ゼットラボ(※1)の坂下とヤフーの飯田です。コンテナオーケストレーション Kubernetesの国内イベントとして開催されたKubeFest Tokyo 2020(2020/6/13)で発表した「ヤフー/ゼットラボのステートフルアプリケーションへの挑戦」について紹介します。
※1ゼットラボはヤフーの子会社
はじめに
これまで、コンテナはステート(データ)を持つアプリケーション(ステートフルアプリケーション)が苦手と言われてきました。しかし、Kubernetesなどコンテナ関連技術の進歩により、ステートフルアプリケーションも扱えるようになってきました。そこで、ヤフーとゼットラボにて取り組んでいるKubernetes as a Service向けステートフルサービスへの取り組みと、導入事例について紹介します。
Kubernetes as a Serviceとは
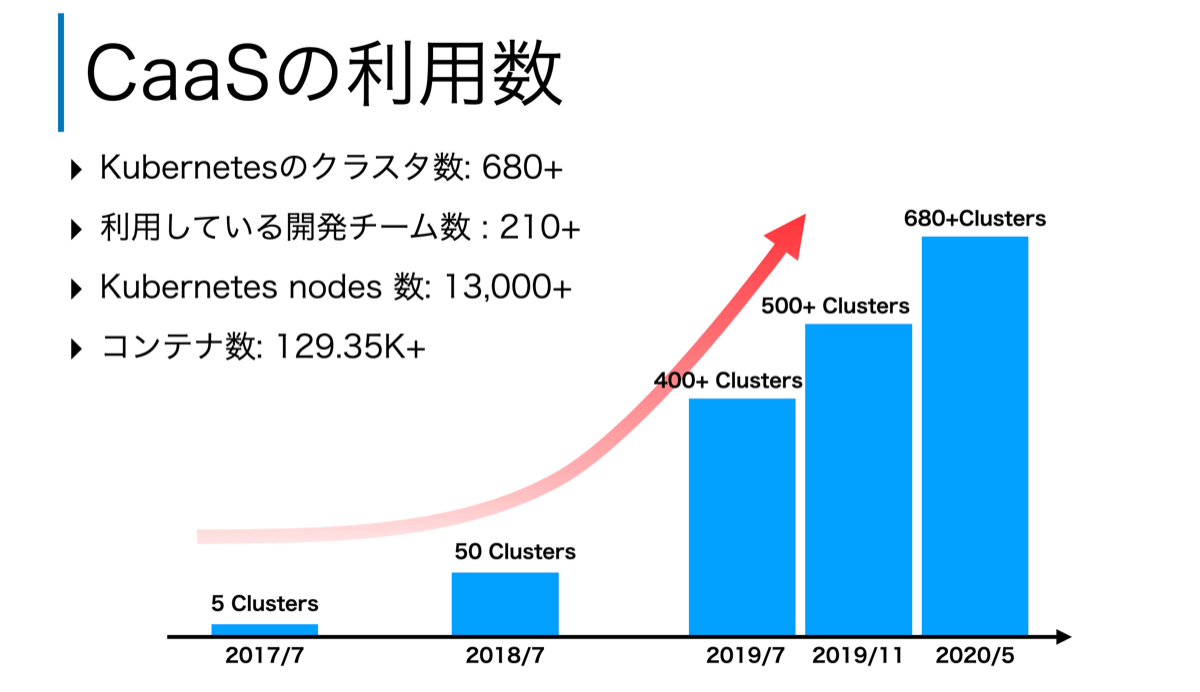
これまで、Yahoo! JAPAN Tech Blogでも何度か紹介していますが、ヤフーではゼットラボが開発したKubernetes as a Service(本記事ではCaaSと略します)を運用し、多くのサービスで利用しています。CaaSの利用数はサービス開始から年々増加し、2020年5月時点でCaaSにて払い出されたKubernetesクラスタの数は680以上、コンテナ数は129.35K個以上と日々成長し続けています。
このCaaSのアーキテクチャを簡単に紹介します。以下の図に示すように、Kubernetes(図の左下)のCustome Controllerとして開発したコントローラの指示で、OpenStackのVMを作成した後、VM上にユーザーが利用するKubernetes(図の右上)をセットアップします。この時、Kubernetesから利用するLoadBalancerなどのネットワークリソースも合わせてセットアップします。
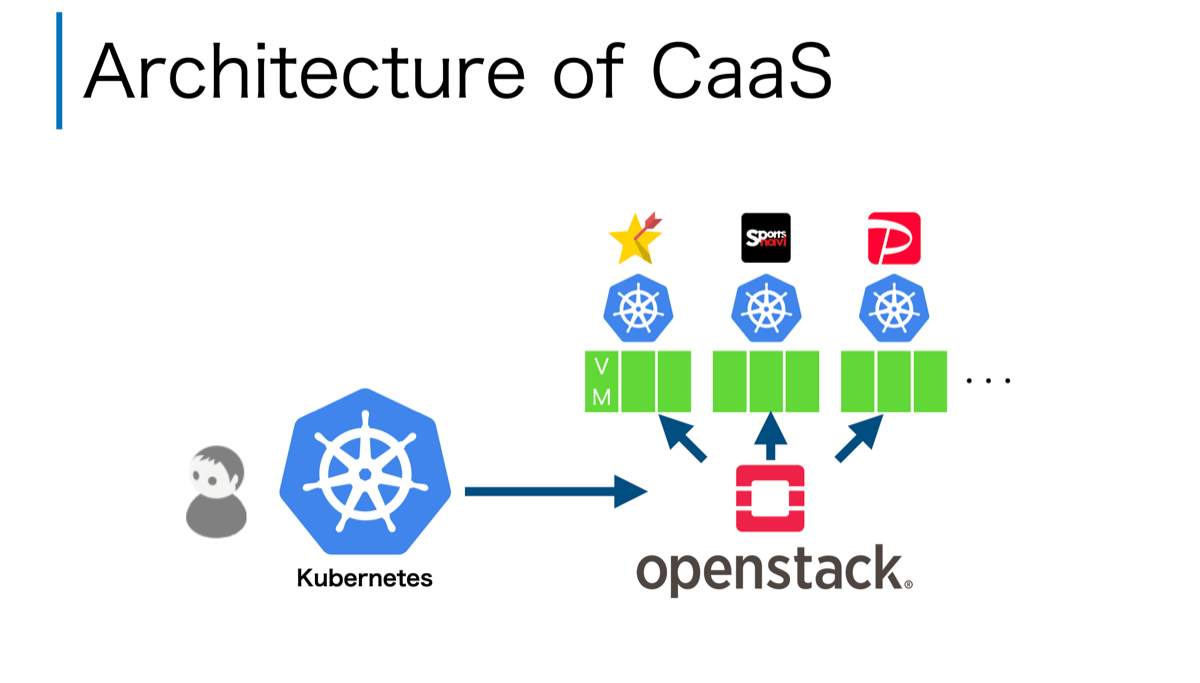
