こんにちは、ヤフーの音声認識エンジン「YJVOICE」の研究開発を担当している藤田です。
今回は、前回のブログに続いて、ヤフーにおける音声認識技術の研究開発の最新の取り組みを紹介します。今回のブログもEnd-to-End(E2E)音声認識に関する話題です。E2E音声認識の説明は前回のブログに譲って、早速、今回の取り組みについて説明します。
なお、この研究は難関国際会議INTERSPEECH 2020に投稿し、採択されました。論文はこちらで公開されています。
従来のE2Eモデルとの違い
早速、今回の研究と従来法との違いについて説明していきます。
従来の音声認識処理においては、「音声は左から右に(left-to-right, L2R)生成されるので、左から右に認識処理をするのが良いだろう」という仮定がありました。今回の研究では、この仮定に縛られない音声認識処理を実現します。
L2Rって何? となると思いますが、例えば、「明日の天気は?」という文章が与えられたら、当然、左から右に読みますよね。これがL2Rな生成です。参考までにL2Rじゃない例(non-L2R)は、翻訳された文章です。「明日の天気は?」は英語だと「What is the weather like tomorrow?」になるので、「天気(weather)」と「明日(tomorrow)」の順番が入れ替わりますね。これはnon-L2Rです。
音声認識処理ではL2Rな生成を仮定して、「明→日→の→天→気」という順番で認識処理をするのが妥当と考えられていました。しかし、われわれ人間が人の声を聞くときは、必ずしもそうではないと思います。発音が不明瞭な単語は後回しにして、文章の最後まで聞いてからその単語が何だったか推測することもあると思います。今回の研究は、L2Rではない(non-L2R)音声認識処理ってアリなの? という疑問に答えます。
Non-L2Rな音声認識ってどうやるの?
続いて、non-L2Rな音声認識処理をどう実現するか、説明します。
L2Rな生成を仮定したE2Eモデルは自己回帰(autoregressive, AR)モデルとも呼ばれます。Non-L2Rな仮定とするためには、非自己回帰(Non-autoregressive, NAR)モデルと呼ばれるものを用います。その中でも、近年、機械翻訳の分野で流行しているNon-autoregressive Transformer(NAT)と呼ばれる、Transformerを用いたNARモデルを利用します。
