こんにちは。音声認識技術の研究開発を担当している篠原です。
皆さんはスマートフォンで音声による検索を使ったことがあるでしょうか? 音声認識は入力された音声をテキストに変換する技術で音声検索などさまざまなアプリで使われています。最近「End-to-End 音声認識」というニューラルネットに基づく革新的な方式が登場して驚くようなスピードで技術が発展しているところです。この記事ではヤフーにおける End-to-End 音声認識の研究成果の一例として「最小遅延学習」と呼ばれるレスポンス高速化の新技術を紹介します。
なお、本研究は米国カーネギーメロン大学の渡部晋治准教授との共同研究として実施したものです。また、この技術の詳細は先週開催された音声処理分野のトップ国際会議「INTERSPEECH 2022」で発表していますので、ご興味がある方はぜひ論文もチェックしてみてください。
はじめに
音声認識とは?
音声認識は入力された音声の内容を自動的に文字に書き起こす技術(図 1)で、私たちの日常生活のさまざまな場面で使われている便利な技術です。たとえばスマートフォンでウェブ検索をするときに、ソフトウェアキーボードで文字を入力するよりも音声で入力するほうが素早く検索を行えます。またスマートスピーカをはじめとするスマート家電の操作もタッチスクリーンやリモコンよりも音声のほうがスムーズに行えます。将来的には自動音声翻訳機や自然な対話ができる AI・ロボットなど、音声認識の応用範囲はさらに広がっていくものと期待されています。

図 1. 音声認識は入力された音声をテキストに変換する技術
End-to-End 音声認識とは?
音声認識の分野では最近「End-to-End 音声認識」と呼ばれる全く新しい方式が登場して急速に技術が発展しているところです。下の図のように、従来の音声認識は複数の統計モデル(音響モデル・言語モデル・発音モデル)を組み合わせて音声をテキストに変換する方式(図 2)でしたが、End-to-End 音声認識は単一のニューラルネットで音声をテキストに直接変換する方式(図 3)になっていて、従来とは全く異なる方式であることがわかると思います。

図 2. 従来の音声認識は複数の統計モデルを用いて音声をテキストに変換する

図 3. End-to-End 音声認識は単一のモデル(ニューラルネット)で音声をテキストに変換する
End-to-End 音声認識のメリットとして、
- 単一のモデルを End-to-End で全体最適化するので認識精度が高い
- 単一のモデルで構成されるためソフトウェアがシンプルで開発・保守が容易
- モデルのサイズが小さいためオンデバイス(たとえばスマートフォン)でも実行できる
などが挙げられていおり、世界中の企業・大学が実用化に向けて活発に研究開発を行っています。ニューラルネットは自然言語処理やコンピュータビジョンなど機械学習の諸分野に革命的な進歩をもたらしていますが、End-to-End 方式の登場によって音声認識の分野でも急速な技術発展が起こっている最中です。
なぜレスポンスの高速化が重要なのか?
End-to-End 音声認識の実用化に向けては解決すべき課題が数多くあり、とくにレスポンスの高速化(=遅延の削減)はユーザ体験に大きな影響を与えるため重要な課題です。少し具体的に説明すると、音声認識では短い単位(たとえば 100 ミリ秒)に分割されて逐次入力される音声に対して、リアルタイムで認識結果を少しずつ(たとえば 1 単語ずつ)逐次出力していきます。このとき入力から出力までの遅延をなるべく小さく抑える必要があります。たとえばスマートフォンの音声検索で「東京の明日の天気」と音声で入力しているときに、「東京」と話した瞬間から「東京」という二文字が画面に表示される瞬間までの時間(遅延)が 1 秒なのか 0.1 秒なのかではアプリの軽快感がまったく違ったものになります。End-to-End 音声認識では従来方式と比べて遅延が大きくなる傾向があるため、遅延を削減する技術がとくに重要になってきます。
新技術(最小遅延学習)はどういうアイデアか?