このように、Kubernetes(図の左下)を使ってKubernetes(図の右上)を管理するアーキテクチャとなっています。このアーキテクチャのメリットとしては、Kubernetes自身の特徴機能であるセルフヒーリング/ローリングアップデートなどのメリットを活用し、Kubernetes(図の右上)を管理できる点です。たとえば、ユーザーが利用するKubernetes(図の右上)のノードであるVMに障害が発生しても、Kubernetes(図の左下)が検知し、セルフヒーリングにより自動で回復させることが可能です。さらには、ノードをローリングアップデートさせることで、アプリケーションを停止させずKubernetesのバージョンをアップデートすることも出来ます。このようなアーキテクチャを取ることで、Kubernetesの運用管理の手間を省力化しています。
さらに、管理面だけでなくユーザーの利便性を高めるため、アプリケーションを自動配布する独自のAddon-managerもゼットラボにて開発し提供しています。この独自のAddon-managerにより、監視やアラーティングなどで多くのユーザーが利用するGrafanaやPrometheusといったアプリケーションおよびダッシュボードやアラートルールなどを自動配布しています。これにより、ユーザーはCaaSにより払い出されたKubernetesを利用開始直後から、Grafanaのダッシュボードで監視ができ、障害通知などのアラートを受け取ることができます。もちろん、Kubernetesや配布されているアプリケーションがバージョンアップした場合でも、Addon-managerにより自動でアップデートされます。

CaaS向けステートフルサービスへの挑戦
このような特徴をもつCaaSですが、2019年時点ではデータを持たないステートレスなアプリケーション(ステートレスアプリケーション)にて利用されてきました。しかし、ユーザーからはデータを持つステートフルアプリケーションもKubernetes上で動作させたいとの要望が高まってきました。そこで、ゼットラボでは、ステートフルアプリケーションを安心・安全に実行できるようにCaaS向けにステートフルサービスの研究開発に取り組みました。
