こんにちは! Yahoo!ショッピングクーポンチームの小倉です。
前回のフロントエンド技術刷新の話とは打って変わり、今回は2019年に行ったバックエンド技術刷新の話です。
刷新前のシステムはノンフレームワークPHPのモノリスでしたが、現在は主にJava/Spring Bootでマイクロサービス化しています。今回は、その中でもっとも仕様が複雑だったマイクロサービスにおいて、ドメイン駆動設計(Domain Driven Design:DDD)を実践した話をご紹介します。
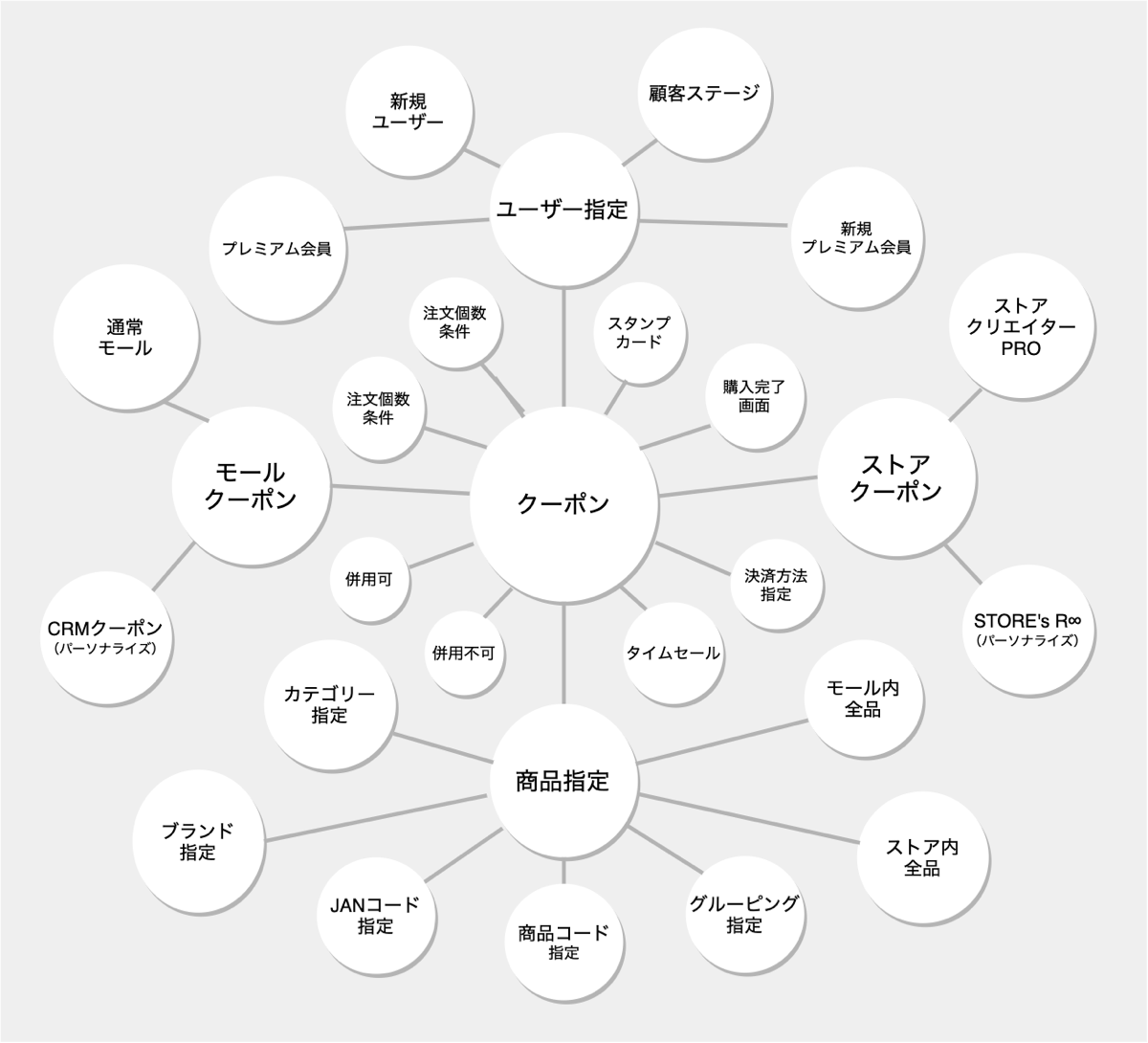
ショッピングクーポンの自由度を知る
みなさんは、ショッピングの商品が割引になるクーポンをご存じでしょうか? 実は、クーポンには、ヤフーが予算をだして発行する「モールクーポン」と、ストアが予算をだして発行する「ストアクーポン」が存在します。そこから、ユーザー属性・顧客ステージによる指定、カテゴリー・ブランドなどによる商品の指定、注文金額・個数による条件など、さまざまな要素を掛け合わせられます。
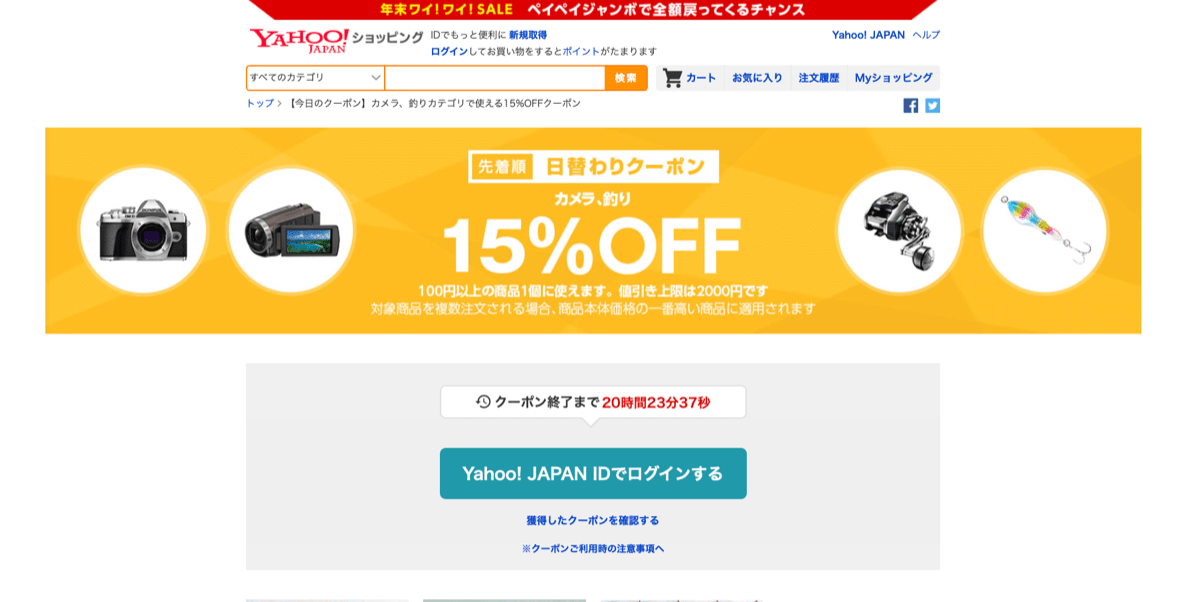
例えば、以下の「日替わりクーポン」は、特定の商品カテゴリーを対象としたモールクーポンとなります。
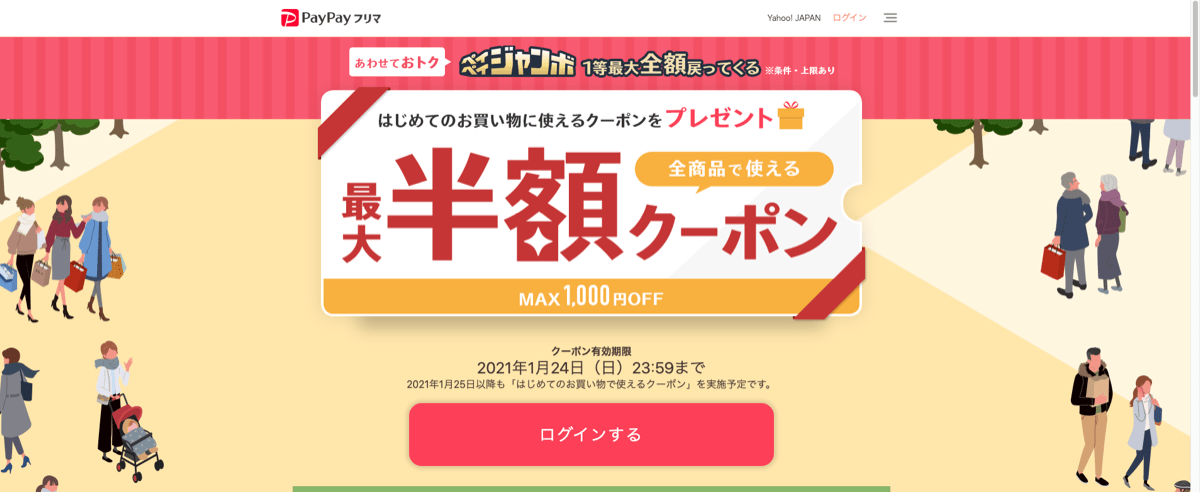
また、こちらの「くらしの応援クーポン」は、ファッション・グルメ・インテリアなど幅広い商品で使えるYahoo!プレミアム会員限定のクーポンです。
こうした自由度の高さによって、ユーザーのさまざまな購入体験とストアの多様な購買施策を実現できますが、一方でシステムには「複雑さ」をもたらします。以降では、技術刷新においてこの「複雑さ」をどのように解決したのかを紹介していきます。
複雑さに立ち向かうためDDDを導入する
今回は、以下の2つの参照APIをJava/Spring Bootで刷新しました。
- ユーザーやカゴ内の商品を加味して適用できるクーポンの「利用候補」を返却する
- クーポンをカゴに適用したときの「割引明細」を計算する(クーポンの複数組み合わせや、割引額の商品ごとの案分なども考慮する)
なお、ここでは先ほど紹介したようなすべての条件を満たしているという整合性が要求されるため、機能要件が複雑になることが目に見えていました。そこで、ドメイン駆動設計(Domain-Driven Design: DDD)を取り入れることによって、複雑さに立ち向かうという選択をしました。
