こんにちは。インターン生の齋藤主裕です。
この記事では私がヤフーの音声認識チームで2週間のインターンシップを行った際に取り組んだ内容について紹介します。インターンシップでは主にストリーミングEnd-to-End音声認識のレスポンスを高速化する技術のうち、国際学会で最近発表された技術の追試を行いました。以下ではその技術の概要と得られた結果、およびインターンシップの感想について書きます。
ストリーミングEnd-to-End音声認識とは
ニューラルネットワークを使って音声情報から直接発話文字列を出力する手法をEnd-to-End音声認識といいます。End-to-End音声認識は従来手法(ニューラルネットワークと隠れマルコフモデルのハイブリッド音声認識)と比べて認識精度の向上、モデルサイズの大幅な縮小、開発保守の容易化などのメリットがあり、プロダクションレベルで従来手法を置き換えつつあります。
また、音声認識の中でも実用上特に重要なのがスマホの音声入力などで使われるストリーミング型の音声認識です。ストリーミング型の音声認識ではユーザーの発話とほぼ同時に音声認識を行う必要があるため、「正確な認識精度」だけではなく「高速なレスポンス」も求められます。
このストリーミング型の音声認識をEnd-to-Endで行うことをストリーミングEnd-to-End音声認識と呼び、実用化に向けて世界中で活発に研究開発が行われています。
今回取り組んだ技術
今回のインターンではストリーミングEnd-to-End音声認識において、レスポンスを高速化(遅延を削減)する技術の追試を主に行いました。レスポンスを高速化することによって、サクサクと軽快に動作する音声入力アプリや瞬時に応答する音声エージェントなど、よりよいユーザ体験を実現できます。追試を行った技術は以下の2つです。
FastEmitはICASSP 2021に、SelfAlignはINTERSPEECH 2021に、それぞれ論文が採択されており、いずれも最新の技術です。
技術の概要
どちらもRNN-Transducer(RNN-T)というストリーミングEnd-to-End音声認識技術をベースに、学習に特殊な正則化を加えることでレスポンスを高速化するという技術です。RNN-Tは音声入力を少しずつ受け取りながら「文字列の出力」(認識結果を出力する)か「待機」(認識する前に音声の続きを聞こうとする)のどちらかを行います。これらの論文では「待機」よりも「文字列の出力」を優先するという正則化を入れることによって、結果として早めに認識結果を出力するモデルの学習を誘導します。認識精度だけを優先するとしっかりと最後まで聞き取ってから認識結果を出力するモデルができるのに対して、これらの技術で得られるモデルでは多少認識精度を犠牲にしてでもなんとなく言っていることがわかった時点で認識結果を出力してしまうようにするというイメージです(例:「うさg」まで聞こえたから「うさぎ」だ!)。
2つの手法の違いは以下のようなイメージです。
- FastEmit:いつでも「文字列の出力」を優先するするように学習する
- SelfAlign:認識しやすいタイミングを学習中に見つけ、それよりも少しだけ早く「文字列の出力」を行うように学習することで認識精度と高速なレスポンスの両立をしようとする
実装方法と並列アルゴリズム
実装はPyTorchおよびChainerをエンジンとした音声認識ツールキットであるESPnetおよびその内部で使われているwarp-transducerをベースにし、主要部分はCUDAカーネルで記述しました。
