こんにちは。ヤフーのAIプラットフォームの開発と運用を担当している黒松です。
ヤフーではオンプレミスにあるKubernetesの上に全社で利用可能なAIプラットフォームを構築しています。昨年8月に公開した「ヤフーのAIプラットフォーム紹介 〜 AI開発をより手軽に」ではヤフーのAIプラットフォームの全体概要をご紹介しました。ここではその続編として、ブログの最後に触れたモデルモニタリングツールであるDronachをご紹介します。
Dronachはヤフーで内製したモデルモニタリングツールです。YAMLフォーマットで特徴量のデータセットを指定するだけで定期的なデータドリフトの検知と統計情報の集計、結果を確認するダッシュボードの構築、アラート通知といったモデルモニタリングに必要なシステムを自動的に構築します。
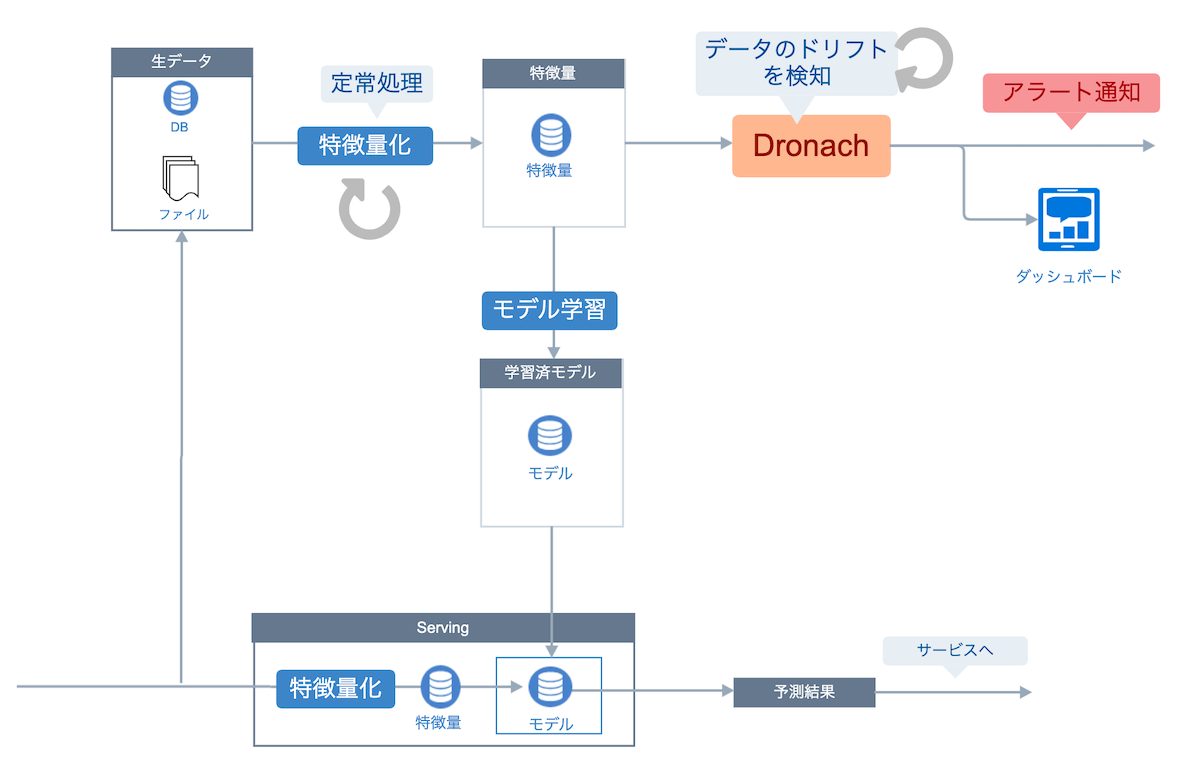
Dronachの実体はモデルモニタリングの設定をカスタムリソースとして扱うKubernetes Operatorです。Kubernetesは機械学習のエンジニアにとって複雑と言われますが、ヤフーにはKubernetesを扱えるエンジニアが多く在籍しておりKubernetesを使うことへの敷居は高くありません。
このブログでは、OSSが主流である今日になぜ社内プラットフォームとしてモデルモニタリングツールを内製する決断をしたのかと、Dronachのシステム構成を説明します。
AIプラットフォームチームについて
私が所属しているAIプラットフォームチームは、社内のAI活用を促進するための共通プラットフォームを開発し提供することが目的のチームです。
AIプラットフォームは、Namespaceで分離されたマルチテナントKubernetesクラスタであるACP(AI Cloud Platform)をはじめとしてさまざまなマネージドサービスで構成されており、データサイエンティストやデータエンジニアが開発に集中できる環境を提供しています。Googleが定義するMLOps レベル1やレベル2で機械学習を使ったシステムを運用することを目指し、日々機能追加と改善を続けています。
AIプラットフォームチームが開発、運用している基盤については「ヤフーのAIプラットフォーム紹介 〜 AI開発をより手軽に」で詳しく紹介しています。
データドリフトとは
実際のデータはさまざまな理由で変化します。時間の経過によって学習時のデータと現在のデータの傾向が異なる状態を、データドリフトと呼びます。データドリフトが発生すると新しいデータの分布に対して適切な予測ができなくなりモデルの性能が低下します。機械学習のモデルの性能はサービスの質と直結するため、モデルの性能をモニタリングして一定のしきい値を下回った場合は現在のデータを使ってモデルを再学習する必要があります。
