こんにちは。ヤフーでプライベートIaaS(Infrastructure as a Service)の構築・運用を担当している高橋です。
IaaSはサーバやストレージ、ネットワークなどのリソースを仮想的に定義してサービスとして提供することを指します。ヤフーでは社内のプラットフォームやユーザに提供するサービスの運用のためIaaSを社内で構築・提供しています。
本記事ではヤフー内のIaaSをかげで支えるKubernetesのアップデート事情について紹介します。
ヤフーのIaaSの構成
IaaSに関連する仮想マシン、そして仮想マシンを動かすためのハイパーバイザーやネットワークといったリソースを管理するためにOpenStackというOSSがあります。
ヤフーではIaaS基盤としてこのOpenStackというソフトウェアを利用しており、現在運用されているクラスタ数は200を超えます。またOpenStack上で稼働している仮想マシンは170,000台以上あります。
このOpenStackというOSSは単体で一つのプログラムというわけではなく、コンピュートリソースを管理するためのNova、ネットワークリソースを管理するためのNeutronなど複数のコンポーネントによって構成され動作しています。
OpenStackクラスタが200以上ともなると管理するコンポーネント数が膨大になるため、コントローラー側のコンポーネントに関しては専用Kubernetes上で管理しています。これによってOpenStackクラスタの構築運用に関わるコストを大きく削減しています。
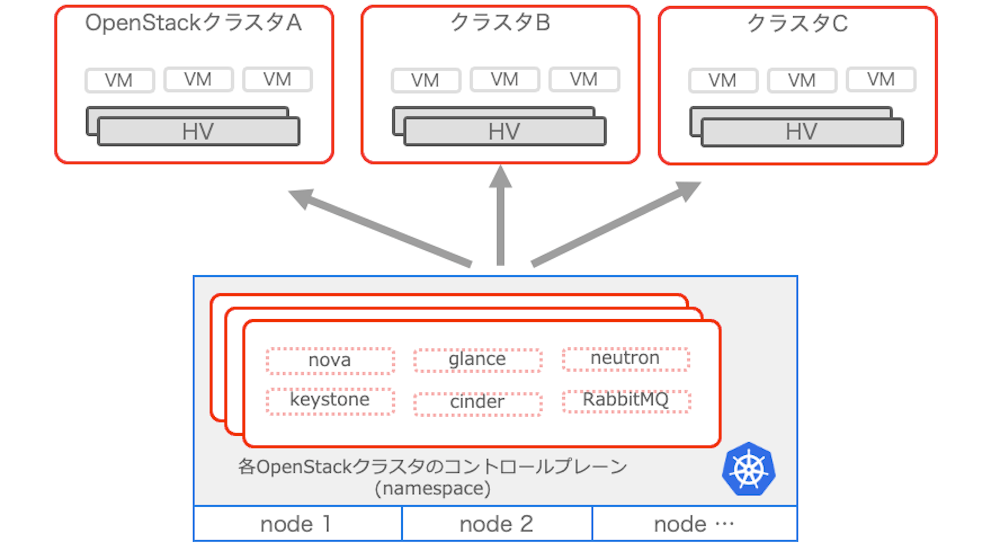
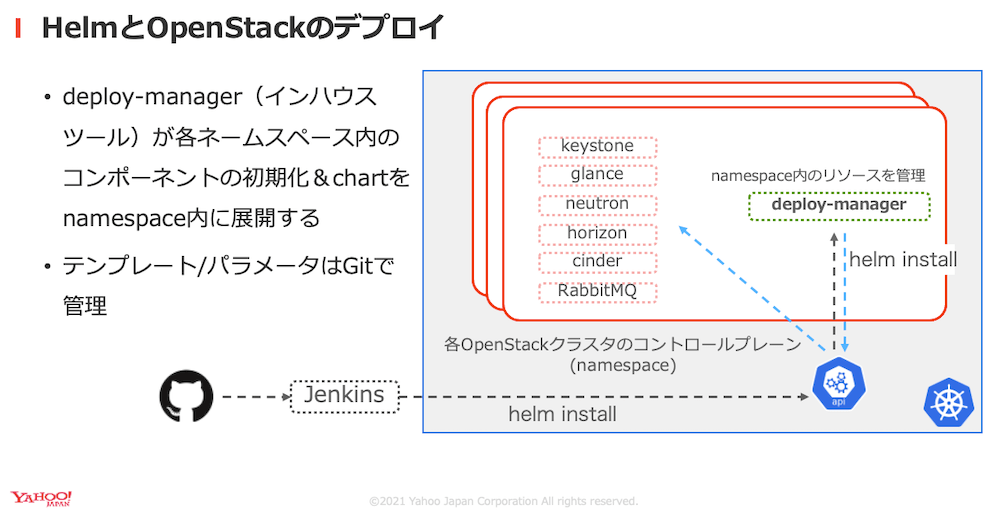
またKubernetes上のOpenStackの管理コンポーネントおよび必要なサービスなどのデプロイは、Kubernetesのリソース管理ツールであるHelmを利用しています。そしてHelmによってデプロイされるリソースのパラメターはGitで管理されています。
これによってOpenStackクラスタのパラメータに変更が必要な際は、変更をpushすることで自動的に変更が反映される仕組みになっています。
私たちは仮想マシンが動作するハイパーバイザはもちろん、Kubernetesも自分たちでハードウェア環境から管理するオンプレミス(オンプレ)で構築しています。そして今回はオンプレ環境だからこそ苦労している、OpenStackのコントロールプレーンであるKubernetesクラスタのアップデートについてお話しします。
これまでの運用
