こんにちは、広告エンジニアの中山です。
唐突ですが、みなさまの Web アプリケーションに User-Agent 文字列を参照する処理はありますか?
User-Agent: Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.1234.56 Safari/537.36例えば User-Agent 文字列を解析して内容に応じて制御を分岐させたり、機械学習の特徴量として用いたり、さらには一般に悪しきユースケースとされていますが IP アドレスと組み合わせて fingerprinting に活用する … といった処理があるかもしれませんね。
私の担当する広告サービスでは
- 不正判定 のための特徴量
- ユーザー属性推定のための特徴量
- その他配信制御(例えばキャリアのターゲティングや特定バージョンのバグ回避など)
といった用途で参照しています。補足としてキャリア判定には通常 IP レンジを用いますが、Wi-Fi 経由のアクセスに対しては User-Agent 文字列に含まれる情報とモデルのカタログを用いて判定できる場合があります。
さて、そんな User-Agent 文字列ですが、今後 Google Chrome をはじめいくつかのブラウザで情報量の削減や凍結が進み、上に挙げた目的での利用は難しくなる見込み です。今回はその対策についてみなさんと一緒に考えてゆきたいと思います。
また、特に断りのない限り、この記事では Google Chrome に関する内容を述べているものとします。
なぜ User-Agent 文字列は情報量を削減され、凍結されるのか?
そうすべきモチベーションとして、代替技術(詳しくは後述)のドキュメントに 以下のような記載 があります。
This header’s value has grown in both length and complexity over the years; a complicated dance between server-side sniffing to provide the right experience for the right devices on the one hand, and client-side spoofing in order to bypass incorrect or inconvenient sniffing on the other.
長く、そして複雑怪奇な文字列仕様を解消し
There’s a lot of entropy wrapped up in the UA string that is sent to servers by default, for all first- and third-party requests.
あわせて高エントロピー故にユーザー追跡を可能にしてしまう問題 … いわゆる fingerprinting ですね … を排除するための取り組みとのことです。以下は Google から 案内されているスケジュール を時間軸にプロットしたものです。表中の黄色のセルは情報量を削減され、凍結されるトークンを示しています。