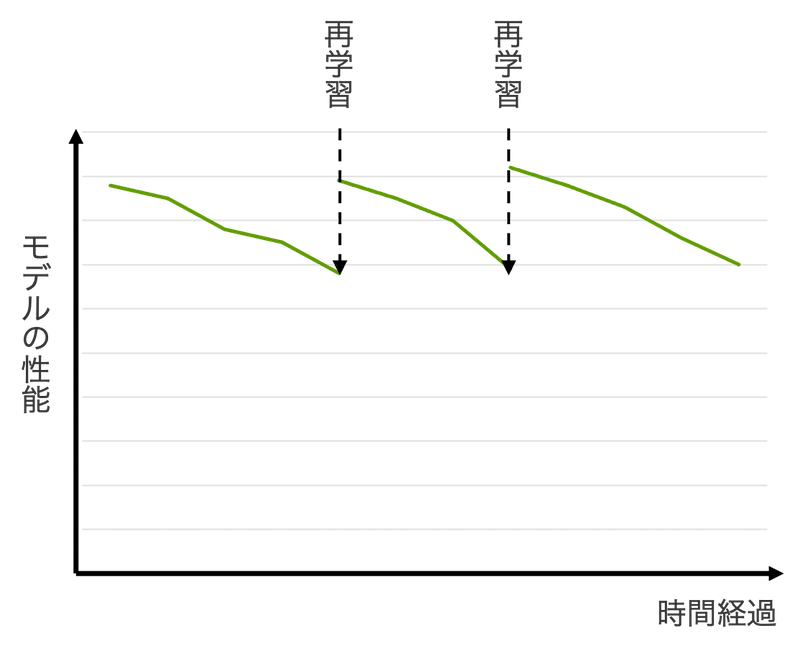
モデルの性能のモニタリングにはデータドリフトの検知が有効です。なお、このブログでは学習時とテスト時で特徴量のデータ分布が異なる共変量シフトを扱いますが、共変量シフト以外のドリフトのモニタリングも有効です。ドリフトの分類やそれらの検知手法の詳細を知りたい方はLearning under Concept Drift: A Reviewをご覧ください。
モニタリングすべき指標
データドリフト以外の理由でもモデルの性能が低下します。たとえば、レコメンドモデルを使いユーザーの嗜好ごとにおすすめの商品を提示するECサイトがあるとします。このECサイトではおすすめ商品の表示数が5つだったため、レコメンドモデルの性能をMAP@5で評価していました。あるときECサイトのデザインが変わり、おすすめ商品の表示数が5つから3つに減ったとします。このとき、モデルが入力として受け取るユーザーの嗜好は変化しませんが、MAP@5で高い指標だったモデルがMAP@3においても適切である保証はありません。この問題を検知するには、データドリフトに加えて以下の項目のモニタリングが有効です。
- MAP@KやAccuracy、AUCなどのメトリクス
- モデルを使うサービスのKPI
教師あり学習や半教師学習のタスクでは、モデルが予測すべき正解がわかっているため、AccuracyやAUCといった直接的な指標を扱えます。これらをモニタリングすることでモデルの性能低下を検知できます。一方で、教師なし学習のタスクではAccuracyやAUCを計算できません。この場合は対象のモデルを使うサービスのKPIを代理の指標として扱います。
ヤフーにおけるモデルモニタリングの課題
モデルモニタリングのシステムを構築して運用するには、機械学習を使ったサービス開発とは異なるスキルと多くの工数が必要になります。
実際、サービスのKPIのモニタリングはしていてもデータドリフトのモニタリングには手が回っておらず、事前に決めた期間でモデルを再学習する運用にしたり、KPIが下がったときにその都度原因を調査して対処することが多くありました。
そこでAIプラットフォームチームは、モデルモニタリングの仕組みを簡単に構築できるサービスを提供することにしました。
モデルモニタリングの内製を決断した理由
モデルモニタリングのサービスをプラットフォームとして提供することを決めたとき、これまでの経験から、サービスを開発するチームに利用してもらうためには
- マネージドサービスとして提供されていて、サービスの開発チームが運用しなくても済むこと
- 導入のコストが低いこと
