こんにちは。Yahoo! JAPAN研究所で自然言語処理の研究開発をしている柴田です。
私は自然言語処理の研究と、最新の自然言語処理技術を社内のサービスに適用できるようにする開発の両方を行っています。今日は後者の話をします。
この記事ではBERTというモデルに焦点をあて、BERTの概要と、社内でのBERTの利用、最後に具体例として検索クエリのカテゴリ分類について紹介します。
※この記事で取り扱っているデータは、プライバシーポリシーの範囲内で取得したデータを個人が特定できない状態に加工しています。
1. BERTとは
2018年にGoogleからBERT (Bidirectional Encoder Representations from Transformers)というモデルが発表されました[文献1]。以下にBERTの概要を示します。まず、BERTは近年さまざまな分野で利用されているTransformerをベースにしています。Transformerは平たく言えば文中の各単語に対して文脈をよく考慮したベクトルを得るものです。図では入力の単語列が赤色の箱で示されており、Transformerにより各単語のベクトル表現が得られ、緑色の箱で示されています。BERTでは事前学習とファインチューニングの2ステップによってモデルの学習を行います。
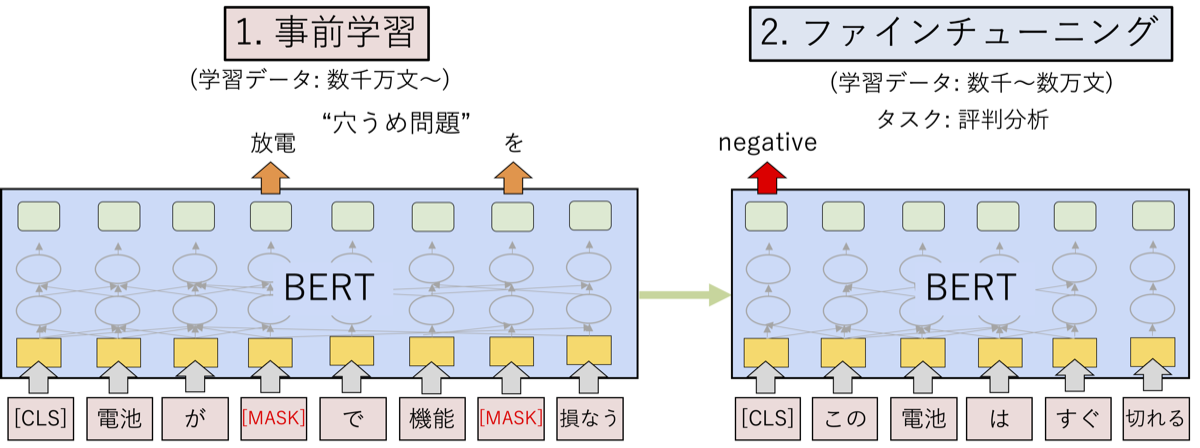
まず、事前学習ではランダムに隠した単語をまわりの単語から推測する、いわば「穴うめ問題」を解くことによってモデルの学習をします。上記の図の例ですと「放電」もしくは「を」という単語を隠して、まわりの単語から推測します。人手により学習データを作る必要がありませんので、大量のテキスト(数千万文以上)を使うことができ、ひたすら穴うめ問題を解くことによって言葉の一般的な意味を学習します。
※ BERTのオリジナル論文では次文予測というタスクも解いていますが、後の論文で有効ではないとされており、以下で述べる学習では採用していません。
次に、ファインチューニングでは実際に解きたいタスクの学習を行います。図の例ですと評判分析というタスク、つまり、文がポジティブ(positive)かネガティブ(negative)かを分類するタスクを解いています。数千から数万文程度の学習データを用意し、事前学習で学習したモデルを初期値としてタスクが解けるようにパラメータを微調整します。
大規模なテキストを用いた事前学習を行えることやTransformerが強力であることから、BERTはさまざまなタスクで高精度を達成しています。BERTを含めた深層学習による自然言語処理全般について説明したスライドを以下で公開していますので、詳細についてはこちらをご覧ください。
2. 社内でのBERTの利用
ヤフー社内では自然言語処理を用いたサービスが数多く動いています。それらのサービスでBERTなどのモデルの検討をできるだけ簡単に行えるように以下のことを進めています。
- ドメイン特化型事前学習モデルの構築と共有
