こんにちは。ヤフーの大岩です。
ヤフーが提供するYahoo!ショッピングやPayPayモールでは1年に1度大規模セールを行っています。
去年(2020/10/17~11/15)の対象期間は、超PayPay祭の開催に合わせて過去最大級の大規模セールとなっていました。特にセール最終日はグランドフィナーレと呼ばれ、ポイント還元率が年間を通して最大となる1年で最もお得な日となっていました。
集客の予測値は通常セールの数倍が見込まれており、セールの高負荷を乗り切るために、セール高負荷専用の対策チームが組まれ、そこを中心として高負荷対策を進めることになりました。
本記事では、大規模セールの高負荷に対して実際にどのような負荷対策を行ったかをサービス組織とプラットフォーム組織の視点で紹介します。
セールに向けた負荷対策
本題に入る前に、ヤフー全体の開発組織体制について説明します。ヤフーでは大まかにサービス開発を行うサービス組織と、サービスが稼働する基盤を開発・運用するプラットフォーム組織が存在します。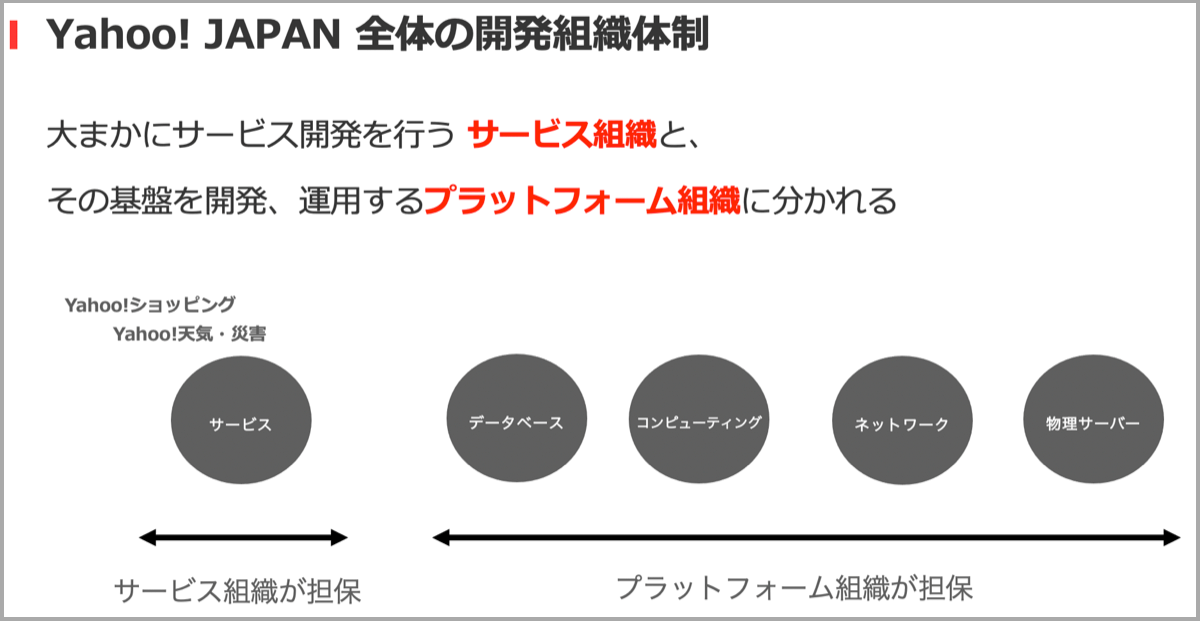
今回のセール対策では、下記が組織ごとの主な責務です。
- サービス組織
- 想定されるサービスへの負荷見積
- 要求されるマシンリソースやネットワーク通信量の算出
- 過負荷時のアプリケーションレイヤーでの対策
- プラットフォーム組織
- サービス組織に要求されたリソースの確保
- 各プラットフォームのSLOの遵守
ここで、2020年の大規模セールに向けて、実際に対策した内容の一部を紹介します。
- クーポンの発行やアプリプッシュ通知等により、特定の時間帯にユーザーが集中しないように企画担当者とイベント、スケジュールを調整
- 主要な機能(検索、購入、etc…)がダウンした際のオペレーション整理
- 過負荷時の対策機能の実装(注文の非同期化、障害時専用の静的ページの表示など)
- キャパシティプランニングおよびスケールアウト
- 予測負荷を処理できるか深夜帯に負荷試験を実施
発生した障害と超PayPay祭の再来
上記の障害対策を実施し、2020年の大規模セールに万全な状態で挑んだつもりでした。しかし、残念ながら障害が発生してしまいました。
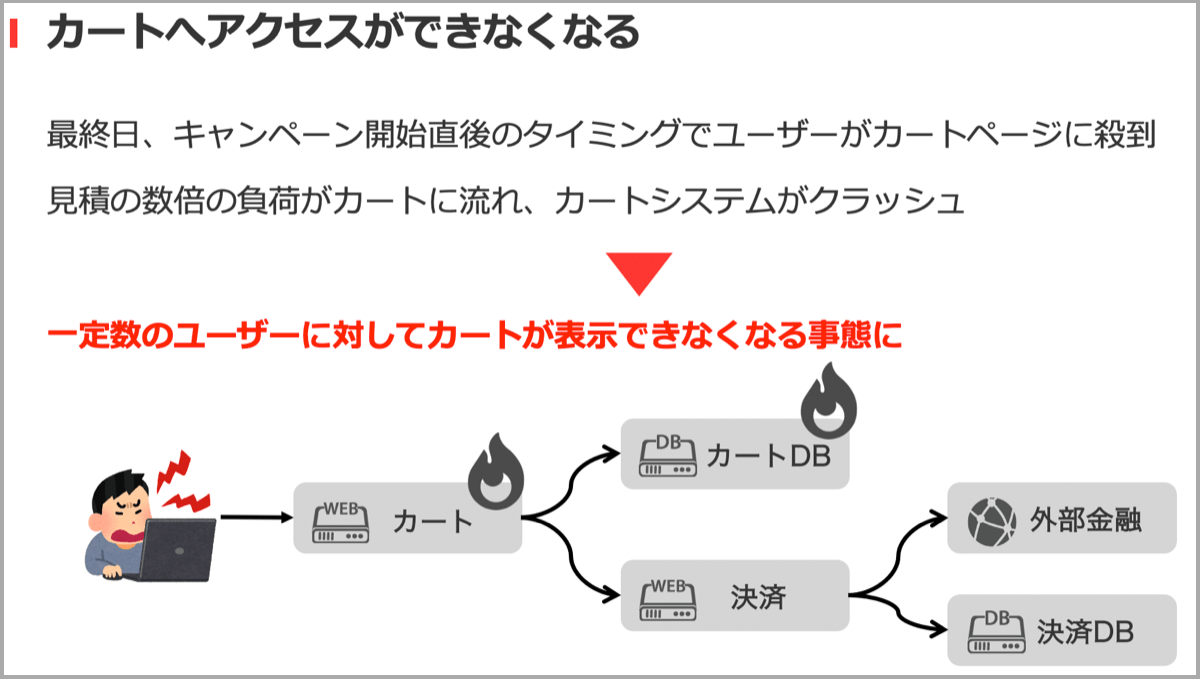
発生した障害は、ショッピングのカートページが表示できなくなりユーザーはアクセスできず、商品購入ができないというものでした。グランドフィナーレの日付切り替わりのタイミングでユーザが予測の数倍殺到し、カートシステムがクラッシュしてしまったのが原因でした。この障害によって当然多くのユーザーにご迷惑をかけてしまう事態となりました。