の2つがそろっていることが必須だと考えました。
世の中には、クラウドプロバイダーが提供するモデルモニタリングサービスが複数あります。また、オンプレミスで利用できるOSSとしても複数の実装が公開されています。これらを導入できるか調査したところ、以下の理由でそれらの採用を見送りました。
- データの保存場所の要件が合わない
- クラウドプロバイダーが提供するモデルモニタリングのサービスは、クラウドプロバイダーが提供するストレージサービスやデータベースサービス上にデータがあることを前提としており、データがオンプレミスにあるヤフーでは利用できない
- オンプレミスで利用できたとしても、データの保存場所がDragon(ヤフーが内製したS3互換のオブジェクトストレージ)やHDFS、Hiveなどさまざまで、これら全てをデータソースとして扱えるツールがない
- ドリフトの検知とKPIの低下を監視してアラートの通知までを一環してサポートする仕組みがなく、導入サービスごとに追加の開発コストが必要になる
- 定期実行をサポートしていなかったり、結果に基づいてアラートを飛ばす仕組みがないなどひとつひとつのツールの機能が限定的であり、一連のモデルモニタリングの仕組みを実現するには他にも複数のツールを組み合わせる必要がある
これらのサービスやツールを採用してモデルモニタリングのサービスとして提供しても、対応していないデータソースにあるデータを使いモデルを学習している社内サービスでは導入できません。仮にデータソースが対応していても、定期実行やアラートシステムとつなぎ込みための工数をサイエンスチームに負担してもらわなければなりません。
このように都度他のデータ処理システムと連携する仕組みを構築しなければならないモデルモニタリングのサービスの設計では、プラットフォームチームの本来の仕事である共通機能の抽象化に失敗しているといえます。
そこで、AIプラットフォームチームではヤフーにあるさまざまなデータソースに対応し、かつ低コストで導入できるモデルモニタリングツールを内製することにしました。プロトタイプは2021年9月に完成し、Dronachと名付けてAIプラットフォーム上のマネージドサービスとして提供しています。
システム構成
定期的にデータソースから特徴量のデータセットを取り出してドリフトを検知する処理には、スケジューリング機能やジョブの依存関係を解決できるワークフローシステムが必要です。DronachではAIプラットフォームでマネージドサービスとして提供しているArgo Workflowsを採用しました。
Dronachのシステム構成を図に示します。なお、この図にある学習済モデルはサービスで利用するためのモデルではなくデータのドリフトを検知するためのモデルです。このモデルはサービスで利用するモデルを学習するために使った特徴量を使って学習します。
