こんにちは。Yahoo!広告のデータマーケティングソリューション(以下、DMS)を開発しているデータアナリストの薄田です。
みなさんは、中間テーブル同士が複雑に絡み合い変更しようにも影響範囲を推定できず、手がつけられない分析パイプラインの保守で苦労された経験はないでしょうか?
私のチームでは数千行におよぶ分析用SQLをリファクタリングして、保守性と生産性を両立する分析パイプラインに生まれ変わらせることができました。
この記事ではリファクタリングを通して確立した、分析用SQLを構造化するための4原則を紹介します。4原則を意識しながらSQLを書くことで、高凝集・疎結合な分析パイプラインを作ることができます。
この記事では凝集度と結合度の概念についての説明は省略します。
しかし、ソフトウェア開発に慣れていないアナリストにとって「凝集度と結合度」はなじみのない概念かもしれません。
結合度・凝集度について知りたい方は例えば以下の記事を読んで頂くのが良いと思います。
- 良いコードとは何か - エンジニア新卒研修 スライド公開(外部サイト)
ヤフーのDMS(データマーケティングソリューション)とは
DMSとはヤフーが保有するビッグデータに基づいた分析商品で、消費者理解から広告効果分析までさまざまなマーケティングのための分析を提供しています。
DMSで提供している分析の種類を本当に多種多様で、分析の種類によっても設計は異なります。
この記事は特に広告効果測定系のソリューションの裏側を紹介します。
DMSのアーキテクチャ
DMSがクライアントに提供されるまでの流れは以下です。
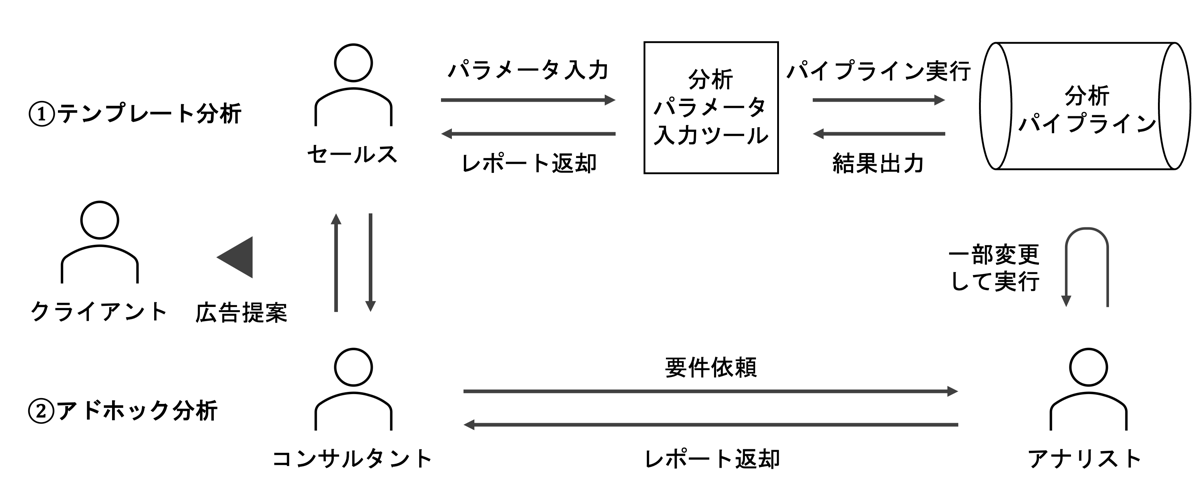
レポートが提供される流れには2パターンあります。
- テンプレート分析: ツールを通して営業やコンサルタントが直接分析パイプラインを実行する
- アドホック分析: 分析パイプラインを開発・運用しているアナリストが分析要件を直接聞いて、一部カスタマイズして分析レポートを作成する
特徴的なのは、毎回異なる条件だが同じ目的のレポートを大量にさまざまなクライアント向けに提供し続ける必要がある点です。
自社サービスのデータ分析を行うアナリストだと、定常的なレポートをBIツールなどで提供し続けることをメインの業務とされている方も多いかもしれません。
提供先の異なる分析をここまで大量に行っている例はなかなか珍しいのではないでしょうか。
課題背景
このように短期間で大量の分析をこなすことが求められる環境で以下のような課題がありました。
- 一度分析パイプラインを組んで定期実行させれば終わりではなく、毎回異なる条件で実行されることが前提の条件分岐なども考慮した実装を行う必要がある
- レポートは基本的に提案資料として使われるため、分析結果の納品までには非常にスピード感が求められる
- データ活用の活発化に伴い分析要件も高度化し、要求される分析の幅と難易度が高まる一方である