このCaaS向けにステートフルサービスを提供するにあたり次の課題がありました。
- 課題1: Kubernetesを利用する各サービスで独立排他なデータアクセスの担保
- 課題2: ステートフル用リソースの保守コストの最小化
- 課題3: ノードのセルフヒーリング・ローリングアップデートとステートフルの両立
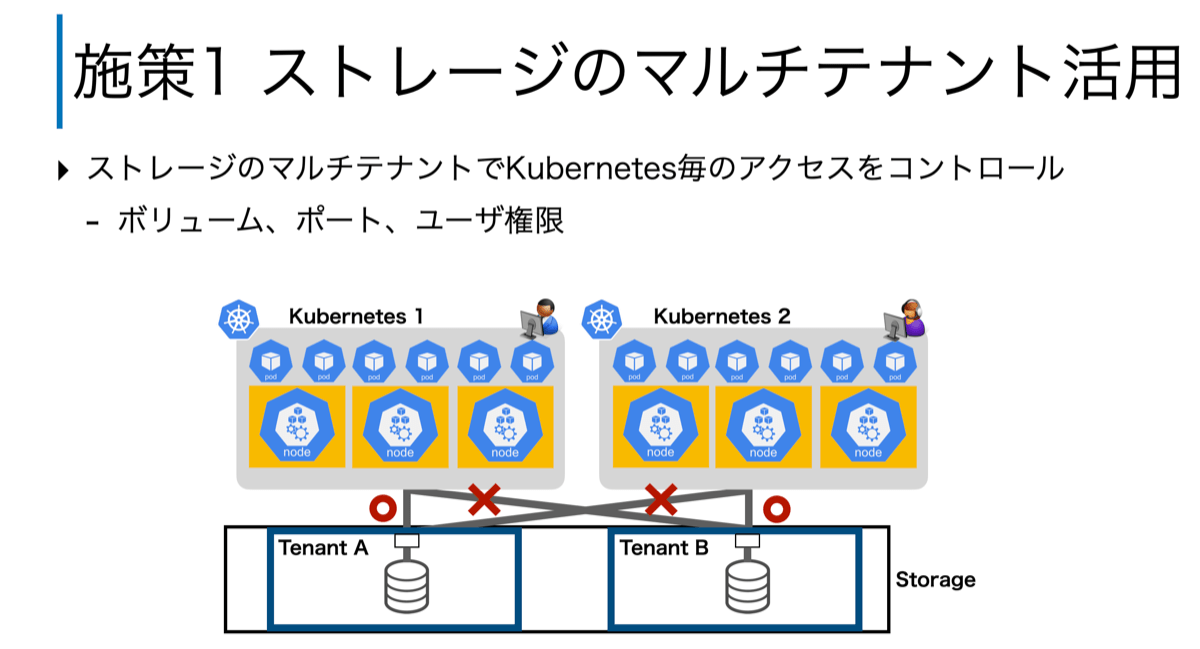
これらの3つの課題に対し、それぞれ施策を行っています。まず、「課題1: Kubernetesを利用する各サービスで独立排他なデータアクセスの担保」については、ストレージのマルチテナント機能を利用し解決しました。Kubernetesでは、単一のKubernetes上のリソースについてはアクセス制御を設定することも可能です。ただし、CaaSのように複数Kubernetesが共有リソース(今回だとストレージ)を使う場合、Kubernetesが備えているアクセス制御では適切に制御できません。そこで、CaaSではストレージのマルチテナントで切り出されたテナントを各Kubernetesに割り当てることで、あるサービスが別のサービスのデータにアクセスができないようにしています。
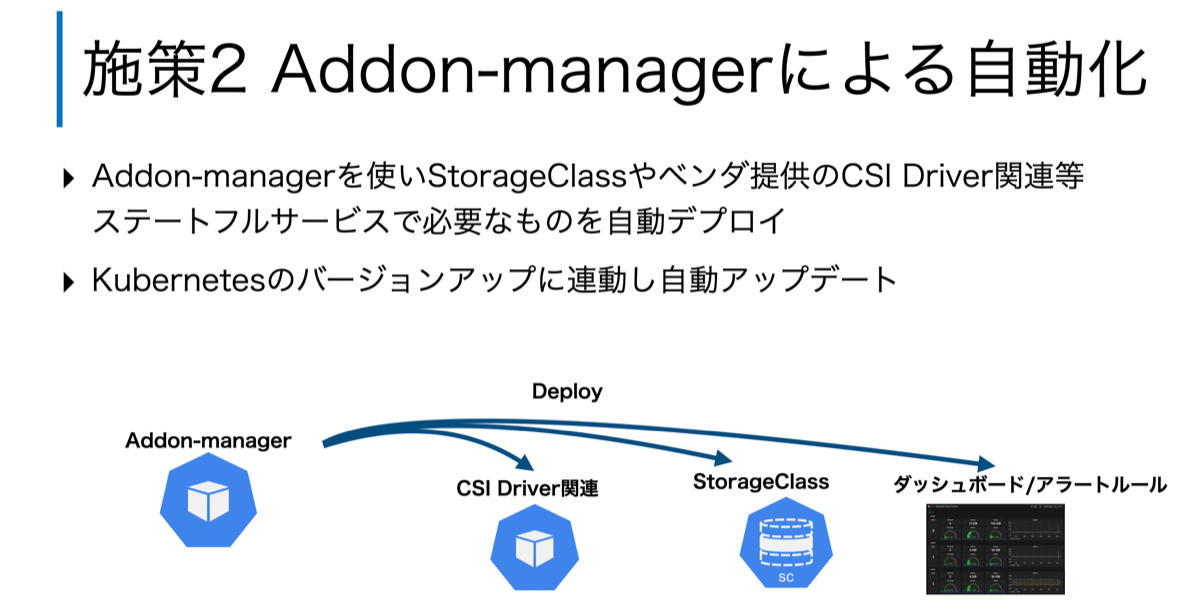
次に、「課題2: ステートフル用リソースの保守コストの最小化」について、CaaSの管理者の省力化を目指しAddon-managerを使ったセットアップ/バージョンアップの自動化に取り組みました。CaaSでは、増加し続けるKubernetesの数に対して、これを保守する管理者の数は、少なくあまり増加していません。さらに、Kubernetesは3ヶ月と早いペースでバージョンアップされます。そのため、少ない管理者にて、ミスなく頻繁にKubernetesと関連するソフトウェアをアップデートし続けるためには、如何に管理者の手動オペレーションなしにセットアップ/バージョンアップできるかが重要となってきます。