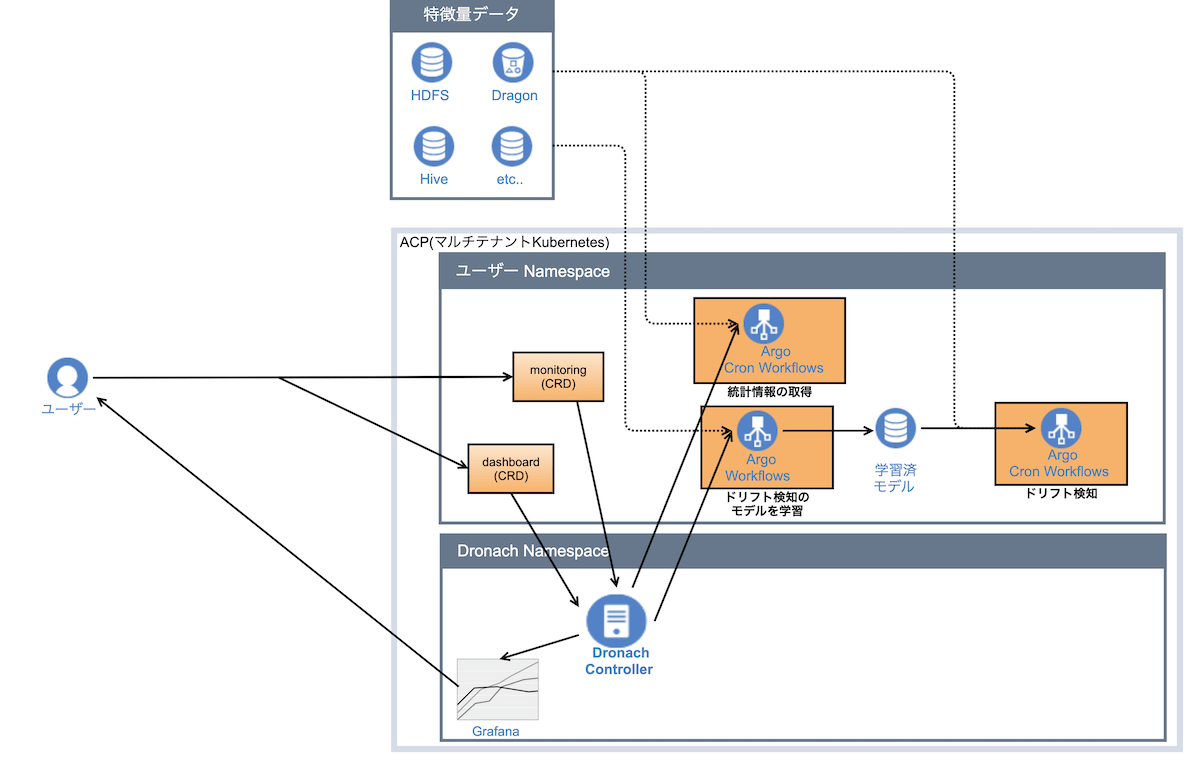
DronachはKubernetesのOperatorパターンの仕組みを採用しています。Operatorパターンとは、Kubernetesに登録されたカスタムリソースの状態の定義に近づくように、リソースに対応するコントローラが必要な処理を次々実施する仕組みです。Dronach固有のカスタムリソースはモニタリングの設定とダッシュボードの2つです。
HDFS上の特徴量データのモニタリングを構築するためにユーザーが書くカスタムリソースの定義がこちらです。なお、ここでは一部の定義を省略しています。
apiVersion: dronach.yahoo.co.jp/v1alpha1
kind: BaseModel
metadata:
name: dronach-sample-model
spec:
data:
name: sampledata
dataType: tabular
fileFormat: csv
volumeSize: 1Gi
hdfs:
keytabSecret: keytab
account: dronach-sample-user
path: "/user/dronach/sample_{{workflow.creationTimestamp.y}}{{workflow.creationTimestamp.m}}{{workflow.creationTimestamp.d}}.csv"
profile:
schedule: "0 */1 * * *"
resources:
limits:
cpu: 1
memory: 500Mi
requests:
cpu: 1
memory: 200Mi
dataDrift:
template:
schedule: "0 */1 * * *"
resources:
limits:
cpu: 1
memory: 500Mi
requests:
cpu: 1
memory: 500Miユーザーが上記のリソース定義に従ってドリフトを検知したいデータ定義してKuberntesにデプロイすると、Dronachのコントローラが、ドリフトを検知するArgo WorkflowsのCronWorkflowとデータの統計情報を収集するCronWorkflowをユーザーのNamespaceにデプロイします。
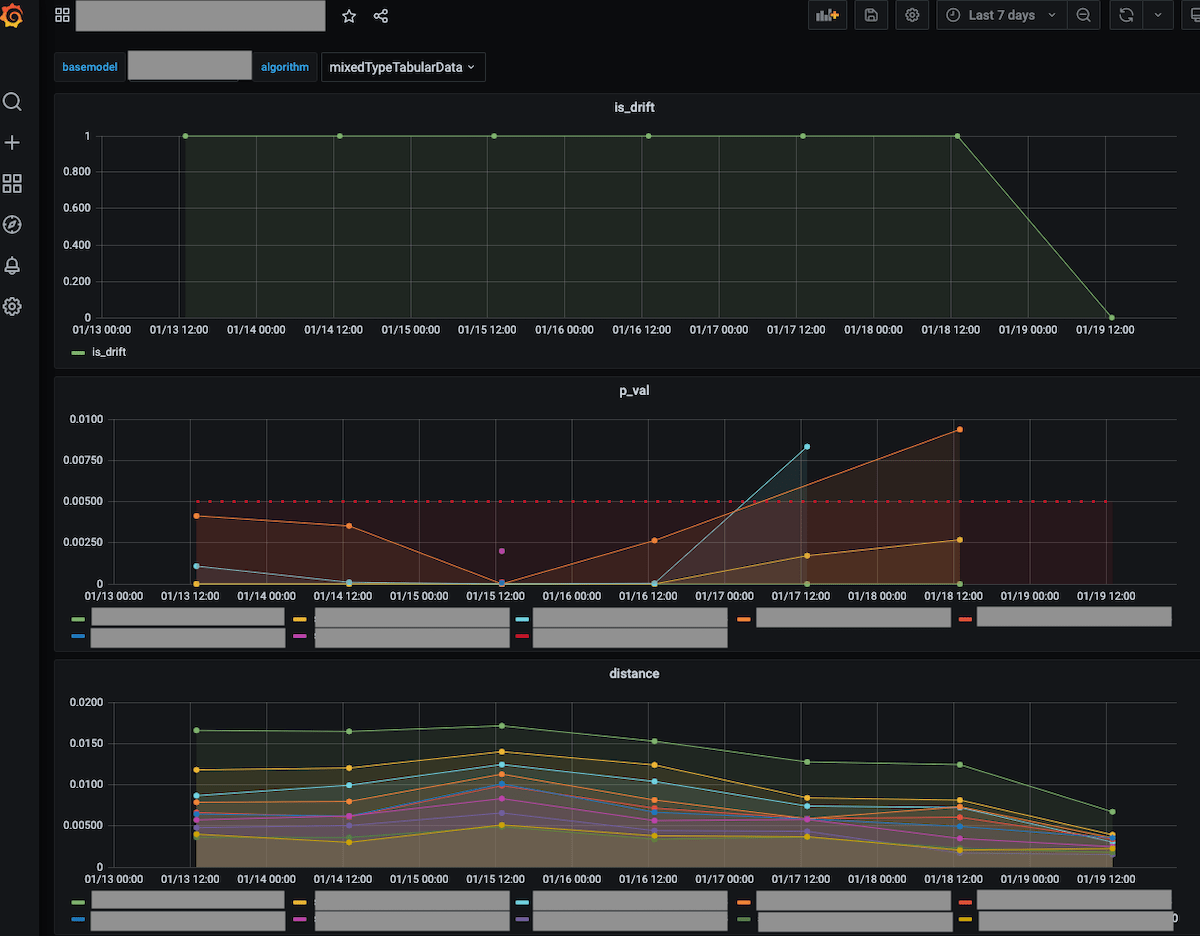
また、ユーザーがダッシュボードのカスタムリソースをデプロイすると、Dronachはドリフトの有無とデータの統計情報を確認するダッシュボードを構築します。いつからドリフトが起きていたのか、特に顕著に変化した統計情報はなんだったのかをこのダッシュボードを見て確認できます。
