こんにちは。データ統括本部でYahoo!広告のデータエンジニアをしている江島です。
本記事では、Yahoo!広告のデータ分析環境であるデータレイク上のデータを、Apache Hudi を用いてレコード単位で削除可能にした事例を紹介します。
Yahoo!広告のデータ分析環境
Yahoo!広告における データマーケティングソリューション では、ヤフーの持つ圧倒的な量と質のデータを活用し、消費者理解や広告効果分析を目的としたさまざまな商品を提供しています。
これらの商品を提供するための裏側には広告に関する膨大なログや多種多様なサービスのログを使ってデータ分析や機械学習を行うためのデータ基盤が必要です。データマーケティングソリューションではデータ基盤として AWS 上に データレイク を構築しています。私たちはこのデータレイクを AD Data Lake on AWS と呼んでおり、オンプレミスの Apache Hadoop 環境から AWS へと Apache NiFi を利用してデータ ETL 処理を行い、 AD Data Lake on AWS へとデータを転送しています。
AD Data Lake on AWS の構築には AWS Lake Formation、 AWS Glue、 Amazon S3 などを使用しており、 S3 のストレージ容量は 2022年4月時点で 2.7ペタバイト(2,700テラバイト) に及びます。
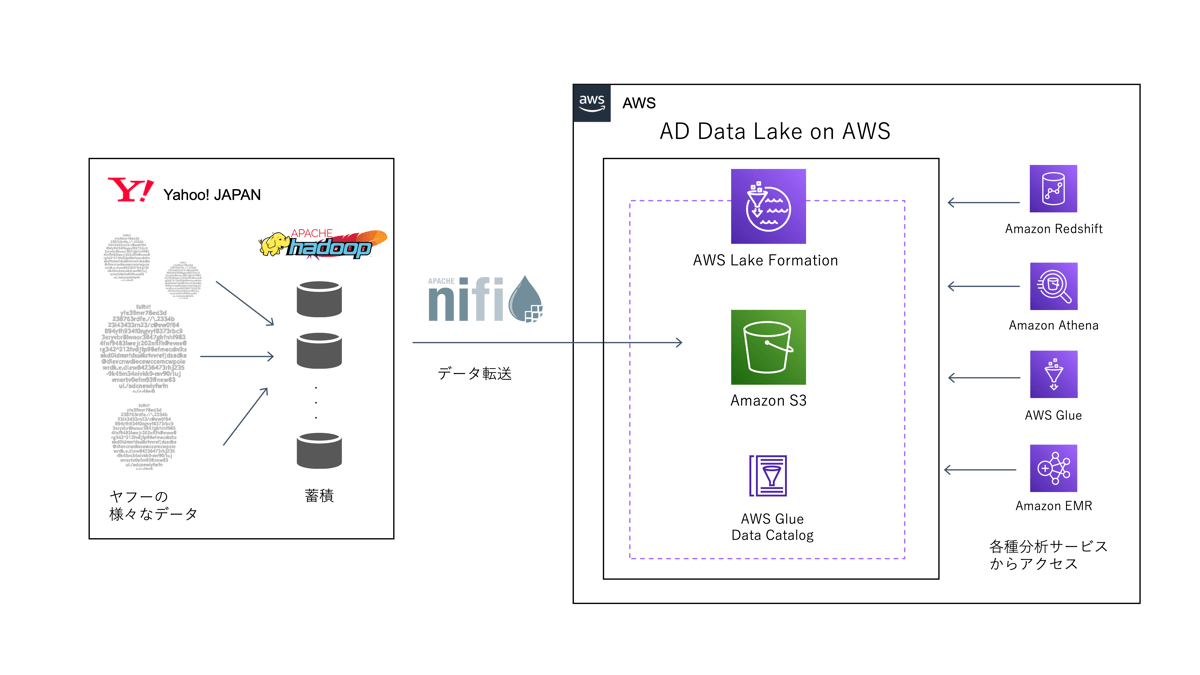 図1: AD Data Lake on AWSへのデータ転送からアクセスまでのデータフロー
図1: AD Data Lake on AWSへのデータ転送からアクセスまでのデータフロー
データレイクの特徴
一般的に、データレイクでは S3 や HDFS などの安価なストレージを用いて、あらゆる構造化データや非構造化データをファイルとして大量に蓄積することが可能です。
一方で、特定のデータを削除したり更新したりすることは、膨大な数のファイルの中から該当の部分が存在するファイルを探し当て、そのファイルの該当部分を削除したり書き換えたりする必要があるため、非常に計算コストがかかります。
AD Data Lake on AWS のデータの実態も、日付などのパーティション項目ごとに区切られた S3 上のディレクトリにアップロードされた Apache ORC 形式のファイルであり、この中から特定のレコードを探して削除や更新を行うことはできません。
例えば、あるパーティションの一部のレコードを削除したい場合、一度 S3 の該当パーティションのディレクトリにアップロード済みのファイルをすべて削除し、データの転送元から削除したいレコードを除外して再度データを転送する、などの工夫をする必要があります。
つまり、データレイクでは簡単にレコード単位での削除を行えないのです。
「データの削除」が求められるデータレイク
しかし現在、日本における 令和2年改正個人情報保護法(2022年4月施行) や、欧州における GDPR などを始めとして、インターネットサービスを利用するユーザの個人情報やプライバシーの保護がより重視される世界的な流れが広まってきています。
特に、令和2年改正個人情報保護法において、ユーザは自身の個人情報やサービスの閲覧ログなどの「パーソナルデータ」を、サービス提供者に対して削除・利用停止の請求をできる要件が緩和されました。これにより、ユーザはより簡単に自身のパーソナルデータに対する削除・利用停止の請求を行えるようになり、従来よりも多くの削除・利用停止の請求が来ることが予想されました。
データマーケティングソリューションでは、ユーザ理解のためにユーザごとの広告のクリックログなどを分析対象にしており、必要に応じて AWS 上にデータの蓄積を行っていますが、これらのデータもパーソナルデータに該当するため、請求があれば削除の対象となります。
ヤフーでは、ユーザのプライバシー保護とそのための情報セキュリティ対策を最も重要な使命だと考えており、法改正によるパーソナルデータの削除請求の増加にも対応すべく、 より簡単にデータを削除できるデータレイク の開発を行う必要がありました。
既存システムにおける問題点
既存の AD Data Lake on AWS のデータ転送システムでは、特定のレコードのみを削除するためには、先述した通りパーティション単位でのデータの再転送が必要になりますが、再転送にはいくつかの問題点がありました。まず、再転送時には一度アップロード済みのデータを削除する必要があるので、再転送が完了するまでの間はデータが参照できないダウンタイムが発生してしまいます。また、データ転送元にそもそも該当期間のデータが既に存在しない場合は、再転送自体が不可能になってしまいます。
さらに、データの整合性という観点においても、データの削除を行う場合にはトランザクション機能や排他制御が行えることが望ましいですが、現状の AD Data Lake on AWS ではこれらの機能は実装されておりませんでした。
上記のような問題を解決するためには、データレイクのデータを RDB のように「レコード単位で」「安全に」データを削除することが出来るような仕組みが必要になります。
