こんにちは、Yahoo!ショッピングでシステム開発を担当している石田と村上です。
Yahoo!ショッピングでは数億件にのぼる商品が日々更新されています。
今回はそれを支える出品ツールをマイクロサービス化して解決した課題と、複数のチームで開発する中で課題に感じたことを紹介します。
出品ツール(ストアエディタ)について
マイクロサービス化の話に入る前に、まずはYahoo!ショッピングの出品ツール(ストアエディタ)について紹介します。
ストアエディタとは、出店ストアの方々がYahoo!ショッピングに出品するためのツールです。
出品データは以下の図にあるフローで連携されます。
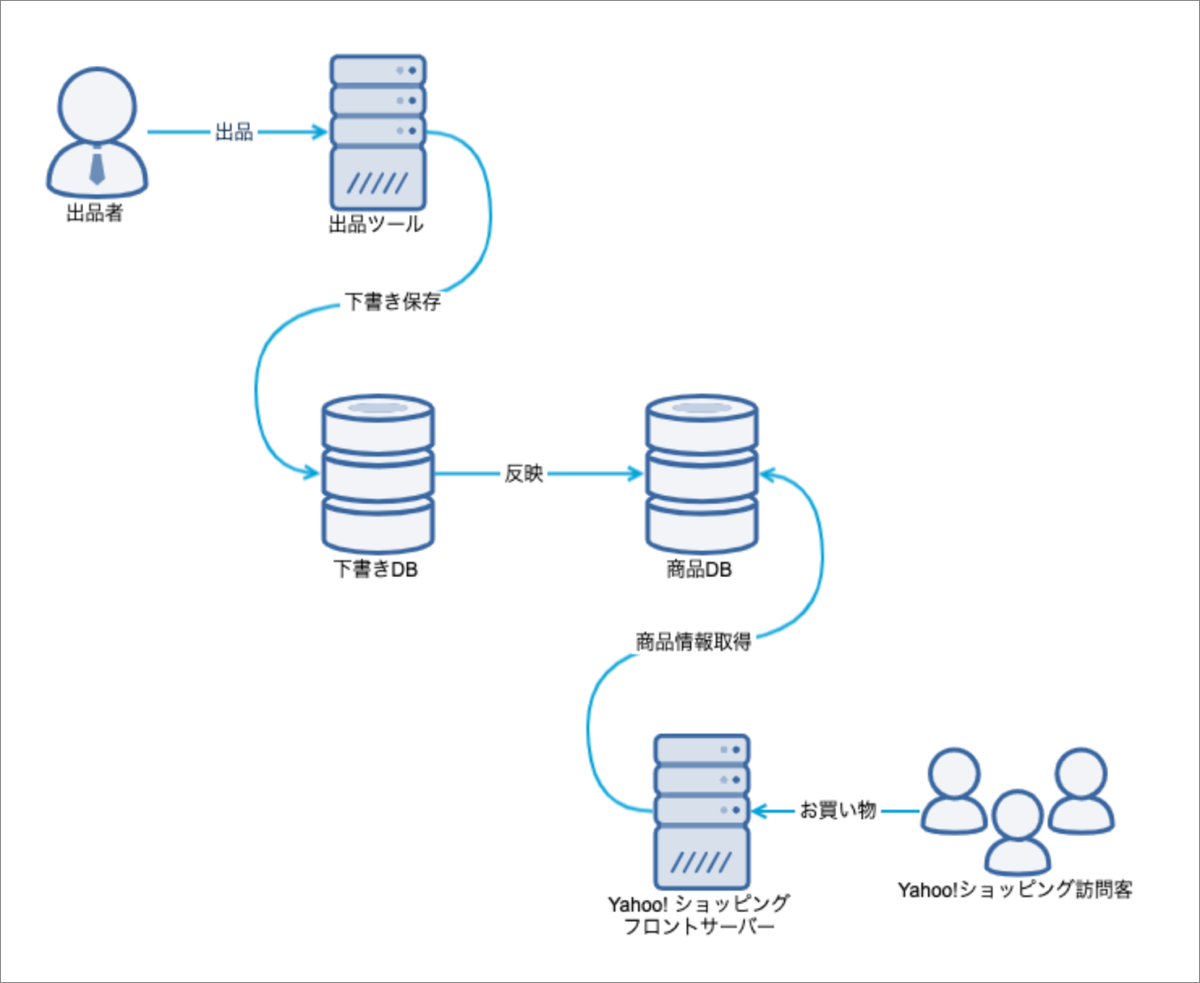
商品情報には以下の情報が含まれており、入稿された値が正しいかどうか確認し、問題なければ下書きとして保存します。
- 商品情報(商品名、価格など)
- 商品画像
- 商品在庫
- デザインデータ
そして、出品者の任意のタイミングでこれら商品情報を下書きデータベース(以下DB)から商品DBに反映をすることが主な業務です。
既存システムの3つの課題
先程紹介した連携図をもう少し拡大し、ストアエディタの大きな課題を3つほど追記してみました。
四角で囲われた文章が課題です。それぞれ詳しく解説します。
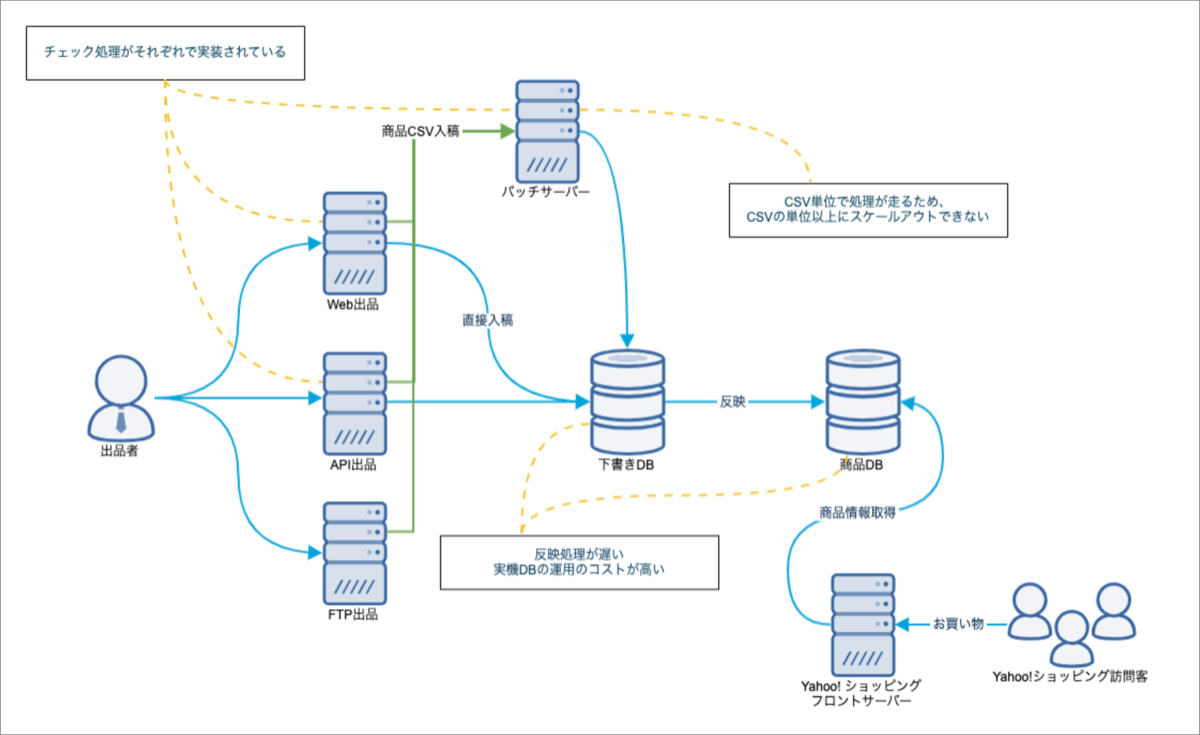
1. 複数ある商品情報の入稿口でチェック処理がそれぞれ実装されている
Yahoo!ショッピングの商品はサービスの成長とともに、出品者のニーズに合わせてさまざまな商品の入力項目が増設されてきました。
その結果、現在では1つの商品につき、100種類以上の入力項目があります。
100種類以上の入力項目がそれぞれで複雑なチェック要件を持ち、また、中には複数の商品にわたって正当性を確認しなければいけない場合もあり、ビジネスロジックの定義は混迷を極めます。
そればかりではなく、3つの入稿口で同じビジネス要件に対して、それぞれ違った実装がされているため、開発者はソースコードの理解に時間がかかります。
当然ビジネス要件の開発やテストのコストも高く、あまり生産的であるとは言えない状況です。
2. 商品CSVの処理が単一のバッチサーバーで処理され、それ以上スケールアウトできない
Yahoo!ショッピングの出品経路は複数ありますが、およそ全体の6割は商品一覧を商品CSVにまとめて記載して入稿する方式が取られています。
しかし、商品CSVのデータをパースしてチェックを行う処理が単一のバッチサーバーで実施されるため、例えば数十万商品が入った商品CSVが処理されるような場合、チェック処理に多大な時間を要します。
3. 2つのDBをまたいだ反映処理が遅く、実機DBの運用コストが高い