データドリフトを検知する仕組み
Dronachを使ってモデルモニタリングを導入するためにユーザーがすることは、ドリフト検知の設定とアラートの条件をYAMLに書いてKubernetesにデプロイするだけです。モデルモニタリングに必要なジョブの定期実行やアラートの設定は全てDronachが用意します。
現在、DronachはデータソースとしてDragon(ヤフーが内製したS3互換のオブジェクトストレージ)、HDFS, Hive, Trino(Presto)をサポートしています。HiveやTrino(Presto)を直接サポートしているため、普段実行しているクエリを書き換えることなく導入できます。
データドリフトの検知の仕組みにはOSSであるAlibi Detectを採用しました。Alibi Detectはベースとなるデータと新しいデータを比較し、2つのデータセットのデータ分布が同じであるかを検定します。Alibi Detectは複数の検定アルゴリズムをサポートしています。Dronachは利用者がアルゴリズムを個別に指定しなくてもAlibi Detectで利用可能な複数の検定アルゴリズムを並行して実行します。そのため、あるアルゴリズムではデータドリフトの発生に気づかなかったとしても別のアルゴリズムでデータドリフトを検知できます。ユーザーは複数のアルゴリズムの結果を見て、データドリフトが起きているかを総合的に判断します。
検定アルゴリズムがデータドリフトの可能性を検出するとDronachはSlackにアラートを送ります。どのデータがどの程度分布が変わるとサービスに影響があるとみなすのかはユーザーであるサービスの開発、運用チームが判断すべきです。そのため、Dronachはモデルの自動的な再学習はサポートせずデータドリフトの発生の可能性をモデリングチームに伝えるのみにとどめています。
データの統計情報の収集
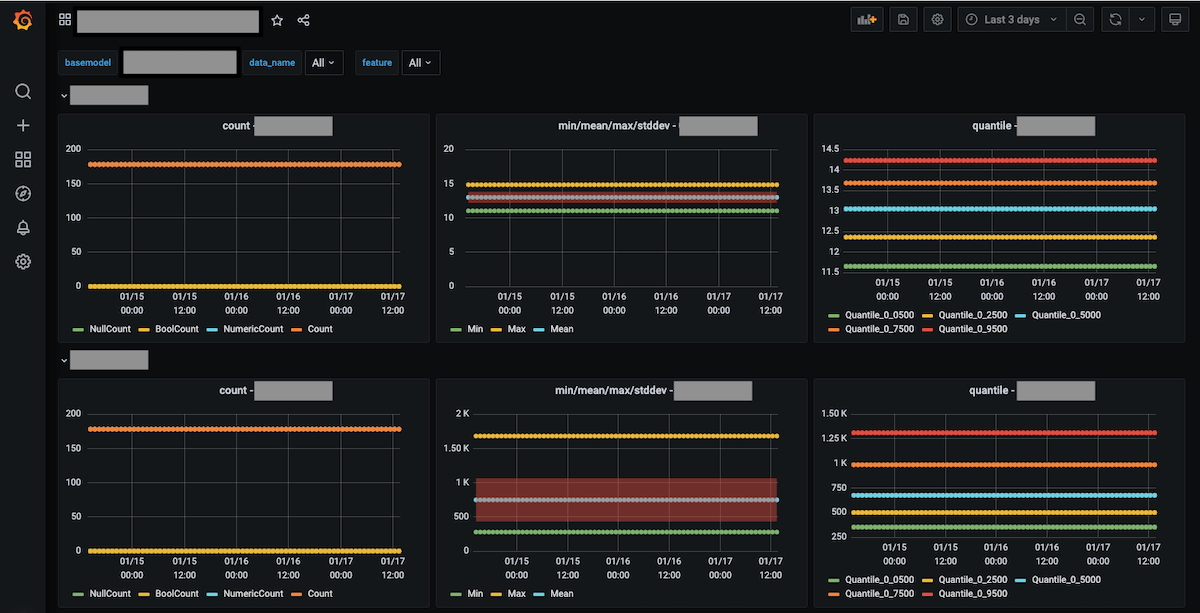
データドリフトが疑われる場合、モデルへの影響を確認するために、どの特徴量の分布が変化しているのかを確認する必要があります。そこでDronachはデータドリフトの検知に加えて特徴量の統計情報を定期的に収集する機能を提供しています。
統計情報の収集はデータロギングのOSSであるwhylogsを使っています。whylogsは内部でデータの統計用法を高速に計算する近似アルゴリズムのライブラリであるApache DataSketchesを採用しており、大量のデータであっても短時間でデータの統計情報を計算できます。
ダッシュボード