Apache Hudi の導入
これらの問題を解決するために、私たちは Apache Hudi を AD Data Lake on AWS へと導入することにしました。
Apache Hudi は、レコード単位でのデータの削除や更新、トランザクション機能、排他制御など、従来のデータレイクでは実現が難しかった機能を提供するオープンソースのデータ管理フレームワークです。
Apache Hudi と似たような機能を持っていて AWS で使用可能なものとしては Databricks の Delta Lake、 Apache Iceberg、AWS Lake Formation の機能である Governed Tables などがありますが、下記のような理由から Apache Hudi を採用しました。
- レコード単位の削除が可能である。
- Apache Hive、Presto、Apache Spark といったさまざまなクエリエンジンに対応している。
- Amazon Athena、Amazon EMR、AWS Glue で AWS が公式にサポートしている。
- Amazon Athena においてワークグループが固定されるという制約がない。
(すべて導入検討時点での情報になり、現在は Apache Hudi 以外も上記に全て対応している可能性があります。)
Apache Hudi の概要
データレイクに Apache Hudi を導入するということは、Apache Hudi に対応した形式のデータフォーマットで作成されたテーブルを作成することであると考えると理解しやすいです。
Hudi テーブルのデータ形式は、データの実体である Apache Parquet 形式のファイルと、 Hudi テーブルのパーティションや後述するタイムラインに関する情報などのメタデータから構成されます。
AD Data Lake on AWS の実際の Hudi テーブルのファイル構成の一部を下記に記載します。
# yyyymmdd=20220401 パーティションのデータの実体となる Parquet ファイル
$ aws s3 ls s3://bucket/warehouse/ad_yda/click_log_hudi/yyyymmdd=20220401/
2022-04-02 05:41:12 93 .hoodie_partition_metadata # パーティションメタ情報のファイル
2022-04-02 05:41:56 124120730 20b7c2c3-b5f7-4a8a-80df-73e776a980f7-0_4-5-116_20220401203957.parquet # Parquet ファイル(データの実体)
2022-04-02 05:42:45 124448077 39ccdd84-768d-45b6-95d8-ecc08423e54e-0_1-5-113_20220401203957.parquet
# Hudi テーブルのメタ情報が配置されたディレクトリ内のファイル
$ aws s3 ls s3://bucket/warehouse/ad_yda/click_log_hudi/.hoodie/
2022-04-19 05:53:36 8749 20220418205107.replacecommit # コミット情報のファイル
2022-04-19 05:52:33 1218 20220418205107.replacecommit.inflight
2022-04-19 05:51:40 0 20220418205107.replacecommit.requested
2022-03-02 18:41:36 273 hoodie.properties # Hudi テーブルのメタ情報ファイルHudi テーブルでは、Parquet ファイルの各レコードが primary key で一意に定まる必要があります。primary key は、レコードごとにユニークなキー(recordkey)とパーティションのパスを表すキー(partitionpath)の組み合わせで Hudi 内部の Key Generator によって生成されます。この primary key を利用することで、Hudi テーブルでは高速なレコードレベルでの削除や更新処理を実現しています。
Hudi テーブルへデータの書き込み処理はコミットと呼ばれ、ファイルごとにバージョン管理をしています。Hudi テーブルではコミットが行われると、不要になった古いバージョンのファイルの削除(Cleaning)や、データの圧縮(Compaction)などさまざまなアクションがバックグラウンドで実行されます。コミットでは Atomic 性が保証されており、書き込みに失敗した場合はロールバックされます。これらのアクション情報は Hudi のタイムラインとして記録されます。
Hudi テーブルでは、下記のようにユースケースに応じてコミット時の挙動(バージョン管理の方針)が異なる 2種類のテーブルタイプを選択できます。