ちなみにSelfAlignははじめPyTorchで実装していたのですが、WSJデータセットの学習に5日かかる予測が出て絶望していました(今回のインターンは2週間です)。そこでCUDAカーネルに書き換え、さらに並列アルゴリズムを見直して高速化を行ったところ、学習が5時間にまで高速化できたのが嬉しかったです。
参考:並列アルゴリズムについて
ここで、並列アルゴリズムについても簡単に紹介します。アルゴリズムの詳細に興味がある方以外は、飛ばしていただいても構いません。
SelfAlign では Viterbi アルゴリズムを用いて Viterbi Forced Alignment(上の方で書いた「認識しやすいタイミング」に相当するもの)を求めるステップで大きな計算量が掛かるため、この処理を高速化する必要があります。Viterbiアルゴリズムは格子状のグラフで最も確率が高い経路を求める方法で、以下のような基礎的な動的計画法の式で計算します。
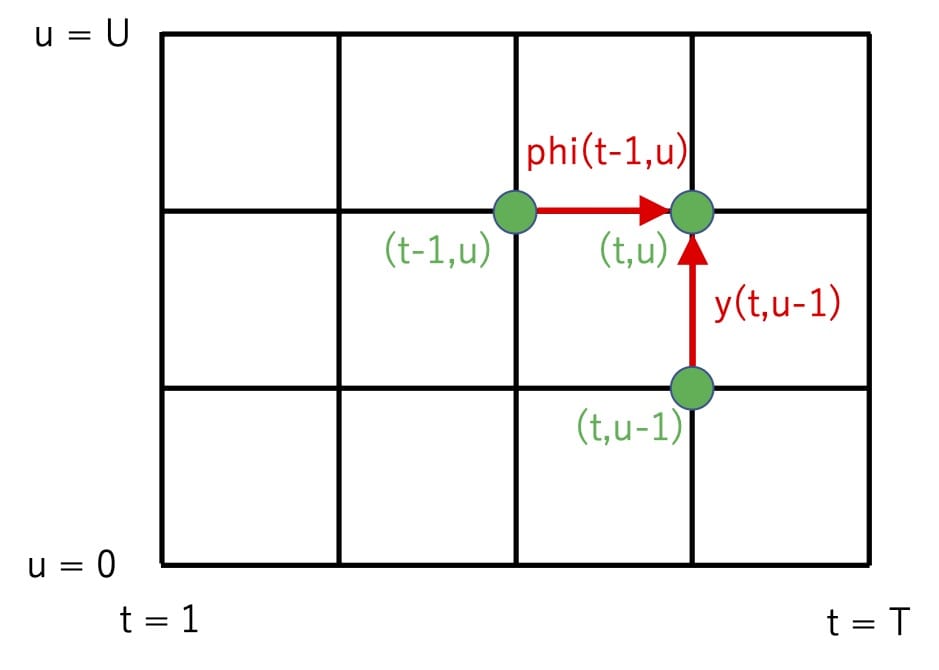
まず、RNN-T の損失関数およびその勾配の計算では下図のような格子状のグラフを考えます。ここで格子状の各点を(t,u)で表し、点(t,u)から点(t,u+1)へ遷移する確率をy[t][u]、点(t,u)から点(t+1,u)へ遷移する確率をphi[t][u]で、それぞれ表すことにします。これらの確率は、時刻tまでにu番目の文字まで出力した時点で、次にu+1番目の文字を出力する確率 Pr(y_{u+1}|t,u) と、次にブランク文字φを出力する確率 Pr(\phi|t,u) に、それぞれ対応しています(先ほどの言葉でいうと「文字列の出力」と「待機」にあたります)。次にSelfAlignでは、始点(t=1,u=0)から終点(t=T,u=U)までの経路のうち確率が最大になるものを求めることを考えます。始点から点(t,u)まで経路のうち最も確率が高い経路の確率を dp[t][u] とおくとき、dp[t][u]は以下の漸化式で求められます。
dp[t][u] := max(dp[t][u-1]*y[t][u-1], dp[t-1][u]*phi[t-1][u])このとき、点(t,u)への遷移元が点(t,u-1) と点(t-1,u) のどちらだったのかをバックポインタ bp[t][u] に記録しておき、終点まで到達したあとに逆向きにバックポインタをたどっていくことで確率最大となる経路を見つけられます。以上のアルゴリズムの計算量は格子の横幅T、縦幅Uに対してO(TU)です。
この式を直接並列化するのは自明ではないと思いますが、以下のように式変形を行うことで並列化する方法が見えてきます。
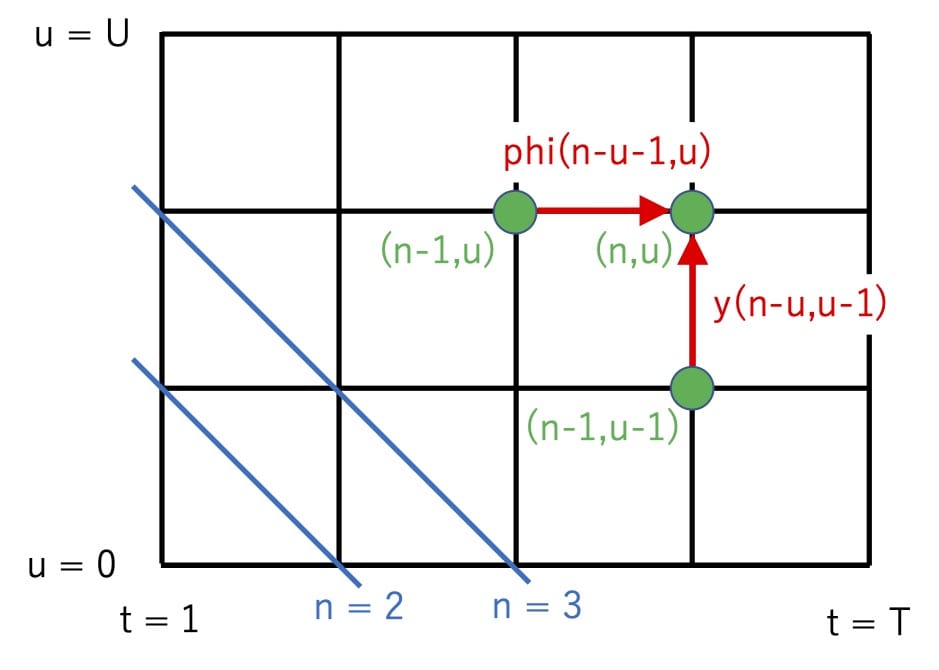
n := t + u
dp[n][u] := max(dp[n-1][u-1]*y[n-u][u-1], dp[n-1][u]*phi[n-u-1][u]) これは格子状の点を斜めに走査していくイメージの式変形です(下図)。この式はdp[n]がdp[n-1]にしか依存していないので、uに関して並列化できます(図を見るとdp[n][u]はdp[n-1][*]さえ求まっていればuの順番に依存しないことがわかると思います)。これを用いてuに関して並列化すると並列化部分をO(1)とした時全体の計算量はO(T + U)となり、線形の計算量に落ちます。