どういう違いがあるか、概念図を書いてみました。
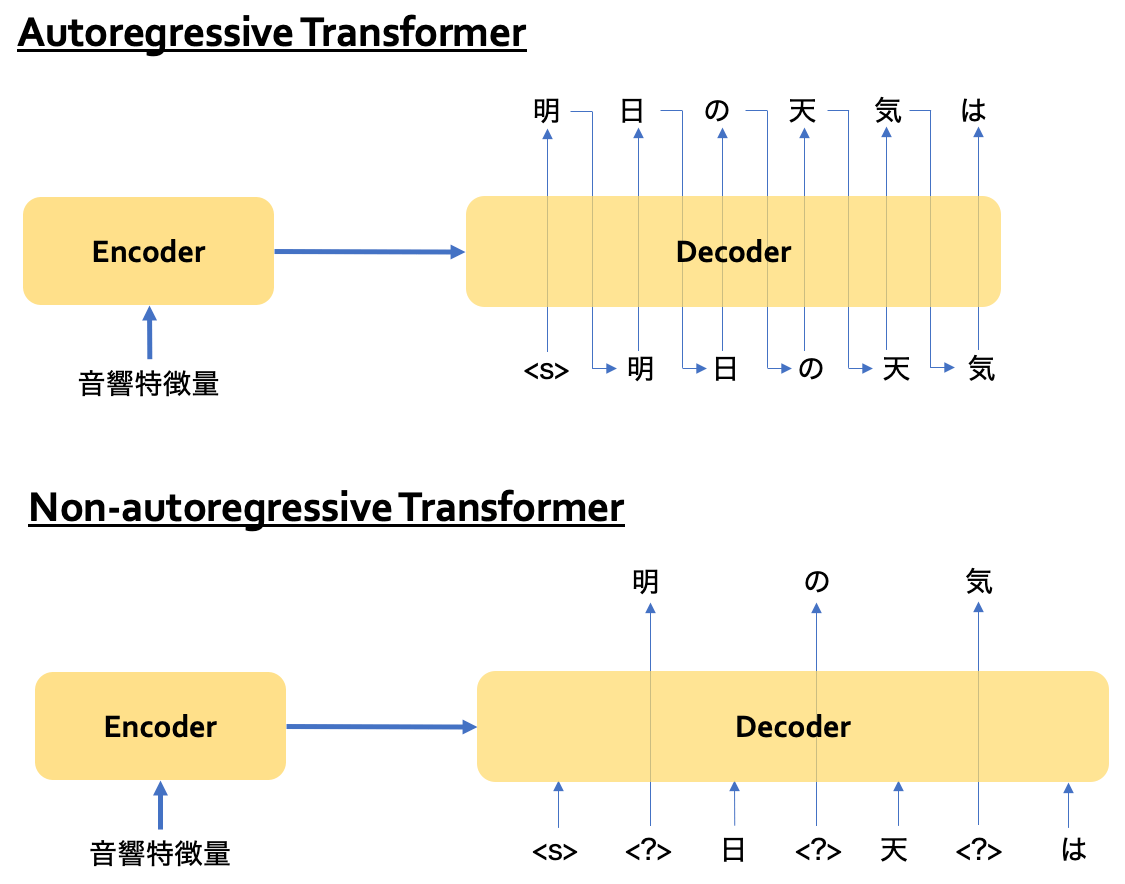
上側がautoregressive Transformer, つまりL2Rな仮定のモデルです。
デコーダの出力つまり認識処理を行う時は、まず文頭を表す特殊記号「<s>」をデコーダに入力し、次の文字を予測して「明」を得ます。次に、「明」をデコーダに入力し、次の文字を予測して「日」を得ます。このように1つ前の文字つまり左側の文字をデコーダに入力して次の文字を予測する、いわゆるL2Rな生成なので、1回の反復で1文字しか出力できません。
一方、下側のnon-autoregressive Transformerでは、左側の文字だけでなく、複数の文字を入力に受け取り、複数の文字を同時に出力します。これはnon-L2Rな生成です。
NATにもいくつか種類があるのですが、この研究では挿入操作に基づく手法(Insertion Transformer)を用いました。他のNATに比べて文字の生成順序が制御しやすいため、この手法を選びました。
挿入操作に基づくNAT, Insertion Transformerとは?
続いて、挿入操作に基づくNAT, Insertion Transformerについて説明します。
L2Rを仮定したautoregressive Transformerの場合、「明→日→の→天→気」という順番で認識結果が出力されますが、non-L2Rな生成を仮定したInsertion Transformerでは、例えば「の→明、気→天、日」というように複数の文字がL2Rではない順番で出力されます。この順番を学習の時にあらかじめ決めておき、その順番にしたがってモデルを学習することで、認識処理の時もある程度学習時と同じ順番で認識結果が出力されます。このように認識処理における文字の生成順序をある程度制御できるのがInsertion Transformerの利点です。