また、DDDの学習にあたっては、増田享さんの現場で役立つシステム設計の原則(以下、増田本)を読んで実践することにしました。エリック・エヴァンスのドメイン駆動設計(以下、エヴァンス本)や実践ドメイン駆動設計(以下、IDDD本)などはボリューミーな書籍が多い一方、こちらはより平易で手に取りやすいボリュームであり、すぐに実践しやすい構成となっています。
次に、実際の現場でどのようにDDDを進めていったかを紹介します。
1.システムの関心事(=モデル)を分析する
ドメイン駆動設計では、デザインパターン的な部分が取り上げられがちですが、まずは業務領域(ドメイン)の分析から始まります。
当時の開発体制としては、カート画面での利用が主になるため、カートチームと並行して開発していました。クーポンチームとしては、私が開発担当・上長がプロジェクトマネージャーという役割分担でした。当初、新卒二年目だった私は当然、クーポンの業務知識を網羅しているわけではありませんでした。
そこで、上長とホワイトボードの前で対話しながら業務知識を深め、どういった「登場人物=関心事=モデル」が必要かを探っていきました。エヴァンス本の文脈でいうと、上長自身がドメインエキスパートになっていたということになります。そして、以下のような分析モデル図ができあがりました。
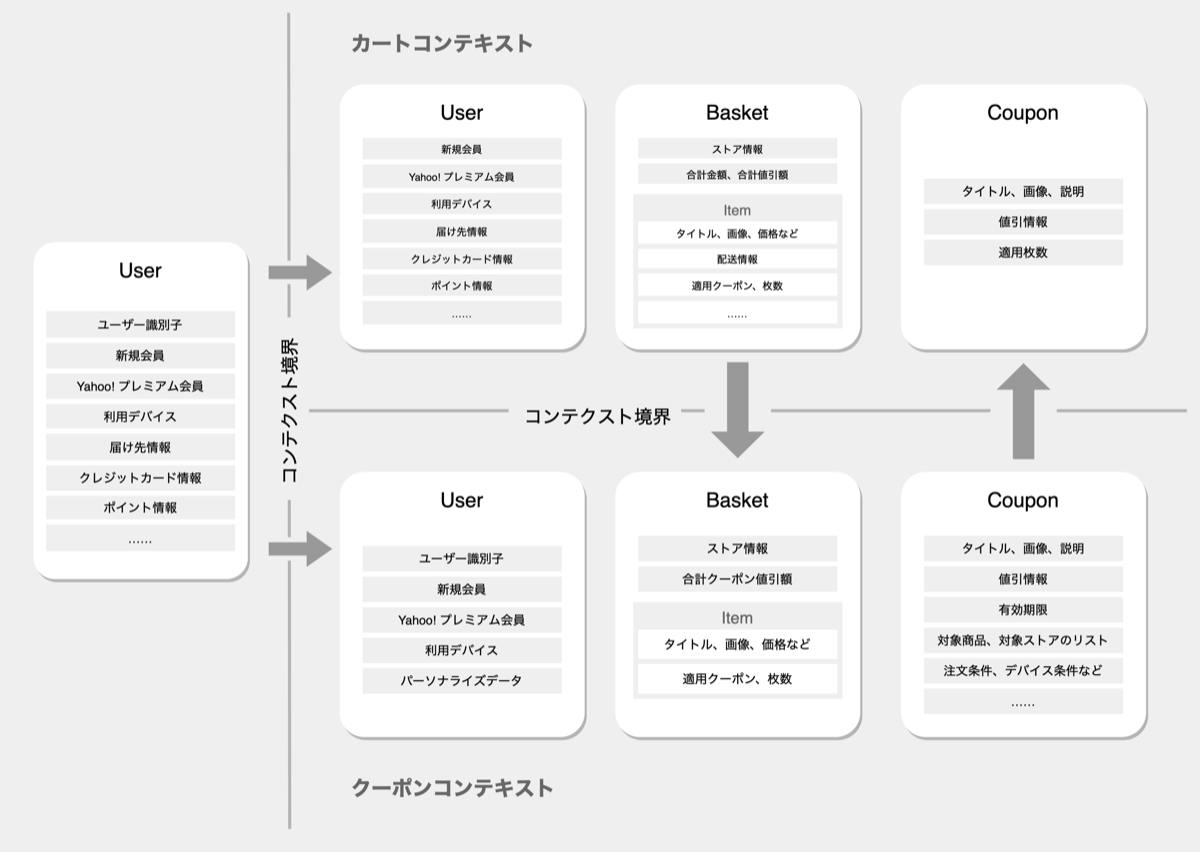
次第に、クーポンチームとしては「カゴ(Basket)」という概念にあまり触れてこなかったことに気付きます。エヴァンス本の文脈で言うと、ここがまさにカートとクーポンにおけるコンテキスト境界だったからです。そこで、カゴという概念について資料調査をしたり、カートチームをドメインエキスパートとして定例で質問するなどして、理解を深めました。これによって、クーポンの文脈として知っているべきカゴの姿というものが見えるようになりました。カゴは単なる商品の集合なのではなく、商品ライン(Line)という概念の集合であることがわかりました。
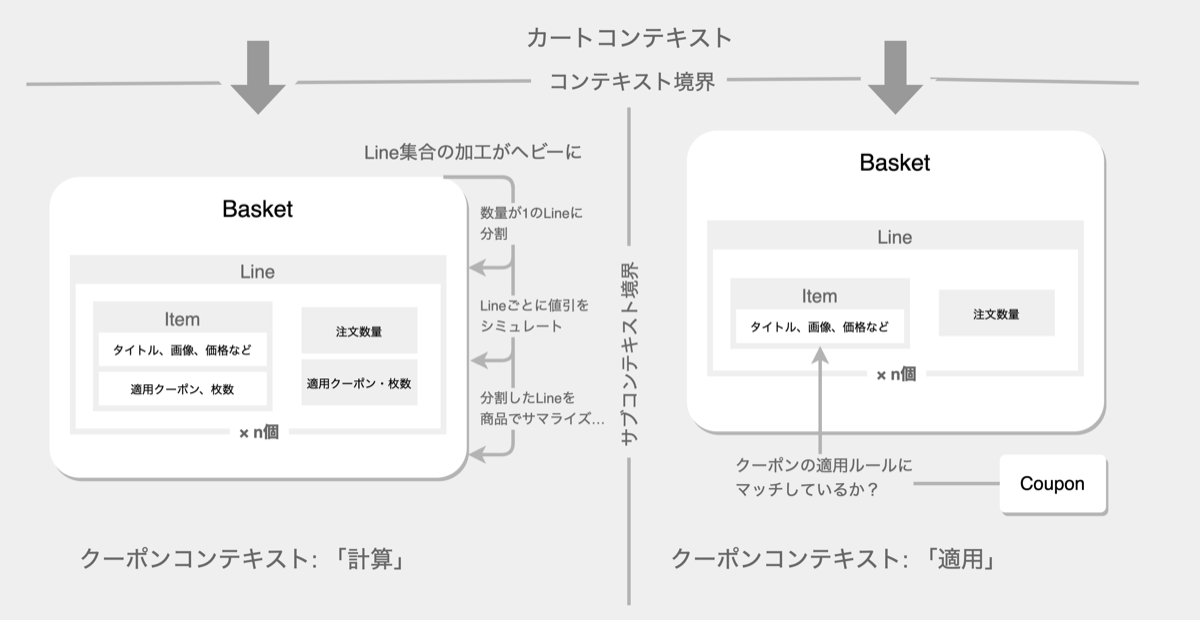
また、「適用候補の探索」と「値引きの計算」というそれぞれのユースケースで、カゴや商品ラインの重要な側面が異なることに気づきました。「計算」の文脈では、商品ラインの分割や値引き額の案分といった「商品ラインの加工」がヘビーになりますが、「適用」の文脈ではそれほど重要でなかったのです。そのため、文脈の違いによってリポジトリを分割し、それぞれでモデリングするといった選択をしました。
こうして現れた分析モデルを、ドメインモデルとして実装に落とし込んでいきます。また、「Basket」「Line」「Coupon」といった名前をドメインモデルのクラス名に採用することで、業務知識とソースコードを結びつけ、ソースコードが業務知識の仕様書になることを目指します(これをエヴァンス本の文脈でユビキタス言語と呼びます)。開発サイドとビジネスサイドでもこのユビキタス言語が共有されていることが理想ですが、まずは開発サイドの中でコンセンサスをとることが重要です。
