こんにちは!サイエンス統括本部でYahoo!ショッピング のレコメンドシステムを開発している高久です。
私の所属するチームでは、さまざまな技術を使ってサービスに実際にどうレコメンド機能を組み込んでいくかについて取り組んでおり、機械学習モデルから配信システムまで一貫して開発・運用しています。
今回はそんな中で取り組んだレコメンドシステムの配信部分の構築事例について紹介します。
※ レコメンドシステムの開発ではプライバシーポリシー の範囲内で取得したデータを用いて行っています。
Yahoo!ショッピングのレコメンドについて
レコメンドとは端的にいうとユーザーの興味がありそうな商品を薦める機能のことで、Yahoo!ショッピング内のさまざまなページや箇所に、例えば「あなたへのおすすめ商品」といったモジュールとして出ています。
ただ、一口にレコメンドといっても
- ユーザーの嗜好に合いそうなおすすめの商品
- 今見ている商品と比較するのにおすすめの商品
- 同時に購入するのにおすすめの商品
などその種類はさまざまあり、Yahoo!ショッピングではユーザーの状況に合わせて現在60種類以上のモデルのレコメンドを展開しています。
その中でも今回はユーザーの過去の行動傾向から「ユーザーの嗜好に合いそうなおすすめの商品」を提示するためのレコメンドシステムについての話になります。
他の種類のレコメンドシステムについても過去にTech Blog が投稿されていますので、宜しければご覧ください。
参考:Yahoo!ショッピングのレコメンドに検索エンジンを導入して運用改善した話
大規模データを扱って直面した課題
レコメンドのアルゴリズムとして古典的なものにMF(Matrix Factorization)やFM(Factorization Machine)といった協調フィルタリングを用いた手法がありますが、 近年はニューラルネットを用いた機械学習モデルを使うことが多くなりました。
しかしながら、こういったモデルを実際にサービスで使おうとすると、Yahoo!ショッピングのように億単位の商品がある大規模データの場合、 モデルのパラメタ数が肥大化し、メモリ不足や推論時のレイテンシ悪化などの問題が発生します。
さらに、実際の運用ではこういったモデルを複数管理することになるため、できるだけ軽量なモデルにしたいという課題がありました。
ベクトル検索を用いた推論
上記の課題を解決するため、われわれのチームではレコメンドの推論処理を以下3つに分割することにしました。