- ファインチューニング・推論環境の構築
2.1 ドメイン特化型事前学習モデルの構築と共有
事前学習は普通、WikipediaやWebテキストなどの一般的なドメインのテキストを使って行われます。社内のサービスで扱うテキストは検索クエリやYahoo!ショッピングの商品説明文など、一般的なドメインとは少し性質が異なることも多く、そのような場合、そのドメインのテキストで事前学習を行った方が精度がよいことが知られています[文献2]。
そこで、検索クエリのログやYahoo!ショッピングの商品説明文などのテキストからドメインに特化した事前学習モデルを学習し、さらに学習したモデルを共有することにより、各サービスで同じようなモデルを学習してしまわないようにしています。
2.2 ファインチューニング・推論環境の構築
BERTは非常に汎用的なモデルで、例えばHugging Face社が公開しているライブラリ transformers などを使って簡単に動かせます。しかし、いざ動かすとなると日本語に対応させるなどの細かな修正が必要となり、気づかないうちに誤って動かしているケースなどがみられたりします。そこで、以下のような学習データ(これは文書分類の場合で、一行に文と正解ラベルのペアを記述します)を用意するだけでプログラムは一切書かずにファインチューニングできる環境を整備しています。
sentence label
この本はおもしろかった。 positive
この映画はつまらない。 negative
..また、推論については社内のAIプラットフォーム上の CuttySarkと呼ばれるシステムを使っています。CuttySarkはヤフーが内製したツールで、推論サーバを簡単に管理できるマネージドサービスです。コマンドひとつで簡単にモデルをデプロイでき、以下のように推論できます。
最初の行の examples で入力文を与えると、ラベル(label)と確信度(prob)が含まれたjsonが返却されています。
$ curl https://..:predict -X POST -d '{"instances": [ {"examples": "この本を買ってよかった。"}]}'
{
"predictions": [
{
"prob": 0.98820132,
"label": "positive"
}
]
}3. BERTによる検索クエリのカテゴリ分類
最後に社内での利用例としてBERTによる検索クエリのカテゴリ分類を紹介します。検索クエリをあるカテゴリ体系に分類したいというニーズは社内のさまざまなサービスでみられます。ここではその一例としてヤフー商品ブレイクマップでの利用検討を紹介します。
ヤフー商品ブレイクマップではカテゴリ別に流行アイテムを網羅的に把握できます。カテゴリの分類は現状、あるシステムを使って行っていますが、BERTによる検索クエリのカテゴリ分類結果を用いて高精度化できないか、検討を進めています。
3.1 検索クエリログで学習した事前学習モデルの利用