最後に、「課題3: ノードのセルフヒーリング・ローリングアップデートとステートフルの両立」について、ACL更新の自動化により解決しました。上述したように、CaaSではローリングアップデートやセルフヒーリング時にノードを再作成します。このため、新しく作成されたノードの情報(IPアドレスやIQN)をストレージのACLに登録する必要があります。もし、ACLへ登録し忘れると、アプリケーションからストレージにアクセスできずサービス停止につながる恐れがあります。また、過度に広いネットワークレンジなどを事前に登録することも可能ですが、これはセキュリティリスクを抱えることになり好ましくありません。
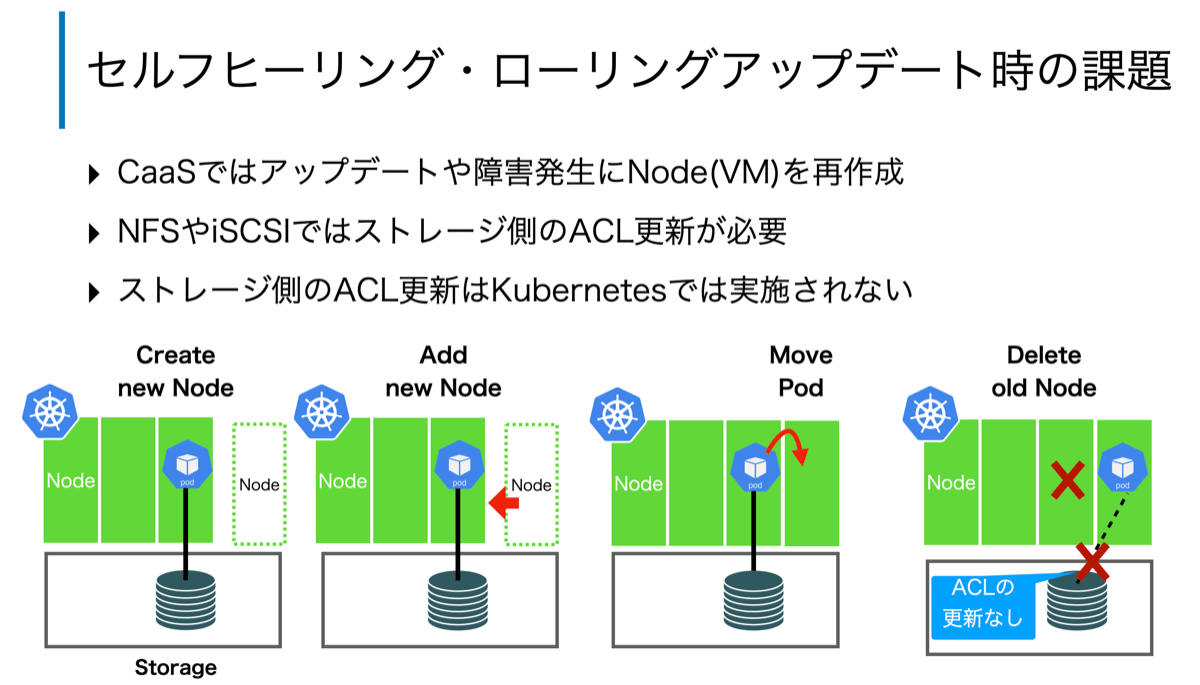
そこでゼットラボでは、ノードをWatchし増減があれば、ストレージのACLを自動更新するCustom Controller(export-policy-manager)を開発しました。これにより、CaaSのローリングアップデートやセルフヒーリングにてノードが再作成された場合でも、管理者の手動のオペレーションなしに、ACLを過不足なく更新します。
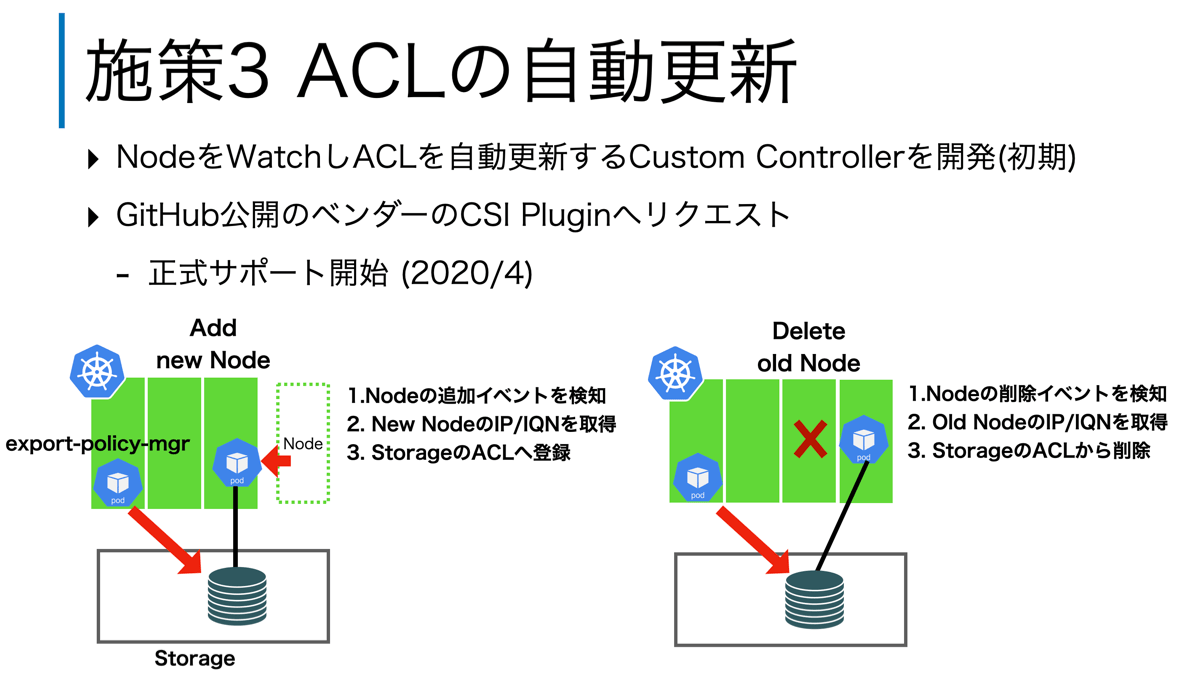
この3つの施策により、CaaS向けのステートフルサービスを実現しています。次に、このCaaS向けステートフルサービスを使ったサービスの導入事例を紹介します。
ディスプレイ広告(YDA)へのCaaS導入事例の紹介
ここからは前半パートで紹介したステートフルサービスに対応したCaaSをYDAのサービスに導入した事例について紹介します。
YDAとはヤフーの広告配信サービスです。テキスト・バナー・動画などさまざまな形式の広告を、Yahoo! JAPANのコンテンツページをはじめ、提携サイトのコンテンツページに配信できます。
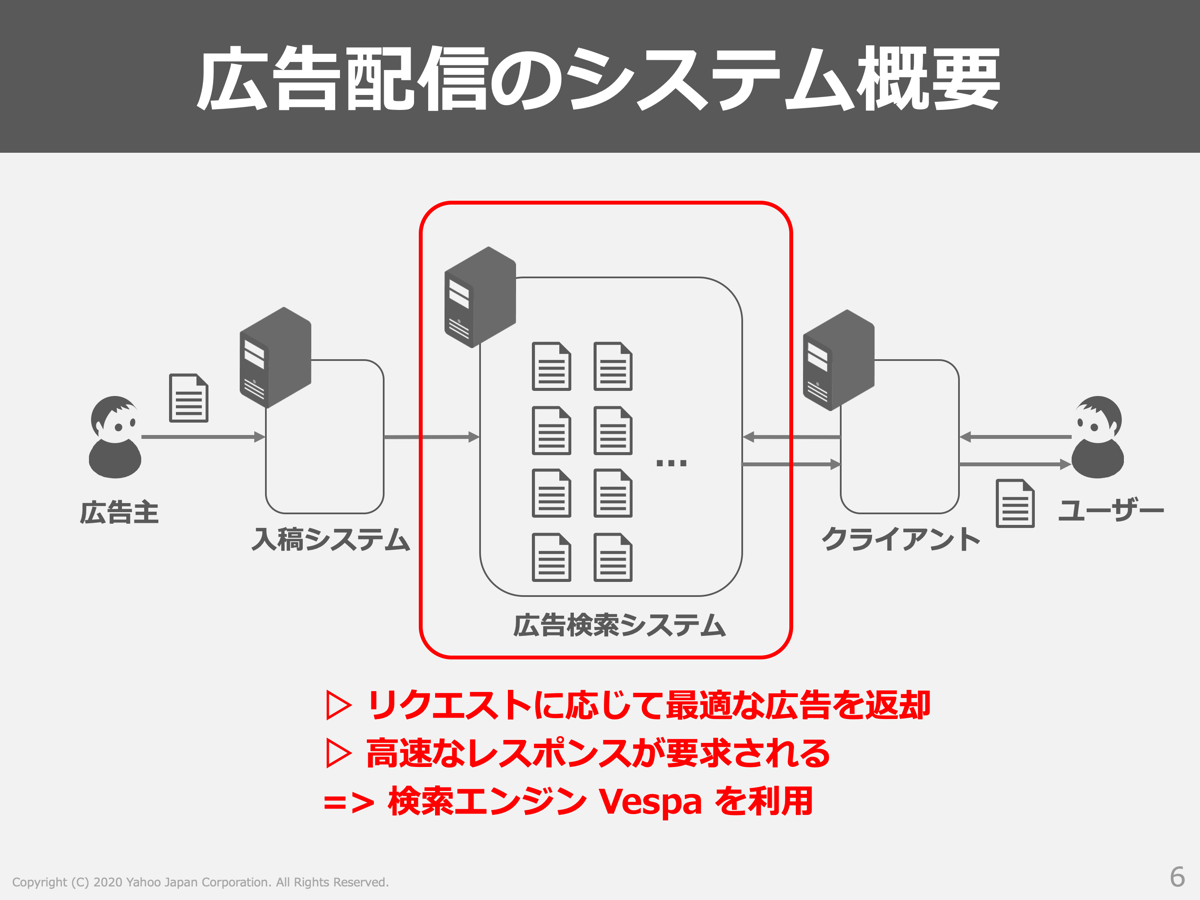
私たちが運用している広告配信システムの概要は以下の図で示すように広告主が広告を入稿する入稿側と、ユーザーからのリクエストに対して最適な広告を引き当てる配信側の2つの側面で成り立っています。そしてその中間的なポジションで広告検索システムが存在し、入稿された広告を保持しておき、ユーザーからのリクエストに対する広告の返却を実現する構成になっています。