次の大規模セールまでにこの問題を改修するため、早急に障害の原因を調査し、過負荷時に問題を起こす要因としてシステムのコアロジックに依存する複数の原因を特定しました。幸いにも次の大規模セールは翌年の11月の予定であったため、猶予は1年と十分な時間があり、今回の反省を踏まえ次のセールに向けて動き出しました。
なぜ障害は起きてしまったのか
当然、負荷対策チームは今回のセールに向けてさまざまな対策を実施しており、想定される負荷をさばくという点においては十分な対策ができていたと考えています。
ここでの最も大きな落とし穴は、これらの対策が全て予測負荷が前提になっていて、これを大きく超えた場合の想定を誰も意識しておらず、また過去の予測から超えることはないと考えていました。また、実際のユーザーの動きを想定したシナリオで負荷試験ができていなかったといった反省点もありました。
負荷対策チームでは、負荷の見積方法として前年度のセールの負荷と予算をベースに今年度の予算との比率を出して負荷予測を計算していました。つまり、予算が2倍になれば負荷も2倍になるという見積を行っていました。この見積方法は、過去数年間に渡る大規模セールで運用され大きく乖離しなかった実績から、この予測が大きく外れることはないだろうと信じてしまっていたことが今回の障害を引き起こしたのです。本来われわれがすべきことだったのは予測された負荷を耐えるではなく予測を超えてもサービスを継続できるようにすることでした。
超PayPay祭、再び
このような反省も踏まえた上で来年度のセールに向けて動き出していましたが、ヤフーがLINEと経営統合したことを記念する2021年3月の超PayPay祭の開催が決定され、前回以上の規模感と超高負荷も予測されました。

この時点で残り期間は3カ月しかなく、当初1年かけて実施しようとしていた対策の実施は不可能であり、限られた期間で実現可能な有効打を急遽打つ必要に迫られました。
次節では実際に残り3カ月でどのように対策を打ったのかをサービス側・プラットフォーム側それぞれの視点で紹介します。
サービス側負荷対策
サービス側負荷対策として、Yahoo!ショッピングおよびPayPayモールで実施した対策を紹介します。
負荷試験の徹底
11月の超PayPay祭の負荷対策でも負荷試験は実施していたのですが、
- 適切に負荷がかけられていない
- 各システムが利用するプラットフォームへの負荷が不透明
- 単体システムごとの負荷試験のみだったため総合的な負荷に対する問題の洗い出しができていなかった