2.レイヤードアーキテクチャによる関心の分離でドメインロジックを疎結合にする
さて、ドメインモデルの実装前に抑えるべきことがあります。
DDDにおいて重要になるのは「関心の分離」であり、特に「業務ロジックを隔離すること」です。DDD実践前における開発のパッケージ・クラス構成は以下のようになっていました。
- Spring Bootのレールに乗っかっていたため、もともと「Controller」「Service」「Repository」といったクラスは存在していた
- しかし、レイヤードアーキテクチャやオニオンアーキテクチャといった構成はとっていない
- そのため、フラットなJavaパッケージ空間上にそれらが存在していた(
controllerパッケージとserviceパッケージが同階層など)
DDD実践後は以下のようなパッケージ・クラス構成に変更しました。
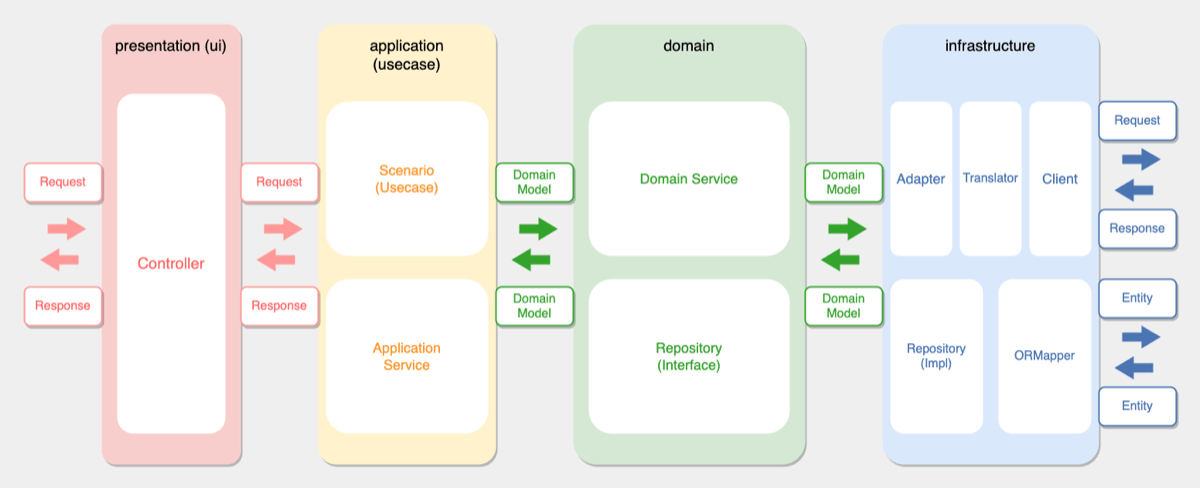
| レイヤー名 | 責務 | そこに置かれるクラス例 |
|---|---|---|
| presentation(ui) | 表示における関心事を扱う。ルーティングやHTTPリクエストレスポンスやそのバリデーション、あるいはUIなど。 | Controller、Request(Form)、Response(Resource)など |
| application(usecase) | ドメインオブジェクトを利用してソフトウェアが行うべき仕事を表現する。 | Scenario(Usecase)、アプリケーションサービスなど |
| domain | 業務ロジックや業務ルールを表現する。 | ドメインモデル、ドメインサービス、Repositoryインターフェース、ドメインモデルのFactoryクラスなど |
| infrastructure | データの永続化処理や外部サービスとのやりとり(REST API/MQ)を行う。 | Repository、ORMapper、Adapter、Translatorなど |
以下に、それぞれのレイヤー間における依存関係の方向を矢印で示しています。ここで大事なのは、domain層=業務ロジックは他のどの層にも依存していないということです。例えば、application(usecase)層→domain層の依存関係は、Scenarioクラスがdomain層のドメインロジックを呼び出すといった関係から明白です。
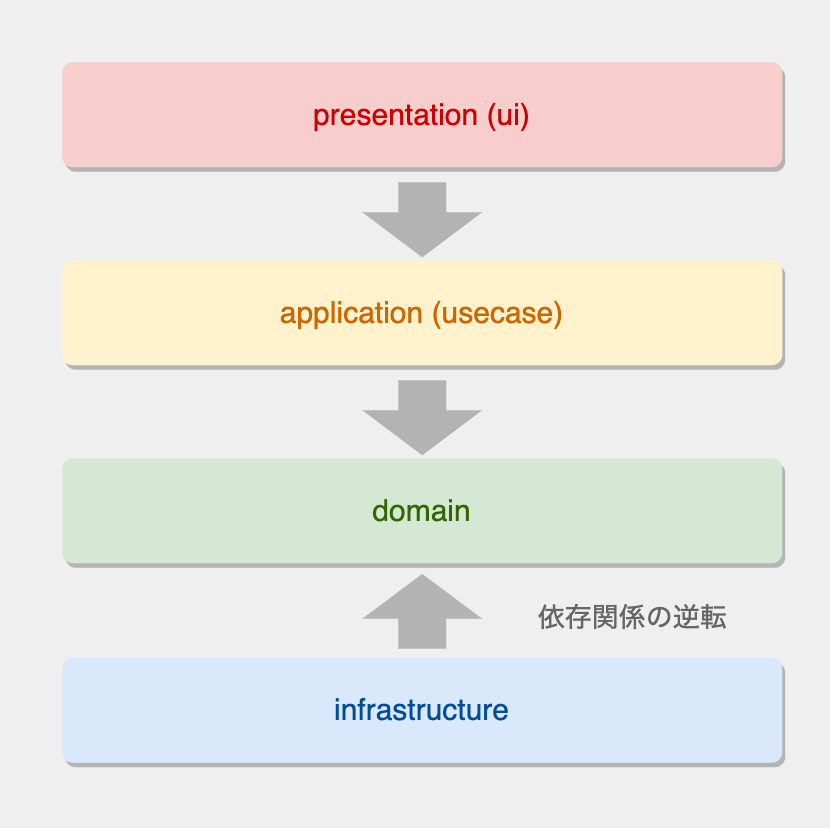