ここに担当者の変更やデータ基盤の変遷なども相まって分析パイプラインは徐々に複雑化し、少しのカスタマイズにも時間が掛かるいわゆる負債化した状態となっていました。
従来の方法ではビジネスが要求するスピード感とレベルの分析を提供することが難しくなってきており、カスタマイズのミスによるインシデントにもつながりかねない状態です。
以上の背景から将来的な生産性の向上とインシデント回避のために大規模なリファクタリングを実施するに至りました。
この記事ではそのリファクタリングを通して確立した、分析パイプラインを構造化して保守性と生産性を両立するための4つの原則を紹介します。
分析用SQLの4原則
4原則は以下の通りです。

これらの原則は、分析パイプラインをいかに高凝集・疎結合にするかという観点から試行錯誤した結果現れたものです。
以降で各原則についてそれぞれ「どんなものか」「何が嬉しいのか」「実践のコツ」「背後にある考え方」を紹介していきます。
1.SQLを関数とみなす
これはなにか
これは分析パイプライン全体に適用される原則で、SQLを「FROM句を引数、SELECT句を返値とするような関数」だとみなす考え方です。
この考え方は、近年はやりのdbtやDataformなどのデータモデリングツールと同様のものと認識しています。※説明の便宜上、SQLをSELECT文に絞っています。
何が嬉しいか
SQLを関数としてみなすことができると何が嬉しいのでしょうか?
それは、結合度・凝集度という構造化プログラミングの考え方をSQLに適用できることです。
この「SQLを関数とみなす」原則は、以降に紹介するその他の原則の考え方がベースにもなっています。
理論的な土台だけではない、直接的なメリットとして「SQLを関数とみなすことでテストが可能になる」こともあげられます。
アナリスト界隈ではSQLに変更を加えるたびに目視で動作確認をする開発プロセスが通例かもしれません。
しかしこの原則の適用後は、分析パイプラインを構成するそれぞれのSQLに対してテストを作成できるようになりました。
その結果、ユーザーが自由にパラメータを入力して実行するテンプレート分析の品質保証を仕組み化することができました。
実践のコツ
私たちのチームではSQLを関数化するために、KedroとJinjaを組み合わせ、以下のように入力と出力をパラメータ化しています。
-- 入力するテーブル名と出力するテーブル名を外部から差し込む
CREATE VIEW {{output_name}} AS (
SELECT
id,
...
FROM
{{ref('input_name')}}
);私たちのチームではアドホック分析とテンプレート分析を両立させたいことやメンバーの経験値などが理由でデータモデリングツールを利用していません。
しかし、特別な理由がない場合は同様の考え方に基づくデータモデリングツールを使ったほうが楽にSQLを関数化できます。
背後にある考え方
この「SQLを関数とみなす」考え方はどこから来たのでしょうか?
