こんにちは。ヤフーで画像処理エンジニアをしている吉橋です。この記事ではヤフーのさまざまなサービスで使われている独自の画像文字認識(OCR)技術と、特に最近のPayPayフリマ「本棚一括持ち物追加機能」での活用事例をご紹介します。
画像文字認識とは
皆さん、ウェブサイトを見ていて「このキーワード気になるな……よしコピーしてヤフーで検索してみよう! と思ったらこれ画像じゃん、コピーできないよ……」なんて困ったことはありませんか?
ウェブで私たちが目にする情報は“テキスト”と“画像”の2種類が主なものです。
- テキスト: 文字列としての情報を保持したデータであり、コピーやウェブ検索に利用したり解析したり、容易に活用できます。
- 画像データ: 文字列ではなく画素の色情報の集合として表現されていて、画像の中に人間が読み取れる文字が見えていたとしても、実際はテキストとしての情報は失われているのでコピーしたりウェブ検索に使うことはできません。
最近ではスマホで画面を記録した“スクリーンショット”をSNSなどで見かけることも多いと思います。これも後者・画像データであり、スクリーンショット内部の気になるテキストやウェブアドレスをコピー&ペーストできないのが不便ですね……
そんなときに便利なのが画像文字認識(optical character recognition, OCR)技術です!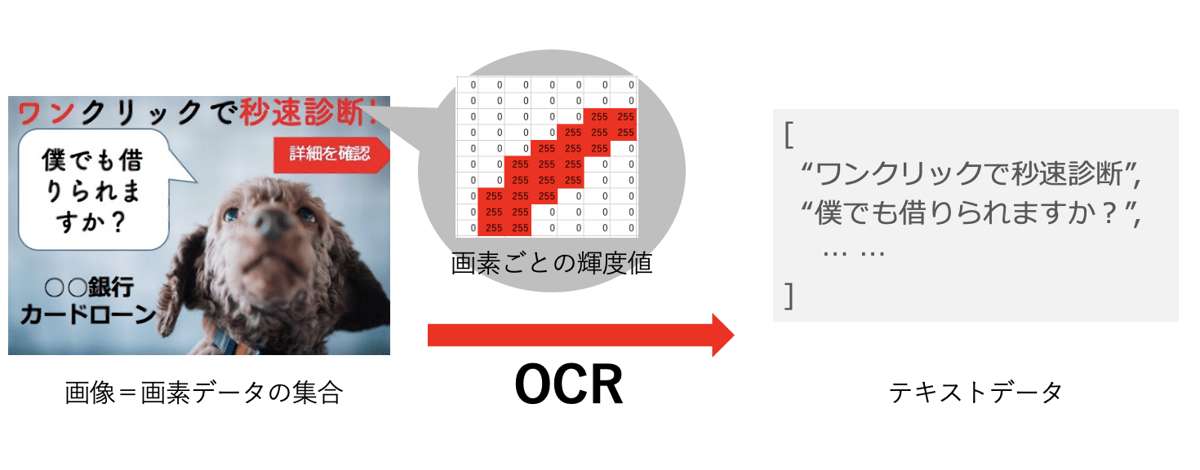
OCRとは画像解析を用いて画像中に出現する文字を書き起こし、テキストデータに変換してくれる技術です。このOCR技術を、ヤフーでも独自に開発し、サービスのユーザーの皆さんに便利を提供するため、また社内での事務処理を効率的にするために活用しています。
OCRを機械学習で実現
古典的にはOCRはテンプレート照合のようなパターン処理技術で作られていましたが、昨今のAIブームの中、OCR分野にも深層学習を代表として機械学習技術が活用されています。ヤフーでも独自の日本語画像学習データを構築し、サービスに合った機械学習モデルの開発に取り組んでいます。
学習データ:フォント合成で自動生成
機械学習を利用する上で問題となるのは「どのように十分な精度を達成するための学習データ量を確保するか?」ということです。ヤフーのOCRでは学習の効率化・低コスト化のために学習データの大部分は合成データを利用しています。まずランダムなテキストデータとフォントを利用して画像化したテキストデータを用意し、これを別途用意した他のテキストがない背景用画像データに合成して、テキスト画像データのパターンを増やしていきます。またこれによって読み取りに必要な文字種・記号類を合成元のテキストを変更していくことで網羅できます。

