こんにちは、自然言語処理システムを開発している山城です。今回はYahoo!リアルタイム検索の一機能である感情分析機能の紹介と、そのシステム刷新作業の一環として行ったラベル偏り改善の取り組みについて解説します。
リアルタイム検索とは?ツイートから受ける印象を推定しよう!
Yahoo!リアルタイム検索というサービスがあります。ユーザーはこちらを用いて、Twitterに投稿されたツイート(つぶやき)が検索できます。
たとえばユーザーが『月曜日』という単語を入力すると、直近数時間のうちにつぶやかれた『月曜日』という文字列を含むツイートが集められて、その単語に関するさまざまなコメントが閲覧できます。
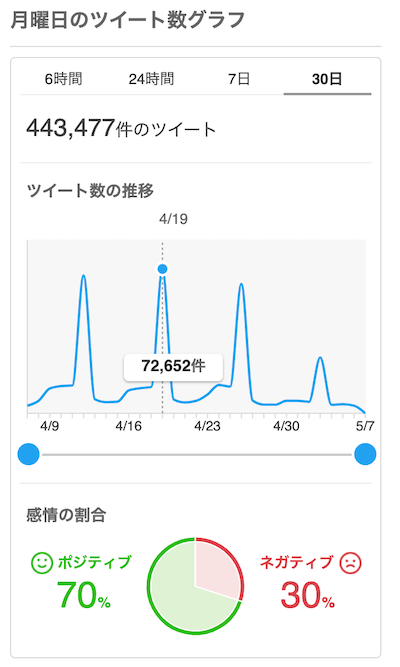
ところで、リアルタイム検索ではその部分コンテンツとして感情分析機能が提供されています。先ほどの検索結果画面をよく見ると、右端に下図のような『感情の割合』という名の円グラフが表示されているはずです。
この円グラフは、集められたツイートに対して自動推定された印象の割合を示しています。ユーザーに対して表示されているのはポジティブとネガティブの比率のみですが、内部的にはそのどちらでもないニュートラルを含めた3ラベルの多クラス分類を各ツイートに対して行っています。
この円グラフを見ることで、ユーザーは『月曜日』に関する直近のツイート傾向が大まかに把握できます。また、ツイートを集める時間幅を変えることで、『月曜日』ツイートに対する一般的な印象の通時的な推移が観察できます。
さて、かよう便利な感情分析機能ですが、リアルタイム検索のシステム刷新に伴って、内部で動いている多クラス分類モデルを新たに作り直すことが決まりました。2020年夏頃の話です。
ラベル偏りの問題
早速、言語処理のエンジニアリングチームが新モデルの作成に取り組みました。それぞれの印象が人手でラベル付けされた約5万件のツイートを学習データとして用意したので、これを用いて多クラス分類モデルを学習させました。モデルとしては推論速度とメモリ使用量の観点からシンプルな単語ベースの線形分類器を採用しました。
作成されたモデルを自動評価したところ、刷新前に使用されていた旧モデルと比べて遜色ない精度スコアを達成しており、特に問題がなければこちらのモデルをそのまま提供する予定でした。
しかし、一つ問題が発見されました。ラベル偏りの問題です。
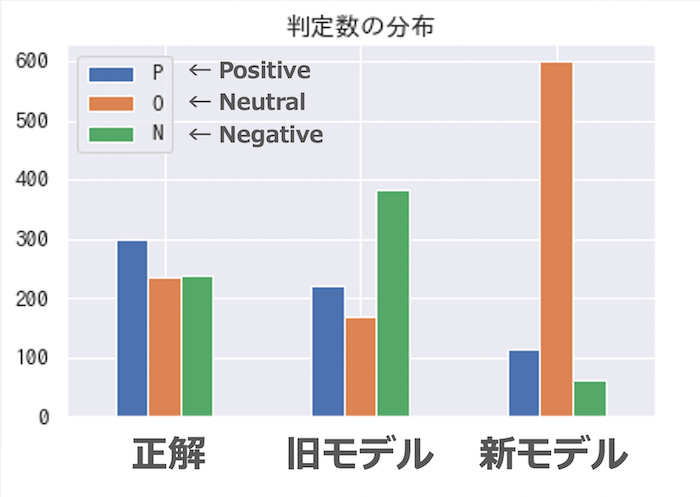
下図は各モデルの出力ラベル比率を示した棒グラフです。
一番左の棒群は人手ラベルの比率を示しており、ここではポジティブ・ニュートラル・ネガティブの比率が大体等しくなるようツイートを集めてきたことがわかります。
真ん中の棒群は、同じツイート集合に対する旧モデルの出力ラベルの比率を示しています。人手ラベルの分布と比べて少しネガティブの出力数が多すぎますが、おおむね均等な出力をしているように見えます。ただし、ここでは人手ラベルとの一致(正誤)は見ず、あくまで出力されたラベルの比率だけに着目していることに注意してください。
さて、ここで指摘されるべき問題は今回われわれが新たに作成した新モデルの出力ラベル比率です。一番右の棒群がこれを示しています。一目でわかるように、ニュートラルの出力数がずば抜けていて、ツイート全体の約75%を占めています。これではとても均等な出力とは言えません。
どうしてこのような問題が起きてしまったのかをわれわれは精査し、その原因が今回使用した学習データにあるのではないかと疑いました。以下で詳しく掘り下げます。