- Copy On Write(CoW): コミットのたびに新しいバージョンの Parquet ファイルを 新たな別ファイルとして生成する 。読み込み処理の多いテーブルに対して効果的。
- Merge On Read(MoR): コミット時の 差分を Apache Avro 形式のファイルとして保存しておき、後でマージする 。書き込み処理の多いテーブルに対して効果的。
私たちの AD Data Lake on AWS のユースケースでは、データの更新は daily や hourly の頻度であり書き込み頻度よりも読み込み頻度の方が高いことや、扱うファイルが Parquet ファイルのみでシンプルであることから CoW のテーブル形式を選択しました。
既存テーブルの Hudi 化
AWS 上では、 AWS Glue Data Catalog を Hudi テーブルの Hive メタストアとして使用することで、Amazon Athena などから従来のテーブルと同様に参照することが可能です。Hudi テーブルの作成は、AWS Glue ETL の Spark ジョブを用いて行えます。
ここで、AD Data Lake on AWS の既存のテーブルはデータ形式が ORC だったため、既存のデータをそのまま Hudi テーブルへと流用できませんでした。そこで、同様のスキーマを持つ Hudi テーブルを作成するため、Spark ジョブ上で既存テーブルを読み込んだ DataFrame を作成してその DataFrame で write 処理を行うことで Hudi テーブル化(正確には、Hudi 形式の別テーブルの作成)を実現しました。
以下は、PySpark での実装のコード例です。
import sys
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from pyspark.sql.session import SparkSession
from awsglue.context import GlueContext
from awsglue.job import Job
# Glue PySpark で Hudi のデータ形式を扱うための設定
spark = SparkSession.builder.config('spark.serializer','org.apache.spark.serializer.KryoSerializer').getOrCreate()
sc = spark.sparkContext
glueContext = GlueContext(sc)
job = Job(glueContext)
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
job.init(args['JOB_NAME'], args)
# 既存テーブルの情報
source_database_name = 'ad_yda'
source_table_name = 'click_log'
yyyymmdd = '20220401' # パーティション
# Hudi テーブルの情報
hudi_database_name = 'ad_yda'
hudi_table_name = 'click_log_hudi'
base_path = f's3://bucket/warehouse/{hudi_database_name}/{hudi_table_name}/'
# DataFrame 作成
query = f'select uuid() as uuid, concat(\"yyyymmdd=\", cast(yyyymmdd as string)) as partitionpath, * from {source_database_name}.{source_table_name} where yyyymmdd = {yyyymmdd}'
df = spark.sql(query)
# Hudiのオプション
hudi_options = {
'hoodie.table.name': hudi_table_name,
# 書き込みオプション
'hoodie.datasource.write.table.name': hudi_table_name, # テーブル名
'hoodie.datasource.write.storage.type': 'COPY_ON_WRITE',
'hoodie.datasource.write.recordkey.field': 'uuid', # レコードキーのカラム名
'hoodie.datasource.write.partitionpath.field': 'partitionpath', # パーティション対象のカラム名
'hoodie.datasource.write.precombine.field': 'uuid', # レコードの重複制御用カラム名
'hoodie.datasource.write.operation': 'bulk_insert', # 書き込み操作種別
# データカタログ連携オプション(hive_sync)
'hoodie.datasource.hive_sync.enable': 'true', # Hive メタストアとの連携を有効にする