しかし同時に、合成データはリアリティーに欠けるためこれだけでの学習では実際の画像での読み取り精度は高くないことが判明しています。そこで現在は大量の合成データに一部実際のYahoo!ショッピング画像などの実画像を数千枚程度混ぜ込んで学習させています(ショッピングストア利用約款に沿って利用しています)。実画像では人手によるアノテーションによってテキスト領域・読み取りの正解などを付与して機械学習に利用できるようにしています。
ニューラルネットワークモデル:OSSを活用
OCRでは2つの機械学習モデルを利用しています。1つ目はテキスト検出モデルで、これは画像中のテキスト領域を発見・抽出してくれるものです。もう一つはテキスト認識モデルで、こちらは検出モデルの発見した領域を一つずつ読み起こし、テキストデータに変換してくれます。
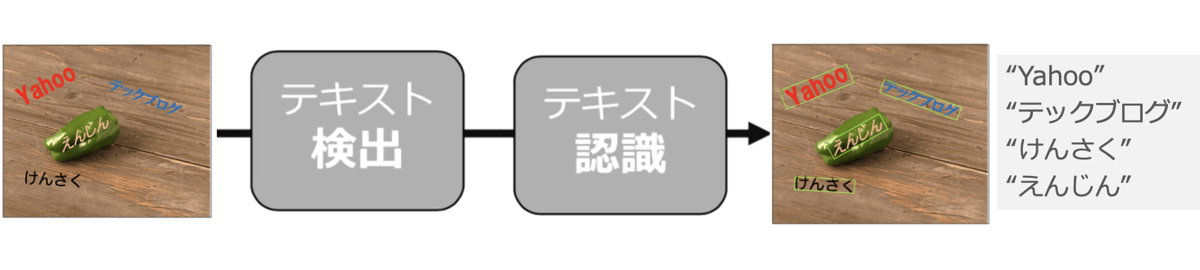
実際の手法としては検出のためにはCRAFT、認識はCRNNを改造をしたものを利用しています。どちらもNaver製のOSSであり、ニューラルネットワークに基づく手法です。これらにデータに合わせた調整をしてから活用しています。
独自技術の研究開発:言語処理・エッジ推論
OSSベースのOCRの提供と並行して、さらに便利なOCR機能の提供に向けた独自技術の調査・開発にも取り組んでいます。その中でも最近特に注力している「言語処理技術との融合」「エッジ推論」についてご紹介したいと思います。
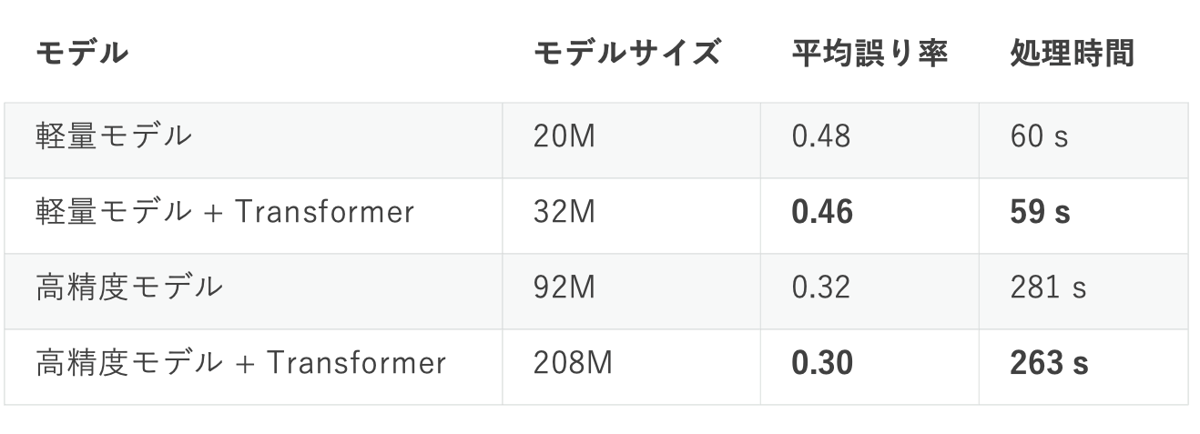
言語処理はAI領域の中でも特に最近“熱い”分野の一つで、Google発の強力ニューラルネット“Transformer”とその学習手法“BERT”によって大きく進展しました。特にBERTはヤフーの言語処理でも既に活用されています。OCRは画像とテキスト情報をまたぐ処理であるので、ここでもこれを活用できないか? といった検討を進めています。既に画像認識モデルにTransformerを組み込むことで、処理時間を犠牲にすることなく精度を向上できることがわかっています(図参照)。ここで“平均誤り率”はテストセットにおいて一文あたりの平均で0.3文字程度の誤りが発生したことを表しています。また“処理時間”はテストセット(約1,000画像)の処理時間の合計です。