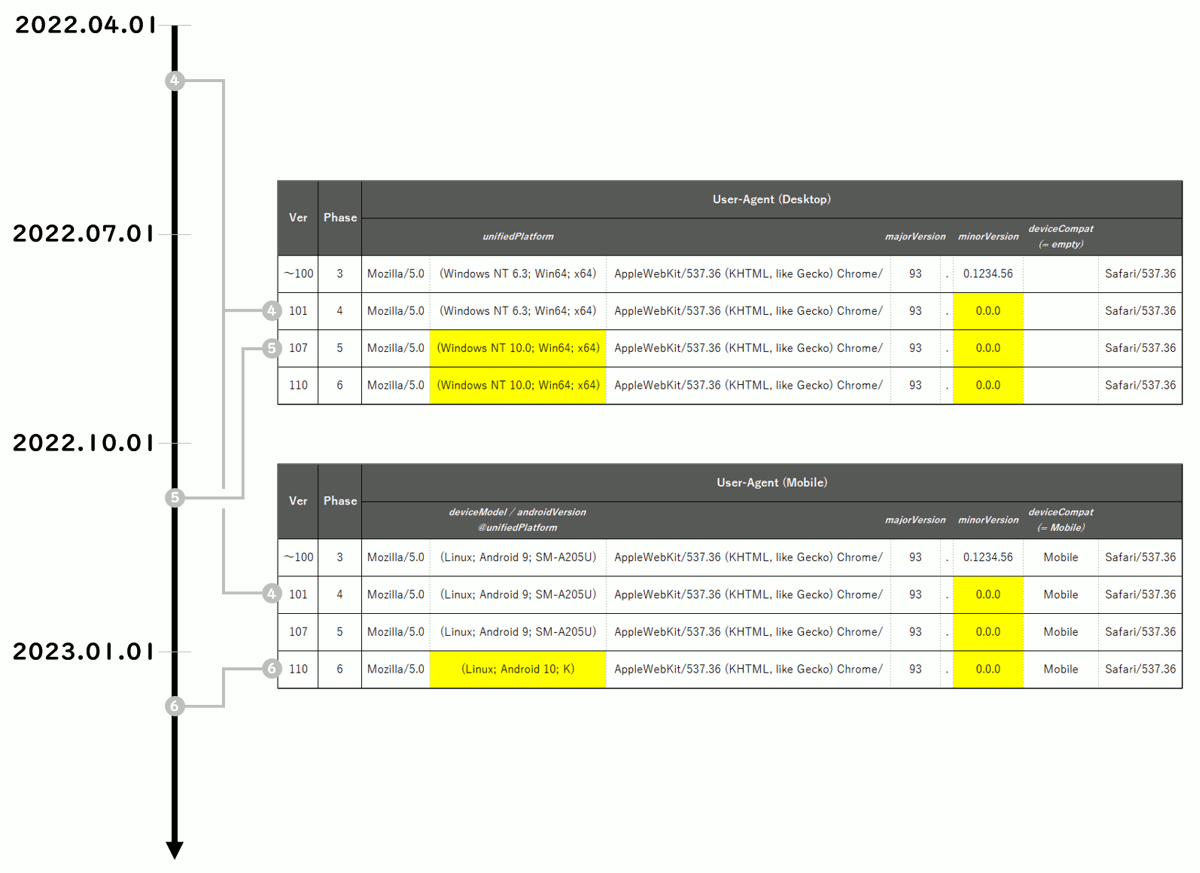
いつ困ることになりそうか?
既に過去のものとなった
In Phase 4 we change the
token to “0.0.0”.
および
In Phase 5 we change the
and tokens from their platform-defined values to the relevant token value (which will never change).
については、広告の例ですと不正判定や配信制御への影響が考えられます。とはいえ、肌感覚としてはそこまで大きな影響ではありません。一方でそれなりに大きな影響が出そうなのは 2023 年が明けてからの
In Phase 6, we change the
token to “K” and change the token to a static “10” string.
のタイミングです。

このタイミングで androidVersion が “10” に、そして deviceModel が “K” に固定されることになります。そうなると …
- deviceModel がユーザー属性に対する説明力を失う
(例えば「らくらくスマートフォン」のユーザーは高齢者である可能性が高そう … などの推定ができなくなる) - deviceModel からキャリア判定ができなくなる
- Mobile の androidVersion をブロックリスト制御やセーフリスト制御に使えなくなる
(Desktop の unifiedPlatform と比べ Mobile における特定のバグ回避ニーズは高いと思われます)
のような影響が生じます。
余談ですが Chrome 以外のブラウザについては 2022/09/08 現在では以下のような状況です。
| ブラウザ | User-Agent 文字列の状況 |
|---|---|
| Edge | “Edg/“ に続く minorVersion が残存(”0.0.0” ではない) |
| Safari | unifiedPlatform が既に固定されている |
| Firefox | unifiedPlatform が既に固定されている |
User Agent Client Hints(UA-CH)による対策案
われわれは Phase 6 の影響をどのように回避すべきでしょうか。
ブラウザはサーバに対して以下のような「User Agent Client Hints(以降 UA-CH)」を要求ヘッダとして送信しますが、結論としてはこの UA-CH を活用することで影響を最小化することができます。