End-to-End 音声認識の遅延を削減する従来法として「アラインメント制約学習」と「FastEmit」という 2 つの方法がありました。アラインメント制約学習は、遅延が閾値よりも大きいアラインメントを禁止する制約を加えることで遅延が小さくなるように学習を正則化する方法です。また FastEmit は、文字出力確率に関する勾配を一定の倍率で増幅させることで認識結果を早期に出力するモデルを学習する方法です。しかし、これらの従来法ではアラインメントを制約したり勾配を増幅させたりすることで遅延を間接的に削減していますが、遅延を直接的に削減するような方法ではありませんでした。そのため遅延を効果的に削減できず、認識精度が高くてレスポンスも高速な理想的なモデルが実現できないのだと考えました。
私たちの論文(”Minimum Latency Training of Sequence Transducers for Streaming End-to-End Speech Recognition“)では、遅延を損失関数に組み込んで直接的に削減する新しい学習法として「最小遅延学習」を提案しました。具体的には、「期待遅延」と呼ばれる数量を定義して、この期待遅延をニューラルネット学習時の損失関数に加えることで認識精度と遅延を同時に最適化する方法を提案しました。私たちが行った実験では、提案した最小遅延学習によって遅延を 220 ミリ秒から 27 ミリ秒に削減できることがわかりました。この結果は従来法(アラインメント制約学習は 110 ミリ秒、FastEmit は 67 ミリ秒)よりも優れており、提案法が遅延削減の有効な手法であることを確認できました。
以下では、この最小遅延学習の方法と実験結果についてもう少し詳しく説明していきます。
最小遅延学習
このセクションでは、まず事前知識として End-to-End 音声認識のおおまかな仕組みについて説明します。次に、End-to-End 音声認識のモデル(ニューラルネット)の学習法として、従来の学習法と提案する学習法(最小遅延学習)を順番に説明していきます。
End-to-End 音声認識の仕組み
End-to-End 音声認識では一定の間隔(たとえば 60 ミリ秒)ごとに入力音声の一部を受け取って認識結果の一部(0 文字以上)を逐次出力していきます(図 4)。なお各時刻でこれ以上出力する文字がなくなったら最後にブランク(空文字)を表す特殊文字「∅」を出力します。たとえば図 4 の例では、時刻 t=1、t=2 では何も出力する文字がないので「∅」のみを出力し、次の時刻 t=3 では認識結果の最初の一文字「明」を出力した後に「∅」を出力しています。このときなるべく早い時刻に文字を出力することでサクサクとした軽快な動作感をユーザに与えられます。たとえば図 4 の例では「∅, ∅, 明, ∅, …」と t=3 で「明」が出力されていますが、これを「∅, 明, ∅, …」のように t=2 で出力できればレスポンスが 1ステップ分(60 ミリ秒)改善します。