先ほど紹介したようにヤフーのIaaSではKubernetesは縁の下の力持ちとして重要な役割を担っています。しかしOpenStackのコントロールプレーンをKubernetes上に動作させる現在の構成にしてから間もない頃は、IaaSも導入期で安定稼働が求められたためKubernetesのアップデートは見送られていました。具体的には、Kubernetes 1.8の状態で2017年より運用が続けられていました。
さらにKubeadmなどの管理ツールを利用せず構築していたため、アップデートのコストが高かったことも理由として挙げられます。
そして何よりもオンプレで運用しているとアップデート作業は以下のような理由で難しくなります。
- 仮想マシンに比べて再起動に多くの時間を要する
- 正常に再起動が完了するとは限らない
- シャットダウン後疎通が取れず、状態が確認できない状態に陥る
- アップデート中のノードの代わりに一時的に他のマシンをクラスタに加えるなどの柔軟な対応が難しい
そのためすべてのKubernetesクラスタの物理サーバをアップデートするのは大変な労力が必要です。
しかしチーム内でのKubernetes利用拡大とともにIaaSは成熟期に達したため、コントロールプレーンとして利用しているKubernetesクラスタのアップデートを進めていくことにしました。
Kubernetesクラスタのアップデート
IaaSチームではChefという構成管理ツールを利用してサーバの運用をしています。そのため基本的には更新対象のパッケージを準備してChefで構成情報を変更し、そして対象ノードでChefを実行することで単一ノードについてはアップデートを完了できます。
しかしOpenStackへ影響を出さないように、Kubernetesクラスタ全体をアップデートするのはそう簡単ではありません。
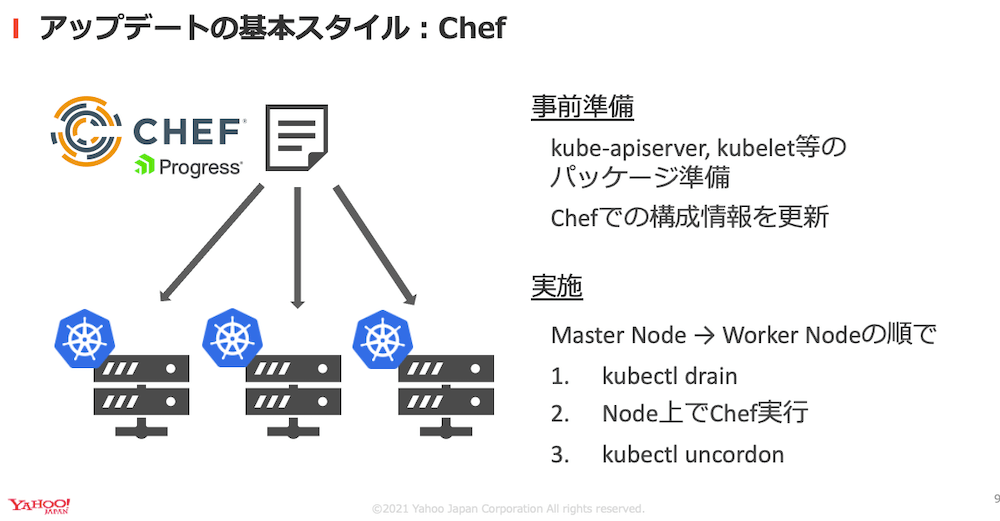
簡単に手順をまとめると以下の通りです。
- ワーカーノードをクラスタから切り離す
- 切り離したノード上でChefを実行
- アップデート完了後クラスタに参加させる
切り離しや再度クラスタに参加させる際はKubernetes Podの移動が伴うこため、Podネットワークや上に乗るサービスが不安定になりがちです。
そのため作業実行時には正常にアップデートができているか確認する監視が欠かせません。
また不健全な状態に陥った場合はアップデートをストップし、サービス復旧に力を入れなければなりません。