考え方のベースはKedroとdbtの設計思想です。
どちらも共通してパイプラインをDAGとみなし、入力と出力から自動でパイプラインを構築します。
またソフトウエアエンジニアリングの叡智をデータ分析の仕事にも適用し、分析コードの保守性や信頼性を高めたり、アナリストの生産性やコラボレーションの質を高めることを目指している点も共通です。
Kedroではパイプラインの各ノードでPythonの関数を実行する仕組みになっているため、関数に関するさまざまなプラクティスを適用できます。
dbtの公式ドキュメントに「SQLを関数とみなす」という直接的な記述は見つけることはできませんでしたが、ref関数などを利用してモデル依存関係を定義する考え方はKedroと全く同じです。
このkedroとdbtの考え方の類似性を着想の原点として生まれた発想が「SQLを関数とみなす」の原則です。
今までSQLは他の言語とは少し性質の異なる言語であり、その他の言語とは切り離された文脈でベストプラクティスが議論されていたように思います。
しかし入出力を抽象化すればSQLは関数とみなすことができ、分析パイプラインについても凝集度・結合度の指標に基づいてコードの良し悪しの判断ができるようになります。
その他の原則は「SQLを関数とみなす」考え方をベースとしたときに、SQLの集合である分析パイプラインを良い性質(高凝集・疎結合)を備えたものにするためにはどうすればいいか、
「どのようなSQLを書けばいいか?」「分析パイプラインの中間テーブル/ビューが満たすべき条件はどのようなものか?」という着眼点からチーム内で対話と試行錯誤を繰り返した結果導き出されたものです。
2.テーブルの意味を明確にする
これはなにか
「テーブルの意味を明確にする」原則は分析パイプラインを構成する1つ1つの中間テーブルやビューに適用される考え方です。
この原則はSQLの凝集度を高めることに役立ちます。
この原則が意味するところは「SQL内のテーブル(ビュー)名には意味が明確なたった一つの名前をつけるべきである」です。
何が嬉しいか
この原則を適用することで、SQLの中身を見ずともテーブル名を見るだけで何をやっているのか把握できるようになります。
同時に目的が一つに定まるためSQLのテストが書きやすくなります。
SQLの再利用性も高まり、複数の分析パイプラインで1つのSQLを共通化できるようになります。
その結果、テスト済みの信頼度の高いSQLを使い回す形で分析パイプラインを構築することができ、テンプレート分析の信頼性を向上させることに役立っています。
実践のコツ
例えば以下のようにすることがこの原則を守ることにつながります。
- 1つのSQLでやることは1つだけに絞る(1SQL1目的)
- 変更の理由が一つだけになるようにSQLを分割する
- 1度に複数種類の集計を行わない
- パフォーマンスの向上が期待できる場合は積極的にVIEWを使う
具体的な例(PV数とCV数の集計)を紹介します。
「テーブルの意味を明確にする」の原則において、上が良い例で、下が原則に違反する悪い例です。
-- GOOD: あえてテーブルを分割しておくことによって、別の分析パイプラインでもSQLを使い回すことができる
CREATE VIEW pv_cnt AS
SELECT
COUNT(id) AS cnt
FROM pv_table
;
CREATE VIEW cv_cnt AS
SELECT
COUNT(id) AS cnt
FROM cv_table