'hoodie.datasource.hive_sync.database': hudi_database_name,
'hoodie.datasource.hive_sync.table': hudi_table_name,
'hoodie.datasource.hive_sync.partition_fields': 'yyyymmdd',
'hoodie.datasource.hive_sync.partition_extractor_class': 'org.apache.hudi.hive.MultiPartKeysValueExtractor',
'hoodie.datasource.hive_sync.use_jdbc': 'false'
}
# Hudi テーブルへの書き込み
df.write.format('hudi').options(**hudi_options).mode('append').save(base_path)
job.commit()Hudi テーブル内のレコードを一意に特定する recordkey や partitionpath は既存テーブルには存在しなかったので、select クエリの中で作成しています。既存テーブルに既にレコードを一意にする primary key が存在する場合や、パーティション項目の値をそのままパーティションの path として設定してよい場合は、既存のカラム名をそのまま指定して使用できます。
Hudi テーブルは、このようなメタ情報カラムをデータとして保持する必要があるため、既存の ORC ファイルに比べてファイルの容量が大きくなってしまう可能性があることに注意が必要です。また、これらのメタ情報カラムは Amazon Athena などからテーブルを select したときにも参照可能になります。もし、テーブルの利用者にはそれらのカラムを見せたくない場合は該当カラムを落とした view を提供してそちらを参照してもらうようにすると良いでしょう。
なお、AWS Glue ETL の PySpark ジョブで Hudi 形式のテーブルを扱うためには、以下の JAR を S3 にアップロードしその path を Dependent JARs path に指定する必要があります(JAR ファイルのバージョンは、執筆時点で動作確認が取れているものです)。
- hudi-spark3-bundle_2.12-0.8.0.jar
- spark-avro_2.12-3.1.1.jar
- libfb303-0.9.3.jar
- calcite-core-1.16.0.jar
レコード単位でのデータの削除の流れ
Hudi テーブルにおけるデータの削除は、下記の 2処理によって実現されます。
- コミットによる新たなファイルバージョンの作成
- クリーナーによるファイルの削除
先述した通り、Hudi におけるデータの更新とは新たなバージョンの新たな別ファイルを生成することです。つまり、100レコードのデータからある1レコードを削除した場合は、既存のファイルを残しつつ、99レコードの新たなファイルが出来上がります。
削除処理後に SQL でテーブルを select したときには 99レコードに見えますが、ストレージ上では 100レコードある古いバージョンのファイルも残った状態のままです。このとき、どれくらいまで古いバージョンのファイルを残すか? という設定ができ、クリーナーは設定より古いバージョンのファイルをコミット後に自動で削除してくれます。
クリーナーの削除ポリシーには、下記の2種類が存在します。
- KEEP_LATEST_COMMITS: 各ファイルごとの最新の N+1 コミットのうち、全コミットのうち最も古いコミット以降のバージョンを残す。
- KEEP_LATEST_FILE_VERSIONS: ファイルごとに最後の N バージョンを残す。
N > 1 を設定した状態で削除処理を行うと、テーブルからはデータが消えているように見えますが、ストレージ上にはまだ過去のファイルが残っているため、タイムトラベルクエリを使用することで過去の時点のデータを参照することも可能です。
今回のユースケースでは、削除処理を行ったデータはその時点ですぐにテーブルからもストレージからも消えてほしいため、 シンプルなファイル管理ができる KEEP_LATEST_FILE_VERSIONS ポリシーを使用し、 N = 1 と設定します。
このときのクリーナーの動きについては、以下の Hudi 公式ブログの概念図が非常に分かりやすいため、引用します。
(出典:Employing correct configurations for Hudi’s cleaner table service)
図2: クリーナー処理が行われる前の状態。色がコミットとそれによって生成されたファイルのバージョンを表す。
(出典:Employing correct configurations for Hudi’s cleaner table service)