一方、domain層←infrastructure層の関係はどうでしょうか。
むしろ、infrastructure層における永続化・通信技術などは業務ロジックを実現するために存在するので、domain層が利用する関係のように思えます。しかし、実際の業務では、それらの技術選択はパフォーマンスやスケーラビリティなどの観点から変更される余地があります。そのため、infrastructure層の実装の詳細にdomain層が依存していると、その技術選択の変更によってdomain層も変更の影響を受けてしまいます。
そこで、「domain層にRepositoryのインターフェースを切り、infrastructure層はそれを実装する」とすれば、domain層はinfrastructure層の実装に依存しなくなります。むしろ、infrastructure層がdomain層の抽象(インターフェース)に依存するようになります(これを依存関係の逆転と呼びます)。
また、infrastructure層ではORMから生成されるEntityが、また、presentation層ではRequestモデルが存在していますが、これらをdomain層まで引きずってしまってはいけません。そこで、それぞれの層(あるいはapplication層)でドメインモデルに変換してあげることが重要です(これを腐敗防止層と呼びます)。
こうすることで、業務ロジックが表示や技術選択といった関心事に依存しない、強固なアプリケーションを作ることができます。ドメインモデルを育てるための土壌が出来上がることになります。
3.ドメインモデルを部品として成熟させることで高凝集性を獲得する
いよいよ、前節で登場した分析モデルたちをドメインモデルとして実装します。DDDを実践するにあたってのメインステップは、「ドメインモデルを作り部品として成熟させること」にあります。そこで実践したことの中で、特に重要だと感じたものを紹介していきます。
ドメインモデルにロジックを寄せることでデータとロジックを一体化させる
増田本の中ではドメインモデルのあるべき姿について、以下のように主張されています。
- データとロジックを一体にするべき(業務ロジックと扱うデータは同じクラスにあるほうがよい)
- ドメインモデルを部品として成熟させるべき(ドメインモデルに業務ロジックが凝集されるべき)
再び、DDD実践前はどうなっていたかを振り返ってみます。
- ドメインエンティティ的なものは存在していたが、あくまでロジックがないデータの入れ物(DTO)だった
- サービスクラスは存在していたが、業務ロジックはそこに凝集し、肥大化していた
そこで、今までの開発とのギャップを埋めるため、以下のような流れで実装していきました。
