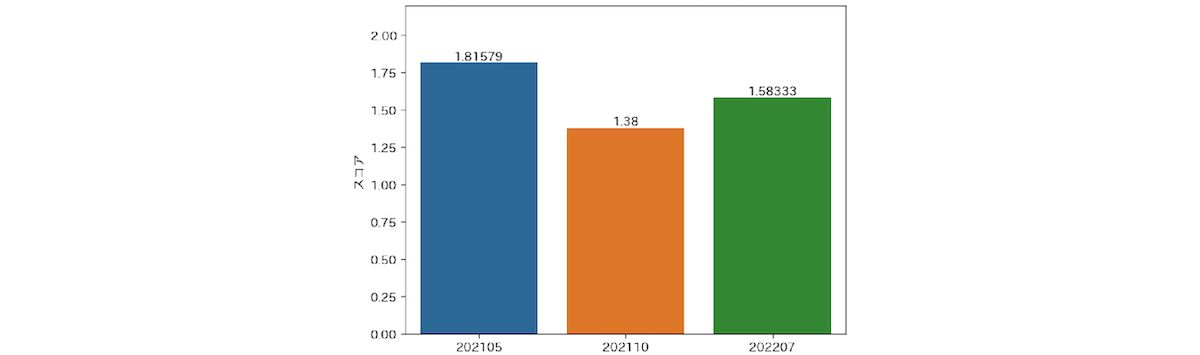
こちらの結果がヤフーのサイエンス組織内で計測したML Test Scoreの平均値の推移です。
この結果を見ると1回目と2回目のML Test Scoreの数値に大きな差が出ていることがわかります。これは先述の判断基準のぶれによって初回のスコアが上振れしていることが原因です。2回目以降は判断基準をより明確にしたことにより正確なものになっていると考えられます。また、2回目と3回目を比較するとスコアが上昇傾向になっています。なお、元論文の判定基準に当てはめると、現行のスコアは「基礎的なプロジェクトの要求事項は通過した。しかし、信頼性向上のためのさらなる投資が必要とされる」という判定です。このスコアが2を超える、「適切なテストがされている、だがさらに自動化の余地が残っている」を達成することがいったんの目標となりそうです。
次に、各領域のML Test Scoreの推移です。
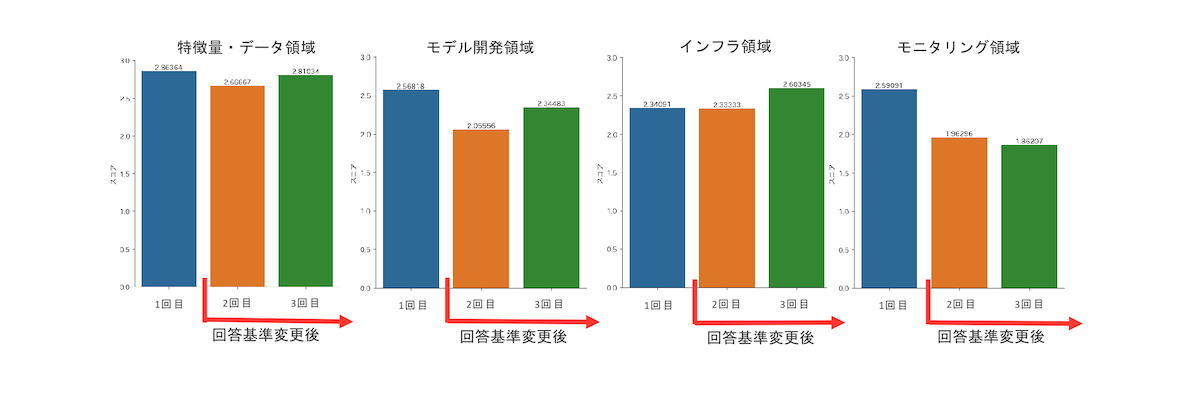
こちらの結果を見ると、2021年10月と2022年7月の比較において、モニタリング以外の項目についてはスコアの向上が見られることがわかります。また、インフラの領域について特に大きなスコアの向上が見られています。
一方でモニタリングの項目についてはほぼ横ばいという結果になっています。こちらの結果の分析やそれに伴うアクションについては後半パートにて詳しく説明しますが、このような形で品質計測をおこなっています。
MLOpsの啓発活動
先述の計測の結果を踏まえ、今後必要になるAIPFの機能の議論、ならびに企画をおこなっています。また、AIPF開発チームから新しい機能が提供される際には、先行利用者としてプロダクトへの適用を行い、その機能が課題を解決しているかの確認、改善ポイントの指摘といったフィードバックをAIPF開発チームに行い、機能のブラッシュアップを行います。また、その際に得られたナレッジや導入効果などを整理し、利用者がスムーズに導入できるように支援を行っています。
さらに、社内でMLOpsの適用を検討している、あるいはより深く理解したい人向けに、MLOpsに関する社内ユーザーコミュニティーとしてMLOps Communityを立ち上げ、定期的にヤフーのMLOps適用事例を広く共有する活動を行っています。
毎回MLOpsの事例が1〜2件共有されており、おおよそ半年前から始めた活動ですが既に10件近い発表が行われている活発なコミュニティーとなっています。
改善施策例
ここでは、MLOps推進チームの活動と関わりの深い改善施策の中から代表的な事例を2つご紹介します。
インフラ領域の強化