図3: KEEP_LATEST_FILE_VERSIONS, N = 1 の設定でクリーナー処理が行われたあとの状態。それぞれのファイルで最も新しいバージョンのファイル以外を削除する。
実際の削除処理は、テーブルの作成時と同様 PySpark ジョブを使用して、削除したいレコードの recordkey と partitionpath を持った DataFrame を作成し、Hudi の Operation で delete を指定してテーブルに write 処理を行うことで実現できます。
以下に、削除処理を行う PySpark の実装例を示します。
import sys
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from pyspark.sql.session import SparkSession
from awsglue.context import GlueContext
from awsglue.job import Job
# Glue PySpark で Hudi のデータ形式を扱うための設定
spark = SparkSession.builder.config('spark.serializer','org.apache.spark.serializer.KryoSerializer').getOrCreate()
sc = spark.sparkContext
glueContext = GlueContext(sc)
job = Job(glueContext)
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
job.init(args['JOB_NAME'], args)
# Hudi テーブルの情報
hudi_database_name = 'ad_yda'
hudi_table_name = 'click_log_hudi'
base_path = f's3://bucket/warehouse/{hudi_database_name}/{hudi_table_name}/'
yyyymmdd = '20220401'
# col_1 = "xxx" という項目を持つレコードを削除するための DataFrame を作成
query = f'select uuid, partitionpath from {hudi_database_name}.{hudi_table_name} where yyyymmdd = {yyyymmdd} and col_1 = "xxx"'
df = spark.sql(query)
# Hudiのオプション
hudi_options = {
'hoodie.table.name': hudi_table_name,
# 書き込みオプション
'hoodie.datasource.write.table.name': hudi_table_name, # テーブル名
'hoodie.datasource.write.recordkey.field': 'uuid', # レコードキーのカラム名
'hoodie.datasource.write.partitionpath.field': 'partitionpath', # パーティション対象のカラム名
'hoodie.datasource.write.precombine.field': 'uuid', # レコードの重複制御用カラム名
'hoodie.datasource.write.operation': 'delete', # 書き込み操作種別
# hudi cleaner オプション
'hoodie.cleaner.policy': 'KEEP_LATEST_FILE_VERSIONS', # N個のファイルバージョンを保持する
'hoodie.cleaner.fileversions.retained': 1, # N=1 にする、つまり最新バージョンのみ保持する
# データカタログ連携オプション(hive_sync)
'hoodie.datasource.hive_sync.enable': 'true', # Hive メタストアとの連携を有効にする
'hoodie.datasource.hive_sync.database': hudi_database_name,
'hoodie.datasource.hive_sync.table': hudi_table_name,
'hoodie.datasource.hive_sync.partition_fields': 'yyyymmdd',
'hoodie.datasource.hive_sync.partition_extractor_class': 'org.apache.hudi.hive.MultiPartKeysValueExtractor',
'hoodie.datasource.hive_sync.use_jdbc': 'false'
}
# Hudi テーブルへの書き込み
df.write.format('hudi').options(**hudi_options).mode('append').save(base_path)