- 分析モデルと対応するドメインモデルクラスをつくる(業務知識とソースコードを結びつける)
- そのモデルのデータを使って、ユースケースを満たすために必要なロジックを実装する(データとロジックがモデルの中で共存する)
- 実装したロジックをできるだけ小さく分解する(部品が再利用性を獲得する)
- 実装できなかったドメインロジックはドメインサービスへ実装することで妥協する
- 再びコードを眺めてみて、ドメインモデルに寄せられるロジックを探して移してみる
- 3.~5.を繰り返す
このとき、実装はできるだけdomain層自身のことだけを考えて進めました。つまり、infrastrcture層の技術選択やpresentation層のIF仕様といった関心から離れるのです。これはすなわち、レイヤードアーキテクチャによる関心の分離をおこなうメリットでもあります。
ちなみに、業務ロジックをドメインモデルへ移して行ったとき、ドメインサービスには何が残るべきなのかという疑問に陥ることがありました。これについては、little_handsさんの記事DDD基礎解説:Entity、ValueObjectってなんなんだが参考になりました。一言で表すと、「そのドメインモデル自身に関する情報だがそのドメインモデル自身は知り得ないこと」になります。
こういった作業を繰り返していくと、次第に以下のようなメリットが実感できました。
- 単体テストが実装しやすくなった
- メソッドあたりの責務が小さくなるため、テストすべき関心の対象も小さくなる
- ロジックの凝集性があがった
- データとロジックが一体になる
- 実装者は「今作ろうとしている部品はどのモデルに実装するべきか」ということを考えるようになる
- 実装スピードが上がった
- 小さな部品を作るという意識は、エンジニアの実装タスクを分解する作業
- 人間はタスクが分解されると作業の見通しが良くなる
副作用のない関数にすることで「状態」という悩みを払拭する
ドメインモデルのメソッドを「部品」として捉えると、副作用を持つ関数は「扱いやすい部品」とは言えません。なぜなら、その部品を用いるとき、それによってあるオブジェクトに起こる状態の変化に注意する必要があるからです。そこで、ドメインモデルのメソッドからは副作用を取り除くことを徹底しました。
例えば、コレクションドメインモデルCouponsに要素Couponを追加することを考えます。旧来は、Couponsモデルの中からListオブジェクトの参照をgetterで取得してList#addで追加するといった実装がほとんどでした。しかし今では、増田本の中で推奨されている「副作用を取り除いた実装」を厳守しています。
import lombok.Builder;