sec-ch-ua: "Chromium";v="106", "Google Chrome";v="106", "Not;A=Brand";v="99"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "Windows"ただし、この UA-CH はそのままでは User-Agent 文字列に含まれる deviceModel などの情報を得ることができないため、
- サーバが Accept-CH を応答ヘッダとしてブラウザに送信し、追加情報を要求する
- ブラウザ側で UA-CH JS API を用いて追加情報を取得する
などの手段が必要になります。追加情報取得手段について表にまとめてみました。
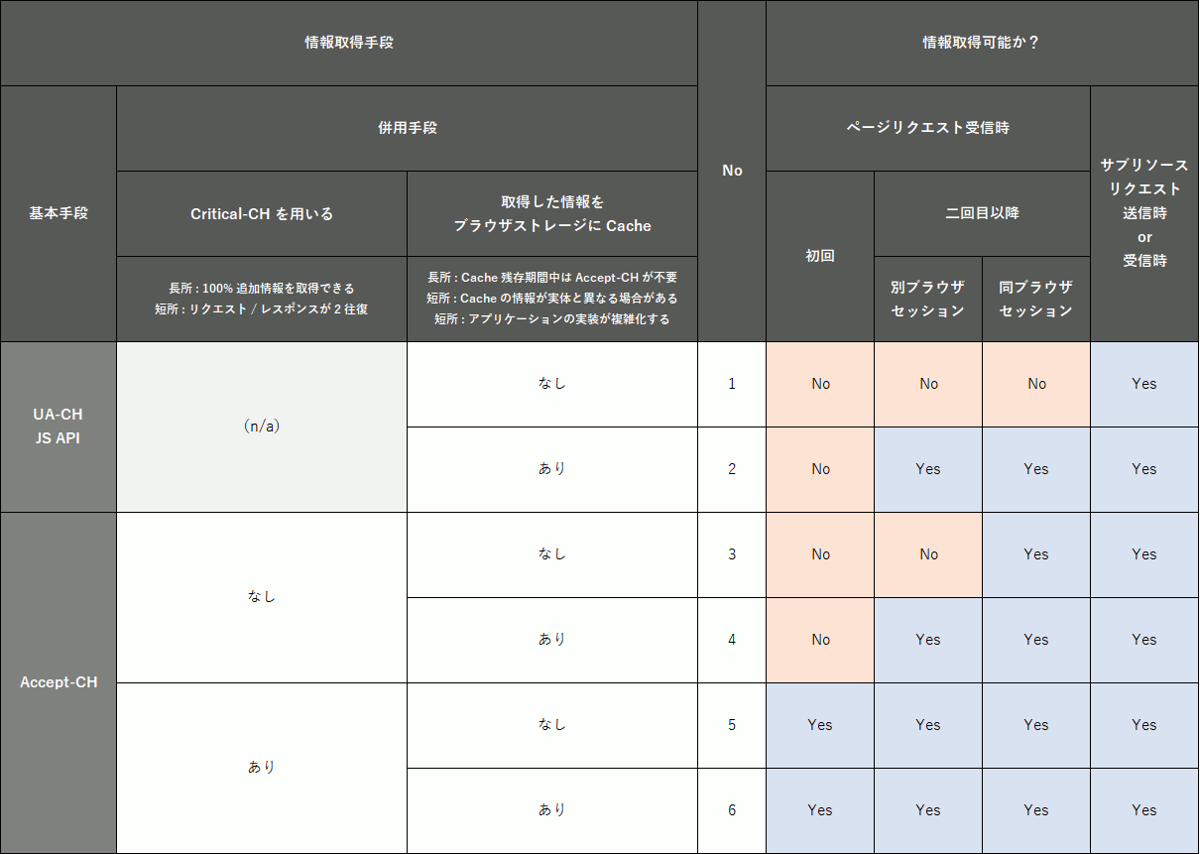
それぞれの選択肢について考察してみましょう。
1. UA-CH JS API
既存の Web アプリケーションが DOM の Navigator オブジェクトから情報を取得している場合には移行しやすい方法です。一方で、将来 Privacy Budget(取得可能なデータ量に制限を設ける仕様) が導入された際の対応を想定しておく必要がありそうです。
navigator.userAgentData.getHighEntropyValues(['model']).then(ua => {
console.log(ua.model);
});2. UA-CH JS API x Cache
取得した追加情報を localStorage や Cookie に Cache することで 1 の Privacy Budget の制限抵触リスクを低くすることができます。
3. Accept-CH
既存の Web アプリケーションが HTTP の User-Agent 文字列から情報を取得している場合には移行しやすい方法です。課題は 1 同様に将来 Privacy Budget 対応が必要になりそうなことと、初回ページリクエストのタイミングで機会損失が発生することです。
Accept-CH: Sec-CH-UA-Model4. Accept-CH x Cache
取得した追加情報を Cookie に Cache し、フォールバック処理を UA-CH 参照 → Cache 参照 → User-Agent 文字列参照 … とすることで機会損失を最小化し、Privacy Budget の制限抵触リスクを低くすることができます。フォールバック処理については Migrate to User-Agent Client Hints にも記載があります。このあたりは具合の良いライブラリの登場を期待します(他力本願 ^^;)。
When processing this on the server-side you should first check if the desired Sec-CH-UA header has been sent and then fallback to the User-Agent header parsing if it is not available.