エッジ推論は、従来サーバーサイドで行われていた高負荷のAI処理をユーザーお手元の端末、特にスマホで可能とする技術です。エッジ推論では画像アップロードを不要とすることで通信量削減・アプリの応答性の向上などの便利さの向上が見込めます。さてエッジ推論の肝は高負荷なAI処理をいかにスマホで過剰な負荷・ユーザーのストレスのない範囲に落とし込むか、という点です。そのために独自の軽量モデルを設計開発、研究用の標準データで評価するなどの検討を行っています。この成果は既に論文化し、文書処理分野の国際会議ICDAR2021 にて発表を行いました。
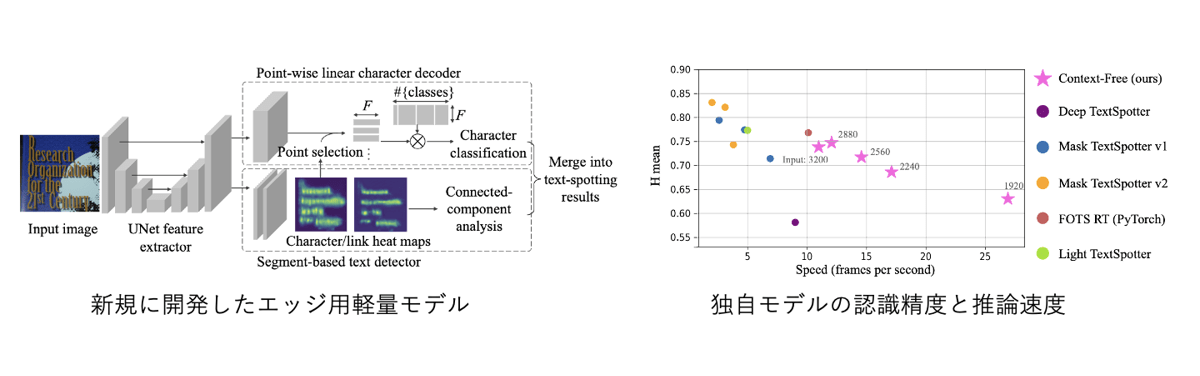
PayPayフリマ「本棚一括持ち物追加機能」での活用
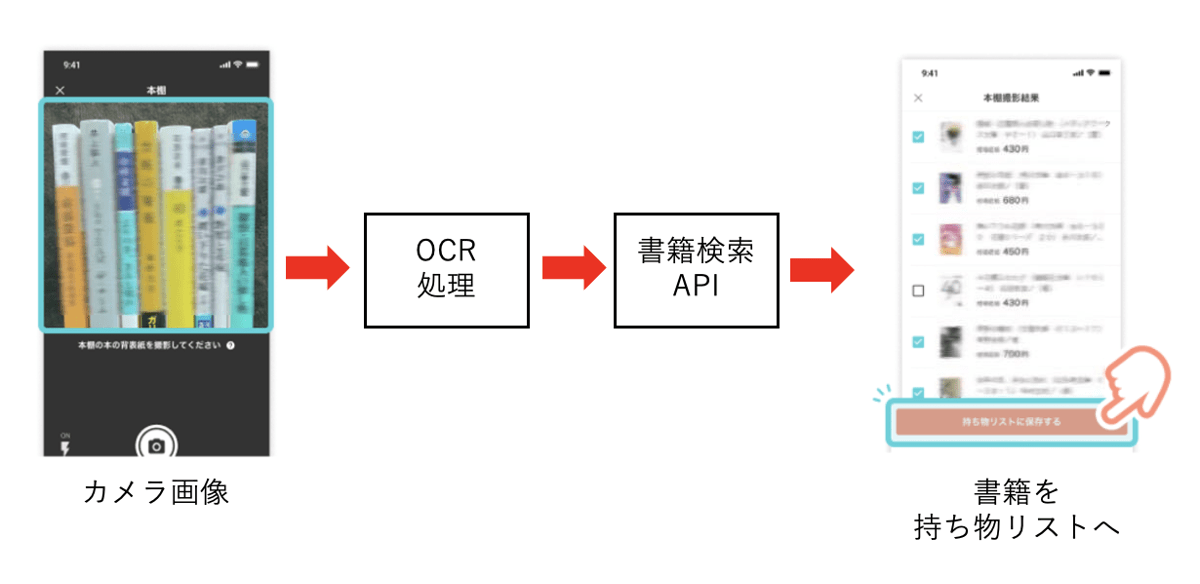
社内でさまざまに活用されているOCRですが、最近の新規活用事例としてPayPayフリマの「本棚一括持ち物追加機能」をご紹介します。
PayPayフリマはみなさんご存じのフリマアプリですが、読み終わった本をまとめて出品しようと思うと一冊ずつ登録するのがなかなか面倒くさい……という課題がありました。
そこでOCRを活用して複数の本の自動登録を可能としたのが「本棚一括持ち物追加機能」です。この機能では本棚の書籍背表紙をカメラ撮影し、OCRで読み取りを行った後は、そのテキストをもとに書籍情報のデータベースから検索を行い、当てはまった書籍を持ち物リストに登録しています。もちろんOCRには読み取り間違いが含まれることもあり、そこはユーザーに修正・追加登録をしていただくことになっています。機能のリリース後には、本の持ち物登録をしてくださるユーザー数が2倍、本の持ち物登録数・出品数が3倍程度になるという反響があり、順調に使っていただけています。
おわりに
今回はヤフーの画像処理技術の1例としてOCRをご紹介しました。OCR機能はYahoo!ブラウザーアプリの”文字読み取り”からお試しいただくこともできます。
その他にもヤフーの画像処理チームでは、社内のさまざまなサービスと連携しながら、コンピュータービジョン・画像認識領域の技術開発や応用に取り組んでいます。現在、画像処理を含めた機械学習領域のエンジニアを絶賛募集中です。ご興味がありましたらぜひご応募ください!
(記事内の画像は一部無料の写真素材「ぱくたそ」からお借りしました。)
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました
- 吉橋 亮太
- 画像処理エンジニア