今回用意した約5万件のツイートに付けられた人手ラベルを改めて観察したところ、ポジティブ・ニュートラル・ネガティブの比率が大体1:5:1になることがわかりました。つまりモデルの側からしてみれば、与えられたツイートに対して無条件にニュートラルさえ出力しておけば、ツイート内容を考慮せずとも5/7(約71%)の確率で正解できてしまうのです。するとモデルは自身の正解率を上げるために、出力すべきラベルの確信が持てないツイートに対してはニュートラルを比較的多く出力するようになります。実際、改めて上の図を見直すと、新モデルの出力比率は1:5:1に近そうに見えます。この偏りは、学習データ中のラベル出現比率を過剰に学習してしまっているからだと言えます。
もう少しだけ詳しく掘り下げます。ではそもそもなぜ、今回の学習データはそのような偏りの大きいラベル比率(imbalanced data) になってしまっているのでしょうか。もちろん、Twitter中の真のラベル比率自体が偏りを抱えていることも原因の一つでしょう。しかし今回使用している学習データは真のラベル比率以上の偏りを抱えているように見受けられます。そしてその大元をたどれば、ツイートの印象を推定するというタスクそのものの難しさに原因があると言えます。
たとえば、「今日のお昼はカレーだった。大盛り無料で嬉しかった。だけど最後まで食べきれず残念……」というツイートのラベルは何がふさわしいでしょうか。一文目だけなら出来事を報告しているだけなのでニュートラル。二文目も含めて読むなら「嬉しかった」と言明しているのでポジティブ。しかし三文目まで着目すると「残念」と言明しているのでネガティブ。というように、一つのツイート中にさまざまな印象が入り乱れています。いま挙げたツイートは作例ですが、これと同様にTwitterには皮肉や自虐など判定の難しいツイートが多く含まれています。また絵文字や感嘆符など、その包含によってツイートの印象が大きく変わる文字も多く出現します。
この難しさは人手で正解ラベルを付ける場面にも直接影響します。今回は学習データとして約5万件のツイートを用いていましたが、これはもともと約25万件のツイートそれぞれに3人の人間によって正解ラベルが付けられたのち、3人とも同じラベルを選んだツイートのみを集めたものです。つまり残りの約20万ツイートについては、3人の付けたラベルが完全一致しなかったということです。
その結果、集められた約5万件のツイートについては、『複数人の人手ラベルが一致しやすいデータ』というサンプル選択の偏り(sample selection bias) が掛かっています。その偏りが、このデータを用いて学習させたモデルの予測結果において、出力ラベルの極端な比率として現れたのだと考えられます。
足りないなら増やせばいい!BERTを用いたデータ蒸留
では、この問題をどのように解決すればいいでしょうか。シンプルな手法としてはオーバーサンプリングが考えられます。これは比較的量が少ないラベル(今回の例で言えばポジティブとネガティブ)のデータを改めて収集・追加することで、学習データ中のラベル比率を調整する手法です。
しかし、ここでデータを追加するということはすなわち、新たに集めたツイートに対して追加で人手ラベルを付与する必要があるということです。数千件のラベル付けですらそこそこ大変ですが、数万件のラベル付けとなればその人手コストは無視できないくらい甚大なものになります。
そこでわれわれは、BERT(Bidirectional Encoder Representations from Transformers)を使用することで、このラベル付け作業を自動化しました。
BERTとはGoogleが開発した高性能な汎用言語処理モデルです。公開された論文では、さまざまな言語処理タスクにおける当時の最高精度を達成し、感情分析タスクにおいても以前の手法より高精度な推定が実現できたと報告されています。