以上がアルゴリズムの並列化の解説です。並列アルゴリズムの厳密な記法と一致しない部分もあるかと思いますが、ご容赦ください。
実験
実験設定
実験はWSJ(Wall Street Journal)とLibriSpeechという 2つの英語音声認識のデータセットで行いました。WSJ は音声データが約81時間と小規模なデータセット、LibriSpeech は同約960時間という比較的大規模なデータセットです。RNN-T モデルには、ストリーミング向けの設定として、エンコーダに6層のUnidirectional LSTMを用いました(その他はESPnetのAISHELL-1というレシピの設定を用いました)。
なお、インターン期間が限られていたこともあり学習および認識に掛かる時間を短縮するため、今回の実験では小さめのサイズのモデルを用い、学習データを拡張する “speed perturbtion” は用いず、また認識時には言語モデルを用いませんでした。そのため、認識精度は論文で報告されている数字よりも少し悪くなっていますが、レスポンス速度の改善効果を確認するには十分な認識精度だと思われます。
評価指標と目的
今回の実験ではFastEmitの論文でも用いられている以下の2つの評価指標を用います。
- Word Error Rate(WER):認識精度の評価指標。小さいほど良い。どれだけの割合で認識を間違えたかを表す。
- Partial Recognition Latency(PR):レスポンス速度の評価指標。小さいほど良い。発話が終わってから認識結果が確定するまでにかかった時間を表す。
今回の実験の目的はこれらの技術が実際に小さいWERを保ちつつPRを小さくできるか確認することです。
なお、PRについてここでは50パーセンタイルであるPR50と90パーセンタイルであるPR90を掲載しています。
実験結果
WSJ データセット
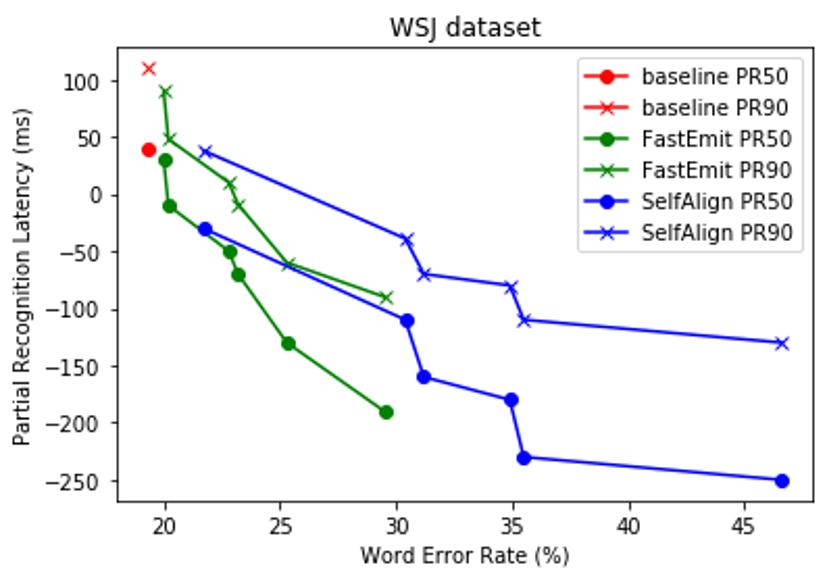
認識精度とレスポンス速度のトレードオフを調整するハイパーパラメータ(λ)を複数取って実験しました。結果を以下の図に示します。
横軸がWER、縦軸がPRなため、折れ線グラフが左下に寄っているほど優れた手法であることがわかります。なお、baselineは通常の学習を表し、λは小さい点からどちらの手法も0.001, 0.004, 0.008, 0.01, 0.02, 0.04です。
図を見てみると、PR50でもPR90でもFastEmitがSelfAlignよりも優れていることがわかります。またどちらの手法でも、(認識精度を多少犠牲にしつつも)ベースラインと比べてレスポンス速度が改善していることを確認できます。
Librispeech データセット
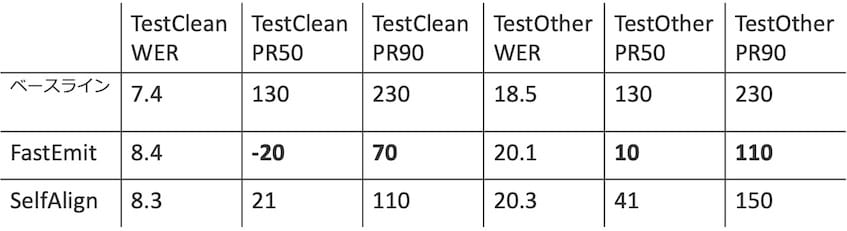
こちらはデータセットのサイズが大きく多くのハイパーパラメータでの実験が行えなかったため、ほぼ同一のWERとなった点ひとつで比較します(λは0.001です)。結果を以下の表に示します。
TestCleanとTestOtherのどちらの評価セットでもFastEmitが優れていることがわかります。またどちらの手法でもベースラインと比べてレスポンス速度が改善していることがわかります。LibriSpeechという比較的大規模なデータセットでも、WSJ データセットと同様の傾向を確認できました。
考察