;-- BAD: 異なる集計を同じテーブル内で行っているため、仕様変更の際に
SELECT
COUNT(flag_pv) AS pv_cnt,
COUNT(flag_cv) AS cv_cnt
FROM data_mart
;私たちのチームでは、SQLのファイル名とテーブル名を一致させるというルールを設けることでこの原則が守られるようにしています。
また、テーブル名には動詞(処理の内容)ではなく名詞(処理の結果)に注目して名前をつけるようにもしています。
処理の内容に注目した命名にすると、冗長になりがちでパッと見の可読性が下がる、関心事がぼやけ密結合なSQLになりがちというデメリットがあるからです。
-- GOOD: 名詞(処理結果)に注目した命名
CREATE VIEW log_impression AS -- インプレッションログ
CREATE VIEW sample_control AS -- コントロール群のサンプル
CREATE VIEW user_click_cnt AS -- ユーザーごとのクリック数
CREATE VIEW uu_click_by_gender AS -- 性別のクリックUU
CREATE VIEW report_lift_value AS -- リフト値のレポート-- BAD: 動詞(処理内容)に注目した命名
CREATE VIEW extract_log AS -- ログを抽出する
CREATE VIEW create_user_list AS -- ユーザーリストを作成する
CREATE VIEW aggregate_uu AS -- uuを集計する
CREATE VIEW join_imp_click AS -- インプレッションとクリックを結合する
CREATE VIEW output_report AS -- レポートを出力するこの原則を守ることは細かく複数のテーブルに処理を分割することを意味するため、パフォーマンスの低下などエンジニアリング上の不都合につながる場合もあります。
そのため、基本的にはビューを使用して、テーブルの実体化はGROUP BYなどデータの要約を行うときだけに限って行うなどの工夫をしています。
私たちのチームではスキャン量課金のAmazon Athenaを主要な分析環境として利用していることもあり、特に気を使っている部分です。
背後にある考え方
関数(クラス)に適切な名前を命名することで、「関心の分離」を実現し高凝集・疎結合な設計を実現できることが知られています。
SQLを関数とみなした時に、関数名に当たる部分がテーブル名です。
つまり「テーブルの意味を明確にする」原則は言い換えると「関心の分離を意識した名前設計をすること」です。
参考: 関心の分離を意識した名前設計で巨大クラスを爆殺する
「テーブルの意味を明確にする」ことは「単一責任の原則」を守ることにもつながります。
「単一責任の原則」は関数(クラス)の変更理由が1つより多く存在してはいけないという原則です。
ここから「テーブルの意味を明確にする」ためには、異なる種類の集計をデータソースが同じであるという理由だけで、一つのテーブルに含めてはいけないというガイドラインが生まれます。
SQLを書くときに1つのSELECT文の中で複数の指標を同時に計算するのはごく自然なことだと思います。
アナリストはBIツールやノートブック上でSQLを書いて分析作業を行うことが多いため、一つのSELECT文でなるべく複数のことを同時に行って結果を得た方が、スムーズに可視化につながり、分析のスピードを高めることにもつながることが多いからです。