機械学習モデルの入力と出力に商品IDを直接使うのではなく、事前に学習したベクトルを扱うようにすることで機械学習モデルのパラメタ数を減らし軽量化を図っています。
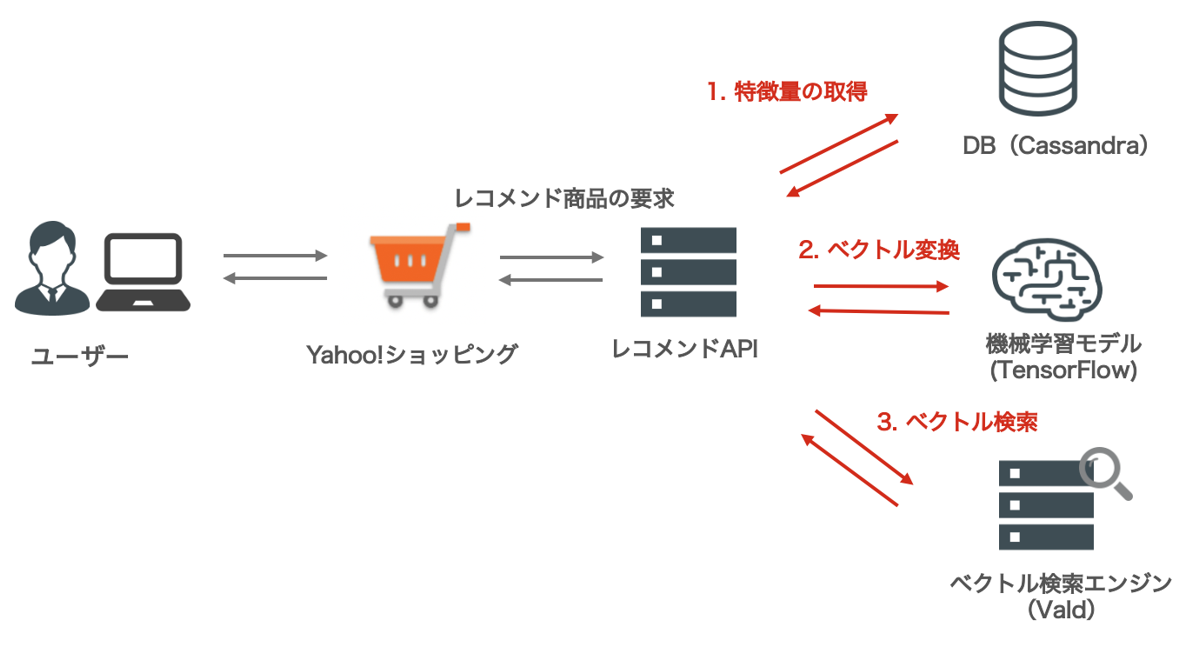
各ステップについて説明します。
1. 特徴量の取得
ここでは、ユーザー情報や行動履歴、およびそれらのベクトルを取得します。代表的なのはユーザーが過去に閲覧した商品をベクトル化したもので、Meta-Prod2VecやSASRec、BERT4Recなどのモデルで作成されます。
これらは主に商品の閲覧情報を使って学習されるものですが、それ以外に入力に有効な情報として商品のテキストや画像といったコンテンツ情報が挙げられます。
ただ、これらはわれわれのようなレコメンドチームよりは画像認識や自然言語処理といった専門分野のチームで既にベクトル化がされていることが多く、自前でベクトルを作成するよりはそういった専門分野のチームで作成しているベクトルがあればそのままDBに格納させてもらい、われわれはそれらを入力としてレコメンド商品を推論する機械学習モデルを作成するところに専念するようにしています。
このDBには大量のデータの格納とREADリクエストを捌く必要があるためスケーラビリティの高いNoSQLであるApache Cassandra (以下、Cassandra)を採用しています。
Cassandraについては過去にTech Blog がございますので、詳しくはそちらをご覧ください。
参考:NoSQLデータベースCassandraの紹介 〜 ヤフーのデータ基盤を支える技術
2. ベクトル変換
先にも述べましたように、商品IDを入力や出力にする機械学習モデルは商品数の増加により肥大化し、メモリを逼迫するほか計算量も大きくなるため推論時にレイテンシの悪化が発生します。
そのため、入力および出力に事前に学習されたベクトルを使うようにモデルを作成、推論時には出力として算出されたベクトルでベクトル検索(次ステップで述べます)することでレコメンド商品を取得しています。
このように推論時にベクトル検索を用いる手法については、レコメンドに関する国際学会であるRecsys2016の論文 でも触れられています。
ここでは、ユーザーが過去に閲覧した商品k個を使ってレコメンド商品を推測する以下のような簡単なモデルで説明したいと思います。
入力としてk個の閲覧商品のベクトルが与えられ、それらを正解となる商品ベクトルと同じn次元ベクトルに変換したのち、正解となる商品ベクトルとの内積の値を出力としています。