5. Accept-CH x Critical-CH
Critical-CH を使うことで機会損失を解消できますが、セッションをまたいだ初回アクセス時にはリクエスト + レスポンスが 2 往復することになるため、アクセスの多い Web アプリケーションの場合は避けたい設定です。
6. Accept-CH x Critical-CH x Cache
取得した追加情報を Cookie に Cache することで 5 の課題をおおむね解消できますが、プライベートブラウジングによるアクセスが多い場合には解消できません。とはいえ、機会損失最小化の優先度が高い場合には現実解となりそうです。
Accept-CH の有効範囲について
ここまでの考察から選択肢の 5 はデメリットを考慮して除外します。さらに Privacy Budget は導入時期や仕様が明確になってからの検討でもよさそうなので 2 も除外します。残りの選択肢については既存の Web アプリケーションが …
- DOM の Navigator オブジェクトから情報を取得しているならば 1 を採用
- HTTP の User-Agent 文字列から情報を取得しているならば、機会損失に対する受容度合とアプリケーションの複雑化のデメリットを勘案して 3, 4, 6 から選択
… とするのがよさそうです。今回われわれは 3 を選択することにしました。
ところで、広告のようなサービスの場合、サブリソースとしての UA-CH 活用を考える必要があります。サブリソースに対して追加の UA-CH 送信を求める場合、サーバ(ページ)が Permissions-Policy を応答ヘッダとしてブラウザに送信する必要がありますが、それ以外のユースケースついて表にまとめてみました(動作確認をした Chrome のバージョンは 107.0.5304.107)。
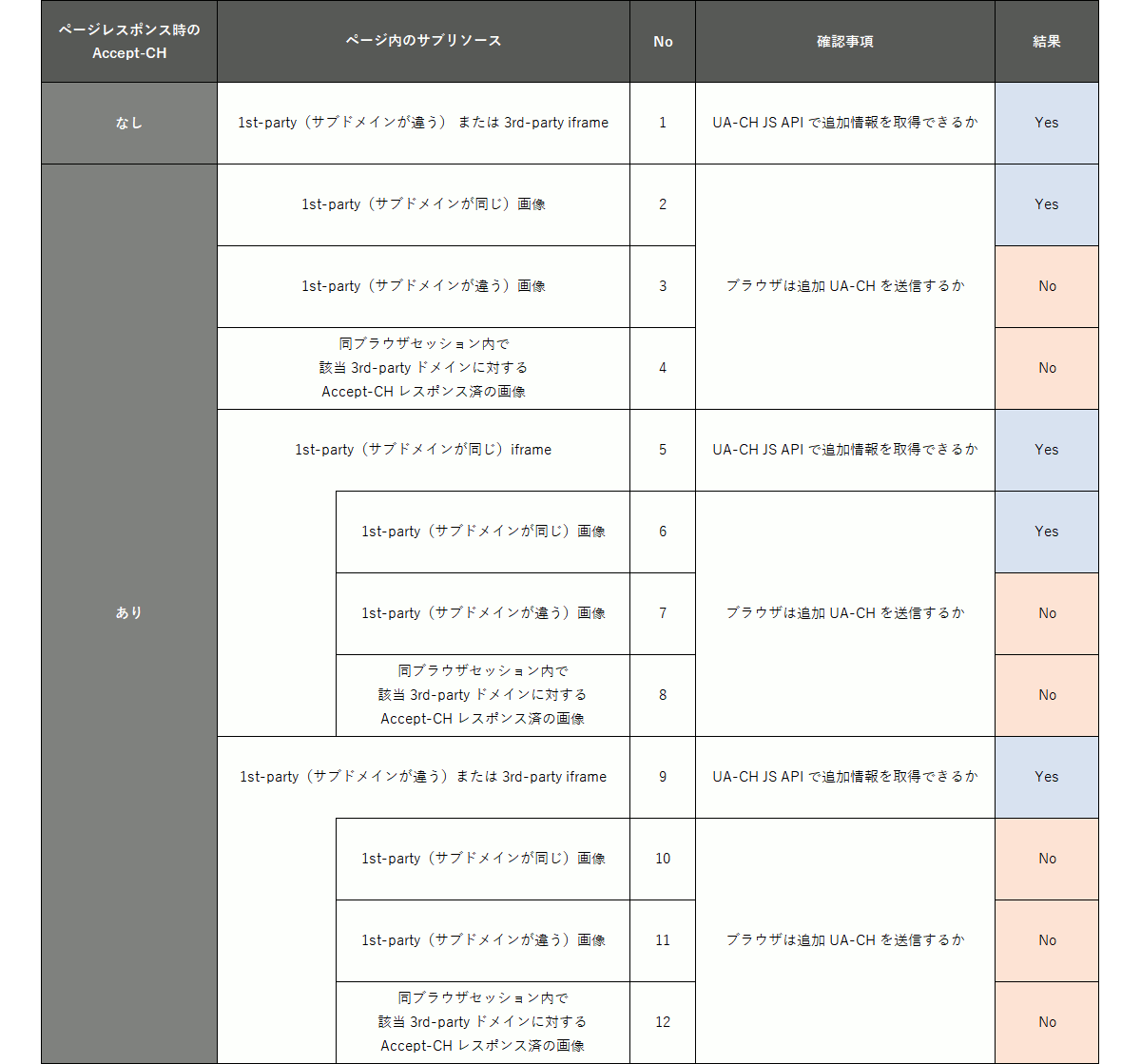
表の内容を要約すると
- サブリソースとページのサブドメインが一致する場合、ページが Accept-CH をレスポンスすることでサブリソース側でも追加情報を取得できる