反映前後のDBはどちらもMySQLを採用していますが、商品CSV単位でトランザクションが貼られるため、大量の入稿になると急激にパフォーマンスが下がります。
また、下書きDBに保持されているような複雑なテーブル構造のまま参照すると、ショッピングフロントからアクセスされた際に高いパフォーマンスでリクエストをさばくことができないため、データ構造を簡略化させた形で商品DBを持つ必要があり、予約反映機能の実装のほか、パフォーマンス面からも2つのDBをまたがざるを得ない状況になっています。
更に、データが増えると水平分割を余儀なくされますが、このオペレーションが開発者による手運用になっており、1回の水平分割あたり10-15人日ほどのコストやメンテナンスのためのサービスの一時停止が要求されます。
既存システムから新システムへ
既存システムの一連の課題を引き起こした原因は、要件が増えるごとに、以下のような適切ではない改修を積み重ねたままシステム規模が膨大になり、
ソースコード的にもシステム構成的にも良くない構成になってしまったことに起因します。
- スケジュールの都合上、タイトな納期の中で開発する必要があったため、各入稿口で細かい機能に差分を出してしまった
- 対向システムの開発リソースが足りず、本来ストアエディタが持つべきではない業務を追加してしまった
- パフォーマンス面で問題が発覚しても、基本設計の限界から根本的な改善を行う事が難しく、その場しのぎの改善を繰り返した
そのため、私たちは以下のアプローチでストアエディタを刷新することにしました。
- ストアエディタ全体をマイクロサービス化し、各サービスの役割を明確かつシンプルに定義して、実装の難易度を下げつつ、ソースコードやシステム構成の腐敗を防ぐ
- システムの設計にDDDを採用し、ストアエディタが持つ以下のコアドメインを中心にしたシステムにする
- 商品情報のチェックにかかる時間を短縮し、開発を容易にする
- 商品の反映にかかる時間を短縮する
刷新後のシステム構成
下記の図は刷新後のシステム構成です。
ここまでに紹介した3つの問題点をどう解決したか紹介します。
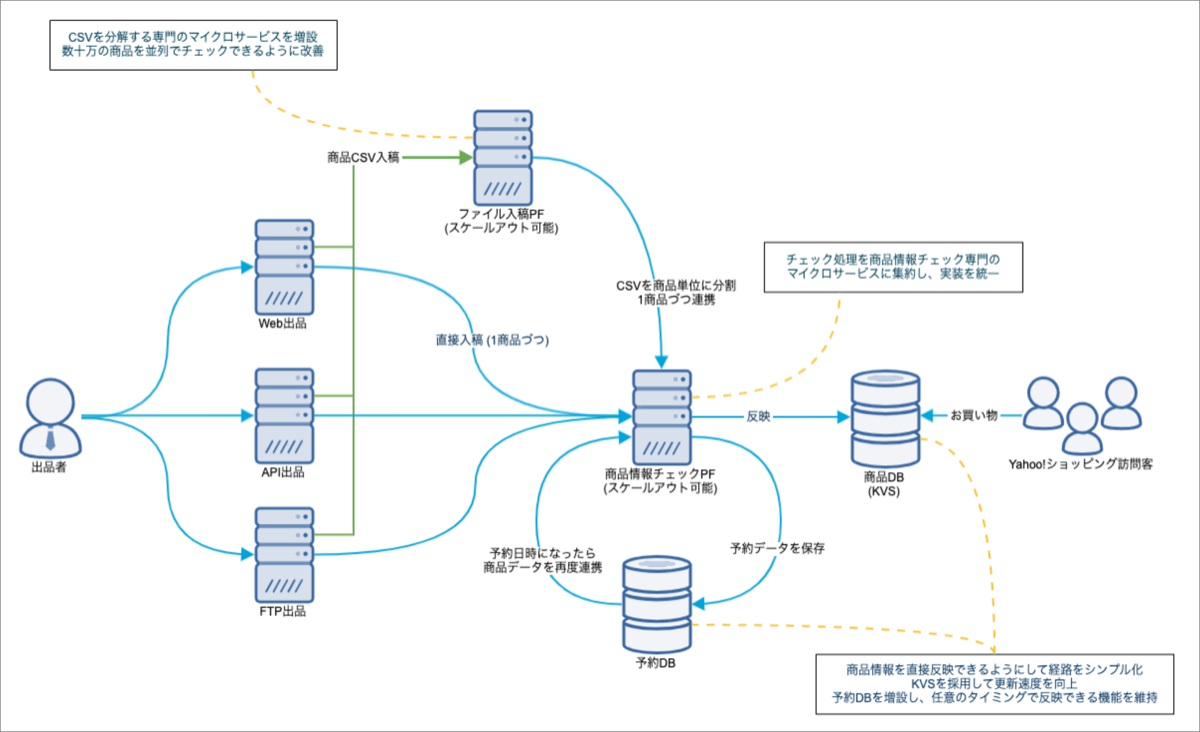
1. 商品情報のチェックロジックを1つにまとめ、チェック専門のマイクロサービスを新設
これまでは各入稿口とバッチサーバーで、同じビジネス要件に対して、異なる実装をしていました。
刷新後のシステムでは、商品情報チェックPFにチェック処理を集約し、実装コストを大幅に下げました。
また、1商品単位のチェック処理のみを行うという制限を設けることで、チェックロジックがシンプルになりました。
今後は商品情報チェックPFに対していかに商品情報を連携するか。という目線で周辺のマイクロサービスを構築していくことになります。