ちなみに End-to-End 音声認識で使われているニューラルネットは「Recurrent Neural Network Transducer (RNN-T)」と呼ばれるモデルです。本ブログでは詳細には触れませんが、自然言語処理などで使われているエンコーダ・デコーダ型の系列変換用のニューラルネット(Transformer など)と似たようなモデルだと思ってください。
なお上記のようなブランク文字「∅」を含んだ認識結果のことを「アラインメント(alignment)」と呼び記号 a で表すことにします。また End-to-End 音声認識のモデルは入力音声 X に対してアラインメント a を生成する確率 P(a|X) も計算できます。
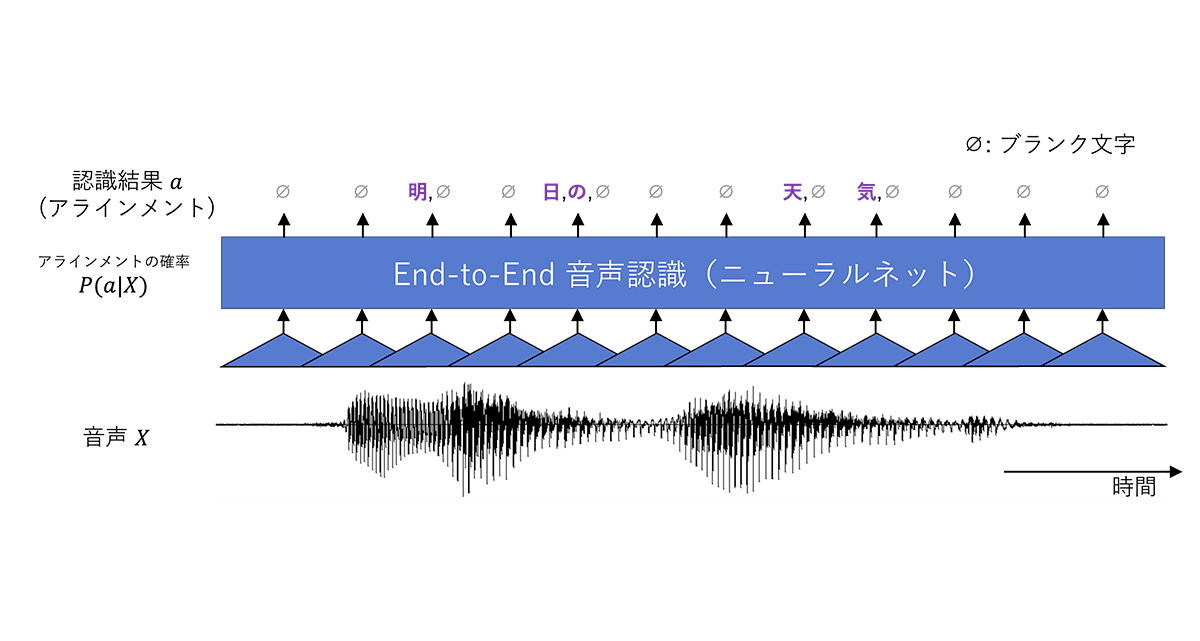
図 4. End-to-End 音声認識は入力された音声を文字列に逐次変換する
従来の学習法
End-to-End 音声認識の従来の学習法(Graves 2012)では正解文字列を生成する尤度を最大化するようにモデルのパラメータ(ニューラルネットの結合荷重)を最適化します。これ自体は機械学習ではごく一般的な枠組みなのですが、End-to-End 音声認識では上で述べたようにブランク文字「∅」を考慮しながら尤度を計算しないといけないので少し工夫が必要です。
具体的には、図 5 に示すように、同じ正解文字列 Y(たとえば Y = “明日の天気”)を生成する場合でも、ブランク文字「∅」の位置が異なる無数のアラインメントが考えられます。そこでこれらのアラインメントの確率 P(a|X) の総和をとることで正解文字列 Y を生成する尤度 P(Y|X) を求めます。このように定義した尤度に対して負の対数をとったもの(負の対数尤度)を損失関数として用います。これにより正解文字列が出る確率が高い、つまり認識精度の高いモデルを得られます。
しかし、この損失関数では遅延について一切考慮していないため、認識精度は高いけれども遅延が大きいモデルが学習されてしまう点が課題です。この問題には系列データに対する予測を行うニューラルネットでは予測を行う位置の前後のなるべく広いコンテキストを観測したほうが予測精度が高まるという性質が関係しています。End-to-End 音声認識でもある単語(例えば「明日」)が実際に話された時刻よりも(過去だけでなく)未来まで観測してから予測を行ったほうが認識精度が高くなるため、認識精度のみを最適化するとどうしても遅延が大きくなってしまうのです。

図 5. End-to-End 音声認識の従来の学習法。尤度を最適化することで認識精度の高いモデルを学習する。
提案する学習法(最小遅延学習)
私たちは認識精度とレスポンスを両立したモデルを実現するため「最小遅延学習」という新しい学習法を提案しました。具体的には、損失関数に「期待遅延」と呼ばれる数量を追加することによって尤度(認識精度)と遅延(レスポンス)を同時に最適化する方法を考案しました。以下で詳しく説明していきます。