インフラ領域は言葉通りMLOpsにおけるインフラ領域にフォーカスした項目群となっており、例としては以下の様なものがあります。
- 学習は再現性がある
- 全てのMLパイプラインは結合テストされている
- モデルの品質はサービスインする前に検証が行われている
ここでは特にMLパイプラインについてフォーカスを当てます。
以前の社内では、MLパイプラインの構築におけるデファクトスタンダードと呼べる物がなく、それぞれの案件担当者が各自の判断で選択・構築していました。このためナレッジの集約や共通化も局所的な物となり、ML Test Scoreが求めるレベルの課題は手がつけにくい状況が続いていました。
この課題感はMLOps推進チームの立ち上げ以前から関係者間ではある程度の共通認識として持っており、AIPF開発チームとの議論でも度々話題にあがっていました。この解決策として、AIPF開発チームではパイプライン環境のApache Airflow、Argo Workflowsといったツールの提供を開始しました。
これらのツールは
- 利用者側でも比較的高い課題感を持っていた
- 改善効果を説明しやすく(工数削減&施策の回転数UP)関連組織の協力を得やすい
- MLOps領域の中では比較的シンプルな課題であり手をつけやすい
などの要因も手伝って、大きなプロモーション活動なしでも自然に社内に浸透していきました。
インフラ領域のML Test Scoreは初回のヒアリング時点では想定通り他領域と比較して低い状態でしたが、そこから1年以上経過し、先述のツール群がある程度浸透した3回目のヒアリングでは大きなスコア上昇が見られました。
モニタリング領域の強化
モニタリング領域はMLパイプラインの要所におけるモニタリングにフォーカスした内容となっており、例としては以下の様なものがあります。
- 依存先のデータ変更時に通知される
- モデルが古すぎない
- サービング時にモデルの予測性能が悪化していない
インフラ領域が順調な伸びを見せる一方で、同様にスコアの低いモニタリング領域については現在も試行錯誤が続いています。こちらも解決策としてAIPF開発チームからモデルモニタリングサービスとしてDronachが提供されていますが、インフラ領域とは逆に
- これまでモニタリングを行っていない項目についてはエラーが検知された事がないためそもそも課題として認識されるに至っていない
- 事前に改善効果の見積もりが困難であるため、目の前にある今の業務と比較して優先度が低くなりやすい
- 課題自体の難易度や知見不足により導入ハードルが高い
といった要因から、インフラ領域と比較してなかなか浸透せず、何らかのテコ入れが必要でした。そこでMLOps推進チームでは、複数のサービスに協力を依頼してツールの導入検証を行い、AIPF開発チームにフィードバックを返して機能改善を進める施策を行いました。施策自体の定量的な評価は難しいですが、結果として課題の認知向上やツールの改善による導入ハードルの低下に一定の効果があったと思います。