このカテゴリ分類では日々生まれる新語に対応しないといけないことから、上記で説明した検索クエリのログで学習した事前学習モデルを用います。新語の例として、みなさん 、「マリトッツォ」をご存じでしょうか。マリトッツォはイタリア発祥の、パンにたっぷりのクリームを挟んだスイーツで、最近話題になっています。例えば「マリトッツォ」を含む検索クエリは以下のようなものがあります。
マリトッツォ
マリトッツォとは
マリトッツォ コンビニ
マリトッツォ 食べ方
ゴディバ マリトッツォ
マリトッツォ パン
..もしマリトッツォがどんなものなのか知らない方でも「コンビニ」「食べ方」などと一緒に検索されていることからマリトッツォはスイーツかなと想像できるかと思います。このような検索クエリのログを用いて、BERTは先に説明した穴うめ問題を解くことによりマリトッツォがどのようなものであるかを事前学習します。
3.2 ファインチューニングと推論
検索クエリをグルメ、人名、企業などのカテゴリに分類するために、約50,000クエリを約60カテゴリに人手で分類し、それを学習データとして用いてファインチューニングします。検索クエリをさまざまな観点から分析できるようにするため、ここではマルチラベル分類という、一つの入力に対して複数のカテゴリが付与されうる設定にしています。例えば、「ワールドカップ予選」というクエリには「スポーツ」と「イベント」の複数のカテゴリが付与されています。
ファインチューニングしたモデルをCuttySarkでデプロイし推論させると、以下のように「マリトッツォ」は正しく「グルメ」「レシピ・料理」「製品・商品」に分類されることがわかります。
$ curl ..:predict -X POST -d '{"instances": [ {"examples": "マリトッツォ"}]}'
{
"predictions": [
{
"label": "グルメ",
"prob": 0.971430302
},
{
"label": "レシピ・料理",
"prob": 0.84826827
},
{
"label": "製品・商品",
"prob": 0.835515499
}
]
}3.3 カテゴリ分類精度と分類例
いくつかの設定でカテゴリの分類精度(マイクロF値)を算出し、システムの出力がどれくらい正解と一致しているかを評価しました。
まず、事前学習に用いるテキストをかえた場合の分類精度を以下に示します。一般的なドメインであるWikipediaと、検索クエリのログを用いた場合を比較し、検索クエリのログを用いる場合はその量を変えると精度がどのように変わるかを調べました。
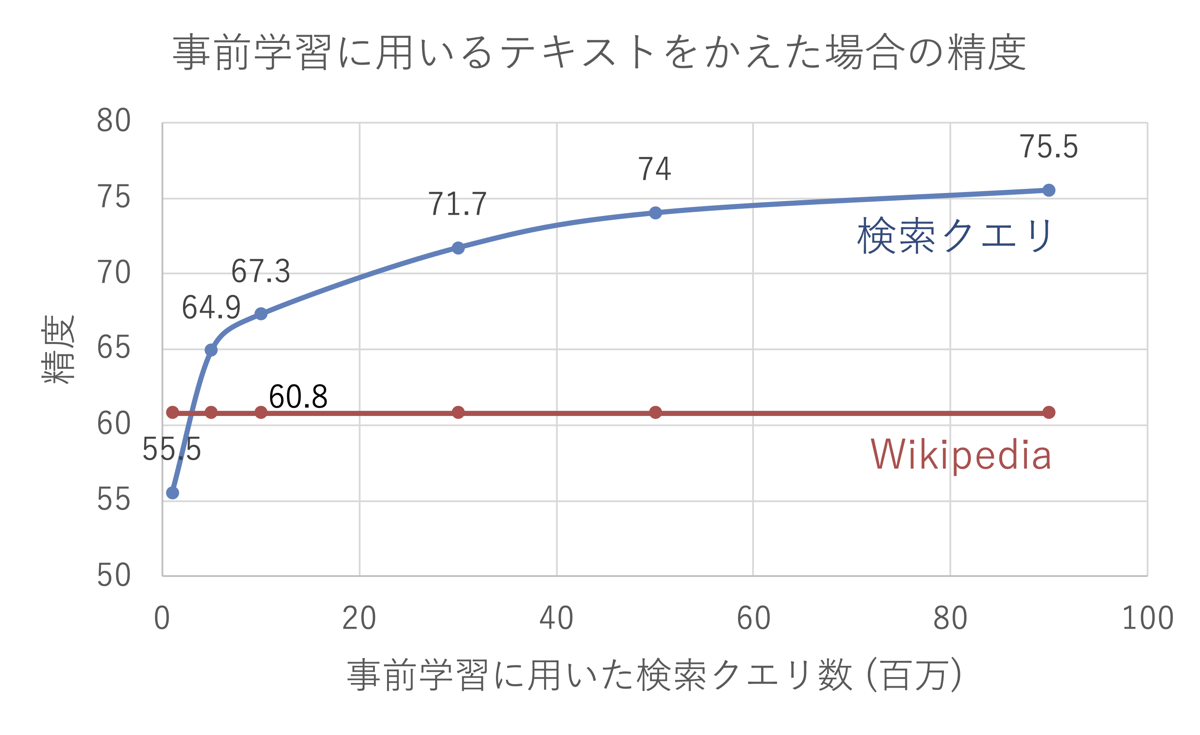
まず、Wikipediaのテキストで事前学習したモデルを利用した場合の精度は60.8でした。それに対し、検索クエリのログを9,000万クエリ利用した場合の精度は75.5まで上昇し、ドメイン特化型の事前学習モデルが有効であることがわかります。また、事前学習に用いる検索クエリの数を増やせば増やすほど精度が上がっていることがわかり、9,000万クエリから増やすとまだ上がりそうです。大量のデータを利用するのはよいことだ、と示せる非常にわかりやすい例になっています。