また、チェック処理はストアエディタの最も重要な業務になることから、詳細設計にDDD(ドメイン駆動設計)を取り入れてコードの腐敗を防いでいます。
具体的にはドメイン層にコレクションと値オブジェクトを持ち、データの置き場所とビジネスロジックを一体にすることで、コードの可読性を格段に上げています。これはコードが仕様書と言い張れるほどの会心の出来になりました。
DDDを活用した開発を行う上で、開発者同士で増田亨さんの現場で役立つシステム設計の原則を読み合わせ、知識レベルを統一させた上で開発に取り掛かりました。この本はとてもわかりやすくDDDの概念やテクニックの活用方法を解説をされていて、DDD初心者の方でも非常に読みやすい一冊になっています。
2. 商品CSVを商品単位に分解し、直接入稿と同じ経路に連携
数十万に及ぶ巨大なCSVのチェック処理は、出品処理にかかる時間の大きなボトルネックになっていました。
刷新後のシステムでは、商品CSVは全て商品単位に分解され、非同期で商品情報チェックPFに連携されるようになりました。
これによって、今まで1台で実行していた膨大なチェック処理を大量のサーバーで並列処理できるようになりました。
3. 2つあったDBを1つにし、全社マネージドのKVSを採用
これまでは予約反映機能とパフォーマンスの確保を実現するため、DBは2つに分けていました。
刷新後のシステムでは、DBは1つに集約し、商品単位の入稿にKVS(Apache Cassandra)を採用することで、参照/更新の双方の速度を向上させました。
これにより、1つのDBでフロントの激しいアクセスに耐えつつ、ストアエディタからの高い更新要求にも耐えられます。
KVSは複数レコードの操作や、JOINが苦手な代わりに、単体レコードであればRDBに比べて非常に高速に処理できるという特徴があります。
商品情報チェックPFでは常に商品単位でチェック処理が行われるため、KVSと大変相性が良く、採用に至りました。
今まで持っていた予約機能は予約専門のDBを持つことで、必要な場合にだけ、2つのDBをまたぐような仕組みに改善しています。
また、今まではMySQLの実機を開発者が手動で運用していたため、運用コストが高かったことも問題でしたが、刷新後のシステムでは社内のインフラチームマネージドのKVSを採用しており、開発者はより開発に集中できるようになりました。
チーム内でどのように開発を進めたか
ここからは実際に、このようなシステム刷新をチーム内でどのようにすすめていったかご紹介します。
開発手法について
部署内で小さなチームを複数作り、そのチームで1つずつマイクロサービスをスクラッチ開発するという方法で行いました。 その小さなチームの中で、開発手法はウォーターフォールを採用しました。