FastEmitに関しては、おおむね元論文の主張通りの結果が得られました。一方でSelfAlignはFastEmitよりも全体的に劣っており、論文の主張とは異なる結果になりました。直感的にもSelfAlignの方が低いWERの劣化でPRを小さくできそうな印象を受けていたのでこれは意外でした。なぜこのような結果になったのか検証するには、さらなる実験が必要だと思われます。また、両者の学習方法を組み合わせたような手法を考えることもできるので、機会があれば実験してみたいと思います。
OSS貢献
余談ですが、私が書いたFastEmitのCUDAカーネルがESPnetの公式実装に取り込まれました。
FastEmit実装はインターン期間とほぼ同時期に他の方が出したESPnetへのプルリクエストがマージされていました。しかしよく見るとこの実装が間違っていることに気づき、ちょうど実験結果がそろっていることもあったので、私が書いたコードに修正するようなプルリクエストを送信したところ、無事にマージされました。自分が書いたプログラムが大規模なOSSに取り込まれるのは初めてなので、貴重な体験ができました(正確にはプルリクエストを送信したのはESPnet本体ではなくwarp-transducerのESPnet用のブランチです)。
おわりに
大変だったこと
ここまでインターン期間でやったことを簡単にまとめましたが、大変だったこともありました。
まず、音声についてほぼ未経験から2週間で基礎知識から勉強を始め2つの論文の実験を終わらせるのはそれなりにハードでした。実験を回し始めてから結果が出るまでに5時間〜3日ほどかかるため、結果を検証できる回数が少なかったこともその一因です。
また、既存の実装をベースに書いたため大きくて複雑なコードを読み解く必要があったことや、CUDAプログラムのデバッグに苦労したなどエンジニアリング的な困難さもありました。
今回検証した論文にまつわる苦労としては、warp-transducerのRNN-T(のforward-backwardアルゴリズムを用いた勾配計算)の実装は利用メモリ削減のためsoftmaxの出力ではなくロジットに関する勾配を直接計算しており、FastEmitの実装時はそれに合わせるために元の論文よりも複雑な式を考える必要があったことも少し大変でした。SelfAlignに関しては先ほども書きましたが、今回のインターン期間中に学習を終わらせるためには並列アルゴリズムを考えて実装しなければならなかったので、ここでも工夫が必要でした。
感想
私がこのインターンシップに応募した目的は普段あまり取り組まない音声分野を体験してみるためでしたが、その目的通りしっかりと音声分野の論文読みからコーディングと実験までを体験でき、非常に充実したものになりました。ニューラルネットワーク分野の手法はなかなか再現できないことも多いですが、今回の手法は再現性が非常に高い論文で実験でもしっかりと結果が出たので、その点は運が良かったと思うとともに、メンターの方の論文選びのセンスの良さだと感じました。その他にも今回のインターンシップの活動が円滑に行えたのは音声認識チームのメンターの方の多大な協力があってのものでした。この場を借りて感謝します。2週間ありがとうございました!
(この記事に関連する採用情報「音声認識エンジニア・研究員」もぜひご覧ください)
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました
- 齋藤 主裕
- 音声認識 インターン生