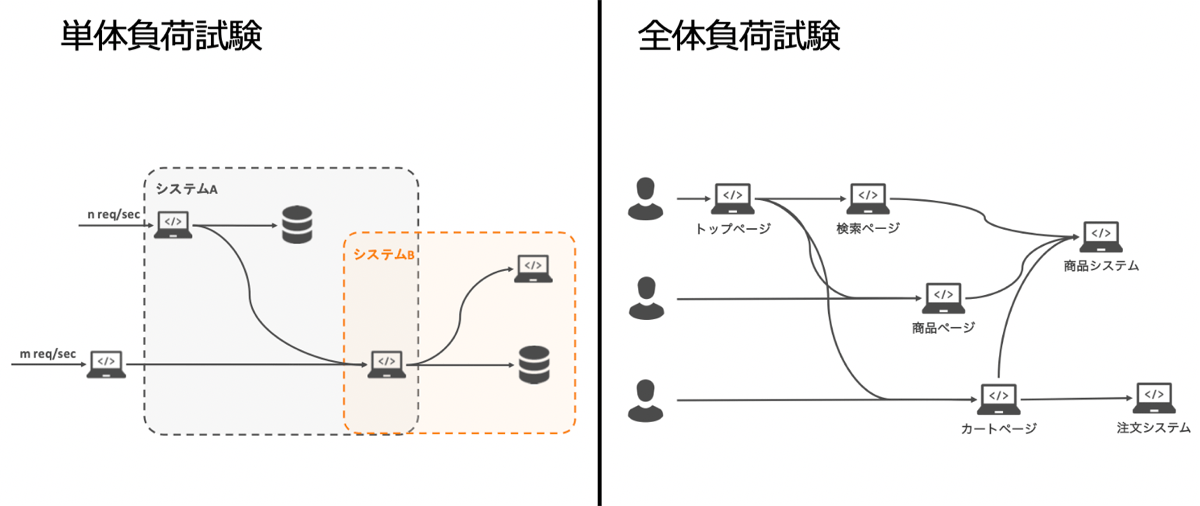
など、いくつかの課題がありました。そこで、2021年3月の超PayPay祭に向けた負荷対策では、試験内容の見直しや単体負荷試験と全体負荷試験と二種類の試験を行うことで徹底的に実施しました。
- 単体負荷試験
- ユーザーにサービス提供する上で必須のシステムを個別に重点的にテスト
- 主要なシステムについて詳細な構成図作成と綿密な負荷見積の実施
- 利用する各システム・各プラットフォームを含めて試算
- サービス・プラットフォーム担当者で複眼でチェック
- 全体負荷試験
- 高負荷時にシステム全体として問題なく機能を提供し続けられるかの確認
- 実際のユーザーの行動に促したシナリオ
- トップページ→検索→商品ページと遷移するようなユーザー
- 直接カートページにアクセスするといったユーザーからのリクエスト
- 想定を超えた負荷がかかった場合のテスト
負荷試験の際には、プラットフォーム担当者も待機しリアルタイムに監視することで、ボトルネックや懸念点の洗い出しを実施しました。この試験結果を踏まえてスケールアップ・スケールアウトや実装修正、構成変更を何度も繰り返しました。本番直前3日前まで何度も繰り返し、万全な状態で臨めるように取り組みました。このように負荷試験を徹底的に実施し、システム全体の問題をつぶしていき、大規模セールに挑める状態に仕上げていきました。
RateLimitの活用
負荷試験を通して想定負荷に対するキャパシティは用意できたものの、予測以上の負荷がきてしまった場合、システムがダウンしてしまうリスクがあり、ショッピングで購入できなくなる可能性があります。さらに一部システムでは実機を利用しているなどの理由で即座の増強も難しい状態でした。
そこで、許容範囲を超える量のリクエストを制限するRateLimitを導入することで、システム全体のダウンを防ぎつつ、最低限購入可能な状態を維持できるように対応しました。
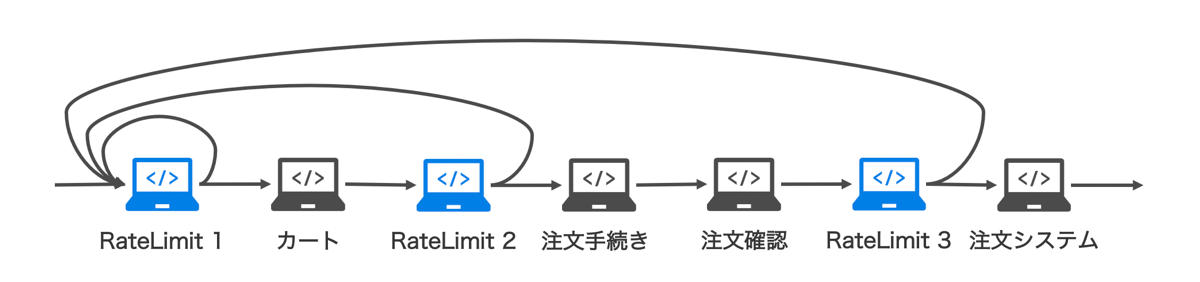
今回実施したRatelimitの掛け方は下記の通りです。
- 購入したいユーザーは必ずカートページを閲覧するため、カートページがダウンしない程度でRateLimitを設定
- 実際に手続きに進める人を絞り、さらに増設が特に困難だった注文システムの保全のためさらにRateLimitを設定
- Ratelimitに引っかかった場合はカートページに再アクセスするように促すページに遷移