次にモデルサイズを変えた場合の速度と精度の関係を調べました。ここではモデルサイズとしてTransformerの層の数を変えました。一般に層の数を大きくすると精度が高くなりますが、推論速度が遅くなります。BERTのBaseモデルと呼ばれるサイズは12層からなっています。これを6層、3層と小さくした場合の速度(レイテンシ)と精度を調べると以下のようになります(速度の値は小さい方がよく、精度の値は大きい方がよいです)。
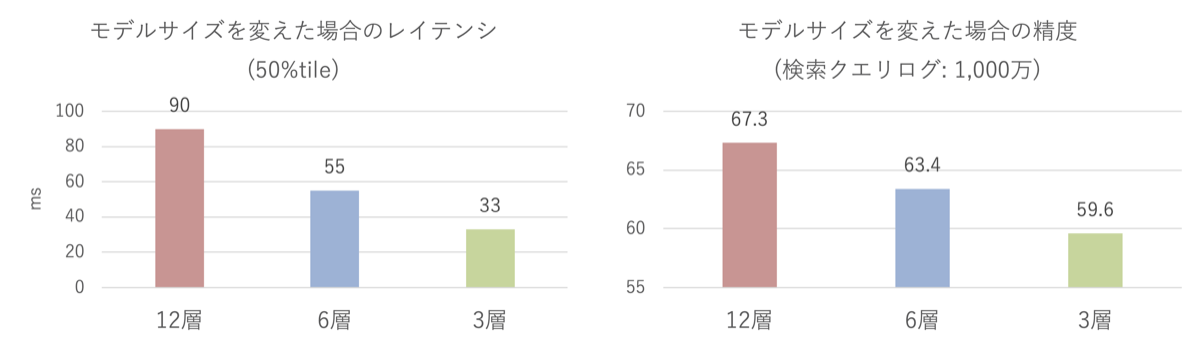
層の数を減らすとたしかにレイテンシは速くなっていますが、精度は結構下がってしまっていますので、12層のモデルを使用するのがよい、と判断できます。他のタスクでは層の数を減らしてもあまり精度が下がらない場合もあり、そのような場合は6層や3層のモデルを使用しています。このように速度と精度のトレードオフを調べながら適切なモデルサイズを決めています。
最後に分類例を示します。知らない単語であっても正しく分類されていることがあり、BERTの性能の高さに驚かされます。
| 検索クエリ | 分類されたカテゴリ集合 |
|---|---|
| オッドタクシー | タイトル名,テレビ,マンガ・アニメ |
| エイペックス スイッチ | ゲーム,タイトル名 |
| プッシュポップ | 製品 |
4. おわりに
この記事ではヤフーにおける自然言語処理モデルBERTの利用について紹介しました。検索クエリのカテゴリ分類を例として、精度、解析スピード、適切な事前学習モデルの選択などの検討について説明しました。
今後はカテゴリ分類以外のタスクへの拡張や、より手軽にモデルの学習・推論を行える環境の整備などを行い、より多くのサービスで使われるようにしていきたいと考えています。
参考文献
- [文献1] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1, pp. 4171-4186, June 2019.
- [文献2] Jinhyuk Lee, Wonjin Yoon, Sungdong Kim, Donghyeon Kim, Sunkyu Kim, Chan Ho So, and Jaewoo Kang. BioBERT: a pre-trained biomedical language representation model for biomedical text mining. Bioinformatics, Vol. 36, No. 4, pp. 1234-1240, 2020.
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました
- 柴田 知秀
- Yahoo! JAPAN研究所 研究員
- 自然言語処理に関する研究開発をしています。
-