広告配信では以下のような厳しい要件が求められる点も特徴の一つかと思います。
- 広告検索してクライアントに返却するまでのレイテンシに厳しい制約がある
- 検索レイテンシの制約を満たしつつ、高スループットを実現する必要がある
- 大量の広告データを保持・更新・削除しないといけない
- 削除漏れなどの誤配信は重大・深刻事故につながるため更新ロストは許されない
そして私たちは広告検索システムにVespaという検索エンジンを利用して、これらの厳しい要件を実現しています。
CaaS導入の背景
検索エンジン(Vespa)をCaaS上で稼働させる以前は、実機+VMを利用しており、こういったインフラならではの以下の課題点がありました。
- 緊急時に備えて余分なサーバーを用意しておくなど、マシンリソースを効率的に使えていない
- サーバー故障時(主に実機の故障時)の運用が面倒
- リリースに時間がかかる
CaaSであればこのような課題点を解決できると考え、VespaをCaaS上で稼働させることに挑戦しました。
検索エンジン Vespaとは
Vespaについては、過去にYahoo! JAPAN Tech Blogで紹介していますので、そちらを参照ください。
ここではステート(データ)を持つアプリケーションという点に着目してVespaのデータ管理について簡単に紹介します。
Vespaはドキュメント(データ)の集合をbucketという単位に分割して、複数のVespa Server(公式ドキュメントではContent Nodeと表記されています)に分散する仕組みになっています。以下の図では冗長性を2レプリカに設定した場合であり、このレプリカ間のデータ同期もVespaが自動で行います。各bucketを担当するVespa ServerはVespa内部で動的に決定され、Vespaクラスタを構成するVespa Serverに応じて柔軟にデータを管理することが可能です。CaaSはノードをスケールされることが得意とするため、このような点ではVespaと相性が良いと考えることができます。