そのため、テーブルの意味を明確にするために細かくテーブルを分割するこの考え方は直感に反する方も多いのではないでしょうか。
しかし高頻度で変更(カスタマイズ)が求められる分析パイプラインの開発では、普段手元で行っている分析作業とは真逆の発想でSQLを書くことが求められます。
「テーブルの意味を明確にする」原則は、普段の分析作業の発想からはなかなか思いつかない実装方針を教えてくれるという意味で価値のある原則です。
3.カラムからフラグを排除する
これはなにか
「カラムからフラグを排除する」原則はテーブルのカラムに適用される考え方です。
この原則を守ることで分析パイプラインの結合度を下げることができます。
テーブルにフラグを立てることは他のSQLが内部仕様に依存することを誘発するアンチパターンなので避けましょう。
フラグ(カラム)による情報の受け渡しはテーブル同士を密結合化させることを意味するため、変更時に思わぬ副作用やバグを生み出す原因になりやすいです。
代わりにレコードの単位によって情報の授受ができないか検討してみましょう。
何が嬉しいか
「カラムからフラグを排除する」原則を守ることは分析パイプラインの密結合化を回避し、柔軟で変更に強いものにする効果があります。
私のチームの分析パイプラインはリファクタリング前、以下のように前半の処理で作成されたテーブル内のフラグがあちこちで使われる設計となっておりました。
そのため、変更のたびに後続のテーブルに影響がないか確認しながら作業を行う必要がありました。
分析パイプラインも長大なため、フラグがどこでどんな使われ方をしているのかを把握しながら、変更を行う作業は時間も神経も使う大変なものでした。
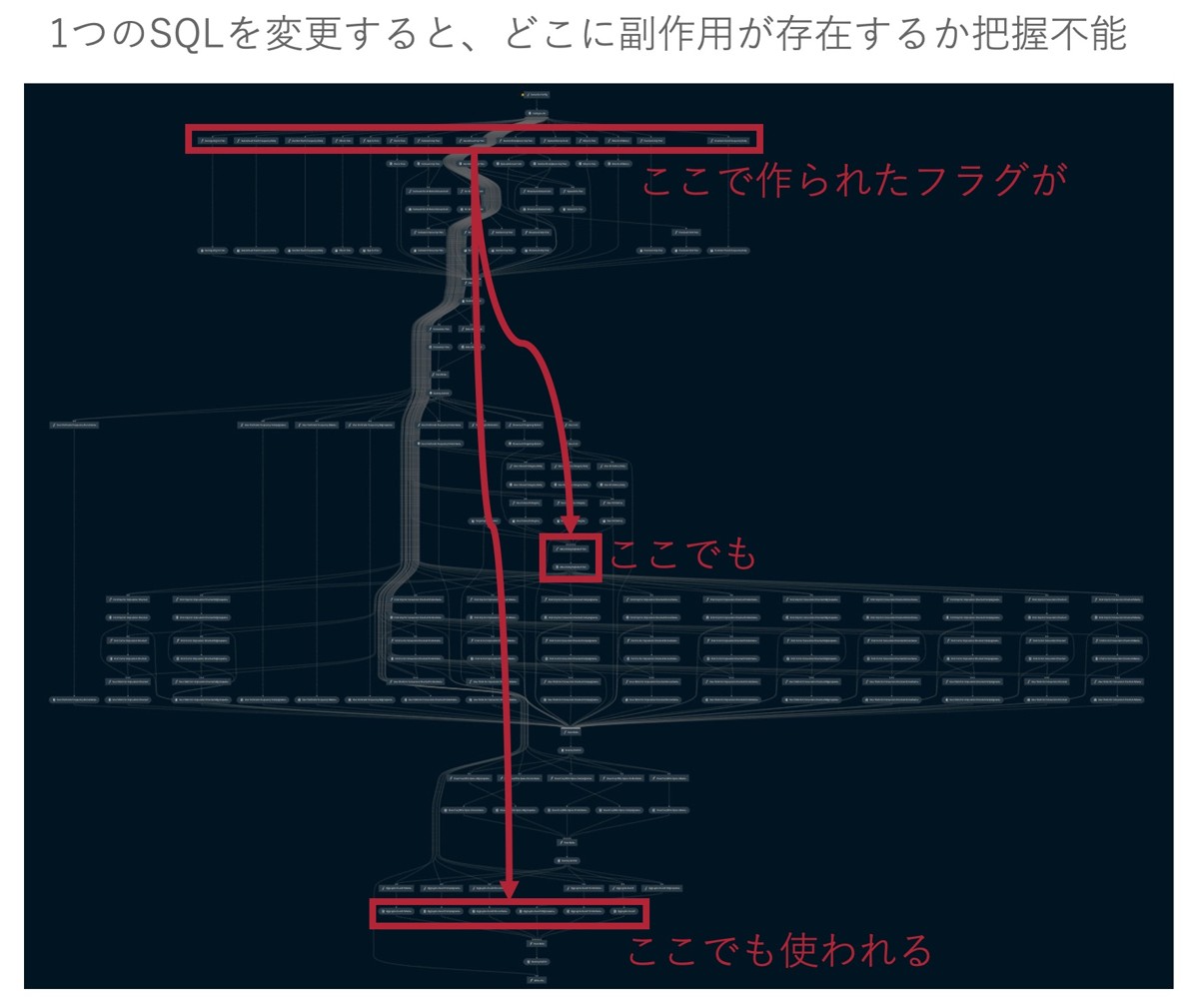
しかし、0 or 1のフラグを使う代わりにレコードの単位によって情報の伝達を行うようにリファクタリングを施した結果、テーブル同士が疎結合になり、仕様変更の影響を局所化することに成功しました。
これによって、アドホック分析で一部のテーブルの仕様を変更したとしてもその他の部分を変えずに実行できるようになり、大幅な工数削減と品質保証につながりました。
レコードの単位による情報伝達の具体的なやり方については、次の原則にて紹介します。
実践のコツ
フラグ(0 or 1)カラムを作りたくなった場合は、テーブルを分割するチャンスかもしれません。0 or 1のフラグを避けるためには、フラグの表す意味をレコードの単位で表現できないか検討してみましょう。
-- GOOD: 集計部分はカラムに依存しないレコード数の集計(`COUNT(*)`)になっているため、元テーブルの仕様変更に強い
CREATE VIEW log_click AS (
SELECT *
FROM log
WHERE click = 1
);
SELECT COUNT(*) FROM log_click;-- BAD: logテーブルのカラム名が変化した場合に集計SQLの変更も必要になる
SELECT
SUM(log.click) -- log.clickはクリックされていたら1、そうでなければ0のフラグ
FROM
log;レコードの単位に意味をもたせることで、後続の集計処理がシンプル化され、共通化もしやすくなるメリットも存在します。
これについても後述します。
背後にある考え方