これによりダウンさせずにユーザーにカート表示、注文機能を提供し続けることが可能となり、一定のユーザーについては継続利用可能な状態にできました。システム全体のクラッシュを防ぎ、継続的にサービス提供可能になったことで、不測の負荷に対しても備えられました。
プラットフォーム側負荷対策(クラウド編)
続いてプラットフォーム側の負荷対策について紹介します。ヤフーでは多くのプラットフォームがあるため、今回はクラウド領域における負荷対策を紹介します。
簡単にヤフーのプライベートクラウドの概要ですが、IaaS/PaaS/CaaSといったコンピューティング基盤があります。その上で、Yahoo!天気・災害やYahoo!ニュースなどはもちろん、超PayPay祭といった大規模セールに関わるショッピングの多くのアプリケーションが稼働しております。
このようなプライベートクラウドでの大規模セールのようなイベントにおける一般的な注意点・課題として下記が挙げられます。
- CPU/Memory/ネットワーク帯域などの必要となるリソースの把握と確保
- 特定のサービスだけ注力せず常に安定したプラットフォーム提供が必要
- イベントにおける超高負荷時のプラットフォームへの影響度合いの把握
上記の一般的な内容だけでなく、過去の超PayPay祭の経験から以下の課題も顕在化しました。
- 超PayPay祭が影響するプラットフォームの把握不足で緊急時の障害調査が難航していた
- セール本番当日にプラットフォーム上で緊急スケールアウトが必要となる利用者が一定数いた
- 突発セールであったためキャパシティプランニングに入っていない大量のリソース要求
これらの課題1つずつに対策を取ることでセール本番に備えました。

これらの課題対応について、サービス側負荷対策の際にも説明がありましたが、主要システムの利用プラットフォームの詳細を含めた構成図作成や本番同等かつそれ以上の負荷の負荷試験を実施してもらい、ボトルネックや問題点を把握してもらうことで、サービス側と連携しつつ事前に万全な状態になるように対策しました。また、追加で急遽大量リソースが必要になった課題については、余剰リソースのかき集めなどで500台近くの爆速増強祭りにより負荷対策で必要となるリソースを提供できました。
このようにクラウド側でも負荷対策を進めていましたが、ここで負荷対策中にクラウド担当者が恐怖したタイミングがいくつかあったので少し紹介します。負荷試験中にCPUが回りすぎて一部ラックの電力が上限付近まで到達しかけてラック全体が落ちかけた件や、PaaS環境の一部でCPUが超高負荷になり問題が起きないかヒヤヒヤしたりしました。このような課題についても一つずつ対策を施すことで、セール本番を安心して迎えられるように奔走しました。