こういった監視を最初は標準のCLI(Command Line Interface)であるkubectlなどを利用して確認していましたが、アップデートを複数クラスタ同時に進めているような状況では個別のCLIを操作するのが難しくなってきました。
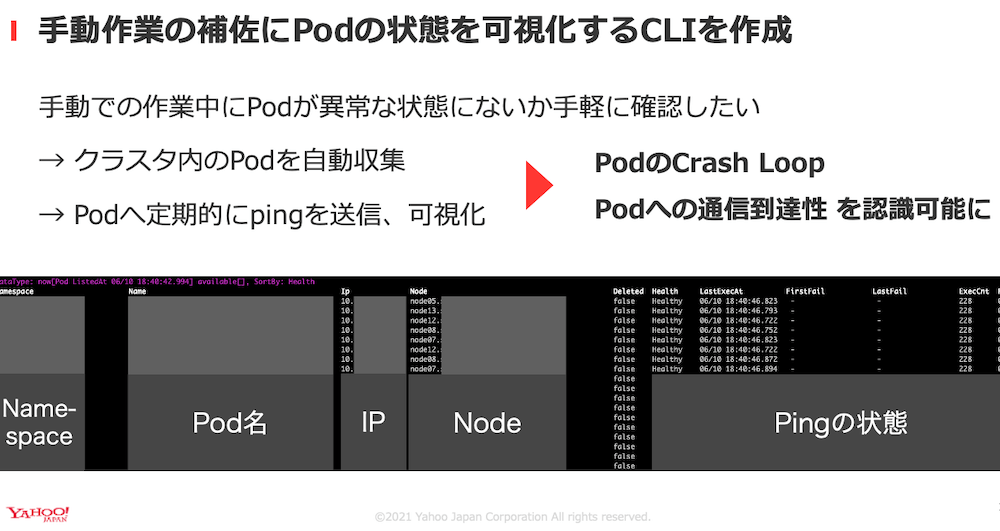
そこで私たちはアップデート作業の改善として、クラスタ上のPodやサービスの状態を可視化するための専用CLIツールを作成することにしました。
このツールが頻繁にKubernetesリソースに対して情報を収集し疎通性を確認するので、リソースが健全な状態であることをひと目で確認するできるようになります。
アップデートの自動化
専用のCLIを作成したものの、たくさんのノードを抱えたクラスタが複数、そしてなによりも日々規模が大きくなるクラスタを手動でアップデートするのは容易なことではありません。そしてKubernetesは比較的高い頻度で新しいバージョンがリリースされることから、この次のステップとしてアップデートの自動化が求められていました。
私たちは最初に利用していたKubernetes 1.8からスタートして徐々に自動化を進めてきました。

そして現在ではほとんどの作業を自動化できている状態にまで至ることができました。
ここに至るまでに工夫した点を一つ紹介します。
私たちはアップデートの自動化のために、Kubernetesクラスタのアップデートの際はOpenStackのE2Eテストを組み込んでいます。理由はFabricというPythonのタスクランナーを使用した際におきたトラブルが理由です。Fabricは対象のホストにssh経由でコマンドを実行するツールです。
Fabricを使って、クラスタのアップデートとリソース監視を組合させてアップデートを行っていましたが、OpenStackのユーザから問い合わせで仮想マシンの新規作成ができないことに気づきました。
直接の原因はOpenStackに利用しているメッセージキューへの再接続にバグが有り、不適切なTCPコネクションを維持していしまうことにありました。
Kubernetesリソースの状態を監視していたとはいえ、ユーザからの問い合わせがあるまで、障害に気づけなかったことは大きな問題です。
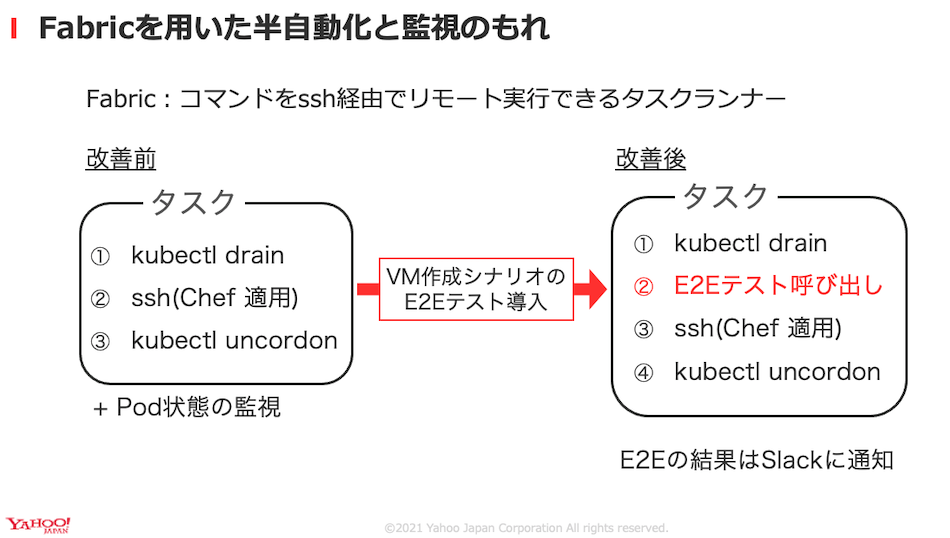
Kubernetesクラスタのアップデートの際はOpenStackのE2Eテストを組み込むことによってOpenStackクラスタの操作でE2Eテストに失敗した場合はSlackで通知を受け取り障害に気づけます。
アップデート作業の知見