テーブルをクラス、レコードをインスタンスと考えるなら、カラムはインスタンス変数(属性)とみなすことができます。
カラム=インスタンス変数(パブリック変数)ならば、パイプライン内でフラグ(カラム)を使って情報を受け渡しすることは、テーブル同士をスタンプ結合していると解釈できるのではないでしょうか。
スタンプ結合自体はそこまで悪くない結合ですが、SQLの場合は同時に複数レコード(インスタンス)を扱い、レコード数によってもカラム(変数)に対する集計の意味合いが変わってきます。
ここがその他の言語とSQLで結合度に対する考え方少し異なるポイントです。
SQLの場合は結合度が高まった場合の悪影響が大きいため、より疎結合を意識した設計が大切になります。
4.レコードの単位を意識する
これはなにか
「レコードの単位を意識する」原則はテーブルを構成する1行1行のレコードに適用される考え方です。
この原則を守ることは、凝集度を高めることと結合度を下げることの両方の役に立ちます。
「レコードの単位を意識する」ことはテーブルの抽象レベルを統一することを意味しています。
何が嬉しいか
レコードの単位を意識し、テーブルの抽象レベルを統一すると、何が嬉しいのでしょうか?
次のようなメリットがあると考えています。
- 「テーブルの意味を明確にする」ことにつながる
- 「カラムからフラグを排除する」ことにつながる
- 似た処理を行うSQLをまとめて管理することにつながるため、コードの「要約性」や「閲覧性」が高まる
- 後続の処理の単純化と共通化につながり、分析パイプラインの保守性が高まる
レコードの単位はテーブルの意味を構成する一部のため「レコードの単位を意識する」ことはそのまま「テーブルの意味を明確にする」ことを意味します。
「レコードの単位を意識する」ことが「カラムからフラグを排除する」ことにつながるとはどういうことでしょうか。
レコードの単位が不明確な(=複数の意味が混在している)場合、レコードの表す単位をカラムに追加する必要が発生します。
そのようなカラムは0 or 1フラグのことがほとんどなため「カラムからフラグを排除する」の原則の違反を誘発するということです。
コードの要約性と閲覧性が高まることや後続の処理の単純化と共通化に繋がるメリットについては、実践のコツのパートで解説します。
実践のコツ
「レコードの単位を意識する」を実践すると、具体的には以下のようになります。
- ユースケースごとに単位が同じテーブルをまとめて管理する
- レコードの意味や単位が異なるテーブルを連結(
UNION ALL)しない - まとめて管理しているテーブルのカラム名を揃える
順に見ていきましょう。
ユースケースごとに単位が同じテーブルをまとめて管理する
例えば、広告のインプレッションとクリックなどのように発生タイミングは異なるが単位(リクエスト)は同じログを扱う分析パイプラインを作る例で考えてみましょう。
この時、以下のようにレコードの単位やユースケース別にディレクトリを分けてSQLファイルを管理することでファイル構成を見るだけで、どのような処理をしているのかのイメージがつくようになります。
sql/
log/ # 生データからログ抽出と前処理を行うSQL
└impression.sql
└click.sql
└user/ # ログ単位のテーブルを丸めてユーザー単位テーブルを作るSQL
└impression.sql
└click.sql
└statistics # 総数やUU数などの集計値単位のテーブルを作るSQL