まず「参照アラインメント」と呼ばれる各文字の理想的な出力時刻(実際にその文字が話された時刻)を表すアラインメントを定義します。これは例えば「強制アラインメント」と呼ばれる方法で音声 X と正解文字列 Y の対応付けをとることで求められます。次に各アラインメントの各ステップにおいて、参照アラインメントと比べて出力が何文字遅れているかを表す「遅延」を求めます。たとえば図 6 の例では、参照アラインメントは 7 番目のステップ(n=7)までに 3 文字出力していますが、1 番目のアラインメント(a1)では 1 文字しか出力していないため n=7 での遅延を「2」とします。
次に各ステップ n において、各アラインメントの遅延をアラインメントの確率で重み付けながら和をとることで「期待遅延」を算出します。たとえば図 6 の例で、P(a1|X) = 0.05, P(a2|X) = 0.02, P(a3|X) = 0.03 で、簡単のため a1,a2,a3 以外のアラインメントは無視できるほど確率が小さかったと仮定すると、n=7 における期待遅延は 0.5 * 2 + 0.2 * 0 + 0.3 * 1 = 1.3 となります(アラインメントの確率は総和 P(Y|X) = 0.05 + 0.02 + 0.03 = 0.1 で正規化されていることに注意してください)。
最小遅延学習では、このように定義した期待遅延を損失関数に加えることで尤度と遅延を同時に最適化します。これにより認識精度とレスポンスを両立したモデルを学習することが可能になります。
なお、このアイデアを愚直に実装しようとすると無数のアラインメントを処理しなければならず膨大な計算コストがかかります。また確率的勾配降下法などの勾配ベースの学習法に組み込むためには期待遅延の勾配を求める必要があります。私たちの論文では期待遅延の勾配をフォワードバックワードアルゴリズム(動的計画法の一種)を拡張した方法で効率的に計算できることを示しています。詳細にご興味がある方はぜひ論文もチェックしてみてください。

図 6. End-to-End 音声認識の最小遅延学習(提案法)。尤度と遅延を同時に最適化することで認識精度とレスポンスを両立したモデルを学習する。
実験結果
提案する最小遅延学習法によって本当に認識精度とレスポンスを両立したモデルを学習できるのかを検証するため実験を行いました。
実験条件は以下のとおりです。
- 学習データ:Wall Street Journal という英語音声コーパスを用いてモデルの学習と評価を行いました。
- モデル:Conformer Transducer と呼ばれるニューラルネットを用いました。これは Recurrent Neural Network Transducer のエンコーダ部の構造を LSTM (Long Short-Term Memory) から Conformer(convolution と Transformer を融合した構造)に変更したものです。
- その他:入力特徴量はフィルタバンク特徴量(80次元)、出力トークンはブランク文字「∅」を含む 52 文字を用いました。なお今回の実験では言語モデルは用いませんでした。
- 評価指標:2 つの指標で評価しました。
- 単語正解精度(%):認識精度の評価指標。認識結果の単語のうち何パーセントが正解だったかを表す。大きいほど良い。