job.commit()実際に、削除処理を行ったときに S3 のファイルがどのような挙動になるのかを確認してみます。
まず、ある 100 件のレコードを持った Hudi テーブルの削除処理前のパーティションの状態は下記のようになっていました。
$ aws s3 ls s3://bucket/warehouse/ad_yda/click_log_hudi/yyyymmdd=20220401/
2022-04-02 17:07:56 93 .hoodie_partition_metadata
2022-04-02 17:07:57 600089 1bc30043-e136-4411-a64f-765b90568a2e-0_0-37-4282_20220402080609.parquetこの後、5件のデータの削除を、 KEEP_LATEST_FILE_VERSIONS, N = 10 で行うと、下記のような構成になりました。
$ aws s3 ls s3://bucket/warehouse/ad_yda/click_log_hudi/yyyymmdd=20220401/
2022-04-02 17:07:56 93 .hoodie_partition_metadata
2022-04-02 17:07:57 600089 1bc30043-e136-4411-a64f-765b90568a2e-0_0-37-4282_20220402080609.parquet
2022-04-02 17:17:53 594984 1bc30043-e136-4411-a64f-765b90568a2e-0_0-39-7173_20220402081701.parquetもとのファイルはそのまま残り、容量が少し小さなファイルが新たに出来上がっていることが分かります。Amazon Athena などからデータを select すると、テーブルの件数は 95 件を返しますが、 KEEP_LATEST_FILE_VERSIONS, N = 10 としたため、古いバージョンのファイルも残ってしまっています。
そこで、KEEP_LATEST_FILE_VERSIONS, N = 1 として再び削除処理を実行するとどうなるでしょうか。
$ aws s3 ls s3://bucket/warehouse/ad_yda/click_log_hudi/yyyymmdd=20220201/
2022-04-02 17:07:56 93 .hoodie_partition_metadata
2022-04-02 17:29:47 583290 1bc30043-e136-4411-a64f-765b90568a2e-0_0-51-7297_20220402082916.parquet上記のように、最新のバージョンのファイルだけが残っています! この状態で Amazon Athena などから select すると、テーブルの件数は 90 件になります。つまり、テーブルからもストレージからもデータが削除されたということになります。
このように、コミットとクリーナーを組み合わせることレコード単位でのテーブルデータの削除を実現できます。
まとめ
本記事では、Yahoo!広告において、 Apache Hudi を利用してレコード単位でデータの削除が可能なデータレイクを構築した事例を紹介しました。
一般的なデータレイクでは、データの削除を行うことは簡単ではありませんが、データレイクのテーブルを Hudi テーブルへと変更することで、簡単かつ安全なデータの削除を実現しました。
データ利活用においては、多種多様なデータを「ためる」ことがまず大前提として求められますが、世間では改正個人情報保護法を始めとしてプライバシーに対する意識がますます高まって来ており、データを「削除」することが求められる機会も今後増えてくることが予想されます。
そんなときは、Apache Hudi のような削除・更新が可能なデータフォーマットであるかどうかも、データレイクの構築において重要な要素となってきていると言えるのではないでしょうか。
Apache Hudi, Apache Hadoop, Apache NiFi, Apache ORC, Apache Iceberg, Apache Hive, Apache Spark, Apache Parquet, Apache Avro は、The Apache Software Foundation の米国およびその他の国における登録商標または商標です。
Amazon Web Servicesおよびその他のAWS商標は、Amazon.com, Inc.またはその関連会社の米国およびその他の国における登録商標または商標です。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました
- 江島 昇太
- データエンジニア / データサイエンティスト
- Yahoo!広告のデータエンジニアをしていました。現在はデータサイエンティストとして、ユーザのプライバシー保護を前提としたインターネット広告の実現を目指して研究・開発しています。