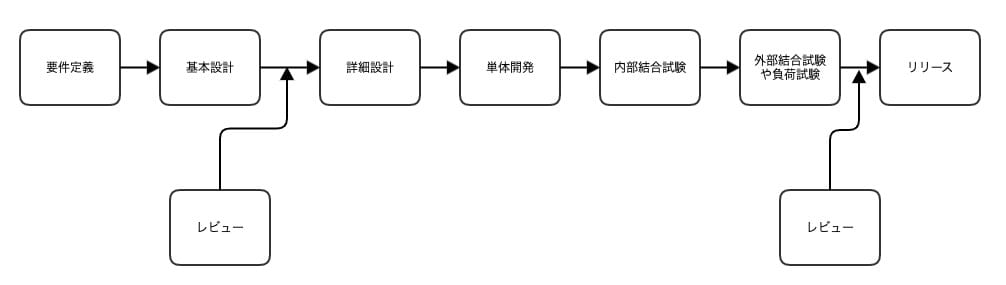
基本設計後と各種試験が終わったタイミングで、チーム内外のメンバー、テクニカルディレクターを交えて、要件を満たしているかレビューを行います。
いまアジャイルな開発手法が話題になっていたりしますが、あえてウォーターフォールにした理由は3点あります。
- 必要な工程が洗い出せているので、人材投入計画をたてて計画管理をしたかった
- 既存システムのリプレイスのため、仕様が大幅に変更される可能性が低かった
- 開発経験が浅いメンバーが多いため、事前に取り組む仕様・要件を確定させて迷いがない状態で開発をすすめたかった
実際に取り組んでみて、ガントチャートを引いて管理することで計画管理や、人的リソースの割当の状況把握がやりやすく、プロジェクト管理はやりやすかったです。
取り組んでつまずいた課題
ウォーターフォールな開発は管理はしやすかったのですが、開発をすすめていく中で課題も発生しました。
1. チーム毎に開発したため、仕様が揃っていない部分があった
ウォーターフォール開発では各フェーズごとに順番に開発を進めていきます。
今回、各マイクロサービスごとに開発も進めたため、他システムとの連携が最後になりました。
実際に外部結合試験を始めたところ、インターフェースの要件や単体開発時にでた追加要件などに追従していないことがわかりました。
結果、結合試験が思うように進まず、結合させるために追加の工数が必要になりました。
2. 採用技術が異なるため、他チームをサポートできない
各マイクロサービスに技術選定を任せた結果、それぞれのチームやシステムにあった技術を採用することができました。
しかし、言語や各種フレームワークが異なることにより、メンバーの中には触ったことがない言語を使っていたり、使ったことのない技術が採用されていたりして、マイクロサービス間での人の行き来がしにくいという問題がありました。
「XXのマイクロサービスが忙しいからYYから助けてもらおう」ということがなかなかうまくできませんでした。
3. タイムアウト値や、リトライ回数等の非機能要件の認識合わせがマイクロサービス間で十分にされなかった
開発を各マイクロサービス内で閉じた結果、リトライ回数やタイムアウト値をそれぞれ決め打ちして作りこんでしまいました。
実際に結合して、ユースケースを想定したテストを行った際に「ああ、XXのマイクロサービスからYYのマイクロサービスにアクセスしたときに3秒でタイムアウトしているから処理が進まない」といったようなことが発生しました。
事前に処理の規模や速度をサービス間で共有して、リトライ回数等を決めておくべきです。
課題を踏まえてやってみたこと / 次回やりたいこと