負荷対策に奮闘した結果
サービス・プラットフォーム側でさまざまな負荷対策に奮闘した結果、最も負荷がくる最終日グランドフィナーレでは、大きな障害もなく無事乗り切ることができました。また、最終日は前回比1.8倍の取扱高と、過去最高記録も達成でき大成功となりました。
高負荷に立ち向かうために
最後に今回の負荷対策を通して学んだサービス・プラットフォーム側それぞれで大切なことをまとめます。
サービス担当者は、必要なキャパシティ・リソースを適切に見積もることがやはり大事であり、サービス運用者自信はもちろんプラットフォーム担当者にもシステムを知ってもらうことが大切です。また、想定以上の負荷がきてもサービス提供し続けるための設計や対策が必要です。
プラットフォーム担当者は、サービス側から急にどのような要求がきてもいいように、突発的なイベントに常に備えておくことが大事だと今回のセールを通して改めて感じました。サービス側を自ら知ろうとして、プラットフォーム側からコンサルして相互理解を促していけるとより良い関係を築いていけると思っています。あとは、プラットフォーム利用者に対して適切な利用の啓蒙も非常に大事です。
このようにサービス・プラットフォームそれぞれがより密に連携していけると、今回のような大きな成果も生みやすいのではと考えております。
まとめ
2020年の超PayPay祭では障害が起きましたが、サービス・プラットフォーム担当者が密に連携し、限られた期間の中で障害の原因分析や対策を進めることで、急遽開催となった超PayPay祭の高負荷に挑みました。負荷対策の効果として、万全かつ予想以上の負荷も考慮された状態となった結果、大成功しました。まだまだ課題は残っていますが、引き続き技術の力での課題解決を行い、今後の超PayPay祭などのセールも見据えてより良いサービスの提供を目指していきます。
本項は2021年の夏に開催されたCloud Operator Days Tokyo 2021でのヤフー株式会社の講演を記事化したものです。
- Cloud Operator Days:https://cloudopsdays.com/
- アーカイブ動画:https://youtu.be/jM2eB-RQP7I
また、こちらの発表で「実行委員会賞」を受賞しました。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました
- 大岩 朗
- クラウドエンジニア