ユーザーはDronachが定期的に実行するデータドリフトの検定結果と統計情報の計算結果をダッシュボードで確認できます。ドリフト検知、統計情報の収集、それらを可視化して確認できるダッシュボードの作成をDronachがサポートしているため、データサイエンティストやサービスの開発者が自身でダッシュボード画面を作成する必要はなく、素早くデータの分布変化を確認できます。
Operatorパターンを採用した理由
先ほど説明したようにDronachはKubernetesのOperatorパターンを採用して開発しました。Operatorパターンを採用した理由は2つあります。
1つめの理由は、Kubernetesの認証認可の仕組みをそのまま使ってモデルモニタリングの認証認可を実現できることです。AIプラットフォームが提供するKubernetesクラスタはAthenzとGarmを使いOpenID Connectによる認証認可を実現しています。
モデルモニタリングの設定をKubernetesのカスタムリソースとして設計したことでKubernetesのRBAC機能やOpenID Connectの認可の仕組みを使ってモデルモニタリングの設定を作成できる人を制限できます。対象の特徴量のデータが保護されている場合はデータにアクセスするために必要なSecretやConfigMapを参照できる人だけがモデルモニタリングを設定できるように権限を設定できます。
2つめの理由は、モデルモニタリングの状況をユーザー自身が把握できるため、開発者であるAIプラットフォームチームが障害調査のボトルネックになることを避けられることです。Dronachはユーザーが定義するモデルモニタリングの設定のためのカスタムリソースに加えて、統計情報の取得やドリフト検知のジョブを示す中間状態のカスタムリソース(データドリフトの検定や統計情報を収集するジョブの状態を管理)を持ちます。これらのカスタムリソースはDronachのOperatorが作成、更新します。ユーザーはこの中間状態のカスタムリソースのステータスを確認することでジョブの現在の状態や失敗した原因を調査できます。失敗の原因がジョブのワークフローの特定のタスクであればユーザーはArgo WorkflowsのWeb UIから実行ログを見て原因を特定できます。
複数のレイヤーでユーザー自身が原因を調査する手段があるため、モデルモニタリングのジョブが失敗するたびにDronachの開発メンバーが毎回調査しなければならないといった問題を回避できます。これは全社向けのマネージドなKubernetesクラスタであるZCPがヤフーに浸透しており、Kubernetesを直接操作できるエンジニアが多くいること、モデルモニタリングのジョブの実態が利用者の権限で実行できるジョブに閉じた設計だからこそ実現できたことです。