理論的にはどんな順番でも良いのですが、Balanced-Binary-Tree(BBT)というのが認識処理の反復回数を減らせるので、この研究ではBBTを用いました。これは、認識対象の文のなるべく中心の文字を予測するので、N文字の認識処理がほぼlog(N)の反復で終わります。図で書くとこのようになります。
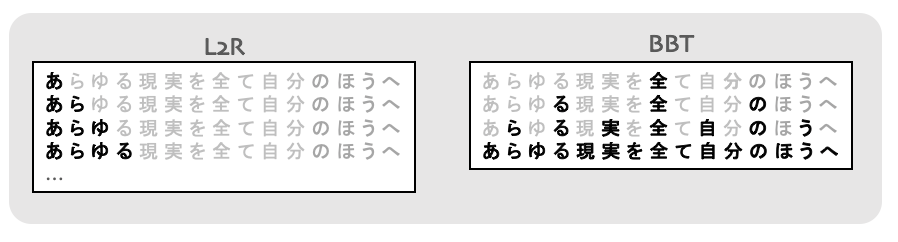
L2Rでは1回の反復で1文字しか出力できないので、N回の反復が必要ですが、BBTの場合、複数の文字を出力できるのと、なるべく中心の文字を出力するので、ほぼlog(N)で全ての文字を出力できます。
実際に試してみると…
というわけで、実験してみました。Corpus of Spontaneous Japanese(CSJ)という日本語の音声データを用いて評価を行いました。L2Rなモデルとして、autoregressive Transformerと比較しました。こちらが結果のグラフです。文字誤り率なので、低い方が良い精度です。
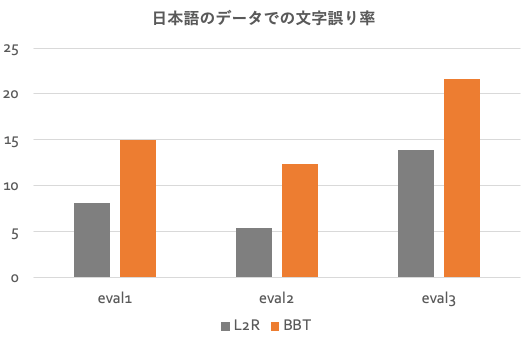
ご覧の通り、L2Rなモデルより性能が悪化してしまいました。やはりL2Rな仮定が音声認識処理には重要なのか…と思い、諦めかけたのですが、なんとかできないかとあれこれ思案しました。そこで思いついたのが、L2Rとnon-L2Rのいいとこ取りができないか、というものです。
2つの仮定の良いところを使った改良
では、どうやっていいとこ取りをするか、が問題です。
まず思いつくのは、E2E音声認識でよく使われるテクニックである、connectionist temporal classification(CTC)と呼ばれるモデルとのマルチタスク学習です。これはTransformerをもちいた音声認識でも利用され、性能改善が報告されています。結果は以下のグラフです。
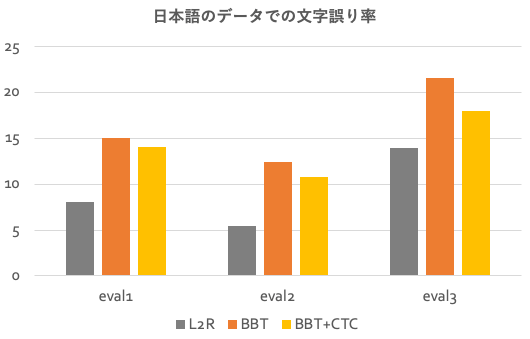
改善はしたのですが、まだL2Rに及びません。
さらに、Insertion Transformerと似たKERMITというモデルを利用することにしてみました。Insertion Transformerとの違いは、TransformerのEncoder層だけしか用いないことです。それだけなのですが、これとCTCを組み合わせると少し面白いことになります。CTCは本来、音響特徴量だけに依存するモデルなのですが、認識文字列にも依存するモデルになるのです。概念図を書くと、以下のようになります。