- PR90 遅延(ミリ秒):遅延の評価指標。Partial Recognition Latency at 90th-percentile の略。音声を話し終わった瞬間から認識結果の最後の文字が出力される瞬間までの時間差。小さいほど良い。
実験では以下の4つの学習法を比較しました。1 つ目は遅延削減を使わない通常の学習法。2 つ目、3 つ目は従来の遅延削減法。そして 4 つ目が提案する遅延削減法です。各遅延削減法について遅延削減の強さを制御するハイパーパラメータ(提案法の場合は正則化項の重みλ)を振って複数のモデルを学習して評価しました。
- 通常の学習法(負の対数尤度を損失関数とする)
- アラインメント制約学習
- FastEmit
- 最小遅延学習(提案法)
図 7 に実験結果を示します。横軸が遅延、縦軸が単語正解精度なのでグラフの左上にいくほどレスポンスと認識精度を両立した良いモデルになります。まず通常の学習法の結果(黒い四角)を見てみると、200 ミリ秒を超える大きな遅延が発生していることがわかります。次に提案する最小遅延学習の結果(赤線)を見てみると、単語正解精度を大きく低下させることなく 50 ミリ秒程度まで遅延を削減できていることがわかります。一方、従来法(アラインメント制約学習と FastEmit)では同じくらいまで遅延を削減すると提案法と比べて単語正解精度が大きく低下することがわかります。
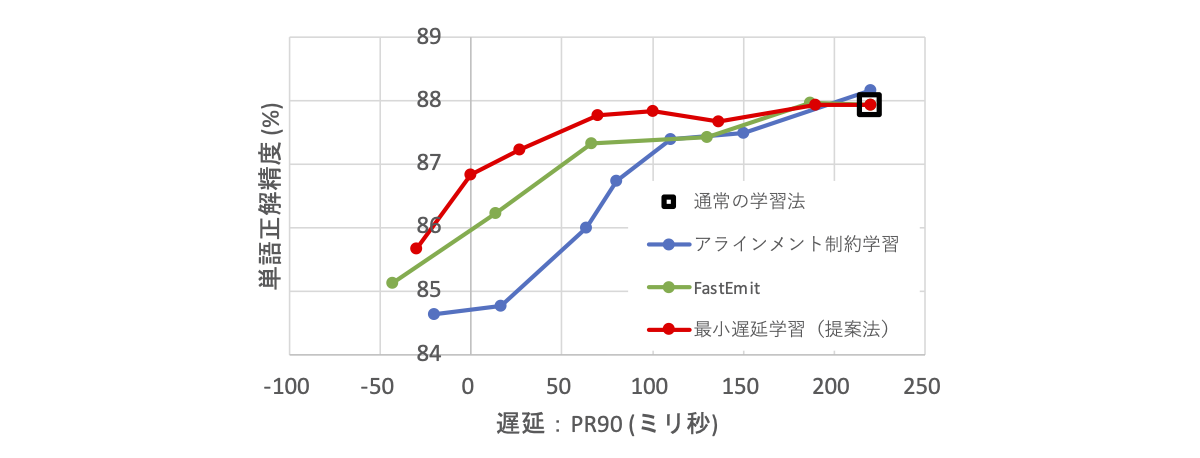
図 7. 各学習法で学習したモデルの遅延と単語正解精度の評価結果
また表 1 に同程度の単語正解精度(87.3% 前後)における遅延を比較した結果を示します。提案する最小遅延学習では遅延を 220 ミリ秒から 27 ミリ秒まで削減しており、従来法(アラインメント制約学習の 110 ミリ秒、FastEmit の 67 ミリ秒)よりも遅延を小さく抑えられていることがわかります。
表 1. 同程度の単語正解精度(87.3% 前後)で遅延を比較した結果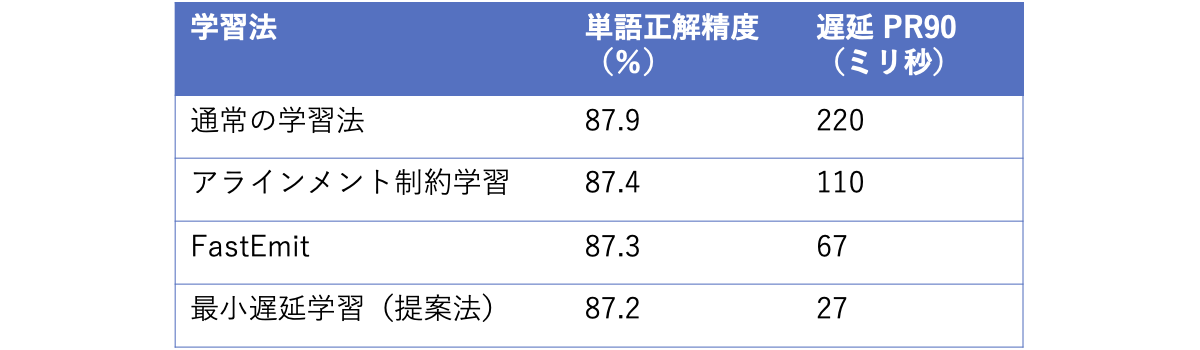
以上の結果から、提案する最小遅延学習は認識精度とレスポンスを両立するモデルを学習する有効な方法であることがわかります。
おわりに
この記事では End-to-End 音声認識のレスポンスを高速化する新技術である「最小遅延学習」について紹介しました。従来の学習法では認識精度のみを最適化していたのに対して、最小遅延学習では認識精度と遅延の両方を考慮して最適化を行うため、認識精度とレスポンスを両立した理想的なモデルが学習できることを示しました。
この記事で紹介した技術の他にもヤフーの音声認識チームでは数多くの研究成果を学会発表しています。今後も新しい技術を創出・発信して音声認識技術の発展に貢献するとともに、これらの技術をコアにした新しいアプリやサービスを世に送り出していきたいと思います。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました
- 篠原 雄介
- 音声認識エンジニア