@Builder
public class Coupons {
List<Coupon> couponList;
/**
* 変更不可なコレクションを返す
* @return List<Line>
*/
public List<Coupon> asList() {
if(couponList == null) {
return Collections.emptyList();
}
// addやremoveが利用できなくなる
return Collections.unmodifiableList(couponList);
}
/**
* クーポンの追加(副作用なし)
* @param coupon
* @return Coupons
*/
public Coupons addCoupon(Coupon coupon)) {
// Listオブジェクトを新たに生成し直す
List<Coupon> couponList = new ArrayList<>(this.couponList);
couponList.add(coupon);
// Couponsモデルも新たに生成し直す
return Coupons.builder().couponList(couponList).build();
}
}上の実装例では、以下の3つを守るように気をつけています。
- コレクションを操作するメソッドをコレクションドメインモデル
Couponsに実装する couponListの参照をそのまま外部に提供するのではなく変更不可なリストにして返すListオブジェクトやそれをラッピングするドメインモデルCouponsは新たにオブジェクトを生成し直す
これによって、状態が異なるオブジェクトは常に別のオブジェクトになり、それぞれのインスタンスが不変性を獲得します。また、外部にListオブジェクトそのものを渡したい場合も、変更不可なリストとして提供されるため、不変性を損いません。
また、コレクションオブジェクトに限らず、「あるオブジェクトの一部の状態を変更したい」といったケースはしばしばあります。例として、CouponモデルのメンバーフィールドuseCountを変更することを考えます。旧来では、CouponモデルのsetterCoupon#setUseCountによって状態を直接変更していましたが、今では以下のように実装しています。
import lombok.Builder;
// toBuilderを使えるようにする
@Builder(toBuilder = true)
public class Coupon {
CouponId couponId;
String title;
String description;
...