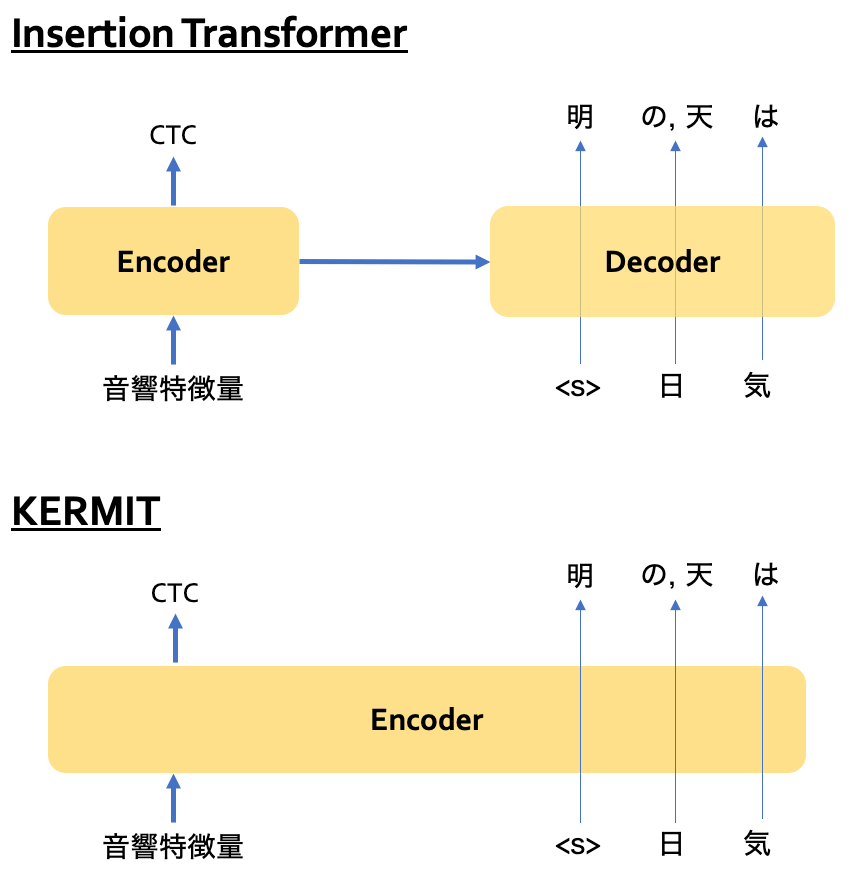
KERMITの場合、音響特徴量も認識結果文字列も1つのEncoderに入力されるので、全ての出力が双方に依存します。CTCはL2Rな生成を仮定するのですが、non-autoregressiveなモデルです。したがって、BBTのようなnon-autoregressiveな生成順序と相性が良いのです。このモデルでは、右側はBBTの順番で認識結果が出力され、左側はその結果に依存してCTCに基づく認識結果が反復ごとに修正されていくような挙動を示します。
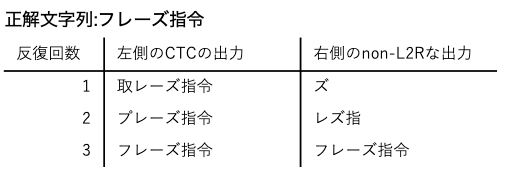
次の図は「フレーズ指令」という発話の認識処理の例です。
さて、性能はどうなったかというと、以下が結果のグラフです。
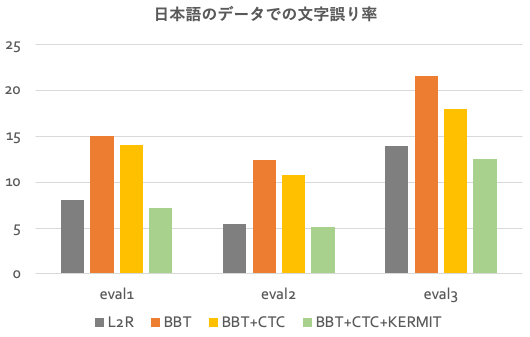
L2Rな仮定のモデルよりも低い文字誤り率を達成できました! L2Rとnon-L2Rの良いとこ取りができたのではないかと考えられます。嬉しいのは、比較しているL2Rなautoregressive Transformerでは認識処理にN回の反復が必要なのに、提案した手法ではほぼlog(N)回の反復で十分なことです。
まとめ
これまでの音声認識処理と違い、左から右ではない順番(non-L2R)で認識結果を出力するモデルが有効なのか、検証してみました。完全にnon-L2RなモデルはL2Rを仮定したモデルに及びませんでしたが、CTCというL2Rなモデルと組み合わせることで、non-L2Rなモデルの美味しいところ、つまり認識処理に必要な反復回数を減らしつつ、L2Rより良い精度を得ることができました。
今後は、課題として、反復回数は減ったのですがトータルの演算量が増えてしまうことと、オンライン処理ができないので、これらの課題を解決して従来よりも低遅延で精度の高い音声認識エンジンの実現を目指します。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました
- 藤田 悠哉
- 音声処理エンジニア
-