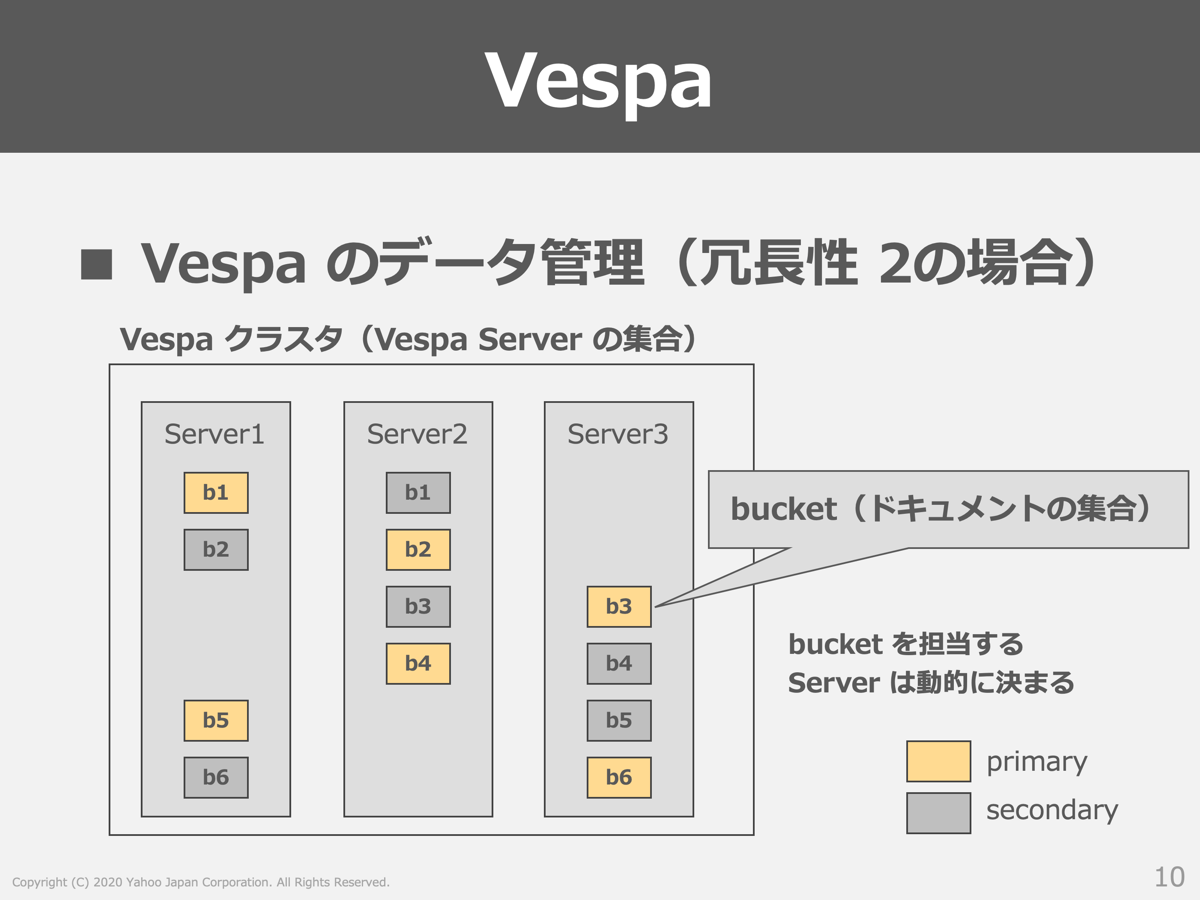
CaaSではノードの再作成が行われますが、ノードが削除される度にbucket(データ)が消えてしまうとなると運用面で大きな問題が発生します。そこでゼットラボ提供のステートフル機能を活用し、自動的なノードの再作成においても問題が発生しないシステム設計を実現しました。
CaaS導入後のシステム構成
CaaS上でVespaを稼働させるシステムの概要を以下の図に示します。
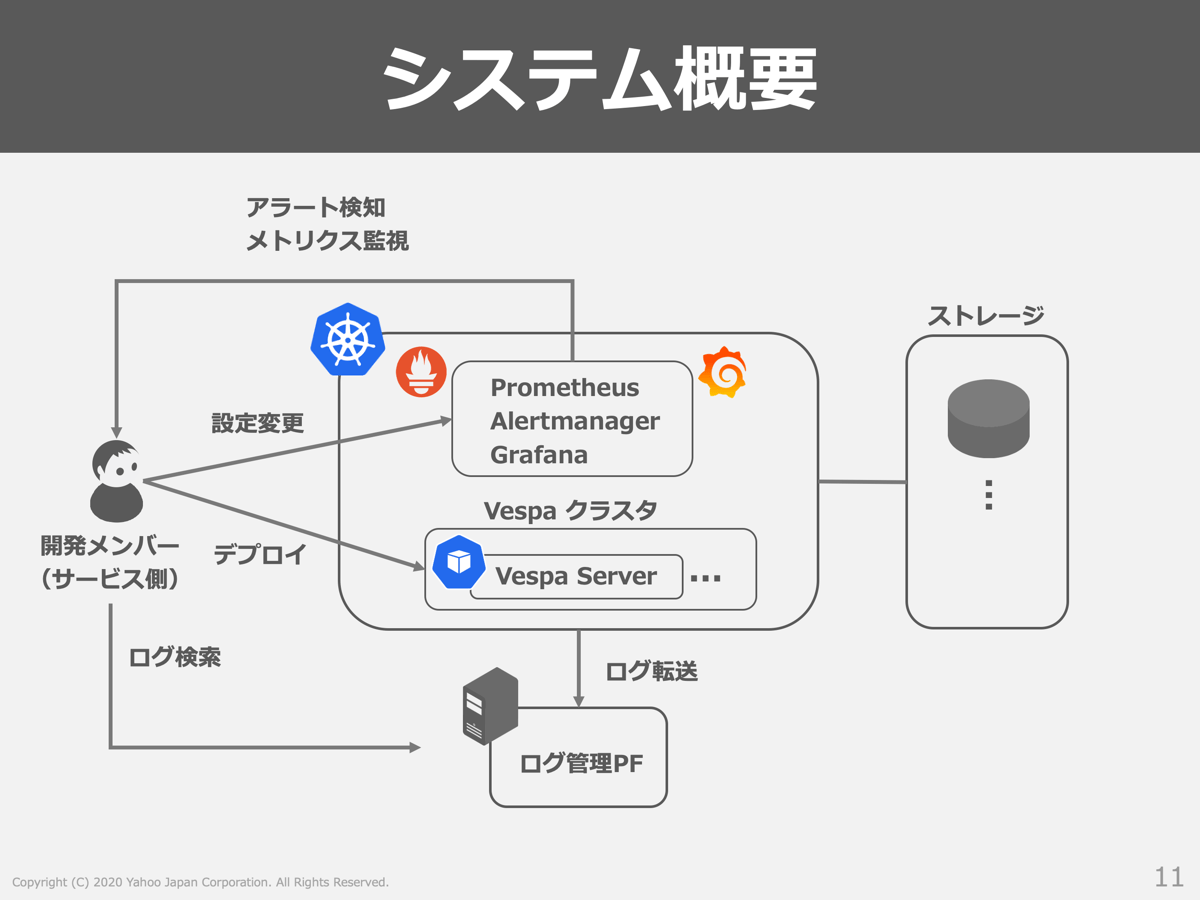
まず、開発者がVespaクラスタをKubernetesにデプロイし、Vespa Serverを外部ストレージと連携させます。外部ストレージを利用することでローリングアップデート時にデータが消失しない仕組みを取っています。
アラート検知やメトリクス監視にはAddon-managerにより提供されるPrometheus/Alertmanager/Grafanaを利用しています。ここでのポイントとして、Kubernetesを利用する上で基本となるメトリクスや監視ルールもAddon-managerにより既に組み込まれているため、サービス側の開発者はアプリケーションに特化したメトリクスや監視ルールを組み込むだけになっています。
また、ログ管理PFとの連携も行っており、問題が発生した際の調査などはログ管理PFを通じて実施しやすい環境が整っています。
Vespaクラスタの部分に着目したシステム構成を以下の図に示します。
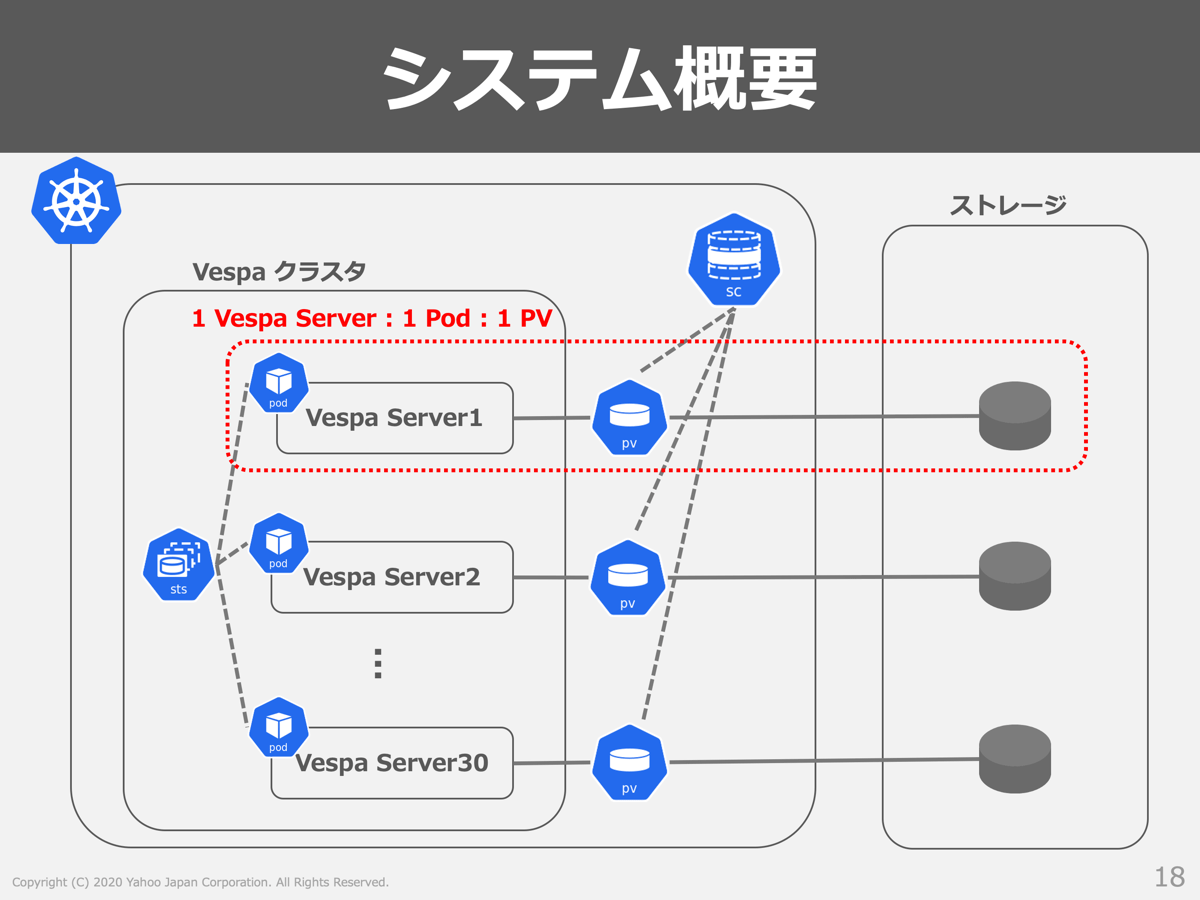
Vespaクラスタを構成するVespa Serverごとに、Persistent Volume(PV)と紐付けることでデータ(bucket)を外部ストレージに格納する仕組みとなっています。Vespaクラスタを構成するVespa Serverの数は30台となっていますが、ドキュメント件数や求められるスループットによって最適な値は変化するため、使用状況を定期的に確認して適切な数へのチューニングを実施するようにしています。