- それ以外のサブリソースで追加情報が必要な場合、ページが Accept-CH + Permissions-Policy をレスポンスする必要がある
- サブドメインが一致しない iframe 内のサブリソースの場合、ページのサブドメインに一致しても追加情報は取得できない
- UA-CH JS API ならばドメイン問わず追加情報を取得できる
となります。
蛇足ですが Web アプリケーションに限らず、ログを扱うアプリケーションでも集計や機械学習などで User-Agent 文字列を扱うケースは少なくないと思います。理想的には Web アプリケーションではライブラリで User-Agent 文字列や UA-CH の解析処理やフォールバック処理を隠蔽し、ログには構造化した情報を書き出す形にして、ブラウザ依存処理を一か所に集約したいですね。
おわりに
今は、もう、動かない、その User-Agent 文字列 … までの残り時間はあとわずかです。
UA-CH の ドキュメント には
the user agent / omitted / can intervene and modify or refuse to provide certain bits of information. This is a privacy win for users.
とありますが privacy win for users の実現に向けて、この記事がみなさまの UA-CH 対応の一助となれば幸いです。
加えて、ヤフー広告では UA-CH 対応に限らず privacy win for users と広告エコシステム発展の両立を志す仲間を募集中です! われこそはという方のご連絡をお待ちしております。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました

- 中山 一紀
- 広告エンジニア
- プライバシー保護と広告エコシステム(ビジネス)発展の両立を日々探求しております
-