こうした3つの課題を踏まえて、チーム内でマイクロサービス開発をする上で、実際に改善してみたこと、こうしたほうがよかったなと思うことを説明したいと思います。
いずれもちょっとの工夫で解決できると思ったので今後にも生かしていきたいなと思います。
チーム合同の朝会を取り入れてみる
実際に開発やテストをすすめていく中で、他マイクロサービスと認識をあわせなければならない場面が多々あります。
ただ、いくら同じ部署内とはいえ、個々のチームでマイクロサービスを作っていると、チーム同士でのコミュニケーションが減りがちでした。
なのでコミュニケーションを促進するため、毎朝30分くらいマイクロサービスごとの担当者を横断して、朝会を行うようにしました。
各システム間の連携の課題や詰まっていることをいち早くキャッチできるようになり、認識の相違が小さくなってきました。
また、「他チームの目」が入ることで、「この箇所の非機能要件が相違してるからちゃんと決めなきゃね」といった話も活発になってきました。
早い段階からコミュニケーションを取る頻度を増やしたほうが、後で困らなくてすむと思います。
非機能要件は早めに標準化しておく
リトライやタイムアウト値、返却されるステータスコードといった要件は、実装する前にあらかじめチームでコンセンサスをとっておくと良いです。
実際に組み終わった後に、すり合わせて決めていくと組み終わったシステムにそぐわない部分が出てきたりします。
また、エラーコードのハンドリング等の実装を後追いでやる必要がでてきたりすると、計画通りにシステム開発が進まなくなることもあります。
早めに結合してみる
今回開発の最後のフェーズで外部結合をしたのですが、認識の相違や問題が後工程になって複数出てきました。
その結果工期が2カ月程度遅延してしまいました。
複数チームで一つのシステムを作り上げる場合、それぞれのマイクロサービスに注力してしまうので、実際に1つのシステムとして動かしてみないと気づかない結合部分の問題も多いです。
なのでシステム間結合の接面は早めに結合して、少しずつ実装していくのが良いと思います。
まだ残る課題
開発を終えてシステムをリリースしたあとも、このマイクロサービスの保守開発だったり、運用だったりが続きます。
これからも解決していかなければならない課題について少し考えてみました。
開発手法のブラッシュアップ
今回、管理コストや、仕様があまり動かないことからウォーターフォールの手法を導入しました。
ですが、もっとコミュニケーションを頻繁にとり、ちょっとずつ開発をすすめるインクリメンタルな手法もあわせて取り入れて行ったほうが良いと思いました。
例えば、スクラムでのスプリントのようにあらかじめ小さなゴールを決めて開発に取り組み、都度動くものを作り続ける開発をしてみるなど、工夫の余地はまだまだあります。