われわれがBERTを用いた手順は以下のようになります。
まず、手元にある約5万件のデータを用いてBERTを学習させます。次に、新たに収集したツイート約200万件に対してBERTによる推論を行い、ここで付与されたラベルを擬似的な正解ラベルと見なします。それから、BERTによって付けられたラベルがポジティブ・ネガティブであるツイートをそれぞれ数千〜数万件ずつ集めて、もともとの約5万件の学習データに追加します。最後に、この新たな学習データを用いてわれわれのモデルを学習させます。
この一連の手順(この手法はデータ蒸留とも呼ばれています)を踏むことで、われわれの新モデルはもともとの学習データに含まれていたラベル偏りの影響を大幅に軽減できました。
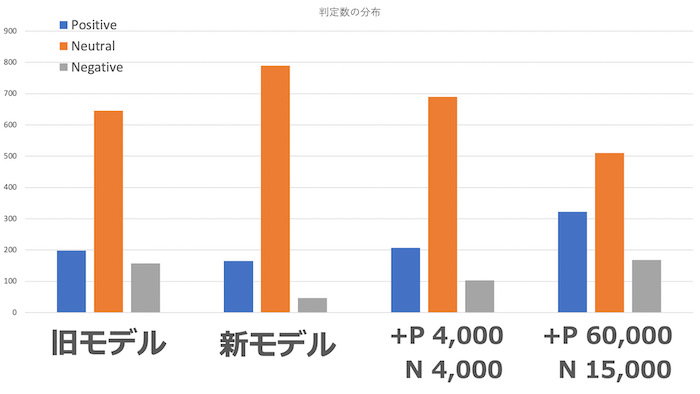
実際にどれほど改善されたかを下図に示しました。
一番左の棒群は、ランダムにサンプリングした1,000ツイートに対する旧モデルの出力ラベルの比率を示しています。左から二番目の棒群は、同じツイート集合に対する何も手を加えていない新モデルの出力ラベルの比率を示しています。右から二番目の棒群は新モデルの学習データにポジティブと判定されたツイートを4,000件、ネガティブと判定されたツイートを4,000件追加した時の出力ラベルの比率を示しています。一番右の棒群は新モデルの学習データにポジティブと判定されたツイートを60,000件、ネガティブと判定されたツイートを15,000件追加した時の出力ラベルの比率を示しています。学習データにおけるポジティブ・ネガティブツイートの量を増やせば増やすほど、よりニュートラルの出力が減り、代わりにポジティブ・ネガティブの出力が増えていることがわかります。
評価はどうする?自動評価の限界
では実際のところ、どれくらいの擬似ラベル付きデータを追加すればいいのでしょうか。一つの案として、学習データの一部をあらかじめテストデータとして確保しておき、このデータに対する自動評価スコアが最大になるような追加量を求めることが考えられます。しかし、おそらくこの部分データ自体もラベル偏りを含んでいるため、必ずしも正確な評価ができるとは限りません。
理想を言えば、Twitter中の真のラベル比率をどうにか観測し、これとぴったり一致するように訓練データの比率を調整したいところです。しかし、そもそもツイートに対して付けられる人手ラベル自体がほとんど一致しないのですから、真のラベル比率はどうあがいても正確に観測できるものではないでしょう。
そこでわれわれは人目での評価に基づいてこのデータ追加量を決めることにしました。具体的には1,000〜5,000件刻みでデータ量を変化させたモデルを約60種類用意し、このうち最も人間の感覚と近い出力ができていそうなモデルを選出しました。
各モデル出力に対する人目での評価は大変泥臭い作業でしたが、この作業のおかげで、自動評価では捉えられないラベル偏りの問題が十分に補正されました。
最終的には、以前こちらの記事で紹介した共通化インターフェース「Azuki」を利用することで開発・運用コストを抑えつつ、無事上記のモデルが提供できました。
おわりに
今回は感情分析タスクにおけるBERTを用いたラベル偏り改善の取り組みを紹介しました。最終的なユーザー体験を向上させるために行われた地道な取り組みの過程を詳細に示せたのではないかと思います。今後も目先の数値だけにとらわれず、ユーザーの皆さんにとってベストな選択肢が選べるよう心がけていきたいです。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました
- 山城 颯太
- 言語処理エンジニア