└num/
└impression.sql
└click.sql
└uu/
└impression.sql
└click.sqlレコードの意味や単位が異なるテーブルを連結(UNION ALL)しない
以下のようにUNION ALLして一つのテーブルとして扱ってはいけません。
-- BAD1: 意味の異なる2つのtableを連結させた結果、テーブルの意味が曖昧化している
-- BAD2: レコードの意味が異なる2つのテーブルを連結させた結果、レコードの単位をフラグによって管理することになっている
CREATE VIEW impression_and_click_table AS
SELECT 1 AS imp, 0 AS clk FROM log_impression
UNION ALL
SELECT 0 AS imp, 1 AS clk FROM log_clickテーブルの連結は意味と単位が同じテーブル同士でのみ行うようにしましょう。
まとめて管理しているテーブルのカラム名を揃える
ユースケースとレコードの単位が同じで、1つのディレクトリで管理されているSQLのカラム名(インターフェース)を統一することで、後続の処理の単純化と共通化ができます。
上記のファイル構成の例で言えば、logディレクトリやuserディレクトリの内のSQLでSELECTするカラム名を統一することで、statistics内の集計SQLのFROM句のテーブルを差し替えるだけで、同様の処理を記述できます。
この時、異常値や外れ値のフィルタリングなどの前処理など(WHERE句)の記述を揃えておくこともポイントです。
そうすることで、ディレクトリ内のテーブルのレコードの単位がそろいます。
その結果、以下のように集計SQLには単純で間違えようのないシンプルな処理を書くだけで済みます。
-- statistics/num/impression.sql
SELECT COUNT(*) FROM {{ref('log_impression')}} -- インプレッション数
-- statistics/num/click.sql
SELECT COUNT(*) FROM {{ref('log_click')}} -- クリック数
-- statistics/uu/impression.sql
SELECT COUNT(*) FROM {{ref('user_impression')}} -- インプレッションUU
-- statistics/uu/click.sql
SELECT COUNT(*) FROM {{ref('user_click')}} -- クリックUU「レコードの単位を意識すること」は後続の処理の単純化と共通化にもつながります。
これは特に集計用のSQLにおいて効果を発揮します。
レコードの単位を意識して、レコードの単位を直接集計の対象にする(COUNT(*))ことによって、後続の集計SQLからフラグを排除できます。
そうすることで、分析パイプラインの結合度を下げるだけでなく、集計SQLそのものの記述も単純で再利用しやすくなります。
背後にある考え方
関数の抽象化レベルを統一することで、コードの可読性と保守性が高まることはSLAPという原則で知られています。
抽象度統一の原則(SLA原則, SLAP) - doc.dev1x.org
「レコードの単位を意識する」原則はSQLにSLAPを当てはめたものです。
テーブルの抽象化レベルを統一することで、さまざまなメリットがあることは今まで紹介してきた通りです。