開発の標準化
システムをマイクロサービス化したことにより、システムごとにタイムアウト値や、リトライ回数の設定が分散しやすくなりました。
単一のアプリケーションで開発していたモノリスな作りであった時よりもかなり細かく規約を定めないと、微妙な設定の差がシステム感の連携にきしみを生むようになります。
また、マイクロサービスにすることで、サービスごとに要素技術が異なることもありえます。そうした異なる技術をチーム内でどう運用していくか、常に考え続けなければなりません。
ある程度人の行き来が多い部署では要素技術は標準化しておくほうがよいように感じています。そうすることによって、新たにチームに入ってくる人の学習コストや、開発する分のリソース調整がしやすくなります。
マイクロサービス化のメリット
こんな感じで開発中にはいろいろ課題もあり、ここまで読んできた皆さんの中ではマイクロサービス化って大変そうと思った方もいると思います。
ですが、実際にマイクロサービス化して下記4点のようなメリットを感じることもあり、結果的に良かったと思っています。
- 変更に強いシステムを作ることができる
- 各マイクロサービスの役割が単純かつ明確になりやすいため、役割の重複を避けやすい
- DDDを合わせて活用することで、ビジネスロジックの定義がスマートになるため、システムのあちこちで同じようなビジネスロジックが乱立することを回避できる
- 並列処理とも相性が良いため、システムを運用する際に思わぬ所でボトルネックが発生した場合でも、一部の機能だけスケールアウトして増強を図ることが簡単にできる
終わりに
今回は漬け込み過ぎた秘伝のタレをマイクロサービス化して刷新した話をいたしました。
皆さんにとって「あるある〜」「わかるなぁ〜」と感じられた部分はありましたでしょうか?
このように何もかも作り変えるような機会は稀かもしれませんが、サービスの持つ業務を細かく分割し、単純にしていくことの大切さが伝われば嬉しいです。
また、開発中にでた課題を解決していき、よりよいシステムを作っていきたいと思います!!
最後まで読んでくださり、ありがとうございました。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました

- 石田 健太
- Yahoo!ショッピング ストア領域バックエンドエンジニア
- Yahoo!ショッピングのストアツール開発・運用をしながら、インフラからアプリまで幅広くできるエンジニアを目指しています。
-

- 村上 賢達
- Yahoo!ショッピング ストア領域バックエンドエンジニア
- Yahoo!ショッピングで数億件規模の商品を支えるストアツールの開発をする傍ら、どんな事でも一撃のコマンドで解決できるシェル芸人も目指しています。
-