CaaS導入で苦労した点
VespaをCaaS上で稼働させるにあたり直面した課題も多く、例えば以下の課題に直面しました。
- ノード側とストレージ側のボリューム上のデータ削除が同時に行われない
- ストレージ性能の問題
- データをロストしないための設計が必要
- デバッグが困難
ここでは「ノード側とストレージ側のボリューム上のデータ削除が同時に行われない」と「データをロストしないための設計が必要」の2つをピックアップして紹介したいと思います。
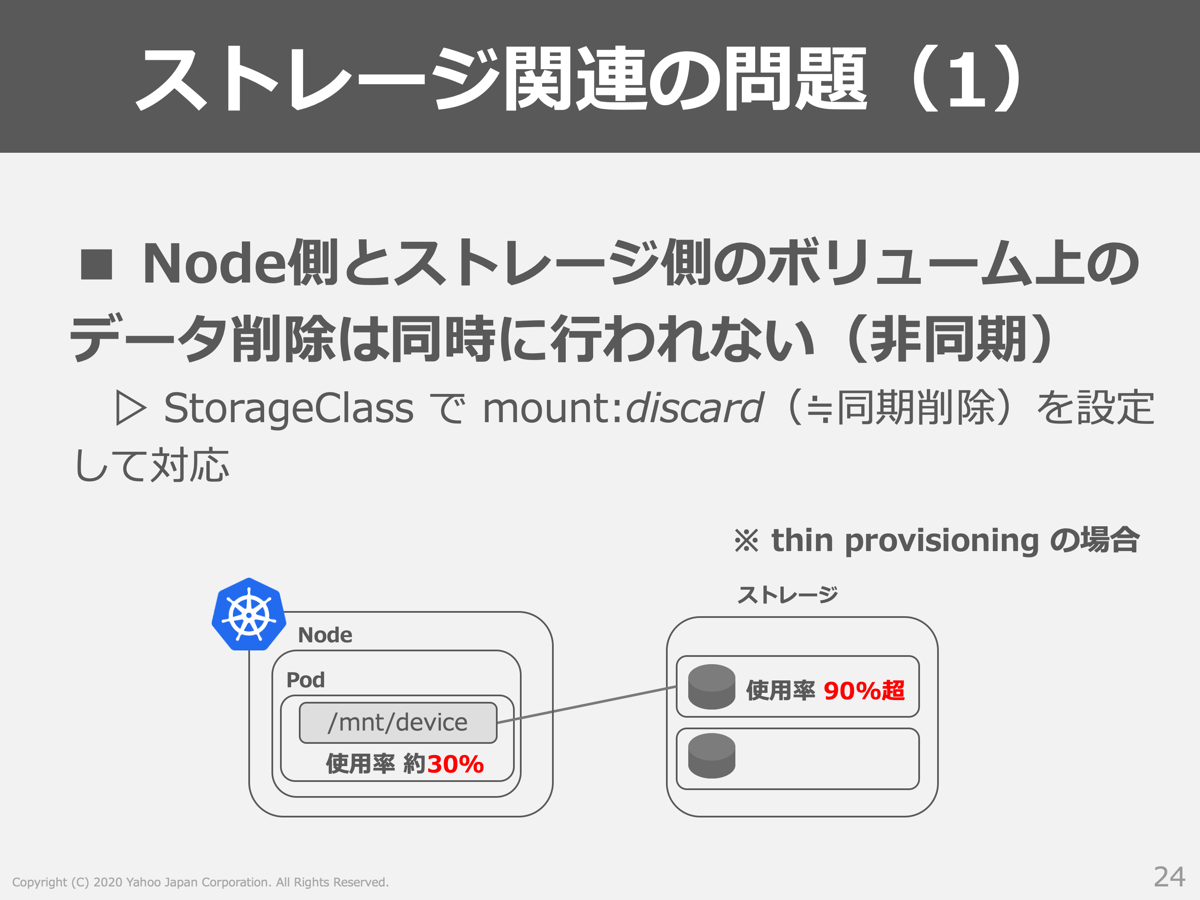
まず「ノード側とストレージ側のボリューム上のデータ削除が同時に行われない」という問題について紹介します。
ストレージがThin Provisioningの場合、ストレージ側のデータ削除が非同期で実行されるため、負荷が高い状況ではノード側で確認できる使用率とストレージ側の実際の使用率が異なるという問題が発生しました。これにより、ノード側ではまだボリュームに空きがあるように見えるため書き込み処理を実行しようとしますが、ストレージ側の使用率は限界であるため書き込むことができないという問題が発生しました。discardオプションを付与してマウントする方法でこの問題は解決でき、現在はAddon-managerにより提供されるStorageClassにデフォルトでそのオプションが適用されるようになっています。注意点として、discardオプションを付与することで性能に影響する場合があります。今回の導入事例では、ゼットラボにて事前検証し性能影響が発生しないストレージを選択しています。これにより、サービス運用に影響が出るほどの性能劣化は見られていません。
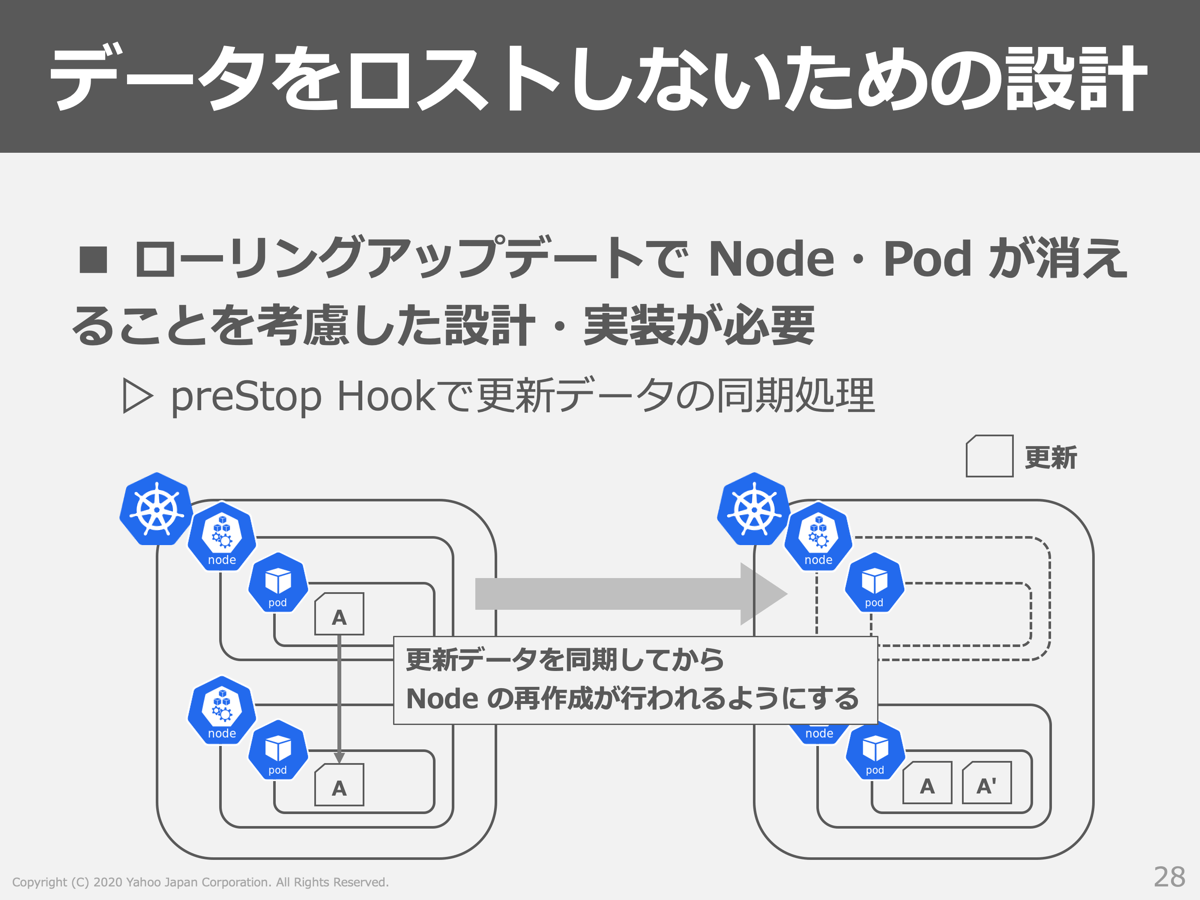
次に、「データをロストしないための設計が必要」という問題についてです。