効果
ここで、皆さんが気になるところは「この4原則に基づいたリファクタリングには本当に効果があったのか、理論もいいけど、実用性はあるのか」という部分だと思います。
なので、リファクタリングによって生産性と保守性にどれほどの変化があったのかも紹介します。
リファクタリング以前のアドホック集計は数千行にもおよぶ分析用SQLのコードをコピペして、一部を書き換えてからSQLを再実行するという流れでした。
このやり方だと、変更範囲の特定や変更の正しさの確認などにとてつもない時間と労力が取られていました。
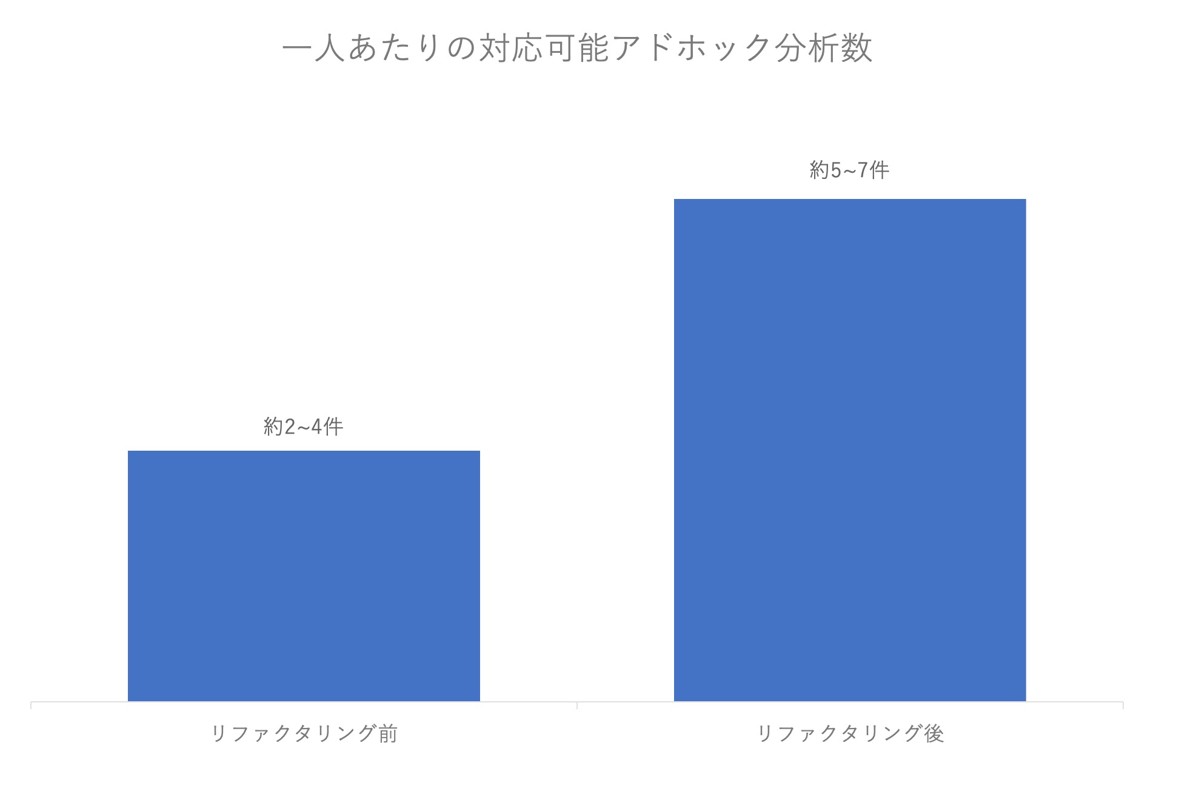
そのため、1カ月に1人のアナリストがこなすことのできるアドホック集計は多くて2〜4件程度でした。
そして、アドホック集計の依頼に対して少なくとも5営業日以上の納期をもらっていました。
しかしリファクタリングの実施後は一人で5件〜7件程度のアドホック依頼をこなすこともできるようになりました。
基本的に部品化されたSQLの差し替えで対応可能なため、コード追加による機能変更で、変更による影響の範囲も限られているためレビューの工数も大幅に削減することができました。
その結果、今までレビューも含めると5営業日以上必要だったアドホックの分析依頼が、最短数時間で完了できるようになりました。
現在は、この原則を適用した分析パイプライン構築をより一層簡単にすべくツールの開発にも取り組んでいます。
まとめ
以上が1つ数千行にもおよぶ分析用SQLをリファクタリングする過程で得られた保守性と生産性を両立する分析SQL構造化の4原則です。
4原則を意識しながら分析用のSQLを書くことで以下のような良いことがありました。
- 既存のコードの変更なしに追加の分析要件に対応でき、変更による影響の範囲も局所化できる(オープンクローズドの原則)
- SQLの単体テストや分析パイプラインの統合テストが可能になり、品質保証を仕組み化できる
- それら品質が保証されたSQLの組み合わせで分析パイプラインを柔軟に再構築できるため、生産性と保守性が両立できる
私たちのチームでは手元で気軽に実行できることなどを重視して分析パイプライン構築ツールであるKedroとテンプレートエンジンのJinjaを組み合わせて分析パイプラインを構築していますが、dbtやDataformなどSQLを関数化(入出力をパラメータ化)するライブラリを使用すれば4原則を適用できます。
今回紹介した4原則はあくまで分析用SQLという最終的なユースケースがはっきりした集計分析用の分析パイプラインを構築する際のものです。
DWHやデータマートの構築など汎用的なデータソースを作成するためのデータパイプラインの構築には当てはまらない部分もあることはご注意ください。
そのようなデータモデリングには、スタースキーマなどディメンショナルモデリングを参考にするほうがより適切かもしれません。
おわりに
この記事では分析用SQLの保守性と生産性を両立するための4原則を紹介しました。
この4原則の考え方が皆さんのSQLコーディングの参考になれば嬉しいです。
最後まで読んで頂きありがとうございました。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました

- 薄田 祐大
- データアナリスト
- Yahoo!広告のデータマーケティングソリューションを開発しています。
-