大規模なクラスタのアップデートには膨大な作業が伴います。こういった作業は定期的に発生するため自動化することで実施コストをぐんと下げられます。そしてこの自動化に必要な要素に関しては1歩ずつ積み上げる必要があります。
テスト環境で成功したアップデートプロセスでも実際に動作しているクラスタへ適用するとさまざまな問題が発覚します。よってはじめから大きな構想を描いてしまうと、前提に問題があった際に思わぬ転び方をしてしまいます。
アップデートプロセスを組み立てる際は作業ごとに必要な点を洗い出して、1つずつ丁寧に実装することで必要なものが出来上がると感じました。
そして実際に本番への反映で得られた反省はコードとして残し次回のアップデートにつなげます。
それからもう一つ大事なことは、アップデート途中に問題が発生していないかを検知する仕組みづくりです。Kubernetesのリソースから上にのっているアプリケーションの正常性まで全てをアップデートの際に目視で確認するのはほぼ不可能です。また自動化されたアップデートでは異常を検知できなければ、次々とシステムを破壊してしまいかねません。
これらを防止するためにはアップデートプロセスごとに正常な状態を正確に定義し、そこからそれた場合は運用者に通知する仕組みが重要です。
総じて私たちが得たアップデートの完全自動化のため得た知見としては以下の2点です。
- アップデートに必要なプロセスの洗い出し、そして得られた知見のプロセスへの反映
- 正常でない状態の定義とその検知の仕組みづくり
まとめ
本記事ではヤフーのIaaSを支えるKubernetesクラスタの構成を紹介しました。またオンプレで構築しているからこそ苦労した大規模Kubernetesクラスタのアップデート作業についてお話ししました。
このように大規模なクラスタの運用ではアップデート作業も含めた効率的な運用が必要不可欠です。そしてアップデート作業の自動化にはアップデートプロセスの継続的な改善が欠かせません。
このように私たちはより効率的に大規模な環境を運用できるよう日々運用プロセスの改善に取り組んでいます。
本記事は2021年7月14日より行われたCloud Operator Days Tokyo 2021での講演を元に記事化したものです。
Cloud Operator Days: https://cloudopsdays.com/
アーカイブ動画: https://www.youtube.com/watch?v=N2Xvr9R-IS8
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました
- 高橋 陽太
- クラウドエンジニア
- 2020年入社以来IaaSチームにて開発運用に従事しています。