CaaSではステートフルな環境の骨組みは提供されていますが、そのステートフル性を過信しすぎることは禁物です。例えばVespaはレプリカ間のbucketの同期を行う仕組みがありますが、その同期状況を考慮せずにローリングアップデートが行われると、同期が不完全なままVespa Serverがダウンしてしまうため更新情報がロストするという問題がありました。そこでpreStop Hookを活用して、確実にデータをロストしない仕組みを取り入れるようにしました(※2)。利用するアプリケーションの特性に応じて、Gradefulに停止させる方法は変わってくると思うので、こういった点を考慮しながらCaaS導入を進めることが重要になると考えています。
※2 PodDisruptionBudgetなど他のリソースも活用しています
おわりに
本記事では、ヤフーとゼットラボにて取り組んでいるCaaS向けステートフルサービスへの取り組みと、YDAへの導入事例について紹介しました。
前半パートでステートフルサービスを提供するためのCaaSのアーキテクチャのポイントを紹介し、後半パートでYDAの広告配信を支えている検索エンジンVespaをCaaS上で稼働させる事例について紹介しました。ステートフルなアプリケーションをKubernetesで稼働させるためには苦労する点も多いですが、運用コストの改善など将来的に見てもメリットとなる側面が多いと考えています。YDAでは、これから本格的な導入を進めていくため、運用コストがどの程度改善されたかなどを随時確認していく予定です。
本記事の情報がKubernetes上でのステートフルアプリケーションを検討している方の参考になれば幸いです。
ヤフーでは大規模にKubernetesが利用されています。そのような環境で働くことに興味がある方は以下からご応募いただけると幸いです。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました

- 坂下 幸徳
- ゼットラボ株式会社 ソフトウェアエンジニア
- Kubernetesでのストレージ活用、Statefulアプリケーションの普及を狙い奮戦中。
-
- 飯田 諒
- ヤフー株式会社 バックエンドエンジニア
- 広告配信システムの開発と運用を担当しています。