Kubernetes Operatorには、Operatorの開発者と利用者が異なる場合は利用者にもKubernetesの知識が必要になりサービスが普及するボトルネックになる、というデメリットがあります。しかし、ヤフーでは2020年8月時点で680を超えるKubernetesクラスタがあるなどKubernetesを扱えるエンジニアが多く在籍しており、このデメリットの影響が小さい環境です。
利用事例
リリースから間もないですがすでに効果がではじめています。あるサービスではドリフトが突然発生し学習用データの一部に欠損が生じたことに気づくことができました。
また、利用していたクエリを書き換えずにそのまま使えるため、事前知識がない状態から数十分程度で導入できたとのフィードバックがあり、設計で掲げた「低コストで導入できるモデルモニタリングツール」を実現できていることを確認できています。
今後の予定
今後はモデルのメトリクス指標やサービスのKPIをモニタリングする機能を計画しています。また、先日のブログでご紹介した内製のモデルサービングサービスであるCuttySarkとDronachを連携して、推論サービスへの入力と出力結果のドリフトを検知する機能を実装する予定です。
おわりに
AIプラットフォームのマネージドサービスとして開発したモデルモニタリングツールであるDronachをご紹介しました。ドリフトを監視したいデータとアラート発火の条件をYAMLで書いてKubernetesにデプロイするだけで継続的なモデルモニタリングを始められます。内製の決断をしたことでHDFS、Hive、Trino(Presto)、S3互換のオブジェクトストレージなどヤフーに必要な多岐にわたるデータソースをサポートしたモデルモニタリングを実現しました。
ヤフーでは、国内でもトップクラスの大規模データを使い最高のMLOpsの実現するための仕組みを一緒に開発してくれるエンジニアを募集しています。AIプラットフォームチームはOSSの採用を基本方針にしていますが、必要であればパブリッククラウドのサービスに相当するツールを自身で設計・開発して社内全体に提供できる希有なポジションです。興味のある方のご応募お待ちしています。オンラインでのカジュアル面談も歓迎です。
採用情報「データプラットフォームエンジニア(AIプラットフォーム/データ基盤/DBA)」
最後まで読んでくださり、ありがとうございました。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました
- 黒松 信行
- AIプラットフォーム エンジニア
- AIプラットフォームの開発や運用を担当しています。
-