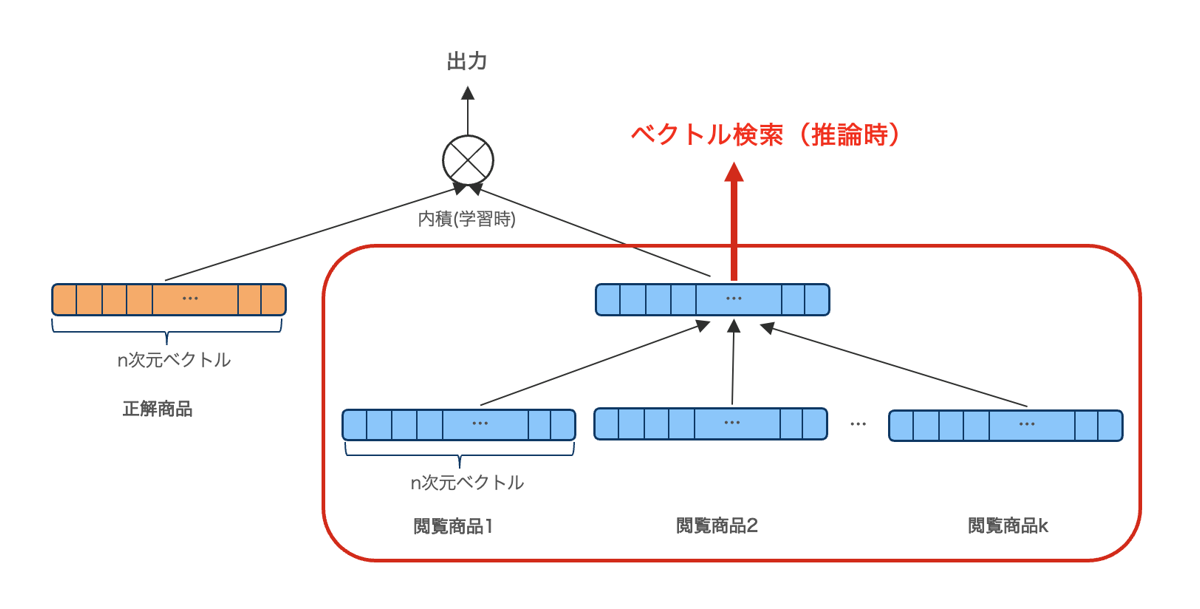
推論時に必要なモデル(赤枠部分)のパラメタ数を計算すると、例えば商品ベクトルの次元数n=128、閲覧履歴数k=5とした場合、
パラメタ数:128(=n) * 5(=k) * 128 = 81,920
となります。
Yahoo!ショッピングでは億単位の商品があるため、それらを埋め込み(Embedding) 層や出力層で扱うモデルに比べて圧倒的にパラメタ数が少なくなります。
説明のため簡単なモデルを例にしていますが、実際にはより複雑な機械学習モデルを使っており、 それらについてはまた別の機会に投稿できればと思っています。
機械学習モデルは、TensorFlowのモデルとして作成し、推論時はKubernetes上に立てたTensorFlow Serving によってサービングしています。
また、Apache Airflow (以下、Airflow) によりモデルは定期的なバッチ処理で再学習され、 学習されたモデルは最終的にネットワーク共有ストレージに配置し、それをTensorFlow Serving側が定期的に読み込むようにしています。
Airflowについては、過去に類似事例についてのTech Blog がありますので、興味があればご覧いただければと思います。
参考:AirflowとKubernetesで機械学習バッチジョブの運用負荷を低減した話
3. ベクトル検索
ベクトル検索は近似近傍探索(ANN: Approximately Nearest Neighbor)を実現するOSSであるVald を採用しています。
厳密なk最近傍法(kNN: k-Nearest Neighbor)ではなくANNを使うことで高速化を実現し、さらに検索に使用するインデックスを分散して保持できるため、莫大な商品数にも耐えうる仕様になっています。
Valdについて詳しくはこちらのTech Blog をご覧いただければと思います。
参考:Vald: 大規模・分散・高速な近似近傍密ベクトル検索エンジンの紹介(OSS)
推論処理の非同期化
これらの仕組みにより、膨大な商品数に対しても高速なレコメンド商品の計算が可能になったものの、それでも配信先の中には100ms以内といった厳しいレイテンシ要件が求められるところもあり、これまで紹介した手法でも要件を満たすことができませんでした。