Integer useCount;
...
public Coupon updateUseCount(int useCount) {
// toBuilderによってオブジェクトからBuilderを生成する
return this.toBuilder()
.useCount(useCount)
.build();
}
}LombokのtoBuilderを用いることで現在のオブジェクトからBuilderを生成し、一部のプロパティuseCountだけを再指定するやり方です。これによって、useCountだけが異なるオブジェクトが再生成されます。つまり、@Setterを廃止してtoBuilderを用いることでドメインモデルの不変性を獲得できるのです。
閉じた操作にすることで部品を組み立てやすくする
ドメインモデルを成熟させるために「閉じた操作」というデザインパターンが存在します。これは、あるドメインモデルのメソッドの戻り値がそのドメインモデル自身になることを指します。
実は、ここまでのサンプルコードで登場したCoupon#updateUseCountやCoupons#addCouponもその一例です。いったん「閉じた操作」パターンを用いれば、以下のように複雑なドメインロジックも、メソッドチェーンによって流れるように実装できます。
public class Lines {
......
public Lines simulate(Coupons storeAllCoupons, Coupons targetItemCoupons, Coupons postageCoupons) {
List<Line> lineList = this.asList()
// 各商品ラインを数量1の商品ラインに分割する
.splitToSingleQuantityLines()
// 計算の前処理として商品単価でソートする
.sortByItemPrice()
// ストア全品クーポンの適用をシミュレートする
.tryToApplyStoreAllCoupons(storeAllCoupons)
// 商品指定クーポンの適用をシミュレートする
.tryToApplyTargetItemCoupons(targetItemCoupons)
// 分割したラインをまとめる
.summarize()
// クーポン適用されたラインを優先的にソートする
.sortByCouponApplyState()
// 送料値引きクーポンの適用をシミュレートする
.tryToApplyPostageCoupon(basket, postageCoupons);
return Lines.builder().lineList(lineList).build();
}
}このユースケースは「商品ラインにクーポンの組み合わせを適用させ計算を行う」という内容ですが、その操作対象が常にLinesに向いているためまさに適切です。何より、コードが仕様書のように流暢(りゅうちょう)に読めると言った利点があります。
4.リファクタリングの繰り返しから事業価値となりうるコアドメインを見いだす
ここまでは、DDDにおいてドメインモデルを育てるための鉄則といえます。冒頭で登場したエヴァンス本やIDDD本では、この他にもAdapter,Translator,Aggregateなど、数々のデザインパターンが紹介されていますが、ボリュームの多い本ですし、そのすべてを適切に理解して適切に用いることは難しいです。
そのため、まずは最低限レイヤードアーキテクチャとドメインモデルによる「関心の分離」を徹底することが先決です。そして、リファクタリングのフェーズにおいて、実装がうまくいかず複雑になった部分やビジネス要求が高いと思われる部分(これをエヴァンス本ではコアドメインと呼びます)を見いだし、適切なデザインパターンを学んで実践すると言うのが現実的です。
今回の開発は、技術刷新のためウォーターフォールによる開発でしたが、その中でリファクタリングの期間を設けていました。実際におこなったリファクタリングの内容を紹介していきます。
シナリオクラスによってユースケースの流れを整理する
Yahoo!ショッピングのシステムは、商品、検索、クーポン……といったように、開発組織とともにマイクロサービス化されています。
したがって、必要な情報は対応するマイクロサービスからかき集めなければなりません。今回はREST APIによってマイクロサービスと連携しますが、平均レスポンスタイムとしては少なくとも30ms前後かかります。
これに対して、非機能要件は平均レスポンスタイム50ms以下でした。そのため、同期的な処理を排除した非同期プログラミングが当然に要求されます。
さらには、フロー制御なども必要になるとシーケンスがより複雑化していき、可読性も落ちてしまい、パフォーマンス改善の方針もわかりづらくなっていきました。
そこで、増田本にも登場する「Scenarioクラス」を実装することで、ユースケースの流れ(シーケンス)を整理しました。
Scenarioクラスは以下の責務だけを持たせ、(application層に置くため当然ですが)ドメインロジックは持たせないようにします。
- 複数ドメインサービスやモデルファクトリーの呼び出し処理
- 非同期処理によるフロー制御
実際に、「ユーザーやカゴの情報をもとに、適用可能なクーポンを取得する」というユースケースを見ていきます。
public class CandidateScenario {
......