実際にモニタリングツールを導入したプロダクトから報告された、事故回避につながった事例を紹介します。
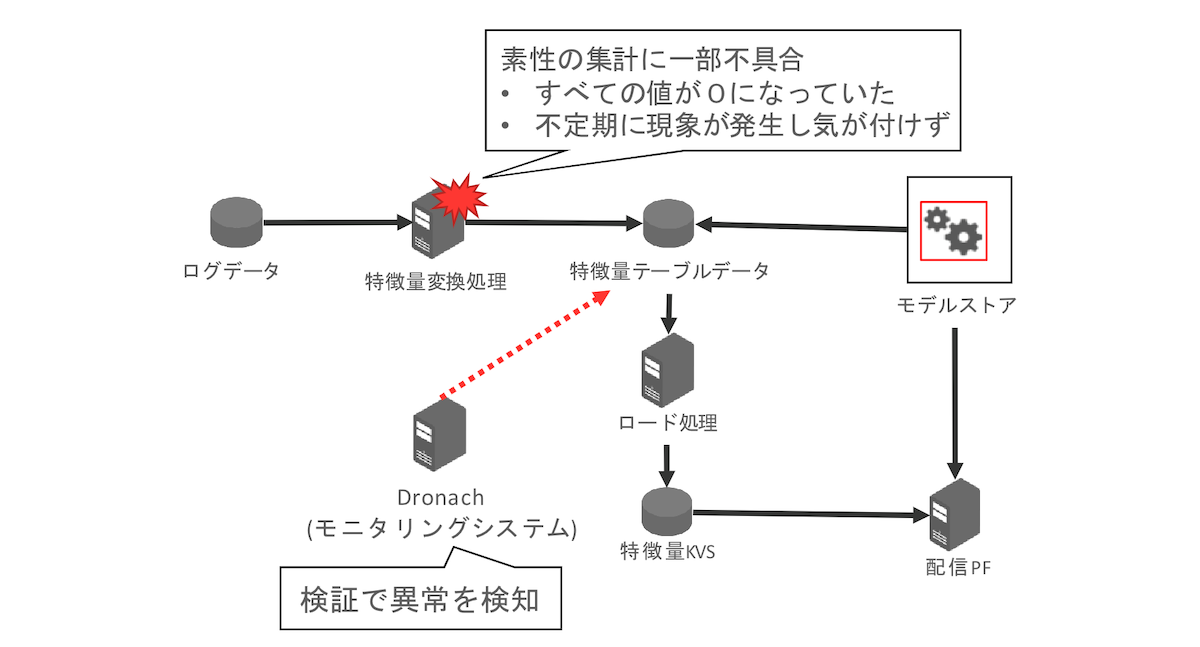
上記の事例では
- モニタリングの仕組みを先行導入したところ、毎日アラートが発生
- 調査したところ、一部の特徴量が不定期に全て0になってしまう不具合があった
- 特徴量変換処理に仕様漏れがあることがわかった
といった事が起きました。
不定期に起こる不具合については人が検知するのは困難で、システムとして導入をした価値のある事例でした。別の事例では
- 入力データの一部で異常な値を検出
- 入力データはあるサービスから取得しているログ情報だが、一部の項目でNULL値が漸増している
- サービス側に確認した所、ログの仕様変更が行われていた
といった事がありました。いずれのケースもモデルのリリース前に気付く事ができたため実サービスへの影響はありませんでしたが、知らずにリリースしていた場合、ユーザーの利便性を損なうとともに、売上毀損も想定される内容でした。
今後事例が増える事で改善効果に関する課題も徐々に解消されていくと考えています。さらなる改善施策をチーム内で議論しており、「モニタリングにおける具体的な評価指標がわからない」といった声に対して、標準メトリクスの様なものを提供する事で解決できないかといった案もあがっています。
終わりに
今回はMLOps推進チームの活動をご紹介しました。今後はモニタリングの強化に重きを置きつつ、さらなるMLモデル開発の効率・品質の向上に向けたさまざまな取り組みを進めていく予定です。
この取り組みは組織内に多くのMLモデル開発プロダクトが存在すること、内製の機械学習開発基盤を構築、ならびに提供していることなどヤフー特有の条件が重なったことによるものが大きいと思いますが、MLOpsの取り組みを組織内で進めたいと考えている方がいましたら、事例の一つとして参考になれば幸いです。
最後まで読んでくださりありがとうございました!
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました

- 井上 稔
- サイエンス統括本部 機械学習エンジニア
- サイエンス領域のデータ利活用推進および広告領域を担当しています。最近自宅のお風呂をリフォームしました。

- 小出 明弘
- サイエンス統括本部 Technical Director
- サイエンス領域の技術責任者をしています。その活動の一環としてサイエンス領域の生産性向上に力を入れています。