レイテンシが遅いとレコメンドを使っていただけないどころか、UX(ユーザー体験)が下がることでサービス自体を利用いただけなくなる可能性もあるため、レイテンシの改善も非常に重要です。
それまではフロントエンドからレコメンド商品の要求がある度に同期的にレコメンド商品を推論していたのですが、レイテンシを改善させるため、各ユーザーのレコメンド結果はバックエンド側で事前に計算してNoSQLであるCassandraに格納するように変更しました。
そして、このバックエンド側でのレコメンドの計算は、ユーザーの行動や配信実績に変化があった場合などをトリガーにして、非同期処理として再計算を行うようにしました。
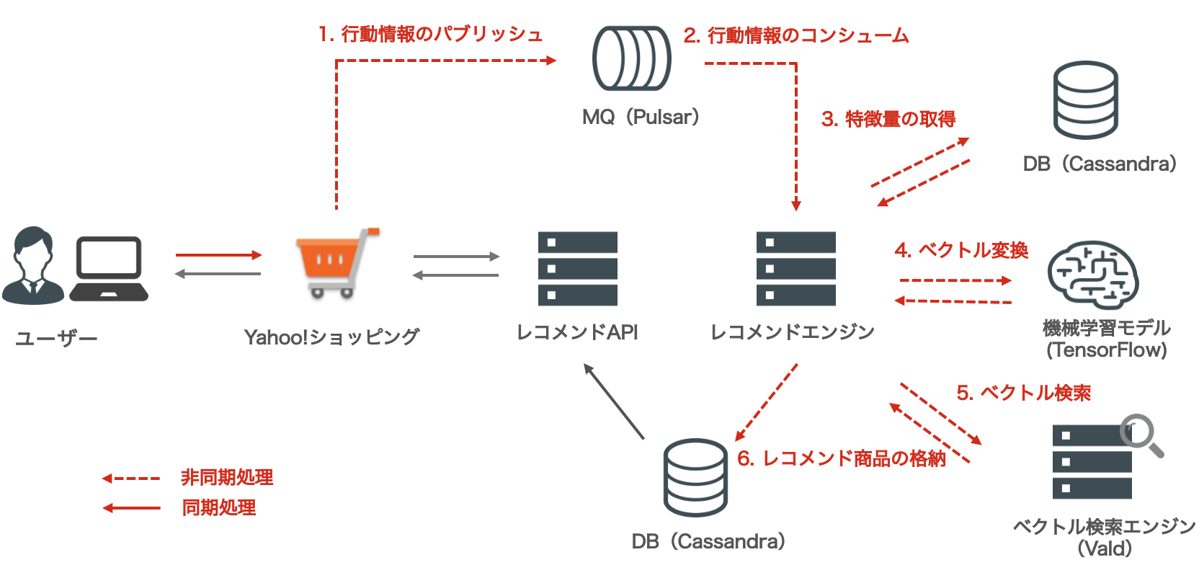
この非同期処理には主にメッセージキュー(MQ)の仕組みを使っており、具体的にはApache Pulsar (以下、Pulsar)で実現しています。
処理を非同期化することで、各システム同士が疎結合になり、バックエンド側のシステム障害が配信側に影響しにくくなるという運用上のメリットもあります。
Pulsarについて詳しくはこちらのTech Blog をご覧いただければと思います。
参考:メッセージングPF「Apache Pulsar」の使い方(入門編)
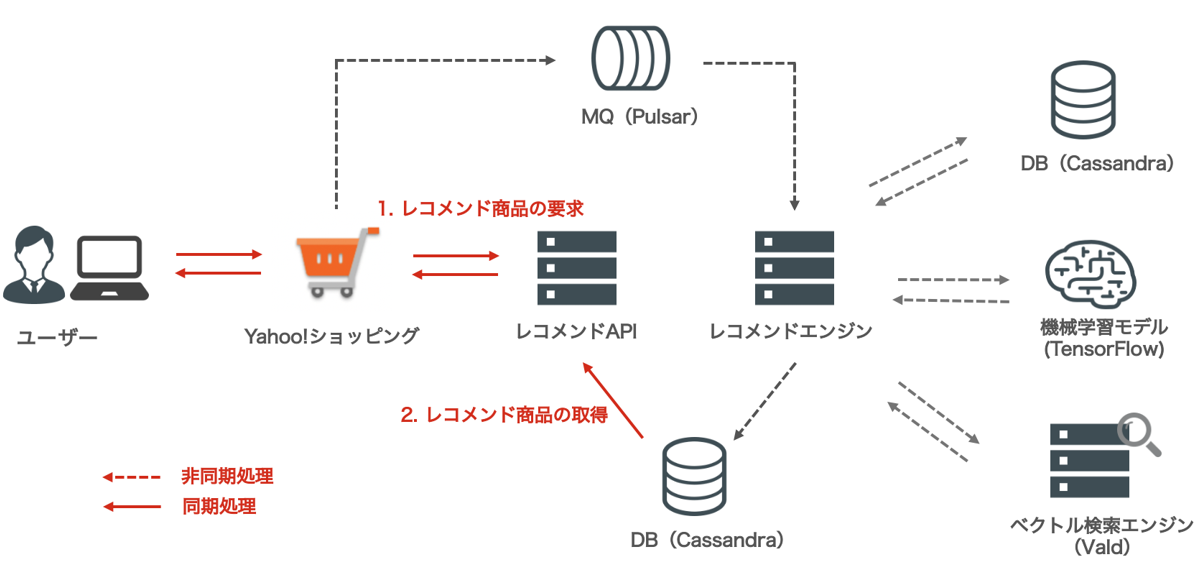
この推論処理の非同期化を導入することで、レコメンド結果の配信時は以下のようにCassandraからレコメンド結果を取得・配信するだけになり、レイテンシを大きく下げることができました。
さいごに
いかがでしたか、今回はレコメンド機能を実際にサービスで提供する際に直面した課題について紹介させていただきました。
少しでも皆様の参考になれば幸いです、そしてもし興味を持っていただいた方がいらっしゃいましたらぜひ弊社の採用募集もご検討ください!
Apache®, Apache Cassandra™, Cassandra™, Apache Airflow™, Airflow™, Apache Pulsar™, Pulsar™及びCassandraのロゴ, Airflowのロゴ, Pulsarのロゴは、米国および/またはその他の国におけるApache Software Foundationの商標または登録商標です。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました
- 高久 陽平
- 機械学習エンジニア