public Coupons candidate(User user, Basket basket) {
// 1. ドメインサービスの呼び出し
CompletableFuture<Coupons> futureCoupons = couponService.fetch(user, basket); // 現在有効なクーポンを取得
CompletableFuture<Basket> futureBasket = basketService.complete(basket); // Basketモデルに商品・ストア情報を補完
CompletableFuture<User> futureUser = userService.complete(user); // Userモデルにユーザー情報を補完
// 2. 三者のドメインモデルがそろうまで待機
CompletableFuture.allOf(futureCoupons, futureUser, futureBasket).join();
// 3. ドメインモデルを取得
Coupons coupons = futureCoupons.join();
Basket completedBasket = futureBasket.join();
User completedUser = futureUser.join();
// 4. パーソナライズ判定による判定を行う(マイクロサービスへ)
Judgements judgements = judgementService.judge(coupons, completedBasket, completedUser);
// 5. 「適用可能なクーポン一覧」という集約を生成する
CandidatesAggregate aggregate = CandidatesAggregateFactroy.create(coupons, completedBasket, completedUser, judgements);
return aggregate;
}
}CouponUserBasketのドメインモデルを提供するドメインサービスを並列タスクとして実行する- 三者のドメインモデルがそろうまで、メインスレッドを
CompletableFuture#allOfによって待機させる CompletableFutureからドメインモデルの実体を取得する- 三者のドメインモデルがそろって初めて行える「マイクロサービスを利用したパーソナライズ判定」を行う
- これまでの結果を用いて、「適用可能なクーポン一覧」という集約(エヴァンス本文脈のAggregateパターン)を生成する
このような実装によって、以下のメリットを感じることができました。
- Controllerクラスがビジネスロジックの呼び出し処理でファットになることを防げる
- ビジネスロジックの順序性が明確化され、実装の見通しが良くなる
- (例)新しいビジネスロジックをどこに挿入すればよいか
- (例)パフォーマンス由来でビジネスロジックの順序変更をしたい
Enumの多態性によってロジックの分岐を整理する
もうひとつの複雑さの要因は、商品・ユーザーの指定方法に基づく「分岐」でした。その種類は、ビジネス要求によって今もなお着々と数を増やし、この技術刷新の最中においても、ターゲティング方法を追加したいといった要望がありました。裏を返すと、ここにもっともビジネス的な価値があり、もっとも保守性が求められているといえます。こういった点を理解せず、愚直に実装していた当時に陥ってしまったのが、複雑怪奇な「if文の迷宮」です。
そこで、JavaのEnumがもつ多態性(ポリモフィズム)を利用して、「分岐」を表現するといったリファクタリングを行いました。例として、商品指定方法のEnumであるItemTargetStrategyをみてみましょう。
// 1. 商品ターゲティング種別を表すEnumを定義する
public enum ItemTargetStrategy {
// 2. ストア内全品対象
STORE_ALL {
@Override
public List<Line> getTargetLineList(Coupon coupon, Basket basket) {
return basket.asLineList();
}
},
// 3. 商品コード指定
ITEM_CODE {
@Override
public List<Line> getTargetLineList(Coupon coupon, Basket basket) {
// 商品コードリストに含まれているものを抽出
return basket.asLineList()
.stream()
.filter(line -> coupon.getTargetItemCodeList()
.contains(line.getItem().getItemCode()))
.collect(Collectors.toList());
}
},
// 4. ブランド指定
BRAND {
@Override
public List<Line> getTargetLineList(Coupon coupon, Basket basket) {
// 対象ブランドリストに含まれているものを抽出
return basket.asLineList()
.stream()
.filter(line -> coupon.getTargetBrandIdList()
.contains(line.getItem().getBrandId().getValue()))
.collect(Collectors.toList());
}
},
......
// 5. 「適用対象となる商品一覧を取得する」という処理の抽象メソッドを定義
public abstract List<Line> getTargetLineList(Coupon coupon, Basket basket);
......
}ここで、ItemTargetStrategy#getTargetLineListは「引数のクーポンCouponについて、適用対象となる商品ラインリストList<Line>を取得する」というメソッドです。
- 対象商品の種別を表すEnumを定義する。各列挙子では、5.で定義した抽象メソッドをオーバーライドすることで「分岐」を表現する。
- ストア内全品指定では、文字通りにストア内のすべての商品がクーポン適用対象となるため、「カゴ内の商品をすべて対象商品として返す」という振る舞いでオーバーライドする。
- 商品コード指定では、ストアやヤフーがピンポイントで商品の一意な識別子を指定するため、「一意な識別子が合致するものだけを返す」という振る舞いでオーバーライドする。
- ブランド指定では、「アディダス」「NIKE」といったブランド単位で商品を指定するため、商品のブランド識別子が一致するものだけを返すという振る舞いでオーバーライドする。
- 2.〜4.でオーバーライドしたメソッドの抽象メソッドを定義しておく。
今回は簡単な列挙子だけを取り上げていますが、カテゴリー指定の場合、カテゴリーが木構造になっていたりします。こうしたポリモフィズムの活用によって、以下のようなメリットが得られました。
- ネストされたif/switch分岐の排除による可読性の向上
- 分岐一つ一つのロジックに対するテストコードの書きやすさ
- 分岐の追加・修正・削除に対する変更容易性の向上
結果:DDDによってビジネス要求への追従スピードは爆速になった
最後に、DDDによる開発で本当に保守性はあがったのかということに言及します。技術刷新後のビジネス案件では、前節での狙い通り「ターゲティングの種別を増やしたい」といった要望が多かったです。
- ZOZOTOWN限定クーポンにあわせてセレクトショップ単位などストア任意のグルーピングで商品指定をできるようにした
- 暮らしの応援クーポンにあわせて新規ユーザー指定をできるようにした
実は、刷新前のシステムではそのロジックの複雑さも相まって、適用のルールに関してはほとんど誰も手がつけられませんでした。一方の刷新後では、DDDによってソースコードと業務知識が一体化したことで、チームの誰もがコア部分への改修に取り組めるようになりました。定量的には、こうした開発要望に対して、受け入れテストなど含めて約1カ月程度で行えるようになり、目立った事故もなくリリースできています。これも、リファクタリングの中でコアドメインを見いだし、より良い形で業務ロジックを表現するという取り組みのおかげだと感じています。
最後に
いかがでしたか? DDDによる開発の知見が、ショッピングクーポンの開発基盤を支えていることが伝われば幸いです。
最後に、Yahoo!ショッピングでは、今後もDDDによる開発で皆様にお得なユーザー体験を向上していきますので、ぜひご活用ください!
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました

- 小倉 陸
- Yahoo!ショッピングエンジニア
- Yahoo!ショッピングでクーポンの開発をしています。フロントエンド・サーバーサイド・機械学習のモデル実装まで携わっています。
-



